
**索引的优点: 提高查询效率 **
索引的缺点: 索引并非越多越好,过多的索引会导致****CPU使用率居高不下,由于数据的改变,会造成索
引文件的改动,过多的磁盘I/O造成CPU负荷太重
一、索引的分类
物理上(聚集索引&非聚集索引),逻辑上(单列索引&多列索引)
1、普通索引:没有任何限制条件,可以给任何类型的字段创建普通索引(创建新表&已有的表,数量不限,一张表的一次sql查询只能用一个索引)用索引肯定是where过滤的时候用的
2****、唯一性索引:使用UNIQUE修饰的字段,值不能够重复,主键索引就隶属于唯一性索引
3****、主键索引:使用Primary Key修饰的字段会自动创建索引(MyISAM, InnoDB)
在InnoDB下,如果创建一张表,会默认增加一个整形字段的列去作为主键,而在MyISAM下不会默认生成,因为InnoDB的数据和索引是存在一个文件下的,.IBD 文件中,他必须建索引树,然后在索引树中存数据,没用索引树是存不了数据的
4****、单列索引:在一个字段上创建索引
5****、多列索引:在表的多个字段上创建索引 (uid+cid,多列索引必须使用到第一个列,才能用到多列索引,否则索引用不上)
6****、全文索引:使用FULLTEXT参数可以设置全文索引,只支持CHAR,VARCHAR和TEXT类型的字段
上,常用于数据量较大的字符串类型上,可以提高查询速度(线上项目支持专门的搜索功能,给后台服务
器增加专门的搜索引擎支持快速高校的搜索 elasticsearch 简称es C++开源的搜索引擎 搜狗的
workflflow)
以索引为过滤条件,也不一定会使用到索引的,MySQL会先进行一下sql分析,如果查出来的数据量跟整表搜索差不多的话,还不如直接就是整表搜索了。因为使用索引的步骤还是比较多的:
首先要读索引文件,花费磁盘io,还要扫描索引树,数据取不完的话最终还要去表上取数据,还不如直接扫描整个表呢
索引创建的细节:
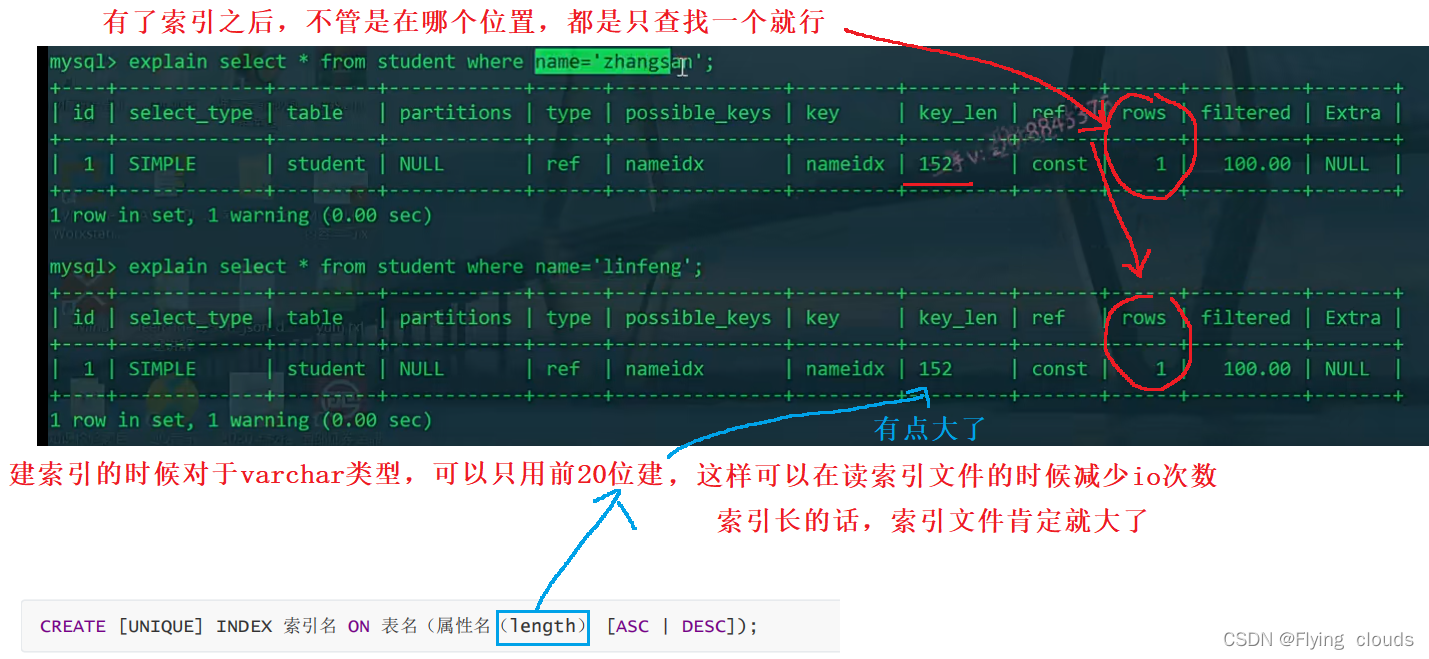
索引优化:
1、给经常要作为where过滤的条件要加上索引
2、给字符串列创建索引的时候要考虑索引的长度,越短越好(只要能区分索引值就行)
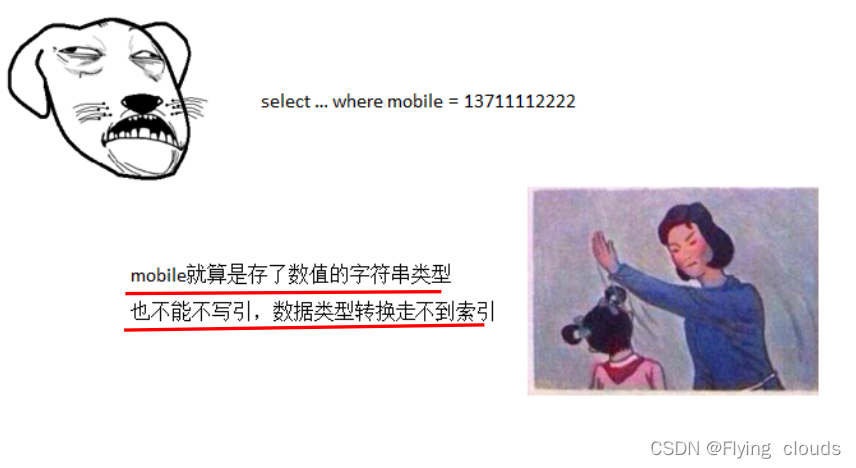
3、如果过滤条件过滤字段涉及类型强转就不能用到索引了,过滤条件用到MySQL的函数,也用不到索引了
二、索引的底层原理是什么?

b树比AVL树最大的好处就是在于磁盘I/O的次数少,在内存上搜索起来效率其实差不多的
2.1、Innodb和MyIsAM两种引擎搜索数据时候的区别:
假设搜索语句是:****select * from student where name = 'ZhangSan';
MyIsAM:
** name 没有索引: 会对name****.MYD**文件进行整表扫描查询。
** name 有索引:**会有一个**name.MYI**的文件,从这个文件中会把数据加载到内存上构建一个b树,花费一次磁盘I/O读取到的数据就刚好写在b树的一个节点上面(**最多磁盘I/O三次就行了**),然后从根节点上开始字符串的比较,效率是log(n),因为**MyIsAM的数据和索引存在不同的文件上,所以找到的data存放的只是真实数据的地址,还要到****name.MYD****上去拿数据**
Innodb:
** name 没用索引:**也会默认有索引树,会自己生成一个整形的主键值,因为查的是name,相当于就说把这课b树整个内容全部搜索一遍,也和整表搜索没啥区别。
** name 有索引:**就会加载name的b树,进行快速搜索就行了。
2.2、为什么MySQL(MyIsAM、Innodb)索引选择B+树而不是B树呢?
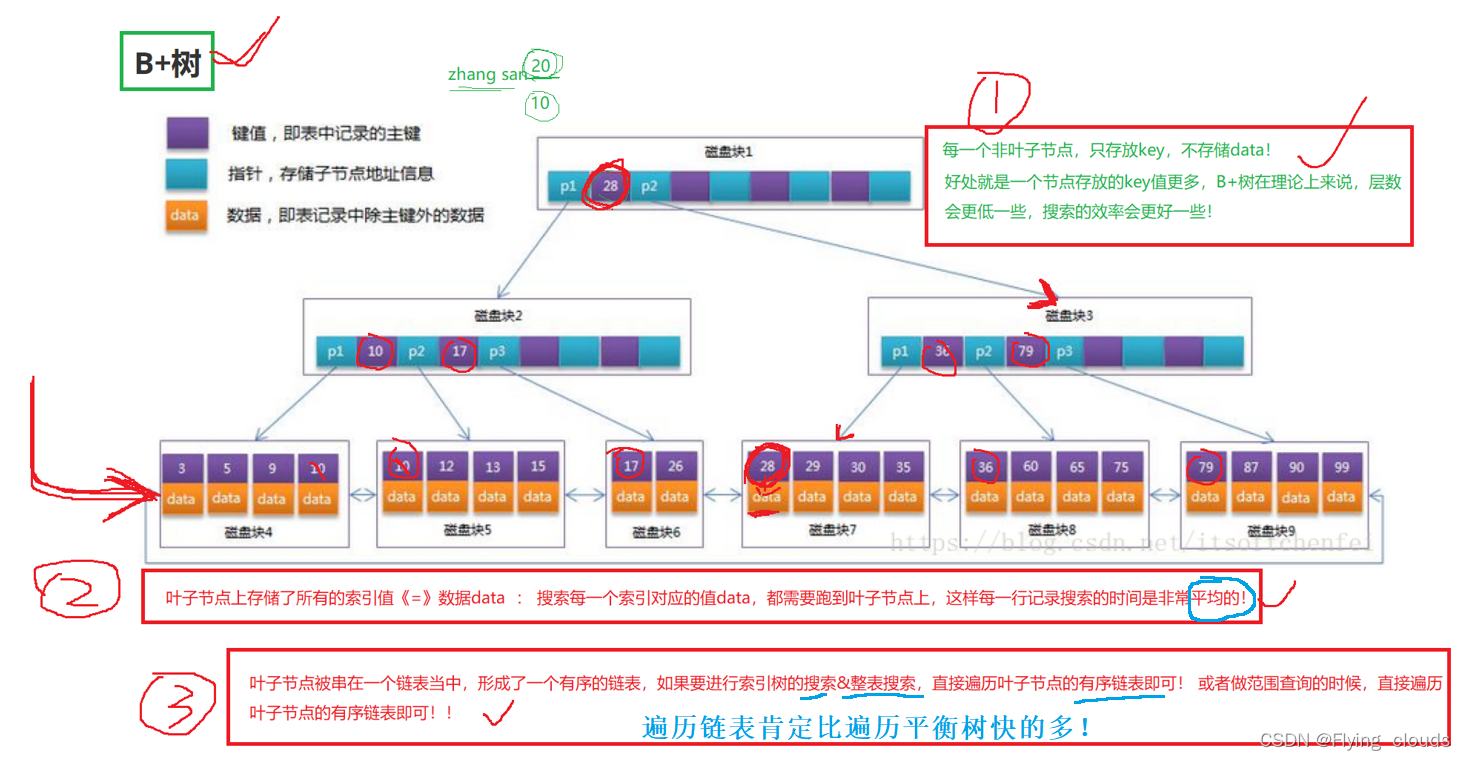
** 问:索引的底层原理是什么?**
select * from student where name='ZhangSan';
当要执行一个sql语句的时候,MySQL会先去分析一下过滤条件,如果没用索引的话,就去整表搜索 ,如果有索引的话,操作系统会从磁盘上的索引文件中将数据读到内存当中,用B+树来构建,为什么用B+树呢?
因为B+树是一颗平衡树,搜索的效率很好,而且B+树一个节点一个节点构建的,每个节点对应着一次磁盘I/O,能用较少的I/O次数构建出B+树结构。
而且所有的data都存在叶子节点上,每次搜索数据查询次数都比较平衡,有链表。。。。
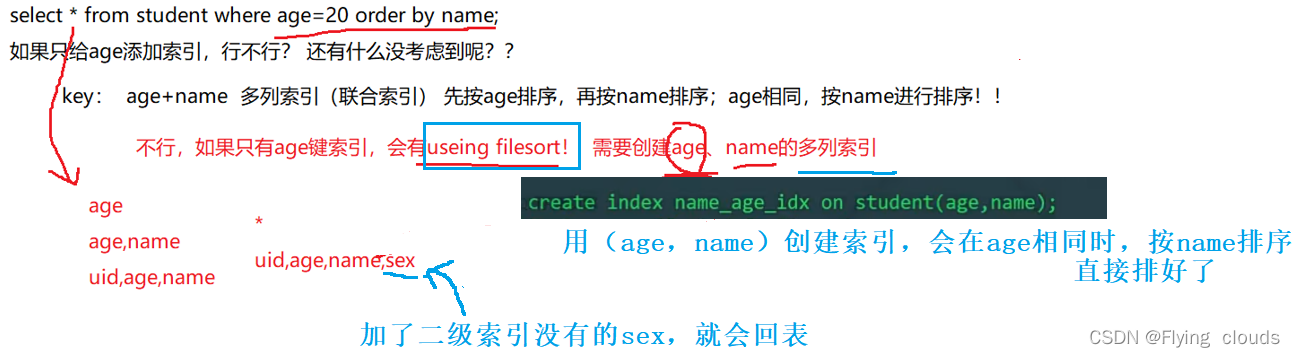
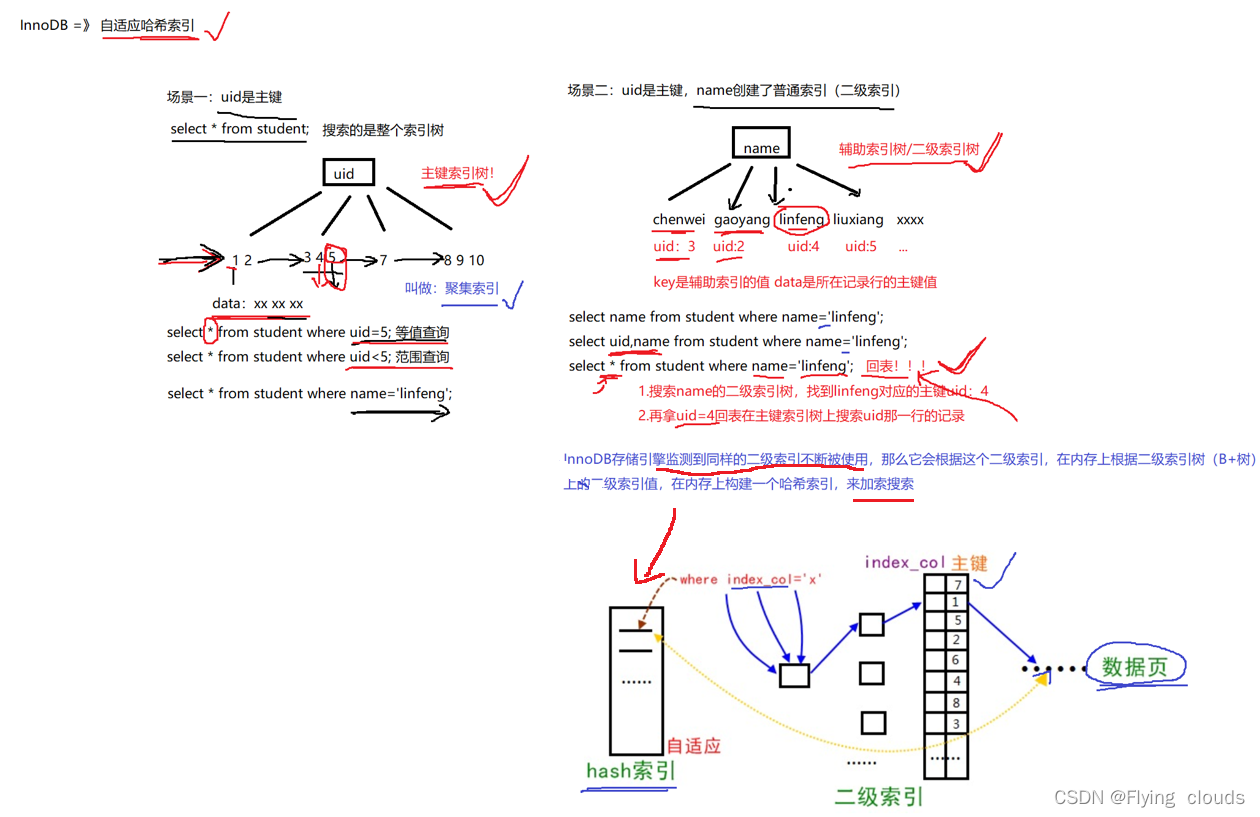
2.3、Innodb的主键索引和二级索引(辅助索引)
重点:二级索引有回表,可以选择相应的列避免回表

** using filesort 问题**
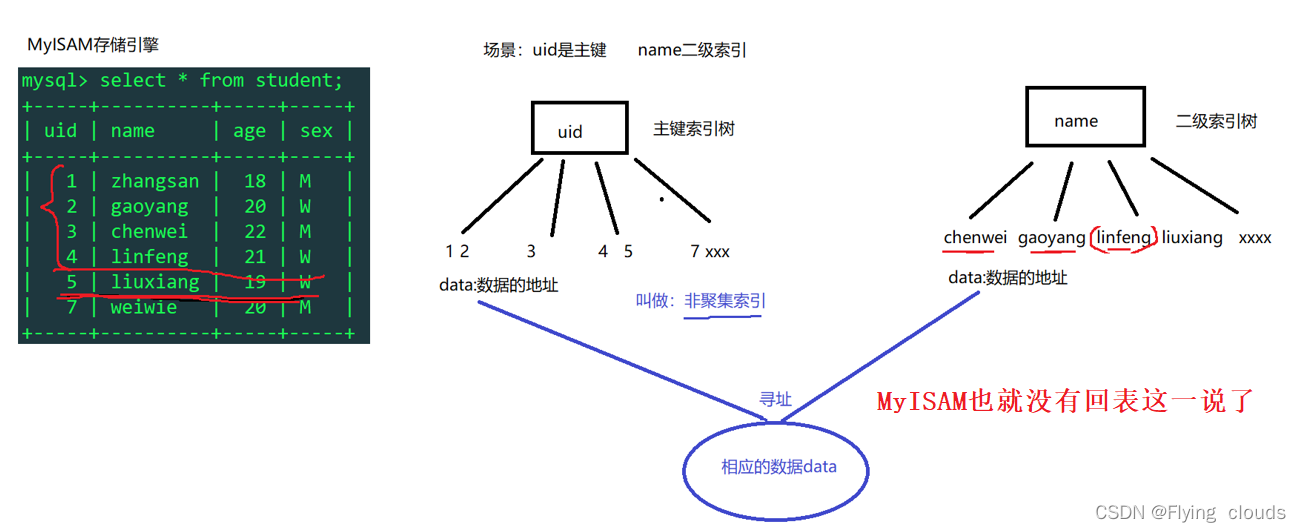
2.4、MysIAM的主键索引树和二级索引树
索引和数据分开存放的叫非聚集索引,放一起的叫****聚集索引
2.5、哈希索引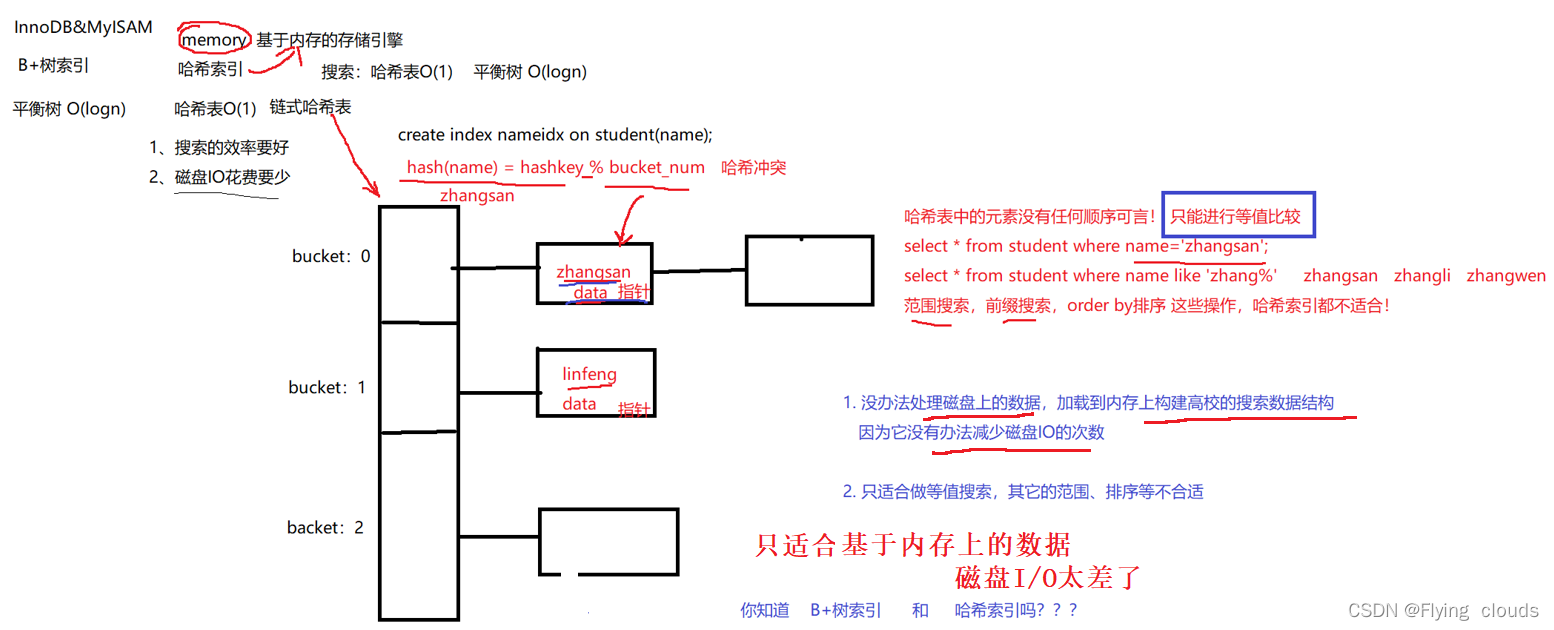
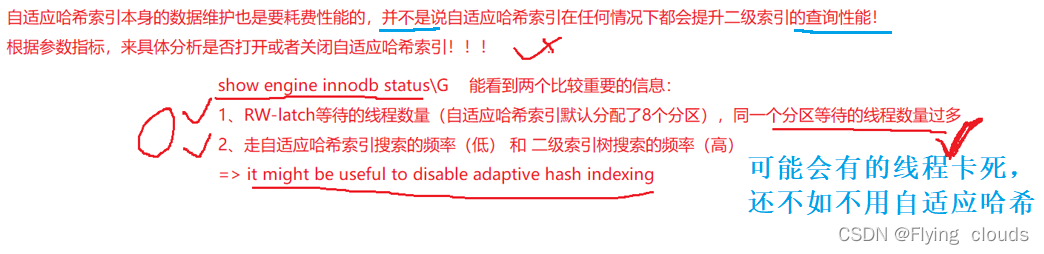
2.6、Innodb自适应哈希索引
自适应索引不是我们主动去创建的,是MySQL为了优化自己去创建的基于B+树的
我们先来看自适应哈希索引是在什么条件下生成的:
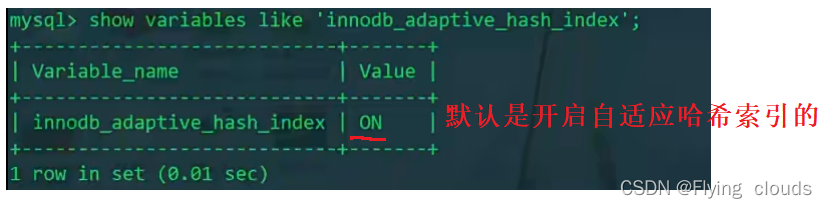
我们可以查看自适应哈希索引的开启情况:
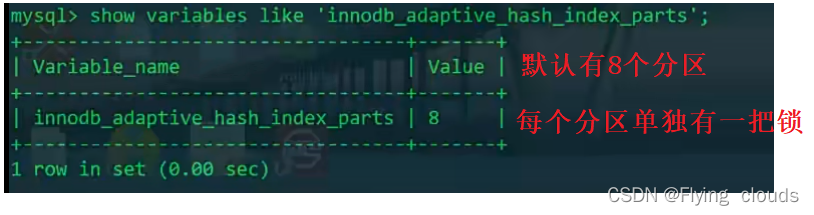
查看分区情况:
自适应哈希索引也不一定能优化:
三、索引的常见问题
3.1、当有多个索引的时候怎么用呢?比如 a=1 and b=2 and c=3
我们首先知道的是:一次sql只会用到一次索引,用到的是看哪个过滤出来的数据少,就用哪个,当然,也是可以进行强制指定到底用哪个索引的。

3.2、涉及到强转(字符串转整型)用不到索引
四、 sql和索引优化问题,怎么切入?用慢查询日志
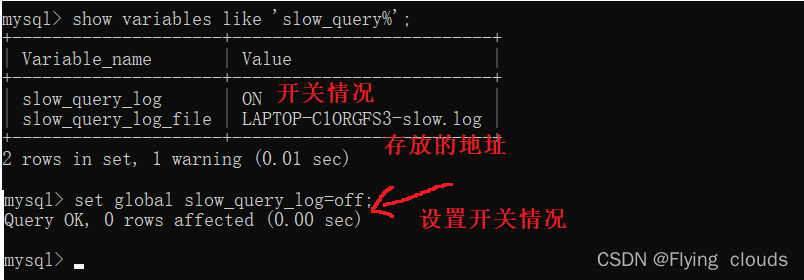
slow_query_log 慢查询日志
MySQL可以设置慢查询日志,当SQL执行的时间超过我们设定的时间,那么这些SQL就会被记录在慢查
询日志当中,然后我们通过查看日志,用explain分析这些SQL的执行计划,来判定为什么效率低下,是
没有使用到索引?还是索引本身创建的有问题?或者是索引使用到了,但是由于表的数据量太大,花费
的时间就是很长,那么此时我们可以把表分成n个小表,比如订单表按年份分成多个小表等。
设置慢查询日志的参数:
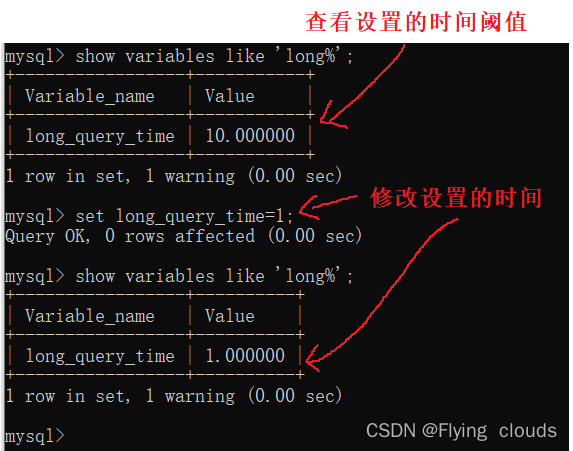
我们可以修改慢查询的时间阈值:
1、 打开慢查询日志,设置合理的业务可以接受的慢查询时间。
2、 压测执行各种业务
3、 查看慢查询日志,找出所有执行耗时的sql
4、****用explain分析这些耗时的sql

5、 ** 一、可能会出现用了 where + order by,有using file sort**的问题。为什么会出现file sort 外部排序的情况呢?因为数据都是在磁盘上存放的,如果没有加合适的索引,就只能先将数据读到内存当中,然后再进行排序的了,可以将where和order by 的数据进行一下联合索引,然后在进行。
** 二、**可能是没有加索引
** 三、**可能是where过滤条件用到了函数,导致没有用到索引
**四、**可能涉及到了MySQL数据的强转(字符串转成了整型),没用到索引。
版权归原作者 Flying clouds 所有, 如有侵权,请联系我们删除。