
最近有点不走运,老是遇到基础服务的问题,还是记着点儿解决方法,以后再遇到快速解决吧,今天遇到这个问题倒不算紧急,但也能通过这个问题熟悉一下Kafka的配置。
问题背景
正在开会的时候突然收到一连串的报警,赶忙看看是为啥
没过一会儿基础服务报警也来了
告警名称:Kafka-topic consume exception
识别号:xxxxx
状态:firing
开始时间:2023-08-0919:28:05
当前时间:2023-08-0919:28:05Summary:KafkaCluster: common-xxxx-xx Topic:{ xxxxxxx-prod }Group:xxxxxxx-prod Status:STALLDescription: 诊断报告
报警标识
Kafka 自身的异常状态的枚举:
- Leader Not Available (LEADER_NOT_AVAILABLE): 当尝试读取或写入一个分区时,分区的 Leader 副本不可用。
- Replica Not Available (REPLICA_NOT_AVAILABLE): 当尝试读取或写入一个分区时,分区的副本不可用。
- Request Timeout (REQUEST_TIMED_OUT): 请求在指定的时间内没有得到响应,可能是因为网络延迟、负载过重等原因。
- Offset Out of Range (OFFSET_OUT_OF_RANGE): 尝试读取一个不存在的偏移量。
- Invalid Offset (INVALID_OFFSET): 提供了无效的偏移量。
- Unknown Topic or Partition (UNKNOWN_TOPIC_OR_PARTITION): 尝试访问不存在的主题或分区。
- Record Too Large (RECORD_TOO_LARGE): 尝试写入的记录大小超过了 broker 配置的最大记录大小。
- Not Enough Replicas (NOT_ENOUGH_REPLICAS): 写入操作无法满足分区的最小副本数配置。
- Message Size Too Large (MESSAGE_TOO_LARGE): 尝试写入的消息大小超过了 broker 配置的最大消息大小。
- Topic Authorization Failed (TOPIC_AUTHORIZATION_FAILED): 消费者或生产者没有足够的权限来访问指定的主题。
- Group Authorization Failed (GROUP_AUTHORIZATION_FAILED): 消费者群组没有足够的权限来访问指定的群组。
- Offset Metadata Too Large (OFFSET_METADATA_TOO_LARGE): 提供的偏移量元数据超过了 broker 配置的最大大小。
- Connection Error (CONNECTION_ERROR): 与 broker 的连接遇到问题,可能是网络故障或 broker 宕机等原因。
- Unknown Error (UNKNOWN_ERROR): 未知的错误,可能是由于 Kafka 内部问题引起的。
这些异常状态可以在 Kafka 的客户端和服务端之间的交互中出现,通常会在日志或异常堆栈跟踪中得到体现
基于Kafka-topic_consume_exception策略,一般对于分区状态的依据kafka的报警状态枚举:
- NotFound 状态:这个consumer group 不存在
- OK 状态:正常消费
- Warning 状态:有一个或多个分区正在延迟,当前在消费,但是消费延迟越来越大
- Error 状态:有一个或多个分区已经处于STOP,STALL,Rewind等几种状态之一
- Stop 状态:消费者已经有一段时间没有提交offset了,并且消费延迟非0
- Stall 状态:消费者正在提交offset,但是offset没有增加,并且消费延迟非0
- Rewind 状态:消费者提交了一个比之前还早的offset
ok,Stall状态结合监控异常,我们发现应该是一批次提交的数量太多处理不完了,可以通过增加批次处理间隔或减少批次数量避免延迟消费
问题原因
配置举例:
max.poll.records = 20
,而
max.poll.interval.ms = 1000
,也就是说consumer一次最多拉取 20 条消息,两次拉取的最长时间间隔为 1 秒。也就是说消费者拉取的20条消息必须在1秒内处理完成,紧接着拉取下一批消息。否则,超过1秒后,kafka broker会认为该消费者处理太缓慢而将他踢出消费组,从而导致消费组rebalance。根据kafka机制,消费组rebalance过程中是不会消费消息的。所以看到三台机器轮流拉取消息,又轮流被踢出消费组,消费组循环进行rebalance,消费就堆积了
标准指标
生产者的一些参数指标
消费者的一些参数指标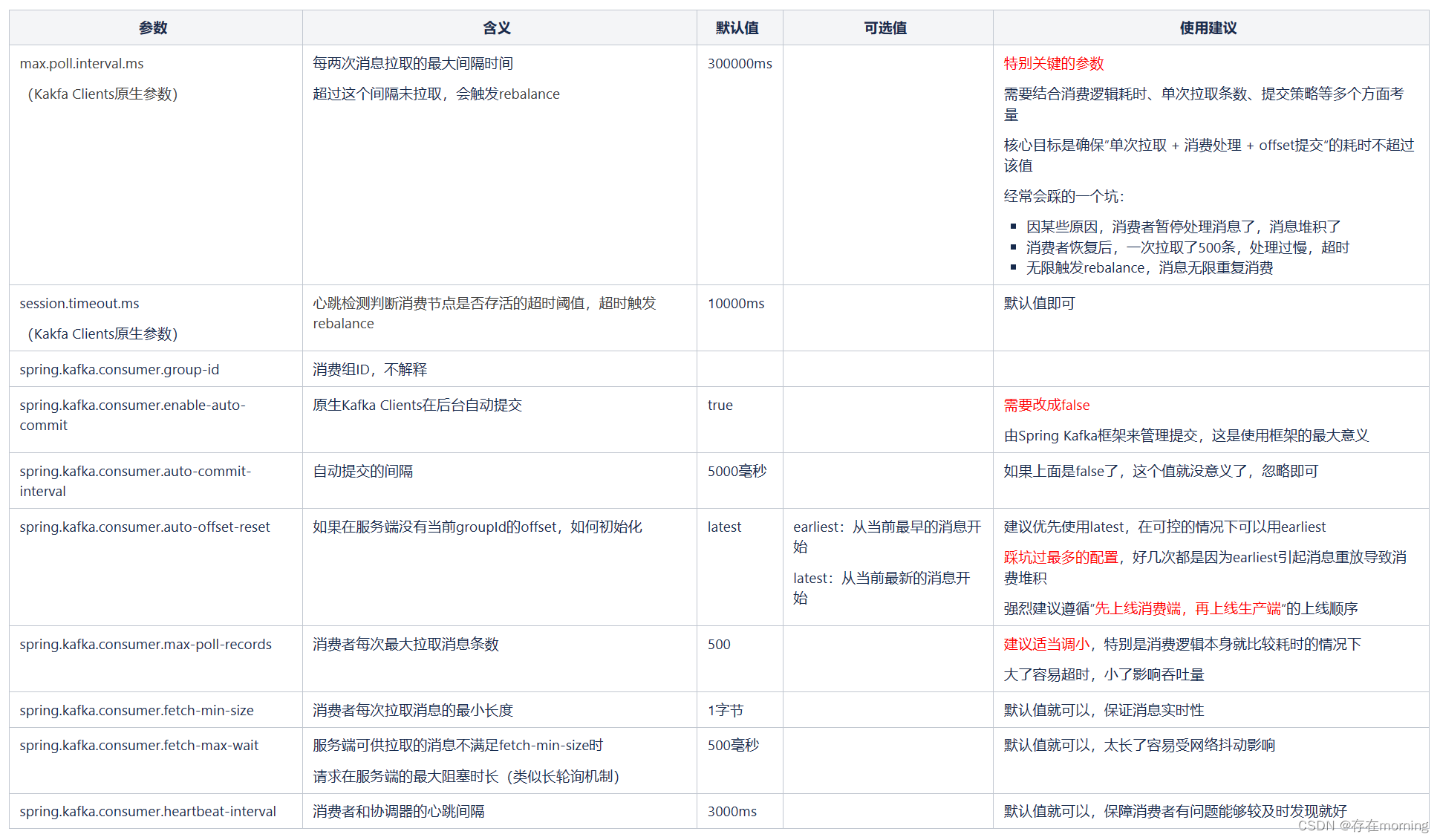
问题解决
明确问题原因后,很好解决,把一批的最大拉取数量调小即可:
spring.kafka.consumer.max-poll-records
,比默认值500多小一点,调整完配置上线后就解决了,消费延迟很快降低到0了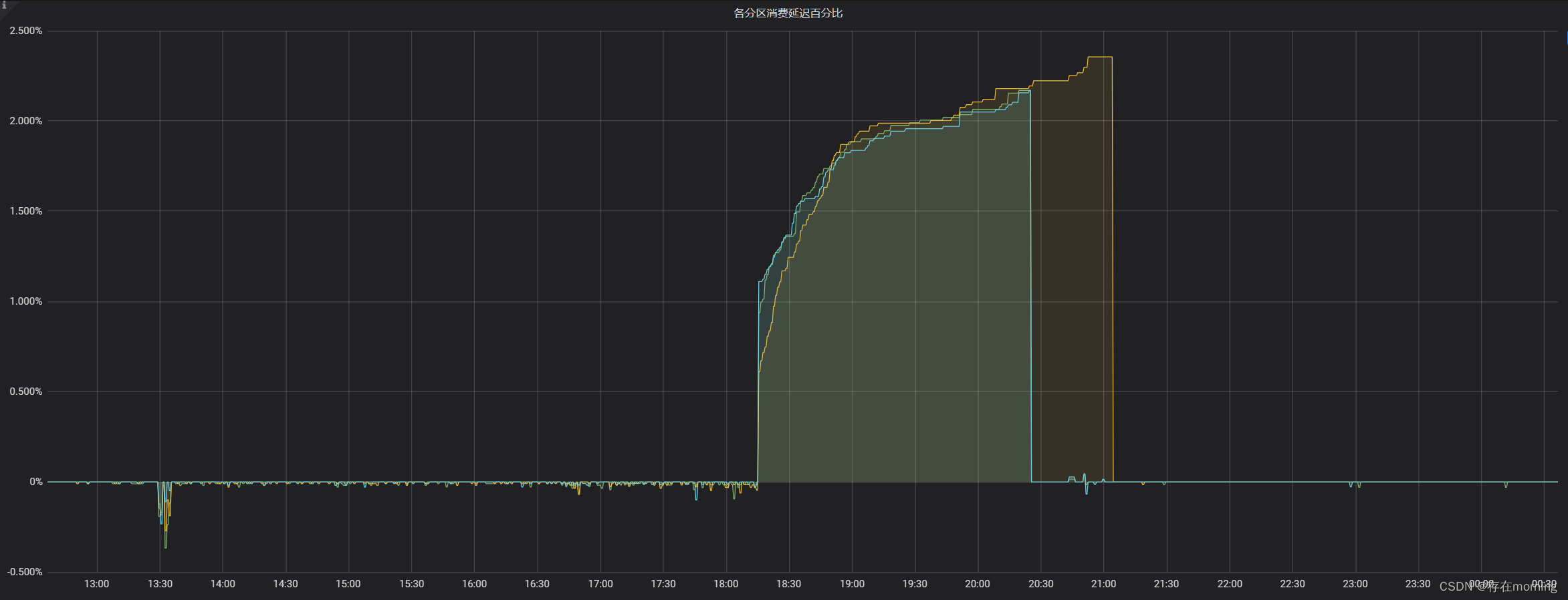
总结一下
照例总结一下,虽然基础服务的一些中间件一般都由基础架构部门维护,但还是要对这些中间件的配置和使用要有所了解,这样出了问题才能快速定位问题、解决问题,避免影响线上稳定性
本文转载自: https://blog.csdn.net/sinat_33087001/article/details/132200359
版权归原作者 存在morning 所有, 如有侵权,请联系我们删除。
版权归原作者 存在morning 所有, 如有侵权,请联系我们删除。