
一、介绍生态圈相关组件
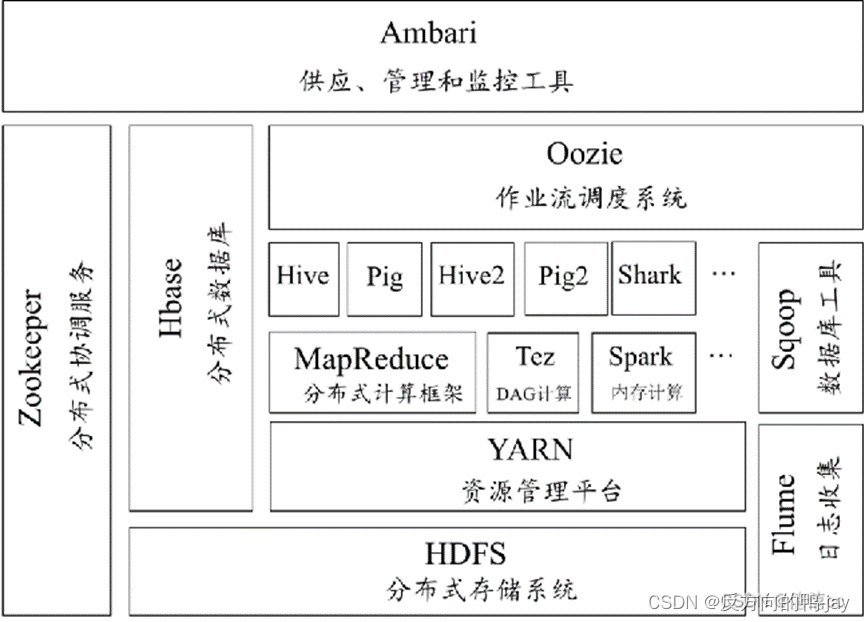
1、HDFS分布式文件系统:HDFS是Hadoop的分布式文件系统,它是Hadoop生态系统中的核心项目之一,是分布式计算中数据存储管理基础。
2、MapReduce分布式计算框架:是一种计算模型,用于大规模数据集(大于1TB)的并行运算
3、Yarn资源管理框架:是Hadoop2.0中的资源管理器,它可为上层应用提供统一的资源管理和调度。
4、sqoop数据迁移工具:sqoop是一款开源的数据导入导出工具,主要用于在Hadoop与传统的数据库间进行数据的转化。
5、Mahout数据挖掘算法库:开源项目,它提供了一些可扩展的机器的机器学习领域经典算法的实现,在帮助开发人员方便快捷地创建智能应用程序。
6、Hbase分布式存储系统:是HBase是Google Bigtable克隆版,它是一个针对对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。
7、Zookeeper分布式协作服务:是一个分布式的,开放源码的分布式应用程序协调服务,
是Google的Chubby一个开源的实现,是Hadoop和HBase的重要组件。
8、Hive基于Hadoop的数据仓库:Hive是基于Hadoop的一个分布式数据仓库工具,可以将结构化的数据文件映射为一张数据库表,将SQL语句转换为MapReduce任务进行运行。
Flume日志收集工具:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力
二、详细介绍MapReduce的特点及运行架构
优缺点
优点:
1.易于编程 — 底层实现了接口
2.良好的扩展性 — 可增加节点
3.高容错性 — 保证任务的完成
4.适合PB级别以上的海量数据的离线处理 — 可实现服务器内节点并发工作
缺点:
1.不擅长实时计算 — 无法做到毫秒或者秒级内返回结果
2.不擅长流式计算 — MR 的输入数据集是静态的,流式计算的输入数据是动态的
3.不擅长DAG(有向图)计算 — 不建议使用,会导致MR一直写入到磁盘造成大量磁盘IO,影响性能
整体架构流程
MR 主要分成 map 和 reduce 两个阶段,核心思想就是“分而治之”。Mapper主要负责“拆分”,即把复杂的任务分解成若干个“小任务”进行处理。 Reduce 阶段是将 Mapper 阶段得到的结果进行汇总。

总结: map先分reduce后合(分而治之)
(1) 首先待计算的数据在client端生成切片(逻辑上对数据进行划分) , 生成的切片个数对应着要启动多少个MapTask程序进行Map阶段的计算。
(2) 多个MapTask程序是并行运行的,互不相干。
(3) 在每个MapTask中对数据的处理要考虑到很多细节, 是否有分区, 如何排序, 数据如何写磁盘等。
(4) 多个MapTask计算完成后,每个MapTask都会有输出的数据。
(5) 会根据分区的个数决定启动多少个ReduceTask(逻辑上来说), 实际上是 启动多少个ReduceTask就会生成多少个分区。
(6) 每个ReduceTask会到每个MapTask中拷贝自己所要处理的数据,说白了就是对应的分区的数据。
(7) 每个ReduceTask最终也会输出最后的结果。
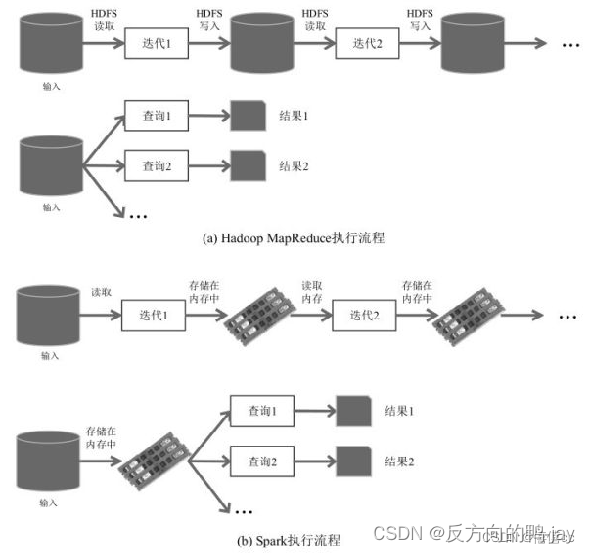
三、详细介绍spark的特点,并与MapReduce作对比说明区别


四、熟练掌握Linux操作命令并演示说明



五、冷备 温备 热备
热备:在数据库运行状态下进行备份,备份时不需要停止数据库的服务。但是,由于备份时需要访问数据库文件,因此备份过程中可能会影响数据库的正常运行。
冷备:在关闭数据库的情况下进行备份。这种备份方式不影响数据库的正常运行,但是需要停止数据库的服务。适用于小型数据量、备份频繁及服务器空闲时进行备份。
温备:同样是在数据库运行中进行的,但是会对当前数据库的操作有所影响,备份时仅支持读操作,不支持写操作。
六、数据类型 (举例说明)
- 1.结构化数据:
- 结构化数据是以表格、行和列的形式组织的数据,通常存储在关系型数据库中。这些数据具有明确定义的模式和结构,例如,数据库中的表格、电子表格中的数据或日志文件中的数据。
- 2.半结构化数据:
- 半结构化数据不像结构化数据那样具有明确定义的模式,但它包含了标记或标签,使得数据可以被更容易地解释和处理。例如,XML、JSON和HTML文件通常属于半结构化数据。
- 3.非结构化数据:
- 非结构化数据是没有明确结构或组织的数据,通常以文本、图像、音频和视频的形式存在。这种类型的数据需要更复杂的处理和分析技术,以提取有用的信息。社交媒体帖子、电子邮件、照片和视频文件是非结构化数据的例子。
- 4.时序数据:
- 时序数据是按照时间顺序记录的数据,通常包括时间戳。这种类型的数据常见于传感器数据、日志数据、股票市场数据和气象数据等领域。
- 5.空间数据:
- 空间数据包括与地理位置相关的信息,通常使用地理坐标系统(如经度和纬度)来表示。这种类型的数据在地理信息系统(GIS)应用中广泛使用,用于地图制图、位置分析和导航。
- 6.图数据:
- 图数据以节点和边的形式组织,用于表示实体之间的关系。社交网络、知识图谱和互联网上的网页链接都可以表示为图数据。
- 7.文本数据:
- 文本数据包括各种文本文档,如文章、评论、新闻文章和书籍。文本数据分析可以用于自然语言处理(NLP)任务,如情感分析、文本分类和信息提取。
- 8.多媒体数据:
多媒体数据包括图像、音频和视频等形式的媒体内容。处理和分析多媒体数据通常需要特殊的技术,如图像处理和音频处理
版权归原作者 反方向的鸭-jay 所有, 如有侵权,请联系我们删除。