
本文主要为了完成平日作业,并进一步加深对算法的理解。也希望对来访的读者有所帮助。
一、什么是Kmeans算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
二、Kmeans算法的意义
K-means算法通常可以应用于维数、数值都很小且连续的数据集,比如:从随机分布的事物集合中将相同事物进行分组。它的应用有许多,比如**文档分类器**、**乘车数据分析**、**IT警报的自动化聚类**等许多方面。
三、Kmeans算法代码解析
1.关键概念
欧式距离公式:(计算其他点到不同中心点的距离,判断属于哪个簇类)
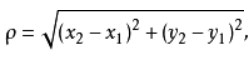
2.大致思路
(1)从N个数据文档(样本)随机选取K个数据文档作为质心(聚类中心)。
本文在聚类中心初始化实现过程中采取在样本空间范围内随机生成K个聚类中心。
(2)对每个数据文档测量其到每个质心的距离,并把它归到最近的质心的类。
(3)重新计算已经得到的各个类的质心。
(4)迭代(2)~(3步直至新的质心与原质心相等或小于指定阈值,算法结束。
本文采用所有样本所属的质心都不再变化时,算法收敛。
3.对照每行代码的详细注解
function [U, E_in] = KMeans(data, K)
[N, d] = size(data);
% init U
sampleIds = randsample(1:N, K, false); //从n个点中随机选择三个点作为中心点
U = data(sampleIds, :); //以这三个点为中心形成簇类
labels_u = zeros(N, 1); //初始换建立一个N行1列的零数组
stop = true;
while stop //把true复制给stop,需要一直循环
for i = 1:N //从第1个点一直到第n个点
x = data(i, :); //读取第1个数据放到X里面
% check label
label = 0; //初始化label为0,代表是第几个簇类
dist = 0; //初始化dist距离为0
for j = 1:K //计算到达三个中心点的距离,依次推断属于哪个簇类
tmp_dist = sum((x-U(j, :)).^2); //计算欧式距离,因比较大小,不用开根号也行
if label == 0 || tmp_dist < dist //如果是第一次计算lable=0或者此时的距离小于上一次计算出的距离
label = j; //当前的点暂时属于第j个聚类
dist = tmp_dist; //欧式距离更新为当前的更小值
end
end //循环结束
if labels_u(i) ~= label //如果第个i点不等于label
stop = false; //继续循环
end
labels_u(i) = label; //第个i点属于第label个簇类
end
if stop == true //退出循环
break;
end
%update U //更新中心点
new_U = zeros(K, d); //初始化中心点,并全部清零
labels_count = zeros(K, 1); //统计不同簇类的个数
for i = 1:N //遍历所有点
label = labels_u(i); //提取出簇类标志
new_U(label, :) = new_U(label, :) + data(i, :); //这行代码不太懂,所有标签及对应data数据之和
labels_count(label) = labels_count(label) + 1; //属于相同簇类的加起来
for i = 1:K%
new_U(i, :) = new_U(i, :)/labels_count(i); //初始化的中心点除以每个聚类里面总的个数
end
U = new_U; //用新的U来代替
end
E_in = 0;
for i = 1:N //N个点需要重新遍历
label = labels_u(i); //将label标签提取出来
u = U(label, :);
E_in = E_in + norm(data(i)-u); //每一个点跟中心的距离,所有的距离应该是欧式距离的和
end
E_in = E_in/N; //欧式距离的和除以N,每个点距离的举止,表示聚合的效果
end
四、总结
以上就是对于Kmeans算法每行代码详细注解的全部内容啦,希望对大家有所帮助,快快收藏,好好学习这个算法吧!我也很乐意与读者进行探讨!
本文转载自: https://blog.csdn.net/TaloyerG/article/details/123946300
版权归原作者 高垚淼 所有, 如有侵权,请联系我们删除。
版权归原作者 高垚淼 所有, 如有侵权,请联系我们删除。