
注意坑:
docker搭建Redis哨兵模式坑较多,请注意以下问题
- 注意: 下面有关ip的配置一定要写实际ip,不要用127.0.0.1和localhost
- 不管使用docker还是docker-compose,在搭建redis节点和哨兵节点时候一定要,指定Redis节点和哨兵节点在同一个网桥下。否则可能会出现哨兵监听不到redis节点的问,因为每一个docker容器都有自己的ip,所以会出现Sentinel监听不到Redis的问题
- 不同服务器之间的节点一定要在配置文件中指定,节点之间交互的地址 1. Redis节点使用 replica-announce-ip replica-announce-port2. Sentinel节点使用 sentinel announce-ip sentinel announce-port
- 关于Redis的端口映射问题,假如说我们使用6380映射Redis的端口的话。最好将Redis配置文件中的默认端口改成6380.使用外部6380映射内部6380.否则也可能会出现Senitnel监听不到Redis节点的问题
Redisson整合哨兵模式的坑:
1. 分布式锁Reidsson在 3.12.5 ---- 3.15.5 的版本在整合哨兵模式会狂喷一下日志,高版本3.17.5解决了这个问题,低版本使用3.12.4即可。
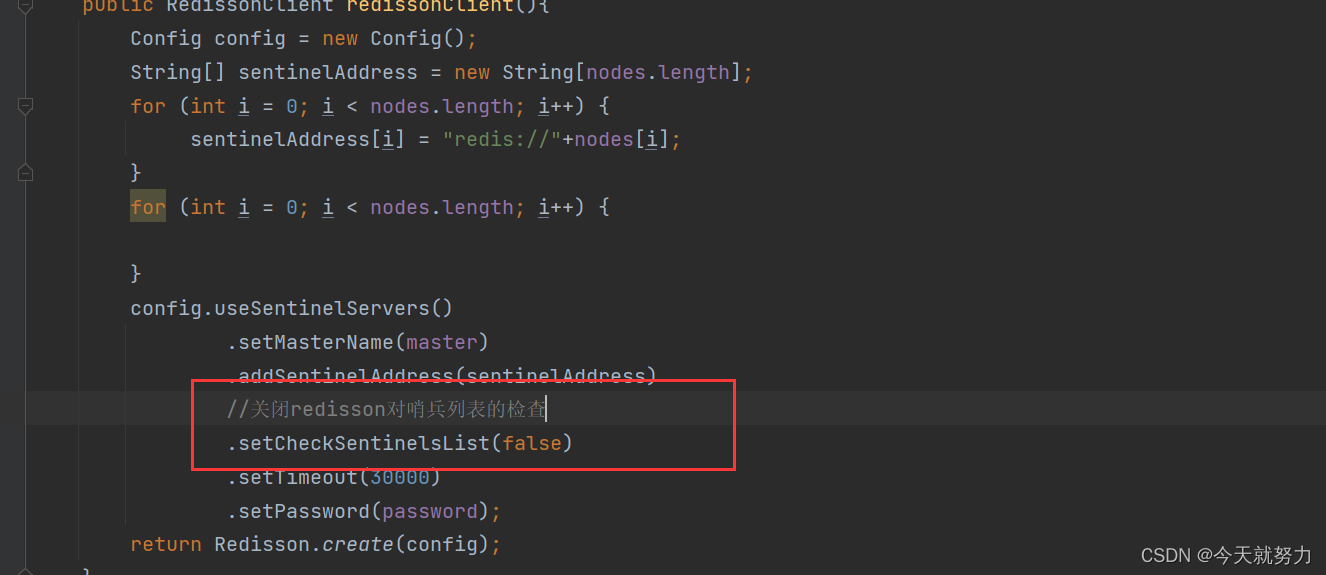
2. 关闭Redisson对集群列表的检查,否则即使有两个哨兵也会报错。


1. 安装docker和docker-compose
2. docker-compose搭建redis哨兵模式(一主二从二哨兵)
2.1启动redis的三个节点
2.1.1 下载redis.conf配置文件
因为docker启动redis是默认没有配置文件的。我们可以去github下载对应版本的redis.conf配置文件
配置文件详解:
#注释掉bind 127.0.0.1,使redis可以外部访问 bind 0.0.0.0 # 端口号 port 6381 #给redis设置密码 #requirepass red ##redis持久化 默认是no appendonly yes #开启protected-mode保护模式,需配置bind ip或者设置访问密码 #关闭protected-mode模式,此时外部网络可以直接访问 protected-mode no #是否开启集群 #cluster-enabled no #集群的配置文件,该文件自动生成 #cluster-config-file nodes.conf #集群的超时时间 #cluster-node-timeout 5000 #用守护线程的方式启动 daemonize no #防止出现远程主机强迫关闭了一个现有的连接的错误 默认是300 tcp-keepalive 300 #设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接 timeout 0 tcp-backlog 511 supervised no pidfile "/var/run/redis_6379.pid" #日志级别 (debug,verbose, notice, 和warning。生产环境下一般开启notice) loglevel notice #redis生成的日志(docker容器内的目录,不是宿主机的目录) logfile "/data/redis-s2.log" #默认数据库数量 databases 16 always-show-logo yes # RDB持久化策略(默认开启) #900秒后 有一个key变化就持久话 #300秒后 有10个key变化就持久话 #60秒后 有10000个key变化就持久话 save 900 1 save 300 10 save 60 10000 #yes : RDB快照保存失败后 客户端不可想redis写入,只可读 #no : 禁用此功能 stop-writes-on-bgsave-error yes # 保存 .rdb持久化文件时 是否使用LZF压缩 yes开启 no关闭 rdbcompression yes #是否检查rdb快照的完整性,损失大概 百分之十 的性能 rdbchecksum yes #rdb持久化生成的默认文件名 dbfilename "dump.rdb" #在未启用持久性的情况下删除复制使用的 RDB 文件。 #默认情况下,此选项被禁用,但是在某些环境中,出于法规或其他安全考虑, #RDB 文件应由 master 持久保存在磁盘上以提供副本,或由副本存储在磁盘上以加载它们以进行初始同步。 #尽快删除。请注意,此选项仅适用于同时禁用 AOF 和 RDB 持久性的实例,否则将被完全忽略。 #获得相同效果的另一种(有时是更好的)方法是在主实例和副本实例上使用无盘复制。然而,在副本的情况下,无盘并不总是一种选择。 rdb-del-sync-files no #redis的工作目录(持久化文件和日志生成后保存的目录) dir "/data" #redis节点用来通信使用的ip和端口 replica-announce-ip 127.0.0.1 replica-announce-port 6379 #当副本失去与主服务器的连接时,或者当复制仍在进行中时,副本可以以两种不同的方式进行操作: #1)如果副本服务陈旧数据设置为“是”(默认值)副本仍然会回复客户端请求,可能带有过期数据,或者如果这是第一次同步,数据集可能只是空的。 #2) 如果replica-serve-stale-data 设置为'no',则replica 将对所有类型的命令回复错误“SYNC with master in progress”, #但对INFO、replicaOF、AUTH、PING、SHUTDOWN、REPLCONF、角色、配置、订阅、取消订阅、订阅、取消订阅、发布、发布订阅、命令、发布、主机:和延迟。 replica-serve-stale-data yes #您可以配置副本实例以接受或不接受写入。 #就是主从复制中,slave节点是否可以写入数据(yes:不能写入;no:可以写入) replica-read-only yes #当使用无盘复制时,master 在开始传输之前等待一段可配置的时间(以秒为单位), #希望多个副本到达并且传输可以并行化。对于慢速磁盘和快速(大带宽)网络,无盘复制效果更好。 repl-diskless-sync no #启用无盘复制后,可以配置服务器等待的延迟,以便生成通过套接字将 RDB 传输到副本的子节点。 #因为一旦传输开始,就不可能为到达的新副本提供服务,新副本将排队等待下一次 RDB 传输,因此服务器等待延迟以让更多副本到达。 #延迟以秒为单位指定,默认为 5 秒。要完全禁用它,只需将其设置为 0 秒, repl-diskless-sync-delay 5 # In many cases the disk is slower than the network, and storing and loading # the RDB file may increase replication time (and even increase the master's # Copy on Write memory and salve buffers). # However, parsing the RDB file directly from the socket may mean that we have # to flush the contents of the current database before the full rdb was # received. For this reason we have the following options: # # "disabled" - Don't use diskless load (store the rdb file to the disk first) # "on-empty-db" - Use diskless load only when it is completely safe. # "swapdb" - Keep a copy of the current db contents in RAM while parsing # the data directly from the socket. note that this requires # sufficient memory, if you don't have it, you risk an OOM kill. repl-diskless-load disabled # Disable TCP_NODELAY on the replica socket after SYNC? # # If you select "yes" Redis will use a smaller number of TCP packets and # less bandwidth to send data to replicas. But this can add a delay for # the data to appear on the replica side, up to 40 milliseconds with # Linux kernels using a default configuration. # # If you select "no" the delay for data to appear on the replica side will # be reduced but more bandwidth will be used for replication. # # By default we optimize for low latency, but in very high traffic conditions # or when the master and replicas are many hops away, turning this to "yes" may # be a good idea. repl-disable-tcp-nodelay no # The replica priority is an integer number published by Redis in the INFO # output. It is used by Redis Sentinel in order to select a replica to promote # into a master if the master is no longer working correctly. # # A replica with a low priority number is considered better for promotion, so # for instance if there are three replicas with priority 10, 100, 25 Sentinel # will pick the one with priority 10, that is the lowest. # # However a special priority of 0 marks the replica as not able to perform the # role of master, so a replica with priority of 0 will never be selected by # Redis Sentinel for promotion. # # By default the priority is 100. replica-priority 100 # ACL LOG # # The ACL Log tracks failed commands and authentication events associated # with ACLs. The ACL Log is useful to troubleshoot failed commands blocked # by ACLs. The ACL Log is stored in memory. You can reclaim memory with # ACL LOG RESET. Define the maximum entry length of the ACL Log below. acllog-max-len 128 # Using an external ACL file # # Instead of configuring users here in this file, it is possible to use # a stand-alone file just listing users. The two methods cannot be mixed: # if you configure users here and at the same time you activate the exteranl # ACL file, the server will refuse to start. # # The format of the external ACL user file is exactly the same as the # format that is used inside redis.conf to describe users. # # aclfile /etc/redis/users.acl # Command renaming (DEPRECATED). # # ------------------------------------------------------------------------ # WARNING: avoid using this option if possible. Instead use ACLs to remove # commands from the default user, and put them only in some admin user you # create for administrative purposes. # ------------------------------------------------------------------------ # # It is possible to change the name of dangerous commands in a shared # environment. For instance the CONFIG command may be renamed into something # hard to guess so that it will still be available for internal-use tools # but not available for general clients. # # Example: # # rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52 # # It is also possible to completely kill a command by renaming it into # an empty string: # # rename-command CONFIG "" # # Please note that changing the name of commands that are logged into the # AOF file or transmitted to replicas may cause problems. ################################### 客户端 #################################### #客户端的最大链接 # maxclients 10000 ############################## 内存管理 ################################ #redis可以占用的内存 单位字节 #当达到内存限制时,Redis 将尝试根据选择的驱逐策略删除键 #maxmemory <bytes> # redis过期key的移除策略 #volatile-lru:从已设置过期时间的key集中,挑选最近最少使用的数据淘汰。 #volatile-ttl:从已设置过期时间的key集中,挑选将要过期的数据淘汰。 #volatile-random:从已设置过期时间的key集中,任意选择数据淘汰。 #volatile-lfu:从已设置过期时间的key集中,挑选使用频率最低的数据淘汰。 #allkeys-lru:从key集中,挑选最近最少使用的数据淘汰 #allkeys-lfu:从key集中,挑选使用频率最低的数据淘汰。 #allkeys-random:从key集中,(server.db[i].dict)任意选择数据淘汰 #noeviction:不进行移除。针对写操作,只是返回错误信息 maxmemory-policy noeviction #LRU、LFU 和最小 TTL 算法不是精确算法,而是近似算法(为了节省内存),因此您可以对其进行调整以提高速度或准确性。 #对于默认 Redis 将检查五个键并选择最近使用较少的一个,您可以使用以下配置指令更改样本大小。 #默认值 5 会产生足够好的结果。 10 非常接近真实的 LRU,但 CPU 成本更高。 3更快但不是很准确。 # maxmemory-samples 5 #从 Redis 5 开始,默认情况下,redis主从复制环境中,salve节点会忽略 maxmemory 设置 # 除非在发生 failover 后,slave此节点被提升为 master 节点。 #这意味着只有 master 才会执行过期删除策略。 #并且 master 在 删除键之后会对 所有slave 发送 DEL (删除)命令。 # replica-ignore-maxmemory yes #设置过期keys仍然驻留在内存中的比重,默认是为1,表示最多只能有10%的过期key驻留在内存中, #该值设置的越小,那么在一个淘汰周期内,消耗的CPU资源也更多,因为需要实时删除更多的过期key。 #所以该值的配置是需要综合权衡的。 # active-expire-effort 1 ############################# LAZY FREEING #################################### #针对redis内存使用达到 maxmemory,并设置有淘汰策略时,在被动淘汰键时,是否采用lazy free机制。 #因为此场景开启lazy free, 可能使用淘汰键的内存释放不及时,导致redis内存超用,超过maxmemory的限制。 lazyfree-lazy-eviction no #针对设置有TTL的键(过期时间),达到过期后,被redis清理删除时是否采用lazy free机制。此场景建议开启,因TTL本身是自适应调整的速度。 lazyfree-lazy-expire no #针对有些指令在处理已存在的键时,会带有一个隐式的DEL键的操作。 #如rename命令,当目标键已存在,redis会先删除目标键, #如果这些目标键是一个big key,那就会引入阻塞删除的性能问题。 #此参数设置就是解决这类问题,建议可开启。 lazyfree-lazy-server-del no #slave进行全量数据同步,slave在加载master的RDB文件前,会运行flushall来清理自己的所有数据, #该配置决定是否采用异常flush机制。如果内存变动不大,建议可开启。 #可减少全量同步耗时,从而减少主库因输出缓冲区爆涨引起的内存使用增长。 replica-lazy-flush no #当用 UNLINK 调用替换用户代码 DEL 调用并不容易时,也可以使用以下配置指令将 DEL 命令的默认行为修改为与 UNLINK 完全相同: lazyfree-lazy-user-del no # AOF持久化生成的文件名 appendfilename "appendonly.aof" #aof文件刷新的频率。有三种: #1.no 依靠OS进行刷新,redis不主动刷新AOF,这样最快,但安全性就差。 #2.always 每提交一个修改命令都调用fsync刷新到AOF文件,非常非常慢,但也非常安全。 #3.everysec 每秒钟都调用fsync刷新到AOF文件,很快,但可能会丢失一秒以内的数据。 appendfsync everysec #指定是否在后台aof文件rewrite期间调用fsync, #默认为no,表示要调用fsync(无论后台是否有子进程在刷盘)。 #Redis在后台写RDB文件或重写AOF文件期间会存在大量磁盘IO,此时,在某些linux系统中,调用fsync可能会阻塞。 no-appendfsync-on-rewrite no #aof文件增长比例,指当前aof文件比上次重写的增长比例大小。aof重写即在aof文件在一定大小之后, #重新将整个内存写到aof文件当中,以反映最新的状态(相当于bgsave)。这样就避免了,aof文件过大 #而实际内存数据小的问题(频繁修改数据问题)。 auto-aof-rewrite-percentage 100 #aof文件重写最小的文件大小,即最开始aof文件必须要达到这个文件时才触发, #后面的每次重写就不会根据这个变量了(根据上一次重写完成之后的大小).此变量仅初始化启动redis有效. #如果是redis恢复时,则lastSize等于初始aof文件大小。 auto-aof-rewrite-min-size 64mb # 指redis在恢复时,会忽略最后一条可能存在问题的指令。 #默认值yes。即在aof写入时,可能存在指令写错的问题,这种情况下,yes会log并继续,而no会直接恢复失败。 aof-load-truncated yes #在开启了这个功能之后,AOF重写产生的文件将同时包含RDB格式的内容和AOF格式的内容, #其中RDB格式的内容用于记录已有的数据,而AOF格式的内存则用于记录最近发生了变化的数据, #这样Redis就可以同时兼有RDB持久化和AOF持久化的优点 #(既能够快速地生成重写文件,也能够在出现问题时,快速地载入数据)。 aof-use-rdb-preamble yes ################################ LUA SCRIPTING ############################### #一个Lua脚本最长的执行时间,单位为毫秒,如果为0或负数表示无限执行时间,默认为5000 lua-time-limit 5000 ################################ REDIS 集群 ############################### #如果是yes,表示启用集群,否则以单例模式启动 # cluster-enabled yes #这不是一个用户可编辑的配置文件,这个文件是Redis集群节点自动持久化每次配置的改变,为了在启动的时候重新读取它 # cluster-config-file nodes-6379.conf #超时时间,集群节点不可用的最大时间。如果一个master节点不可到达超过了指定时间,则认为它失败了。 #注意,每一个在指定时间内不能到达大多数master节点的节点将停止接受查询请求 # cluster-node-timeout 15000 #如果设置为0,则一个slave将总是尝试升级为master。 #如果设置为一个正数,那么最大失去连接的时间是node timeout乘以这个factor。 # cluster-replica-validity-factor 10 #一个master和slave保持连接的最小数量(即:最少与多少个slave保持连接), #也就是说至少与其它多少slave保持连接的slave才有资格成为master # cluster-migration-barrier 1 #如果设置为yes,这也是默认值,如果key space没有达到百分之多少时停止接受写请求。 #如果设置为no,将仍然接受查询请求,即使它只是请求部分key # cluster-require-full-coverage yes # 此选项设置为yes时,可防止从设备尝试对其进行故障转移master在主故障期间。 然而,仍然可以强制执行手动故障转移 # cluster-replica-no-failover no # 是否允许集群在宕机时读取 # cluster-allow-reads-when-down no ########################## docker集群/NAT支持 ######################## # 宣布服务IP # cluster-announce-ip 10.1.1.5 #宣布服务端口 # cluster-announce-port 6379 #宣布集群总线端口 # cluster-announce-bus-port 6380 ################################## SLOW LOG ################################### #决定要对执行时间大于多少微秒(microsecond,1秒 = 1,000,000 微秒)的查询进行记录 slowlog-log-slower-than 10000 # 它决定 slow log 最多能保存多少条日志, slow log 本身是一个 FIFO 队列,当队列大 #小超过 slowlog-max-len 时,最旧的一条日志将被删除,而最新的一条日志加入到 slow log ,以此类推。 slowlog-max-len 128 # 能够采样不同的执行路径来知道redis阻塞在哪里。这使得调试各种延时问题变得简单, #设置一个毫秒单位的延时阈值来开启延时监控。 latency-monitor-threshold 0 # By default all notifications are disabled because most users don't need # this feature and the feature has some overhead. Note that if you don't # specify at least one of K or E, no events will be delivered. notify-keyspace-events "" ############################### ADVANCED CONFIG ############################### # 哈希在条目数量较少且最大条目不超过给定阈值时使用内存高效数据结构进行编码。可以使用以下指令配置这些阈值。 #ziplist最大条目数 hash-max-ziplist-entries 512 #ziplist单个条目value的最大字节数 hash-max-ziplist-value 64 # ziplist列表最大值,默认存在五项: # -5:最大大小:64 Kb <——不建议用于正常工作负载 # -4:最大大小:32 Kb <——不推荐 # -3:最大大小:16 Kb <——可能不推荐 # -2:最大大小:8 Kb<——很好 # -1:最大大小:4 Kb <——好 # 正数意味着存储最多 _exactly_ 该数量的元素 # 正数意味着每个列表节点最多存储_exactly_该数量的元素。性能最高的选项通常是 -2(8 Kb 大小)或 -1(4 Kb 大小) list-max-ziplist-size -2 # 一个quicklist两端不被压缩的节点个数。0: 表示都不压缩。这是Redis的默认值, # 1: 表示quicklist两端各有1个节点不压缩,中间的节点压缩。3: 表示quicklist两 # 端各有3个节点不压缩,中间的节点压缩。 list-compress-depth 0 #set集合仅在一种情况下具有特殊编码:当集合仅由字符串组成时,这些字符串恰好是 64 位有符号整数范围内的基数为 10 的整数。 #以下配置设置设置了集合大小的限制,以便使用这种特殊的内存节省编码。 set-max-intset-entries 512 # 与哈希和列表类似,排序集也经过特殊编码以节省大量空间。仅当排序集的长度和元素低于以下限制时,才使用此编码: zset-max-ziplist-entries 128 zset-max-ziplist-value 64 #value大小 #小于等于hll-sparse-max-bytes使用稀疏数据结构(sparse), #大于hll-sparse-max-bytes使用稠密的数据结构(dense) hll-sparse-max-bytes 3000 # Streams单个节点的字节数,以及切换到新节点之前可能包含的最大项目数。 stream-node-max-bytes 4kb stream-node-max-entries 100 # 主动重新散列每100毫秒CPU时间使用1毫秒,以帮助重新散列主Redis散列表(将顶级键映射到值 activerehashing yes # 对客户端输出缓冲进行限制可以强迫那些不从服务器读取数据的客户端断开连接,用来强制关闭传输缓慢的客户端。 client-output-buffer-limit normal 0 0 0 #对于slave client和MONITER client,如果client-output-buffer一旦超过256mb,又或者超过64mb持续60秒,那么服务器就会立即断开客户端连接 client-output-buffer-limit replica 256mb 64mb 60 #对于pubsub client,如果client-output-buffer一旦超过32mb,又或者超过8mb持续60秒,那么服务器就会立即断开客户端连接 client-output-buffer-limit pubsub 32mb 8mb 60 # 客户端查询缓冲区累积新命令。 默认情况下,它被限制为固定数量,以避免协议失步(例如由于客 # 户端中的错误)将导致查询缓冲区中的未绑定内存使用。 但是,如果您有非常特殊的需求,可以在 # 此配置它,例如我们巨大执行请求 # client-query-buffer-limit 1gb # 在Redis协议中,批量请求(即表示单个字符串的元素)通常限制为512 MB。 但是,您可以在此更改此限制 # proto-max-bulk-len 512mb # 默认情况下,hz设置为10.提高值时,在Redis处于空闲状态下,将使用更多CPU。范围介于1到500之间, # 大多数用户应使用默认值10,除非仅在需要非常低延迟的环境中将此值提高到100 hz 10 # 启用动态HZ时,实际配置的HZ将用作基线,但是一旦连接了更多客户端,将根据实际需要使用配置的HZ值的倍数 dynamic-hz yes # 当一个子进程重写AOF文件时,如果启用下面的选项,则文件每生成32M数据会被同步 aof-rewrite-incremental-fsync yes # 当redis保存RDB文件时,如果启用了以下选项,则每生成32 MB数据将对文件进行fsync。 这对于以递增 # 方式将文件提交到磁盘并避免大延迟峰值非常有用 rdb-save-incremental-fsync yes # Jemalloc background thread for purging will be enabled by default jemalloc-bg-thread yes # Generated by CONFIG REWRITE user default on nopass ~* +@all
2.1.2 配置工作目录
在我们linux下root目录下创建redis的工作目录
//创建三个目录 mkdir /root/redis/redis-node/redis-master mkdir /root/redis/redis-node/redis-slave-1 mkdir /root/redis/redis-node/redis-slave-2 //将我们下载好的redis.conf配置文件分别复制到 redis-master redis-slave-1 redis-slave-2 这三个文件中 cp redis.conf /root/redis/redis-node/redis-master cp redis.conf /root/redis/redis-node/redis-slave-1 cp redis.conf /root/redis/redis-node/redis-slave-2 #------------------------------修改redis.conf一下配置文件-------------------------------- #修改复制好的这三个配置文件,只需要修改一下配置即可 #三个配置文件要修改的除了端口(port),其他部分一样 bind 0.0.0.0 protected-mode no #三个结点端口分别改成6379(主) 6380(从) 6381(从) port 6379 dir /data logfile "/data/redis.log" #本机ip或者域名。 replica-announce-ip 127.0.0.1 #redis的端口 replica-announce-port 6379 //注意三个节点的redis.conf配置文件都需要修改,
2.1.3 编写docker-compose.yml 文件
在/root/redis/redis-node编写docker-compose.yml文件
version: "3.0" #docker-compose的版本号 networks: #网络配置 redis-sentinel-1: driver: bridge services: #所有服务的入口 固定写法 redis-master: #自定义服务名 image: redis:6.0.16 #我们所需要运行的镜像,没有的话,会自定为我们下载 container_name: redis-master #镜像运行后的容器名,自定义 ports: - 6379:6379 #宿主机的6379映射容器内部的6379端口 volumes: #目录挂载 。分号 : 右边代表容器内部的目录,分号左边表示宿主机的目录, - /root/redis-other/redis-node/redis-master/redis.conf:/redis.conf - /root/redis-other/redis-node/redis-master/data:/data command: bash -c "redis-server /redis.conf" #容器启动后,运行的命令 networks: - redis-sentinel-1 redis-slave-1: image: redis:6.0.16 container_name: redis-slave-1 ports: - 6380:6380 volumes: - /root/redis-other/redis-node/redis-slave-1/redis.conf:/redis.conf - /root/redis-other/redis-node/redis-slave-1/data:/data command: bash -c "redis-server /redis.conf --slaveof 192.168.136.128 6379" depends_on: - redis-master networks: - redis-sentinel-1 redis-slave-2: image: redis:6.0.16 container_name: redis-slave-2 ports: - 6381:6381 volumes: - /root/redis-other/redis-node/redis-slave-2/redis.conf:/redis.conf - /root/redis-other/redis-node/redis-slave-2/data:/data command: bash -c "redis-server /redis.conf --slaveof 192.168.136.128 6379" depends_on: - redis-master networks: - redis-sentinel-1
2.2 编写sentinel 哨兵两个节点
2.2.1 创建sentinel工作的目录
//root目录下创建这两个文件 /root/redis-other/sentinel-node/redis-sentinel-1 /root/redis-other/sentinel-node/redis-sentinel-2
2.2.2 编写sentinel.conf配置文件
sentinel.conf配置文件,将编写好的sentinel.conf配置文件分别复制到上面新建的两个工作目录中,注意修改port端口(sentinel1的端口:26379) (sentinel2的端口:26380)
#哨兵的端口 port 26379 #工作路径 dir "/data" # 指明日志文件名 logfile "/data/sentinel.log" # master表示 哨兵监控master服务的别名 # 192.168.136.128 6379 表示 master地址 #2 表示只需要2个sentinel投票即可故障转移 sentinel monitor mymaster 192.168.136.128 6379 1 #这两项配置非常重要,不同哨兵的节点通信的地址 sentinel announce-ip 127.0.0.1 sentinel announce-port 26379
2.2.3 编写snetinel的docker-compose
注意:讲以下配置放到上面编写的docker-compose.yml文件中,一起运行
redis-sentinel-1: image: redis:6.0.16 container_name: redis-sentinel-1 ports: - 26379:23679 volumes: - /root/redis-other/sentinel-node/redis-sentinel-1/data:/data - /root/redis-other/sentinel-node/redis-sentinel-1:/etc command: bash -c "redis-sentinel /etc/sentinel.conf && chmod 777 /etc/sentinel.conf" depends_on: - redis-master - redis-slave-1 - redis-slave-1 networks: - redis-sentinel-1 redis-sentinel-2: image: redis:6.0.16 container_name: redis-sentinel-2 ports: - 26380:23680 volumes: - /root/redis-other/sentinel-node/redis-sentinel-2/data:/data - /root/redis-other/sentinel-node/redis-sentinel-2:/etc/sentinel.conf command: bash -c "redis-sentinel /etc/sentinel.conf && chmod 777 /etc/sentinel.conf" depends_on: - redis-master - redis-slave-1 - redis-slave-1 networks: - redis-sentinel-1
2.2.3运行所有节点
在我们docker-compose所存在的目录下,使用 docker-compose up -d 启动。
此后redis的日志,配置文件,持久化生成的文件等都会映射到我们的/root/redis/redis-node每个节点的目录中
接下我们只需要停掉master节点,等待一会儿查看,sentinel是否为我们自动实现故障转移。
注意:
哨兵模式假如配置在多台服务器上,注意开放redis和哨兵的端口开放redis和哨兵工作目录,所有用户可读写的权限。开放redis持久化生成的文件,所有用户可读写的权限//然后使用工具连接上我们的redis //使用 info replication 查看会打印以下信息 /* "# Replication role:master //表示当前是master节点 connected_slaves:2 //表示自己有两个slave节点 slave0:ip=192.168.144.1,port=6381,state=online,offset=4825,lag=0 //slave节点1的信息 slave1:ip=192.168.144.1,port=6380,state=online,offset=4825,lag=0 //slave节点2的信息 master_replid:f048caa9f1378398126c8ac9fccfc5f1a80a7452 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:4825 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:4825 " */
3. docker-compose搭建redis集群模式(二主二从)
1. 创建redis的工作目录
1.1 在root目录创建六个redis的工作目录,因为我们有启动六个节点(三主三从)//穿件文件夹的命令 mkdir /root/redis-cluster/redis-1 redis-2 redis-3 redis-4 redis-5 redis-61.2 复制六个redis.conf配置文件,到我们的工作目录中//复制六份redis.conf配置文件,到上面我们创建的六个文件夹中 //修改redis.conf配置文件中的以下部分 #每个节点的端口,我们六个节点端口分别是(6379 6380 6381 6382 6383 6384) port 6379 #表示打开集群模式 cluster-enabled yes #节点的配置文件名,启动后会自动生成到你配置文件 dir ./ 命令指定的目录中 cluster-config-flie nodes-6379.conf #设置节点的关联时间(毫秒),超过该时间slave认为master宕机,自动升级 cluster-node-timeout 15000 #集群节点ip #这个IP需要特别注意一下,如果要对外提供访问功能,需要填写宿主机的IP,如果不填或者填写docker分配的IP,可能会导致部分集群节点在跳转时失败。 #整合springboot时候我们用这个IP 加端口 cluster-announce-ip 192.168.136.1282. 编写docker-compose.yml
在/root/redis-cluster 目录编写docker-compose文件,内容即下。注意:
redis官方规定最少启动三个master节点。不然搭建不了集群version: "3.0" services: redis-1: image: redis:6.2.1 container_name: redis-1 ports: - 6379:6379 - 16379:16379 #集群总线端口 默认就是redis端口加1000,每个节点都要打开 volumes: - $PWD/redis-1/redis.conf:/redis.conf - $PWD/redis-1/data:/data command: redis-server /redis.conf redis-2: image: redis:6.2.1 container_name: redis-2 ports: - 6380:6380 - 16380:16380 #集群总线端口 默认就是redis端口加1000,每个节点都要打开 volumes: - $PWD/redis-2/redis.conf:/redis.conf - $PWD/redis-2/data:/data command: redis-server /redis.conf redis-3: image: redis:6.2.1 container_name: redis-3 ports: - 6381:6381 - 16381:16381 #集群总线端口 默认就是redis端口加1000,每个节点都要打开 volumes: - $PWD/redis-3/redis.conf:/redis.conf - $PWD/redis-3/data:/data command: redis-server /redis.conf redis-4: image: redis:6.2.1 container_name: redis-4 ports: - 6382:6382 - 16382:16382 #集群总线端口 默认就是redis端口加1000,每个节点都要打开 volumes: - $PWD/redis-4/redis.conf:/redis.conf - $PWD/redis-4/data:/data command: redis-server /redis.conf redis-5: image: redis:6.2.1 container_name: redis-5 ports: - 6383:6383 - 16383:16383 #集群总线端口 默认就是redis端口加1000,每个节点都要打开 volumes: - $PWD/redis-5/redis.conf:/redis.conf - $PWD/redis-5/data:/data command: redis-server /redis.conf redis-6: image: redis:6.2.1 container_name: redis-6 ports: - 6384:6384 - 16384:16384 volumes: - $PWD/redis-6/redis.conf:/redis.conf - $PWD/redis-6/data:/data command: redis-server /redis.conf3. 启动集群
- redis集群是一个无中心化的集群,他们个个节点之间可以相互访问。
- 可以使用 redis-cli -c -p 6379命令连接集群。
- 使用 cluster nodes 命令查看所有的节点的信息。
//启动所有节点,在你docker-compose存在的目录使用该命令 docker-compose up -d //随便进入一个节点的容器内 docker exec -it redis-1 /bin/bash //使用下面命令串联集群然他们产生关系。 //1 表示一台主机一台从机,正好三组(三主三从) //后面跟所有节点的ip和端口。 //注意:(这里的端口一定要用实际地址,不要用127.0.0.1和localhost) redis-cli --cluster create --cluster-replicas 1 192.168.136.128:6379 192.168.136.128:6380 192.168.136.128:6381 192.168.136.128:6382 192.168.136.128:6383 192.168.136.128:6384 //#显示 [OK] All 16384 slots covered. 表示启动成功 //#显示Waiting for the cluster to join 。。。 一直卡住证明没有开放集群总线端口 //#redis集群是一个无中心化的集群,他们个个节点之间可以相互访问。 //可以使用 redis-cli -c -p 6379命令连接集群。 //使用 cluster nodes 命令查看所有的节点的信息。
卡槽的概念:
- redis集群的所有master节点都负责一部分的卡槽,所有master节点的卡槽加起来总共等于16384个。我们保存到redis的数据都属于这16384个卡槽中。
- 集群模式下,我们保存数据的时候,集群会使用 CRC16%16384 来计算key属于那个卡槽,而后判断该卡槽属于那个master的,然后将命令交给该msaster处理
- 我们可以在redis.conf配置文件中设置,cluster-require-full-coverage 为yes,那么集群中有一组主节点和从节点挂了,整个集群都不可使用。为no集群可使用,只是该master管理的插槽不可使用。
- 使用cluster nodes 命令查看个个节点的信息,图片中红框表示每个master节点的插槽值
集群的常用命令:
cluster keyslot <key> 查看该key在那个插槽中。
cluster countkeysinslot <插槽的值> 查看该插槽中有几条数据。(只能擦看自己的插槽)

注意: 线上实际部署推荐这样,不然服务器宕机 主从全挂了

本文转载自: https://blog.csdn.net/qq_49059667/article/details/123987075
版权归原作者 今天就努力 所有, 如有侵权,请联系我们删除。
版权归原作者 今天就努力 所有, 如有侵权,请联系我们删除。