
kafka的一些概念
- 分组:同一组内的consumer对于队列里的消息只会有一个consumer消费一次(一对一),不同组的consumer对队列里的消息会同时消费(一对多)。
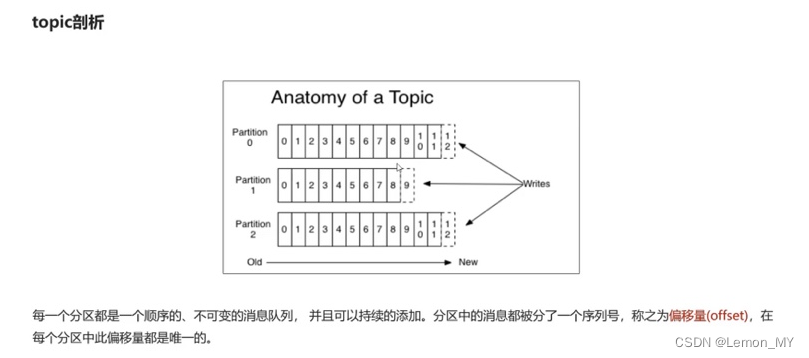
- 分区:kafka将同一队列的消息存在不同服务器上该队列中(消息分区,避免消息集中到一个服务器上)。
- 偏移量:分区中的消息的序列号,在每个分区中此偏移量都是唯一的。
- 分区策略:轮询策略(按顺序轮流将每条数据分配到每个分区中),随机策略(每次都随机的将消息分配到每个分区),按键保存策略(生产者发送数据的时候,可以指定一个key,计算这个key的hashcode值,按照hashcode的值对不同消息进行存储)。
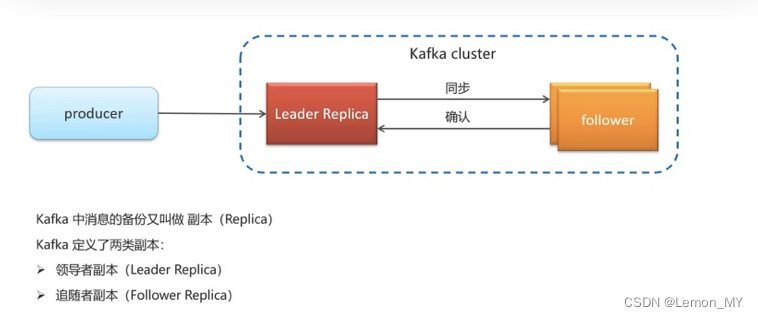
- 备份:kafka中消息的备份又叫做副本,kafka定义了两种副本:领导者副本(leader),追随者副本(follower)。
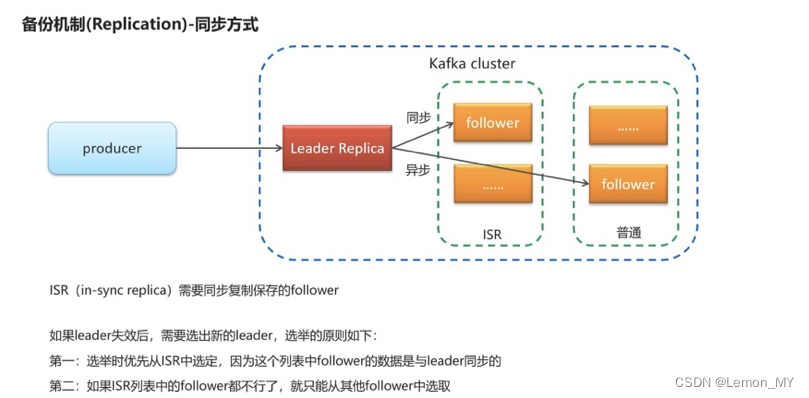
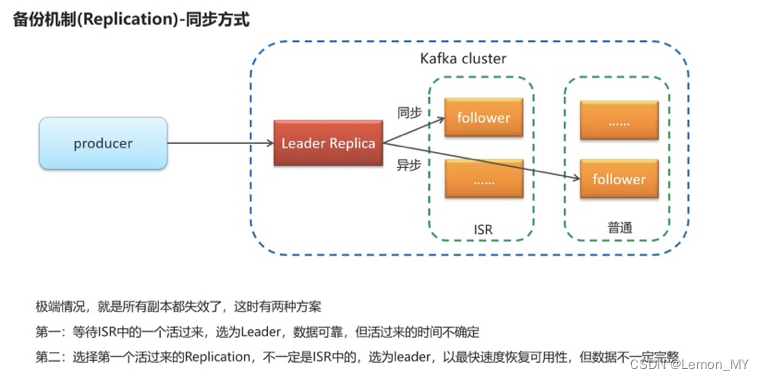
- 备份机制:同步方式,第一种ISR选定方式具有高可靠性,第二种其他follower方式具有高可用性。
- 发送消息方式:同步方式和异步的差别在于异步加上一个回调函数,即加上了回调函数的就是异步发送消息的方式。
- 消息确认机制:通过配置文件中ack的值配置。

- 消息重试次数:通过配置文件中retries的值配置。
- 消息压缩:通过配置文件中的compression-type的值配置。

- 消息有序性:topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。
- 提交偏移量:通过配置文件中enable-auto-commit的值配置手动提交和自动提交。kafka不会像其他JMS队列那样需要得到消费者的确认,消费者可以使用kafka来追踪消息在分区的位置(偏移量)。消费者会往一个叫做 consumer offset的特殊主题发送消息,消息里包含了每个分区的偏移量。如果消费者发生崩溃或有新的消费者加入群组,就会触发再均衡(把消息分区重新均衡的分配给所有可用的消费者,保证大家一起消费)。

配置文件
spring:
kafka:
bootstrap-servers:192.168.101.125:9092
producer:
retries:0
batch-size:16KB
buffer-memory:32MB
acks:1
key-serializer:org.apache.kafka.common.serialization.StringSerializer
value-serializer:org.apache.kafka.common.serialization.ByteArraySerializer
properties:
linger.ms:5
consumer:
# 消费者需要在自己的配置文件里设置为true
enable:false
enable-auto-commit:false
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# 批量拉取时的最大拉取数量
max-poll-records:1000
key-deserializer:org.apache.kafka.common.serialization.StringDeserializer
value-deserializer:org.apache.kafka.common.serialization.ByteArrayDeserializer
# 默认group-id为应用名称
group-id: ${spring.application.name}
topics:
command: msg_command
offline-download: dev_websocket_unDownFile
依赖坐标
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency>
生产者
// 配置文件中设置了key的序列化器StringDeserializer和value的序列化器为ByteArrayDeserializer@AutowiredprivateKafkaTemplate<String,byte[]> kafkaTemplate;@Value("${spring.kafka.topics.offline-download}")privateString topic;// 这里发送的参数是字节类型,因为配置文件中设置了value的序列化器为ByteArrayDeserializer(对象类型的消息通常用json来传输,对象->json字符串->字节数组)
kafkaTemplate.send(topic,JsonUtils.serialize(OfflineDownload.builder().fileId(id).unDown(false).userId(userId).build()).getBytes()).addCallback(success ->// 消息发送成功
log.debug("kafka sending success, topic:{}, body:{}",
topic,JsonUtils.serialize(OfflineDownload.builder().fileId(id).unDown(false).userId(userId).build())), failure ->// 消息发送失败
log.error("kafka sending failure, topic:{}, body:{}",
topic,JsonUtils.serialize(OfflineDownload.builder().fileId(id).unDown(false).userId(userId).build())));
消费者
@KafkaListener(
topics ={"${spring.kafka.topics.offline-download}",},
containerFactory ="stringBytesKafkaFactory")publicvoidreceiveUnDownFileMessage(List<ConsumerRecord<String,byte[]>> records,Acknowledgment ack){debugLogMessageSize(records);List<OfflineDownload> unDownFileMessageDtoList =newArrayList<>();for(ConsumerRecord<String,byte[]> consumerRecord : records){try{// 将json数组转成json字符串String msgStr =newString(consumerRecord.value());// json字符串转成对象OfflineDownload unDownFileMessageDto =JsonUtils.deserialize(msgStr,OfflineDownload.class);
unDownFileMessageDtoList.add(unDownFileMessageDto);}catch(Exception e){errorLogMessage(consumerRecord, e,false);}debugLogMessage(consumerRecord,false);}try{WebSocketServer.dealUnDownFileMessage(unDownFileMessageDtoList);
ack.acknowledge();}catch(CommitFailedException ce){errorLog(ce, ack);}catch(Exception e){errorLog(e, ack);}}
// 消费对象key是string,value是baye[],因为配置文件中设置了key的序列化器StringDeserializer和value的序列化器为ByteArrayDeserializer@KafkaListener(
topics ={"${spring.kafka.topics.command}"},
containerFactory ="stringBytesKafkaFactory")publicvoidreceiveCommandByteMessage(List<ConsumerRecord<String,byte[]>> records,Acknowledgment ack){if(log.isDebugEnabled()){
log.debug("从kafka拉取事件数据{}条", records.size());}List<byte[]> byteMessage =newArrayList<>();for(ConsumerRecord<String,byte[]> consumerRecord : records){
byteMessage.add(consumerRecord.value());if(log.isDebugEnabled()){
log.debug("topic:{}, key:{}, bytes:{}",
consumerRecord.topic(),
consumerRecord.key(),ByteBufUtil.hexDump(consumerRecord.value()));}}try{
mqCommandMessageService.dealCommandMessageBatch(byteMessage);
ack.acknowledge();if(log.isDebugEnabled()){
log.debug("提交偏移量,提交时间:{}",System.currentTimeMillis());}}catch(Exception e){
log.error("处理连接事件异常", e);
ack.nack(0,5*1000L);}}
注:ack.acknowledge()用来确认消息,ack.nack()会确认第一个参数偏移量之前的消息,抛弃后续消息重新返回到队列中。第二个参数时间后再次poll查询未消费消息。
本文转载自: https://blog.csdn.net/Lemon_MY/article/details/129078402
版权归原作者 Lemon_MY 所有, 如有侵权,请联系我们删除。
版权归原作者 Lemon_MY 所有, 如有侵权,请联系我们删除。