
DataHub调研&数据血缘
1. DataHub? 阿里的数据工具datahub?
回答: 不是
DataHub是由Linkedin开源的,官方喊出的口号为:The Metadata Platform for the Modern Data Stack - 为现代数据栈而生的元数据平台。官方网站A Metadata Platform for the Modern Data Stack | DataHub。目的就是为了解决多种多样数据生态系统的元数据管理问题,它提供元数据检索、数据发现、数据监测和数据监管能力,帮助大家解决数据管理的复杂性。
DataHub基于Apache License 2开源,采用基于推送的数据收集架构(当然也支持pull拉取的方式),能够持续收集变化的元数据。当前版本已经集成了大部分流行数据生态系统接入能力,包括但不限于:Kafka, Airflow, MySQL, SQL Server, Postgres, LDAP, Snowflake, Hive, BigQuery。
源码仓库地址:
- GitHub - linkedin/datahub: The Metadata Platform for the Modern Data Stack 该仓库包含DataHub前端和后端服务的完整源码。(DataHub采用先进的前后端分离架构)
- https://github.com/linkedin/datahub-gma 该仓库包含DataHub元数据搜索和发现服务GMA
当前支持的数据栈列表:
数据源名称版当前支持状态
Athena支持
BigQuery支持
Delta Lake计划支持
Druid支持
Elasticsearch支持
Hive支持
Hudi计划支持
Iceberg支持
Kafka Metadata支持
MongoDB支持
Microsoft SQL Server支持
MySQL Oracle PostreSQL支持
Redshift支持
s3支持
Snowflake支持
Spark/Databricks部分支持
Trino FKA Presto支持
市面上常见的元数据管理系统有如下几个,后面章节进行比对:
a) linkedin datahub
b) apache atlas
c) lyft amundsen
2. 主要功能
DataHub是端到端的元数据发现工具,可以帮助数据管理者挖掘其公司数据的价值。
端到端搜索和发现
1)在数据库、数据湖、BI平台、ML特征存储、工作流配置等数据资产中进行[元数据集中查询搜索]
比如:在DataHub里面搜索"health",从所有的元数据(BigQuery数据集、DataHub Tags/Users等)中,得到了所有相关结果,可以在结果中,点击查看相关的结果。
2)通过跨平台、数据集、管道的[血缘关系追踪],轻松理解数据的端到端旅程
3)通过线性血缘图,快速获取相关实体的上下文
4)获取数据集准确性和相关性的确切信息
比如:DataHub针对流行的数据仓库平台提供数据集合的详细信息浏览和实用信息统计,让数据从业者更容易理解数据的形态。
构造坚实的文档和标签基础
1)通过API或DataHub UI获取并维护公司的知识库
随着我们日常操作中定义和用例的丰富,DataHub可以轻松地更新和维护文档。除了通过GMS管理文档外,DataHub通 过UI界面提供丰富的文档和外部支持链接操作界面。
2)通过API或DataHub UI创建和定义新的标签(tag)
在DataHub中可以通过GraphQL API轻松的创建和添加任何实体标签,这样随着时间的推移,实体的属性回越来越丰富。当有一天我们想要查看某一标签的相关实体信息时,只需要在标签位置点击该标签,就会将所有相关的实体数据 列出来。
触手可及的数据治理
1) 快速将资产所有权分配给用户或用户组
2) 使用策略管理细粒度访问控制
DataHub管理员可以创建相应的策略,来定义谁可以在哪些资源上执行什么样的活动。在指定策略时,同时管理员还可以进行如下指定操作:
- 平台型策略 - 最高级别的DataHub平台权限,比如用户管理、组管理和策略管理等
- 资源型策略 - 指定资源类型,比如数据集、看板、管道等
- 权限策略 - 选择权限范围集合,比如编辑用户、编辑文档、编辑链接等
- 用户或组策略 - 分配相关的用户或租;比如可以直接将策略分配给资源使用的用户,而不必太关注他属于哪个组
元数据质量和使用分析
通过DataHub可以对元数据进行深度挖掘。DataHub提供的分析视图可以清晰的展示元数据相关的操作信息,比如用户权限分配的频繁度、本周活动用户、常用的搜索条件及活动等。
3. 架构
Datahub的采用了model-first的架构理念,通过提供一个通用的元数据管理模型,再通过插件的方式集成各种数据平台,进行元数据的导入。整体的架构如下: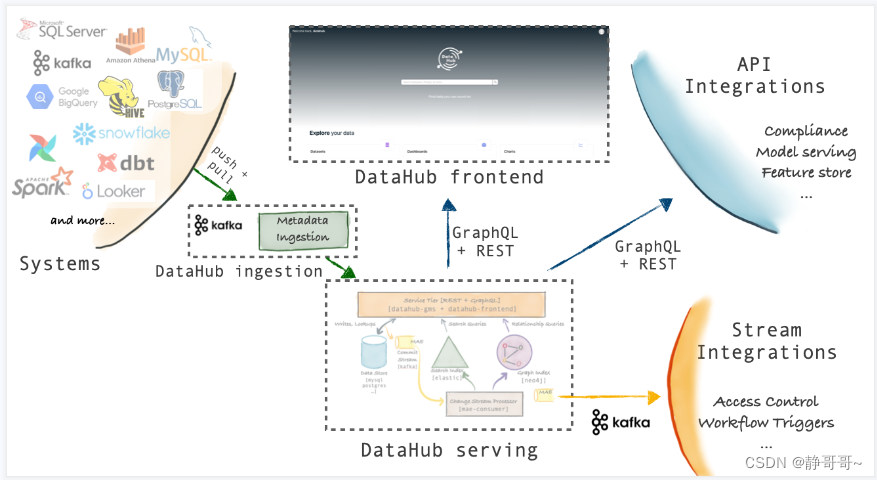
该架构的优点有2个:
- 元数据同步方式多样:可以使用Rest、GraphQL API-s、Avro API(从Kafka消费元数据)
- 数据平台的元数据更改可以实时的被同步到Datahub;在Datahub对元数据进行更改,可以实时的在数据平台进行更新
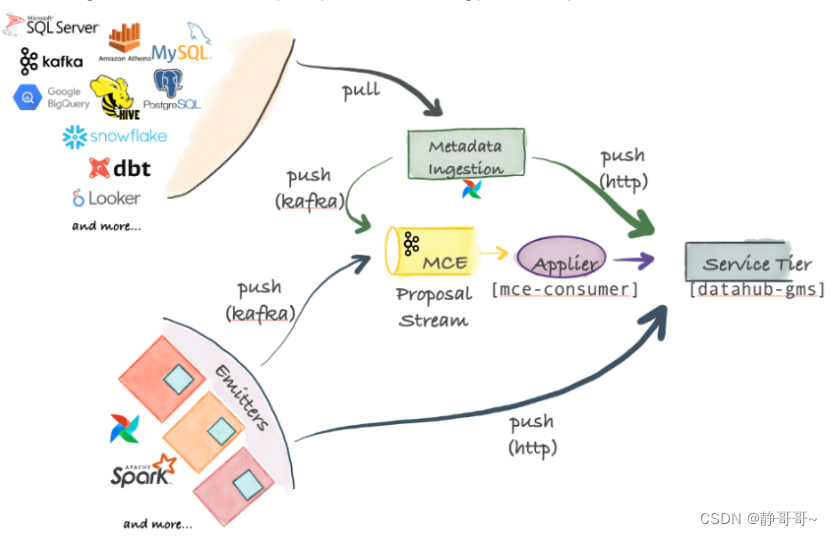
3.1 Ingestion Framework的架构
DataHub支持Push、Pull、同步和异步的元数据导入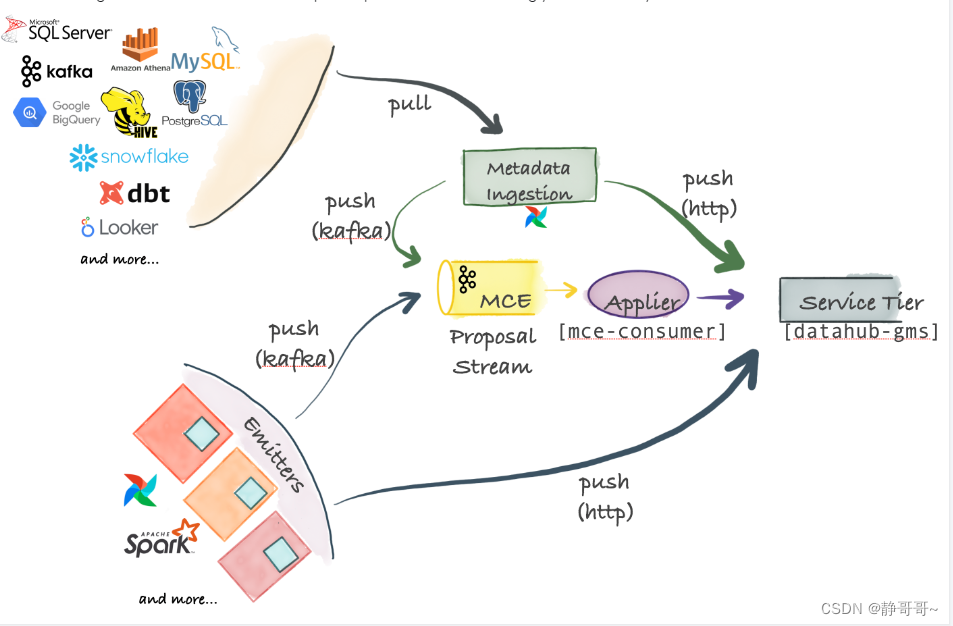
3.1.1 Metadata Change Event(MCE)
MCE是元数据导入的中心。各种数据平台的元数据的实时变更,发送到MCE(由Kafka负责),这是一种异步元数据同步。也可以直接将数据平台的元数据通过HTTP方式发送到Datahub,这是一种同步元数据导入
3.1.2 Pull-based Integration
Datahub通过基于Python的metadata-ingestion系统,从不同的数据平台Pull元数据。然后将元数据Push到Kafka(MCE)或直接Push到Datahub。还可以从Airflow调度系统同步元数据和血缘关系
3.1.3 Push-based Integration
可以向Kafka Push一个元数据变更事件(MCE),或通过HTTP Push数据到Datahub。DataHub还提供了一些简单的Python emitters ,将其集成到我们自己的系统中,以便获取我们自己的系统元数据
3.1.4 Applier(mce-consumer)
消费Kafka的元数据消息,并转换成Datahub的元数据储存格式,再同步到Datahub
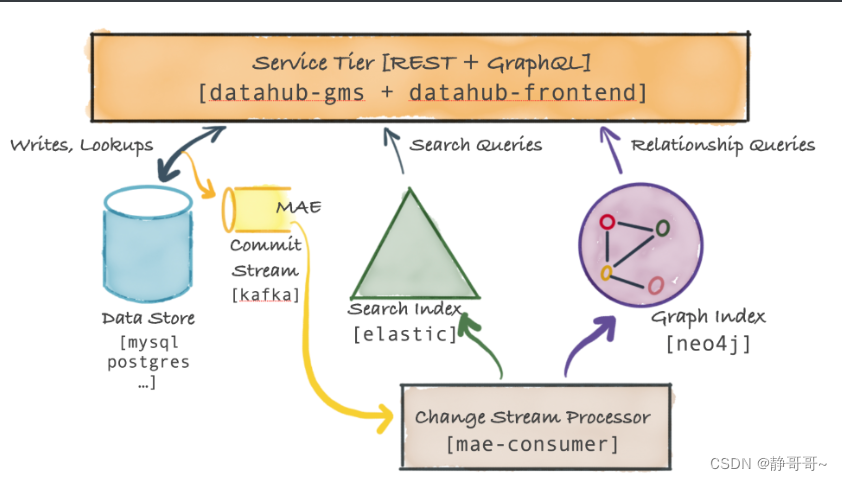
3.2 Datahub Serivce Tier架构
主要的服务是datahub-gms,它提供了一个REST API和一个GraphQL API对元数据进行CRUD操作,还提供支持二级索引、全文搜索的搜索查询,和血缘关系的图数据库查询API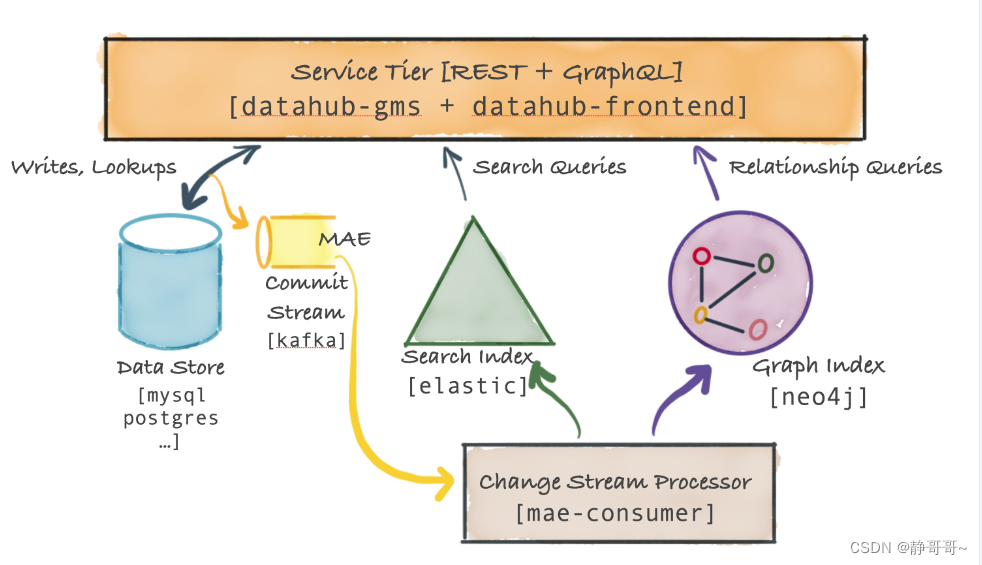
3.2.1 Metadata Storage
储存元数据的数据库,如Mysql、Postgresql、Couchbase
3.2.2 Metadata Commit Log Stream(MAE)
当将元数据更改更新到Metadata Storage中,Datahub Service Tier还会将该更改事件发送到Kafka
3.2.3 Metadata Index Applier (mae-consumer-job)
mae-consumer-job消费MAE(Kafka)中的数据,然后将更改事件流更新到elastic和neo4j,并生成相应的search index和graph index
3.2.4 Metadata Query Serving
基于主键的元数据读取,是从Data store数据库读取的。基于二级索引的元数据读取和全文搜索的元数据读取,是从elastic数据库读取的。基于血缘关系的图查询是从neo4j数据库读取的
4. 内部模块
4.1 Metadata Strore
用于储存Metadata 的Entities和Aspects(切面是一组属性的集合)。同时提供插入和查询API。其中储存由MySQL、Elasticsearch、Kafka负责。Rest API由Java Spring负责
4.2 Metadata Models

元数据模型采用PDL建模语言进行建模。分为Entity、Aspects、Relationships。
Entity:表示一个实体(如果数据库的一个表),每个实体实例都有一个唯一标识符;
Aspects:表示实体实例的术语、标签等;(DatasetProperties)包含一组描述数据集(Dataset)的属性(attributes)。切面可以在一组实体间共享,例如:属主(Ownership)是一个可以在多个拥有“拥有者(owners)”属性的实体间共享。
Relationships:表示不同实体实例的关系
下面是一个示例图,它由3种类型的实体(CorpUser、 Chart、 Dashboard)、2种类型的关系(OwnedBy、 Contains)和3种类型的元数据方面(OwnedInfo、 ChartInfo 和 DashboardInfo)组成。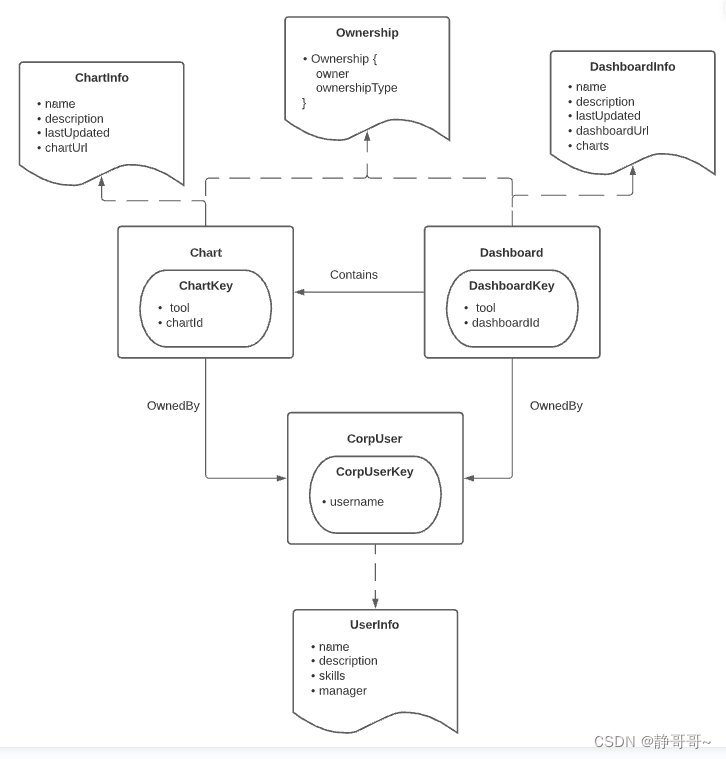
实体(Entities)的核心类型:
- Data Platform: 一种数据“平台”。也就是说,涉及处理、存储或可视化数据资产的外部系统。示例包括 MySQL、 Snowflake、 Redshift 和 S3。
- DataSet: 一组数据。表、视图、流、文档集合和文件都在 DataHub 上建模为“数据集”。数据集可以有标记、所有者、链接、术语表术语和附加到它们的描述。它们还可以具有特定的子类型,如“视图”、“集合”、“流”、“探索”等。示例包括 Postgres 表、 MongoDB 集合或 S3文件。
- Chart: 图表,从数据集派生的单个数据可视化。单个图表可以是多个仪表板的一部分。图表可以有标签、所有者、链接、术语表术语以及附加到它们的描述。示例包括超集或查看器图表。
- Dashboard: 用于可视化的图表集合。仪表板可以有标签、所有者、链接、术语表术语和描述附加到它们上面。示例包括 Superset 或 Mode Dashboard。
- Data Job,Task: 处理数据资产的可执行作业,其中“处理”意味着消耗数据、生成数据或两者兼而有之。数据作业可以有标签、所有者、链接、术语表术语以及附加到它们的描述。它们必须属于单个数据流。示例包括 Airflow 任务。
- Data Flow(pipe line) : 数据作业的一个可执行集合,它们之间存在依赖关系,或者一个 DAG。数据作业可以有标签、所有者、链接、术语表术语以及附加到它们的描述。例子包括气流 DAG。
元数据模型不同实体间的关系: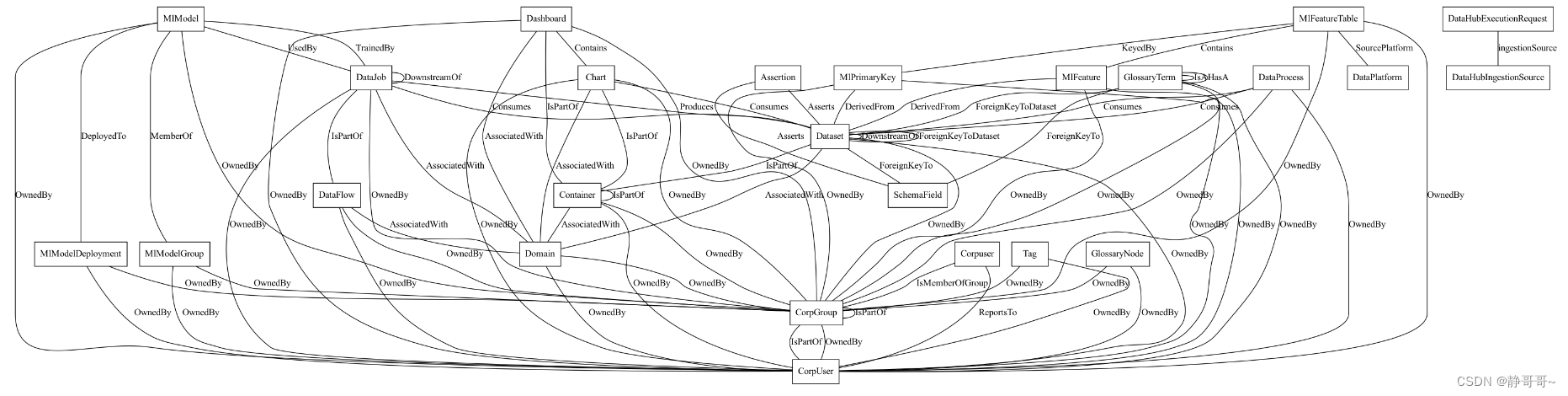
DataSets元数据模型
DataSets元数据模型支持由三部分组成:
- Data Platform (e.g. urn:li:dataPlatform:mysql)
- Name (e.g. db.schema.name)
- Env or Fabric (e.g. DEV, PROD, etc.) 完整的:
urn:li:dataset:(urn:li:dataPlatform:<platform>,<name>,ENV)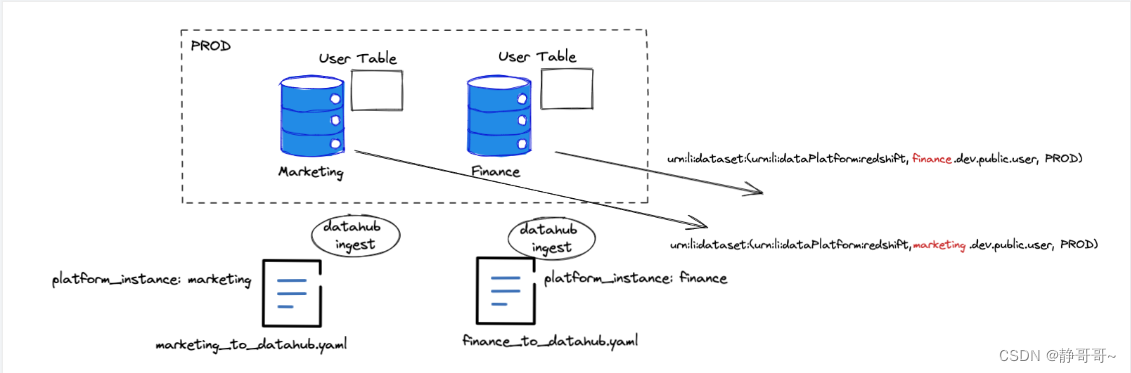
4.3 Ingestion Framework
元数据导入框架通过插件(python库)的方式,集成到Datahub系统。
可以从不同的数据平台将元数据,两种方式:
- 以Rest API直接导入,
- 将元数据生产到Kafka,再从Kafka消费导入到Datahub
元数据导入只需定义一个YAML文件,并执行datahub元数据导入命令
元数据摄取
元数据集成datahub支持push-based与pull-based两种方式:
push-based:直接是数据源系统在元数据发生变化时主动推送到datahub
pull-based:是连接到数据源通过批量或者增量的方式提取元数据的过程
datahub提供两种形式的元数据摄取:通过直接api调用或kafka流。前者适合离线,后者适合实时。
datahub的api基于rest.li,这是一种可扩展的,强类型的restful服务架构,已在linkedin上广泛使用。由于rest.li使用pegasus作为其接口定义,因此可以逐字使用上一节中定义的所有元数据模型。从api到存储需要多层转换的日子已经一去不复返了-api和模型将始终保持同步。
对于基于kafka的提取,预计元数据生产者将发出标准化的元数据更改事件(mce),其中包含由相应实体urn键控的针对特定元数据方面的建议更改列表。
对api和kafka事件模式使用相同的元数据模型,使我们能够轻松地开发模型,而无需精心维护相应的转换逻辑。
元数据服务
datahub旨在支持对大量元数据的四种常见查询类型:
- 面向文档的查询
- 面向图的查询
- 涉及联接的复杂查询
- 全文搜索
4.4 GraphQL API
GraphQL API提供了一个强类型的、面向Entiry的API,通过GraphQL API与储存的元数据进行交互

4.5 User Interface
4.5 用户管理
新用户帐户可以通过3种方式在 DataHub 上供应:
- 共享邀请链接
- 使用 OpenID 链接来配置单点登录(支持的有Azure AD, Okta, keycloak,Ping!, Google Identity)
- 静态凭证配置文件(仅自托管)单点登录

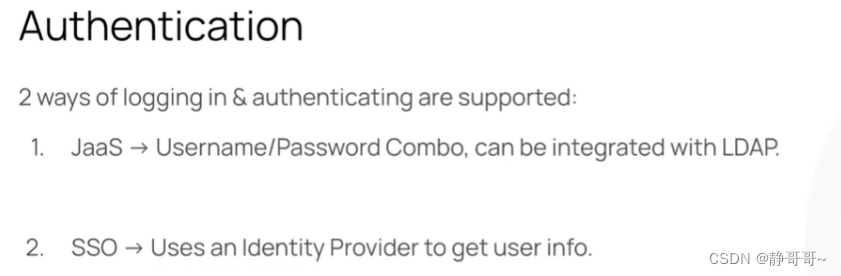
- 静态凭证配置文件(仅自托管)单点登录
5. 特性
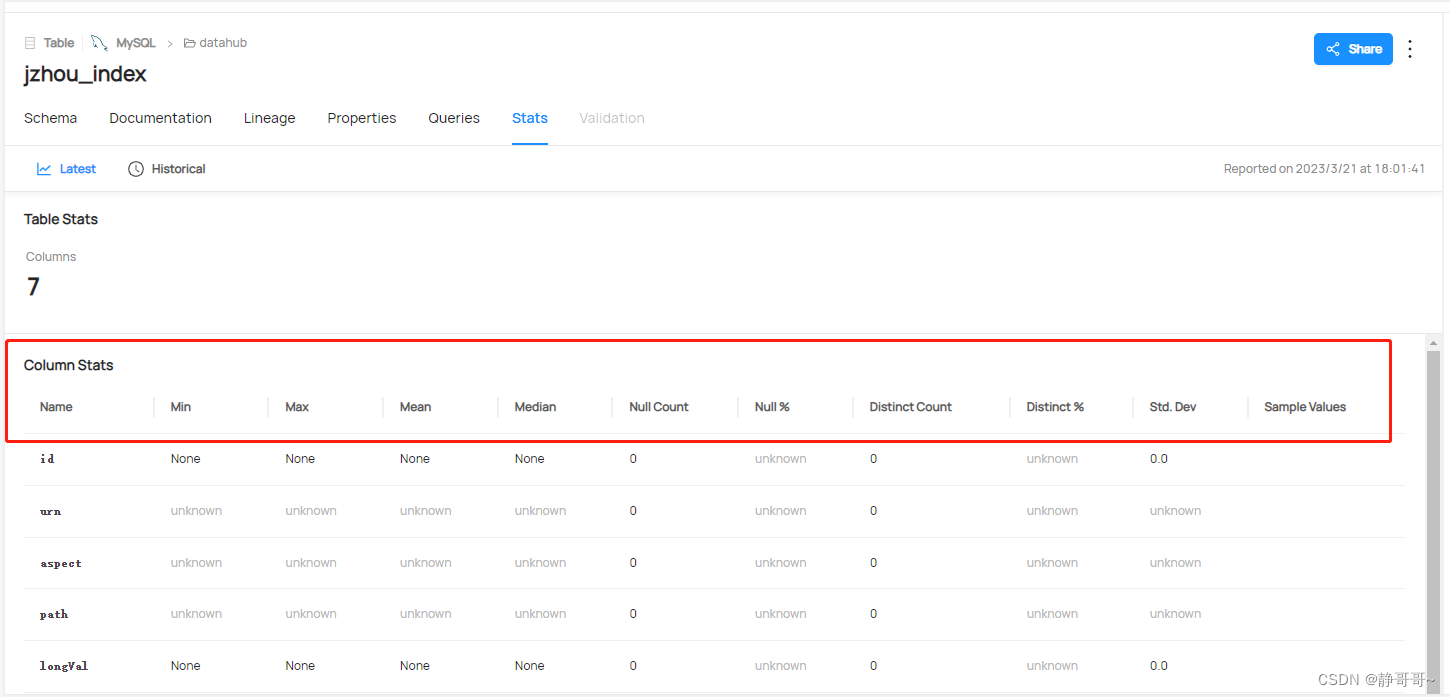
5.1 SQL分析
每个表的行和列计数对于每个列:
- 空值计数和比例
- 不同的数量和比例
- 最小值,最大值,平均值,中位数,标准差,一些分位数值
- 独特值的直方图或频率
5.2 数据血缘
DataHub 支持的数据血缘连接类型如下:
- 数据集到数据集
- 流水线谱系(数据集到作业到数据集dataset-to-job-to-dataset)
- 从仪表盘到图表的血统
- 图表到数据集的血缘
- Job-to-dataflow (dbt 血缘)
字段血缘支持不足 没有atlas对hive那么精细?
新版本支持了字段血缘,FineGrainedLineages可以加上下游字段对应: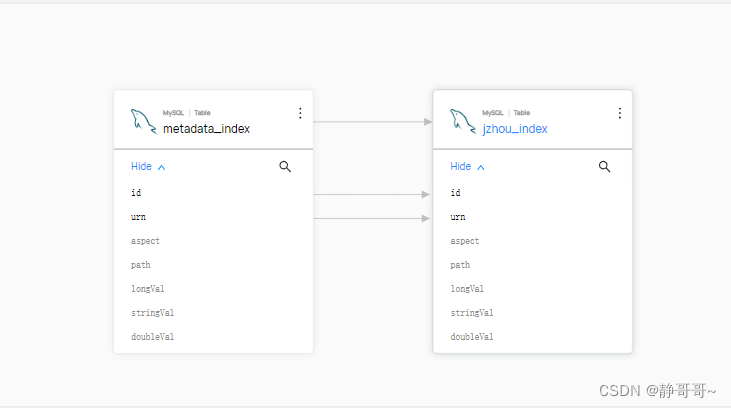
6. 安装
6.1 release版本
Data Hub v0.1.0-alpha Pre-release 2019-10-28 warehouse
LinkedIn开源出来的,原来叫做WhereHows 。经过一段时间的发展datahub于2020年2月在Github开源
VersionRelease DateLinksv0.10.02023-02-07Release Notes, View on GitHubv0.9.6.12023-01-31Release Notes, View on GitHubv0.9.62023-01-13Release Notes, View on GitHubv0.9.52022-12-23Release Notes, View on GitHubv0.9.42022-12-20Release Notes, View on GitHubv0.9.32022-11-30View on GitHubv0.9.22022-11-04View on GitHubv0.9.12022-10-31View on GitHubv0.9.02022-10-11View on GitHubv0.8.452022-09-23View on GitHubv0.8.442022-09-01View on GitHubv0.8.432022-08-09View on GitHubv0.8.422022-08-03View on GitHubv0.8.412022-07-15View on GitHubv0.8.402022-06-30View on GitHubv0.8.392022-06-24View on GitHubv0.8.382022-06-09View on GitHubv0.8.372022-06-09View on GitHubv0.8.362022-06-02View on GitHubv0.8.352022-05-18View on GitHubv0.8.342022-05-04View on GitHubv0.8.332022-04-15View on GitHubv0.8.322022-04-04View on GitHubv0.8.312022-03-17View on GitHubv0.8.302022-03-17View on GitHubv0.8.292022-03-10View on GitHubv0.8.282022-03-07View on GitHubv0.8.272022-02-23View on GitHub
6.2 安装步骤quickstart
# 下载源码包# https://github.com/linkedin/datahub官网下载最新版本,此次调研使用的0.10.0版本# 端口冲突,先将端口就行修改sed -i "s/18087/18081/g"`grep"18087" -lr .`# 创建一个虚拟环境
python3 -m venv tutorial-env
source tutorial-env/bin/activate
# 安装python环境wget https://www.python.org/ftp/python/3.8.2/Python-3.8.2.tgz
cd /usr/local/python3/Python-3.8.2
mkdir -p /usr/local/python3
yum install gcc
./configure --with-ssl --prefix=/usr/local/python3
make&&makeinstallln -s /usr/local/python3/bin/python3 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
# 开始安装环境
$ python3 -m pip install --upgrade pip wheel setuptools -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
$ python3 -m pip uninstall datahub acryl-datahub ||true# sanity check - ok if it fails
$ python3 -m pip install --upgrade acryl-datahub -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
$ datahub version
# 执行quickstart,需要互联网下载,会失败,这里直接指定到文件来start
datahub docker quickstart --quickstart-compose-file ./quickstart/docker-compose-without-neo4j.quickstart.yml
# 导入样例数据
python3 -m datahub check plugins
datahub docker ingest-sample-data
# 注入测试用例cd /home/jzhou/datahub-0.10.0/metadata-ingestion
datahub ingest -c ./examples/recipes/example_to_datahub_rest.dhub.yaml --preview
#定时调度的方式50 * * * datahub ingest -c /home/ubuntu/datahub_ingest/mysql_to_datahub.yml
# 获取urn信息
datahub get --urn "urn:li:dataset:(urn:li:dataPlatform:mysql,datahub.jzhou_index,PROD)" --aspect globalTags
# 获取urn的时间线
datahub timeline --urn "urn:li:dataset:(urn:li:dataPlatform:mysql,datahub.jzhou_index,PROD)" --category TAG --start 7daysago
# 看kafka中topic的信息
./kafka-topics --bootstrap-server localhost:9092 --list
# 如何检查搜索索引是否在 Elasticsearch 创建?curl http://localhost:9200/_cat/indices
导入样例数据的全过程:
(tutorial-env)[root@gs-server-13612 docker]# datahub docker ingest-sample-data
Downloading sample data...
Starting ingestion...
[2023-03-07 20:30:16,024] INFO {datahub.ingestion.run.pipeline:184} - Sink configured successfully. DataHubRestEmitter: configured to talk to http://localhost:8080
[2023-03-07 20:30:16,032] INFO {datahub.ingestion.run.pipeline:201} - Source configured successfully.
[2023-03-07 20:30:16,032] INFO {datahub.ingestion.source.file:246} - Reading file /tmp/tmpqpib79m0.json in FileReadMode.BATCH mode
Cli report:
{'cli_version':'0.10.0.3',
'cli_entry_location':'/home/jzhou/datahub-0.10.0/docker/tutorial-env/lib/python3.8/site-packages/datahub/__init__.py',
'py_version':'3.8.2 (default, Mar 3 2023, 04:13:42) \n[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)]',
'py_exec_path':'/home/jzhou/datahub-0.10.0/docker/tutorial-env/bin/python3',
'os_details':'Linux-3.10.0-1127.13.1.el7.x86_64-x86_64-with-glibc2.17',
'peak_memory_usage':'49.68 MB',
'mem_info':'49.68 MB'}
Source (file) report:
{'events_produced':99,
'events_produced_per_sec':15,
'entities':{'corpuser':['urn:li:corpuser:datahub', 'urn:li:corpuser:jdoe'],
'corpGroup':['urn:li:corpGroup:jdoe', 'urn:li:corpGroup:bfoo'],
'dataset':['urn:li:dataset:(urn:li:dataPlatform:kafka,SampleKafkaDataset,PROD)',
'urn:li:dataset:(urn:li:dataPlatform:hdfs,SampleHdfsDataset,PROD)',
'urn:li:dataset:(urn:li:dataPlatform:hive,SampleHiveDataset,PROD)',
'urn:li:dataset:(urn:li:dataPlatform:hive,logging_events,PROD)',
'urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_created,PROD)',
'urn:li:dataset:(urn:li:dataPlatform:hive,fct_users_deleted,PROD)',
'urn:li:dataset:(urn:li:dataPlatform:s3,project/root/events/logging_events_bckp,PROD)'],
'dataJob':['urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_123)',
'urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_456)'],
'dataFlow':['urn:li:dataFlow:(airflow,dag_abc,PROD)'],
'chart':['urn:li:chart:(looker,baz1)', 'urn:li:chart:(looker,baz2)'],
'dashboard':['urn:li:dashboard:(looker,baz)'],
'mlModel':['urn:li:mlModel:(urn:li:dataPlatform:science,scienceModel,PROD)'],
'tag':['urn:li:tag:Legacy', 'urn:li:tag:NeedsDocumentation'],
'dataPlatform':['urn:li:dataPlatform:couchbase',
'urn:li:dataPlatform:external',
'urn:li:dataPlatform:hdfs',
'urn:li:dataPlatform:hive',
'urn:li:dataPlatform:kafka',
'urn:li:dataPlatform:kusto',
'urn:li:dataPlatform:mongodb',
'urn:li:dataPlatform:teradata',
'urn:li:dataPlatform:snowflake',
'urn:li:dataPlatform:glue',
'... sampled of 27 total elements'],
'mlPrimaryKey':['urn:li:mlPrimaryKey:(test_feature_table_all_feature_dtypes,dummy_entity_1)',
'urn:li:mlPrimaryKey:(test_feature_table_all_feature_dtypes,dummy_entity_2)',
'urn:li:mlPrimaryKey:(test_feature_table_no_labels,dummy_entity_2)',
'urn:li:mlPrimaryKey:(test_feature_table_single_feature,dummy_entity_1)',
'urn:li:mlPrimaryKey:(user_features,user_name)',
'urn:li:mlPrimaryKey:(user_features,user_id)',
'urn:li:mlPrimaryKey:(user_analytics,user_name)'],
'mlFeature':['urn:li:mlFeature:(test_feature_table_all_feature_dtypes,test_BYTES_feature)',
'urn:li:mlFeature:(test_feature_table_all_feature_dtypes,test_DOUBLE_LIST_feature)',
'urn:li:mlFeature:(test_feature_table_all_feature_dtypes,test_DOUBLE_feature)',
'urn:li:mlFeature:(test_feature_table_all_feature_dtypes,test_FLOAT_feature)',
'urn:li:mlFeature:(test_feature_table_all_feature_dtypes,test_INT64_LIST_feature)',
'urn:li:mlFeature:(test_feature_table_all_feature_dtypes,test_INT64_feature)',
'urn:li:mlFeature:(test_feature_table_all_feature_dtypes,test_STRING_LIST_feature)',
'urn:li:mlFeature:(test_feature_table_all_feature_dtypes,test_STRING_feature)',
'urn:li:mlFeature:(test_feature_table_no_labels,test_BYTES_feature)',
'urn:li:mlFeature:(user_features,is_premium_user)',
'... sampled of 20 total elements'],
'mlFeatureTable':['urn:li:mlFeatureTable:(urn:li:dataPlatform:feast,test_feature_table_all_feature_dtypes)',
'urn:li:mlFeatureTable:(urn:li:dataPlatform:feast,test_feature_table_no_labels)',
'urn:li:mlFeatureTable:(urn:li:dataPlatform:feast,test_feature_table_single_feature)',
'urn:li:mlFeatureTable:(urn:li:dataPlatform:feast,user_features)',
'urn:li:mlFeatureTable:(urn:li:dataPlatform:feast,user_analytics)'],
'glossaryTerm':['urn:li:glossaryTerm:CustomerAccount', 'urn:li:glossaryTerm:SavingAccount', 'urn:li:glossaryTerm:AccountBalance'],
'glossaryNode':['urn:li:glossaryNode:ClientsAndAccounts'],
'container':['urn:li:container:DATABASE', 'urn:li:container:SCHEMA'],
'assertion':['urn:li:assertion:358c683782c93c2fc2bd4bdd4fdb0153'],
'query':['urn:li:query:test-query']},
'aspects':{'corpuser':{'corpUserInfo':2, 'corpUserStatus':1, 'status':2},
'corpGroup':{'corpGroupInfo':2, 'status':2},
'dataset':{'browsePaths':2,
'datasetProperties':5,
'ownership':7,
'institutionalMemory':6,
'schemaMetadata':7,
'status':7,
'upstreamLineage':6,
'editableSchemaMetadata':1,
'globalTags':1,
'datasetProfile':2,
'datasetUsageStatistics':1,
'container':1},
'dataJob':{'status':2, 'ownership':2, 'dataJobInfo':2, 'dataJobInputOutput':2},
'dataFlow':{'status':1, 'ownership':1, 'dataFlowInfo':1},
'chart':{'status':2, 'chartInfo':2, 'globalTags':1},
'dashboard':{'status':1, 'ownership':1, 'dashboardInfo':1},
'mlModel':{'ownership':1,
'mlModelProperties':1,
'mlModelTrainingData':1,
'mlModelEvaluationData':1,
'institutionalMemory':1,
'intendedUse':1,
'mlModelMetrics':1,
'mlModelEthicalConsiderations':1,
'mlModelCaveatsAndRecommendations':1,
'status':1,
'cost':1},
'tag':{'status':2, 'tagProperties':2, 'ownership':2},
'dataPlatform':{'dataPlatformInfo':27},
'mlPrimaryKey':{'status':7, 'mlPrimaryKeyProperties':7},
'mlFeature':{'status':20, 'mlFeatureProperties':20},
'mlFeatureTable':{'status':5, 'browsePaths':5, 'mlFeatureTableProperties':5},
'glossaryTerm':{'status':3, 'glossaryTermInfo':3, 'ownership':3},
'glossaryNode':{'glossaryNodeInfo':1, 'ownership':1, 'status':1},
'container':{'containerProperties':2, 'subTypes':2, 'dataPlatformInstance':2, 'container':1},
'assertion':{'assertionInfo':1, 'dataPlatformInstance':1, 'assertionRunEvent':1},
'query':{'queryProperties':1, 'querySubjects':1}},
'warnings':{},
'failures':{},
'total_num_files':1,
'num_files_completed':1,
'files_completed':['/tmp/tmpqpib79m0.json'],
'percentage_completion':'0%',
'estimated_time_to_completion_in_minutes': -1,
'total_bytes_read_completed_files':118861,
'current_file_size':118861,
'total_parse_time_in_seconds':0.0,
'total_count_time_in_seconds':0.0,
'total_deserialize_time_in_seconds':0.02,
'aspect_counts':{'datasetProfile':2,
'datasetUsageStatistics':1,
'containerProperties':2,
'subTypes':2,
'dataPlatformInstance':3,
'container':2,
'assertionInfo':1,
'assertionRunEvent':1,
'queryProperties':1,
'querySubjects':1},
'entity_type_counts':{'dataset':4, 'container':7, 'assertion':3, 'query':2},
'start_time':'2023-03-07 20:30:16.032389 (6.23 seconds ago)',
'running_time':'6.23 seconds'}
Sink (datahub-rest) report:
{'total_records_written':99,
'records_written_per_second':15,
'warnings':[],
'failures':[],
'start_time':'2023-03-07 20:30:16.021072 (6.24 seconds ago)',
'current_time':'2023-03-07 20:30:22.263320 (now)',
'total_duration_in_seconds':6.24,
'gms_version':'v0.10.0',
'pending_requests':0}
Pipeline finished successfully; produced 99 events in6.23 seconds.
6.3 build编译
整个工程是gradle ,编译需要指定一下仓库到阿里库上
# 修改:repositories.gradle 添加下面两行
maven { url "file:///F:/idea/gradle"}
maven { name "Alibaba"; url "https://maven.aliyun.com/repository/public"}# 中途失败需要链接外网VPN 下载部分包
7. 局限性
7.1 各个数据源的局限性
- Airflow仅仅支持version >= 2.0.2,datahub必须配置airflow hook ,支持datahub rest hook 与kafka-based hook
- Spark pipeline(DataJob)或者tasks(DataFlow),支持版本(2.2.0 - 2.4.8),3.1.2 and 3.2.0 测过但不能保证与其他数据源的融合情况
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IGajEJxH-1680588545388)(C:\Users\Gridsum\AppData\Roaming\Typora\typora-user-images\1678691435916.png)]](https://img-blog.csdnimg.cn/190baa8c4aba467db482d6de80b6b491.png)
- Clickhouse,列类型有限制,不支持带时区的聚合函数和日期时间
- Deltalake,提取标签必须开启S3的object/bucket tag
- Pulsar, version > 2.7
- 等等
8、补充
8.1 DataHub Domains, Tags, 和 Glossary Terms的区别?
- Tags(标签): 非正式的、松散控制的标签,作为搜索和发现的工具。资产可能有多个标记。没有正式的集中管理。
- Glossary Terms(术语): 一个带有可选层次结构的受控词表。术语通常用于为治理标准化叶级属性(即模型字段)的类型。例如(EMAIL _ PLAINTEXT)
- Domains(域): 一组顶级类别。通常与资产最相关的业务单元/学科保持一致。集中或分布式管理。每个数据资产的单域分配。
8.2 添加标签跟术语
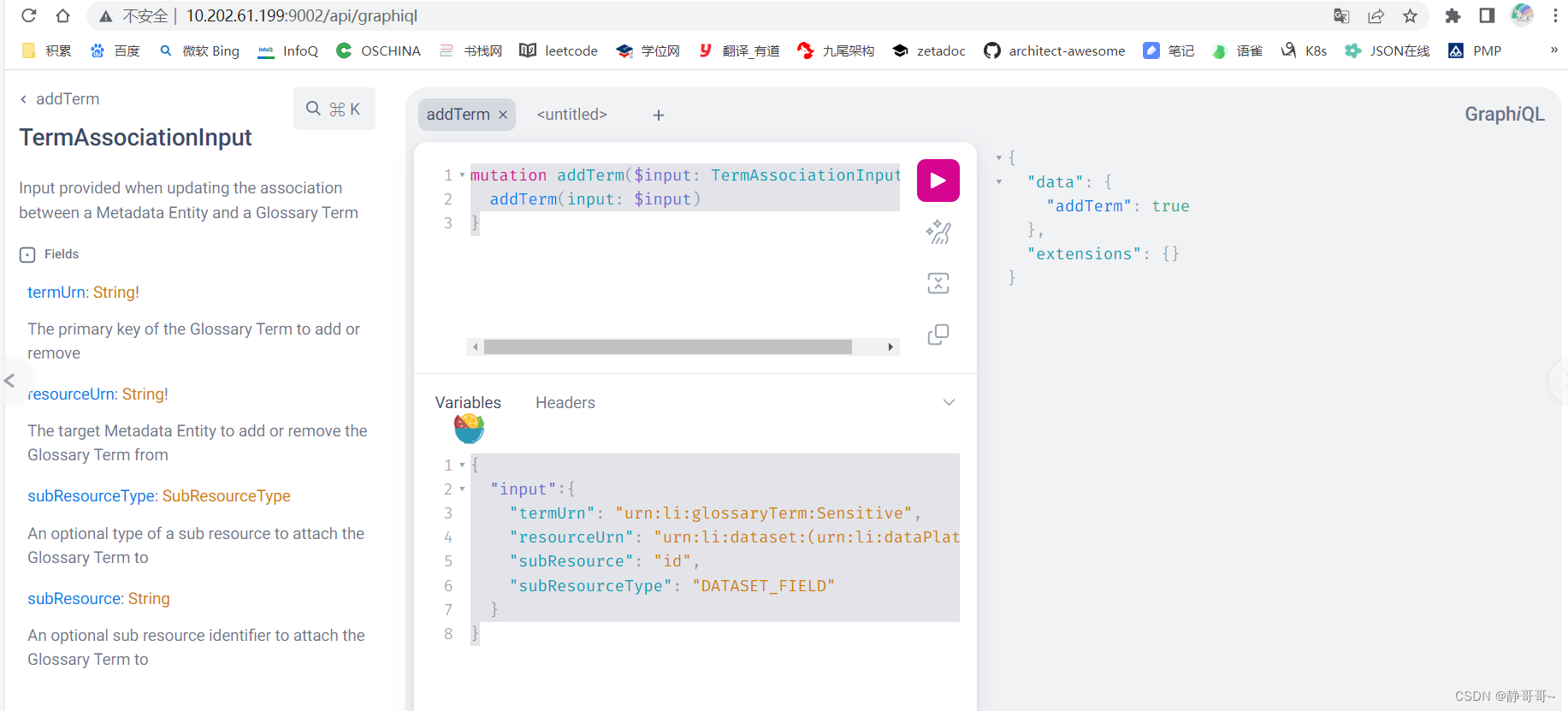
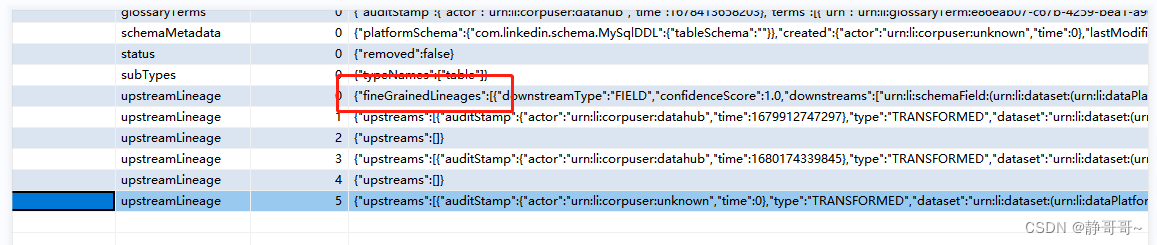
select * from metadata_aspect_v2 mav where urn like "urn:li:glossaryTerm%"
mutation addTerm($input: TermAssociationInput!){
addTerm(input: $input)}{"input":{"termUrn":"urn:li:glossaryTerm:Sensitive",
"resourceUrn":"urn:li:dataset:(urn:li:dataPlatform:mysql,datahub.jzhou_index,PROD)",
"subResource":"id",
"subResourceType":"DATASET_FIELD"}}
8.3 常见元数据管理系统比对
Atlas
作为数据治理计划的一部分,Atlas于2015年7月开始在Hortonworks进行孵化。
Atlas的主要目标是数据治理,支持与HBase,Hive和Kafka的集成。
https://github.com/apache/atlas
基本上一年已更新,维护较少,更新较慢

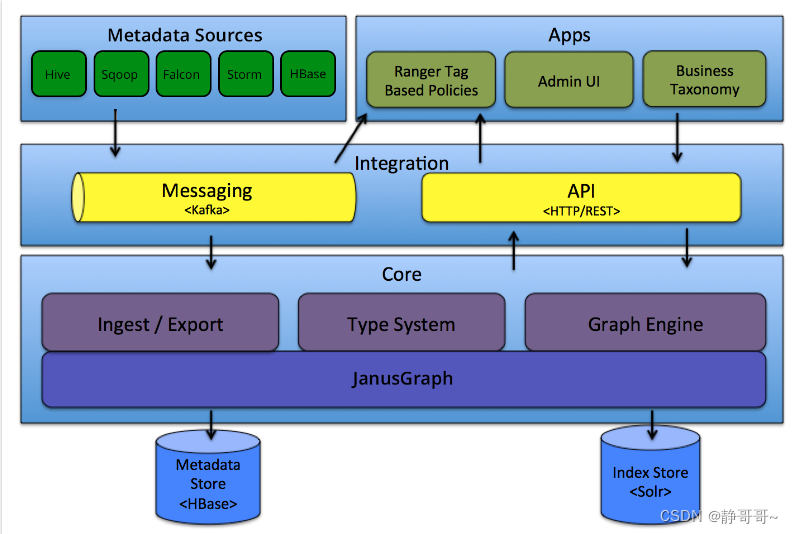
Atlas 对字段血缘的支持比较高: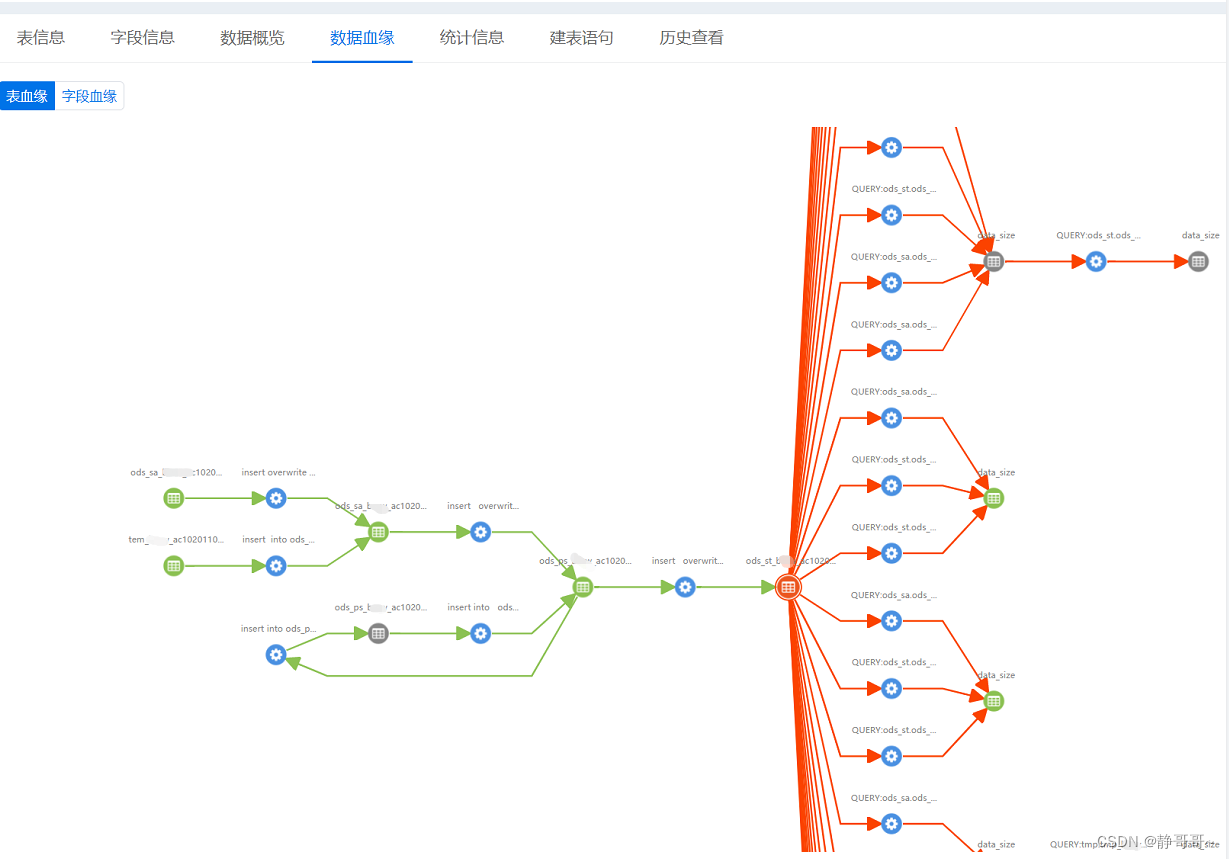
DataHub
LinkedIn开源出来的,原来叫做WhereHows 。经过一段时间的发展datahub于2020年2月在Github开源
https://github.com/datahub-project/datahub
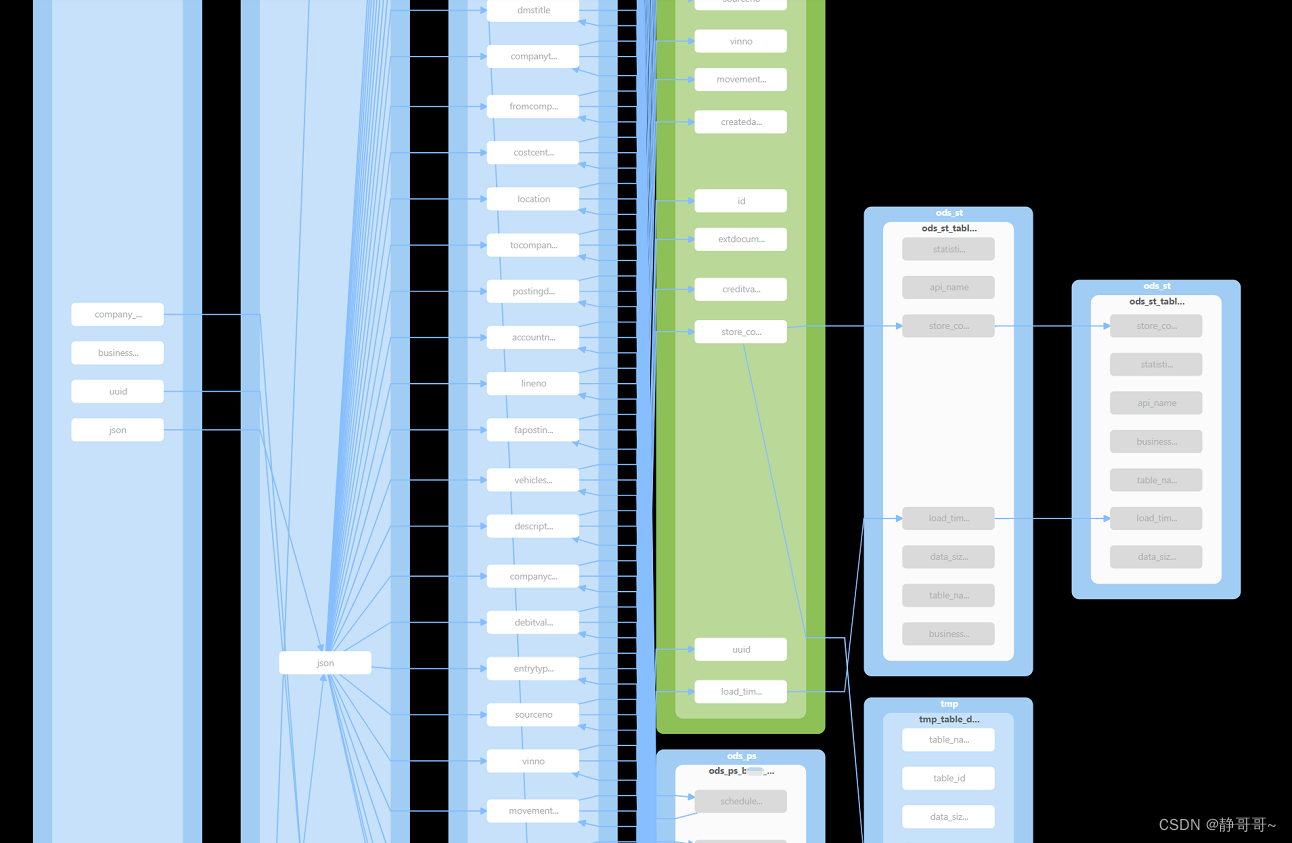
近期几乎一个月2个版本,更新太快,比较新,版本还是0.x.x,国内使用较少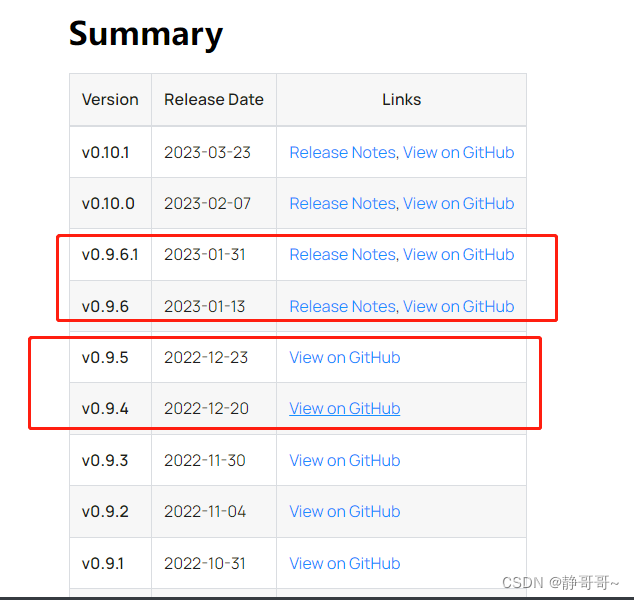

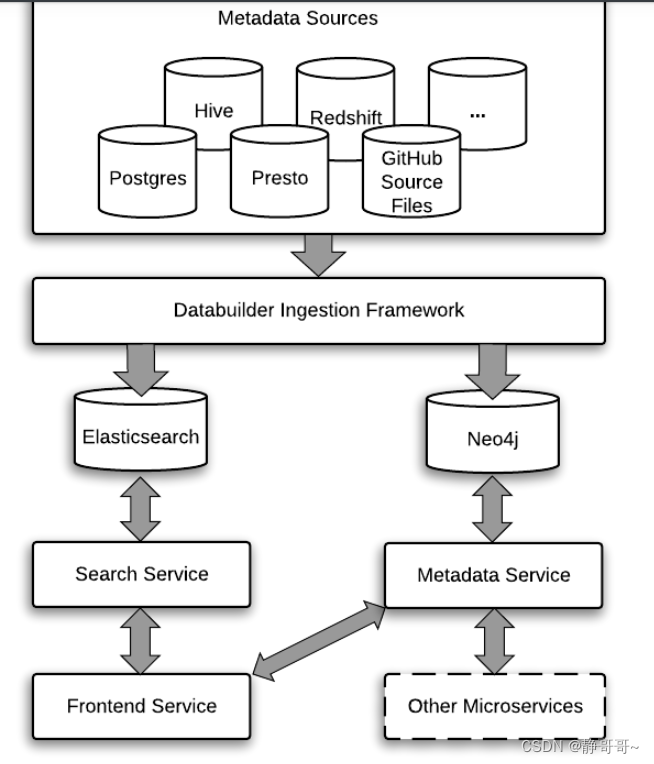
Amundsen
Lyft 于2019年4月开发了Amundsen,并与10月开源。
https://github.com/amundsen-io/amundsen
发版,按模块来发版,近期都有一个版本,版本相对固定,底层也可将Atlas当做是Amundsen的一个存储嵌入,这块还是可以再调研调研。
search-4.1.1:3 days ago
metadata-3.12.1:last week
common-0.31.0:2023.1.10
databuilder-7.4.3:2022.12.16

参考:
- 官网 DataHub Quickstart Guide](https://datahubproject.io/docs/quickstart)
- DataHub安装配置详细过程
- 一站式元数据治理平台——Datahub入门宝典
版权归原作者 静哥哥~ 所有, 如有侵权,请联系我们删除。