
今天在学习黑马头条用户端文章相关内容时,首次在项目中接触到垂直分表的具体实例,之前学习MySQL以及Redis的过程中了解过垂直分表和水平分表但没有涉及到具体项目的使用,借此机会小记心得体会。
垂直分表
垂直分表:根据业务的逻辑,将原本一个库中的一个表拆分为多个表,每个库中的表与表结构不同。
水平分表: 根据分片算法,将一个库拆分为多个库,每个库仍然保存原有的结构。
文章相关信息数据存储分为三张表:文章基本信息表(ap_article)、文章配置表(ap_article_config)和文章内容表(ap_article_content)。
文章基本信息表:存储文章的基本信息。
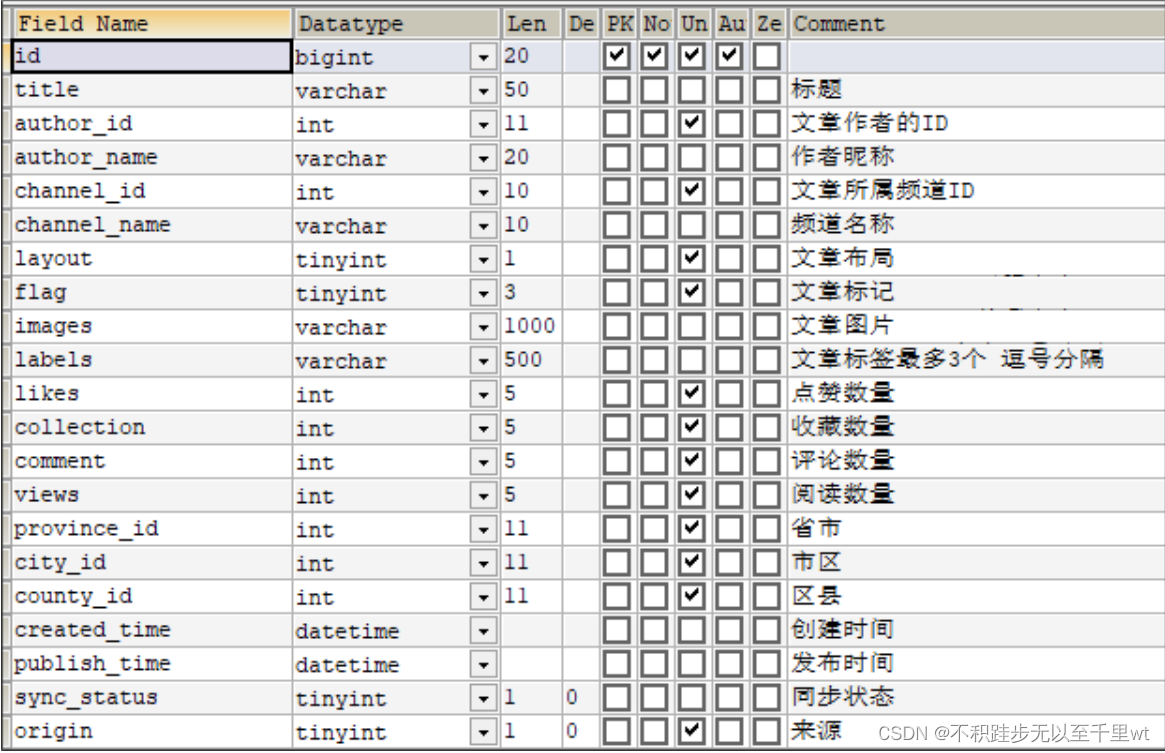
文章配置表:存储文章的相关权限如:是否允许评论、是否允许转发、是否下架、是否已删除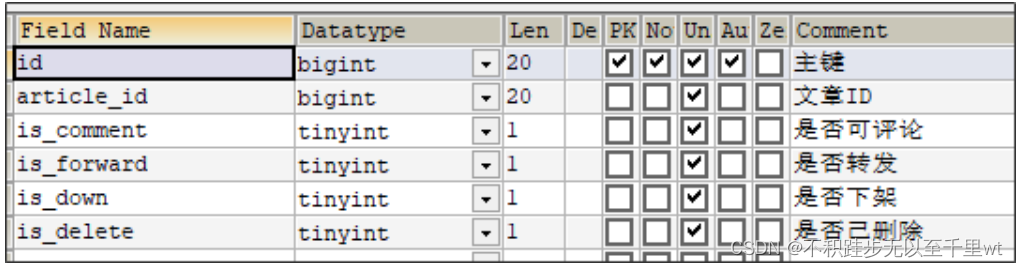 文章内容表:存放文章对应的文本内容(longtext)
文章内容表:存放文章对应的文本内容(longtext)

关于为什么需要将文章信息拆分为三张表格分别存储而不是将其全部放在一张表里进行存储,**考虑实际业务场景,某个人刷微博、小程序时,首先看到的是一条一条的文章的简介以及对应的封面选图,用户可以上滑查看以往的消息同时也可以下拉刷新查看最新的消息,在这个过程中只需要将消息的概述信息进行展示即可,只有当用户点击某一条具体的消息的时候才需要将此条消息对应的具体文本内容进行查找并将其显示在页面上。**参考实际场景的使用,可以理解将文章相关信息拆分为“文章基本信息表”和”文章内容表“,文章内容对应类型为longtext,查询比较耗时,和文章基本信息相比查询耗时但查询具有选择性。文章基本信息的查询量比较大,所以考虑将其拆分分表存储,满足业务场景。此时又产生新的问题:**为什么不将”文章配置表“直接嵌入到以上提及到的两个表格中呢???**以上两个表格在具体查询的时候均涉及到配置信息的条件的使用:如:文章是否下架,假如文章已经下架则不能查询并且显示。所以将其抽取为公共字段供两个表格查询使用,减少重复字段。
分布式ID
为什么需要分布式ID
**单机MySQL数据存储有一定的容量上限,随着项目上线后使用人数的增多,系统的数据量将会越来越大,单机MySQL没有办法继续提供数据支持,需要进行分库分表。**在分库之后,数据将分布在不同服务器上的数据库中,数据库的自增主键无法保证生成的主键ID在不同服务器的数据库间具有唯一性。**此时需要分布式ID保证多个服务器上的数据库中主键的唯一性。**
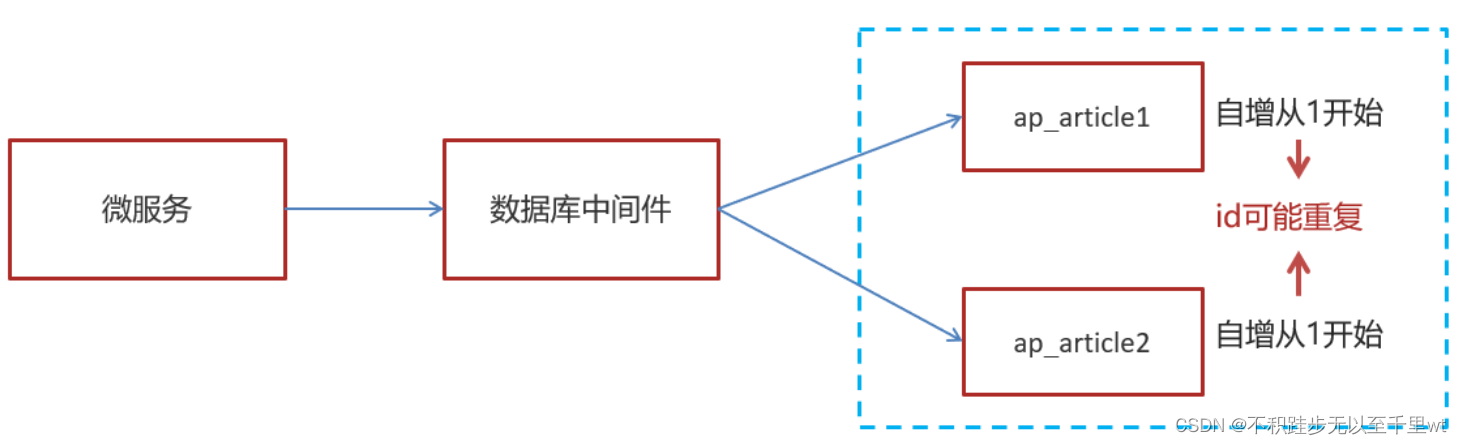
通过引入分布式ID可以解决上面图示问题。
分布式ID需要满足的条件
- 全局唯一:ID 的全局唯一性肯定是首先要满足的!
- 高性能:分布式 ID 的生成速度要快,对本地资源消耗要小。
- 高可用:生成分布式 ID 的服务要保证可用性无限接近于 100%。
- 方便易用:拿来即用,使用方便,快速接入!
- 安全:ID 中不包含敏感信息。
- 有序递增:如果要把 ID 存放在数据库的话,ID 的有序性可以提升数据库写入速度。并且,很多时候 ,我们还很有可能会直接通过 ID 来进行排序。
- 有具体的业务含义:生成的 ID 如果能有具体的业务含义,可以让定位问题以及开发更透明化(通过 ID 就能确定是哪个业务)。
- 独立部署:也就是分布式系统单独有一个发号器服务,专门用来生成分布式 ID。这样就生成 ID 的服务可以和业务相关的服务解耦。不过,这样同样带来了网络调用消耗增加的问题。总的来说,如果需要用到分布式 ID 的场景比较多的话,独立部署的发号器服务还是很有必要的。
常见的分布式ID算法有哪些
**Snowflake(雪花算法)**
Snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。其组成如下:
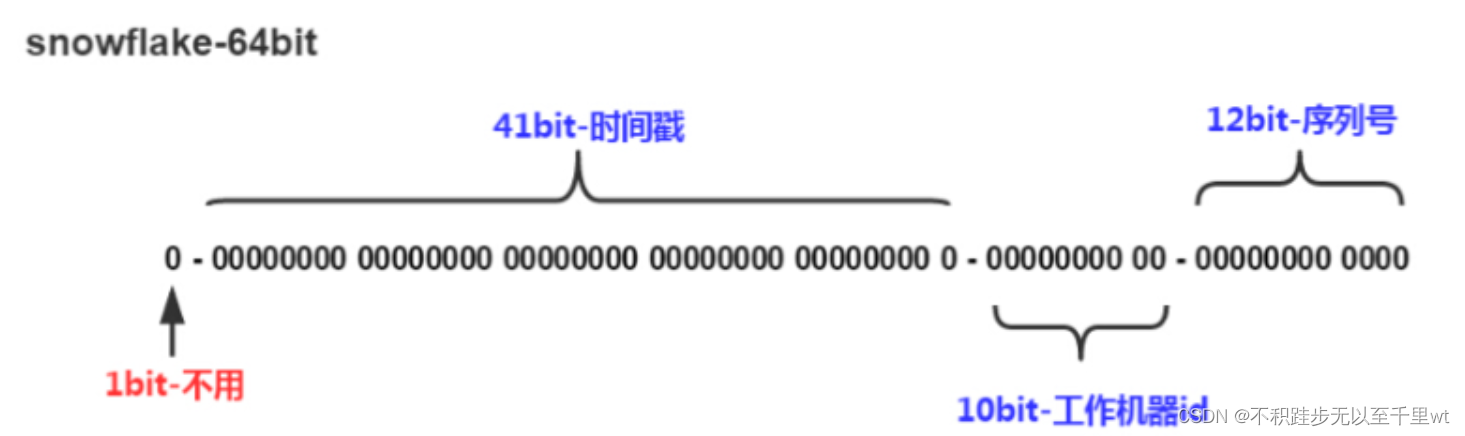
- sign(1bit):符号位(标识正负),始终为 0,代表生成的 ID 为正数。
- timestamp (41 bits):一共 41 位,用来表示时间戳,单位是毫秒,可以支撑 2 ^41 毫秒(约 69 年)
- datacenter id + worker id (10 bits):一般来说,前 5 位表示机房 ID,后 5 位表示机器 ID(实际项目中可以根据实际情况调整)。这样就可以区分不同集群/机房的节点。
- sequence (12 bits):一共 12 位,用来表示序列号。 序列号为自增值,代表单台机器每毫秒能够产生的最大 ID 数(2^12 = 4096),也就是说单台机器每毫秒最多可以生成 4096 个 唯一 ID。
MyBatis-plus中已经集成了雪花算法,使用的时候可以方便使用。
雪花算法的优缺点:
- 优点:生成速度比较快、生成的 ID 有序递增、比较灵活(可以对 Snowflake 算法进行简单的改造比如加入业务 ID)
- 缺点:需要解决重复 ID 问题(ID 生成依赖时间,在获取时间的时候,可能会出现时间回拨的问题,也就是服务器上的时间突然倒退到之前的时间,进而导致会产生重复 ID)、依赖机器 ID 对分布式环境不友好(当需要自动启停或增减机器时,固定的机器 ID 可能不够灵活)。
** UUID(Universally Unique Identifier)通用唯一标识符。**
**UUID包含32个16进制数字。JDK中自带生成UUID的算法:**
//输出示例:cb4a9ede-fa5e-4585-b9bb-d60bce986eaa
UUID.randomUUID()
UUID
的生成简单到只有一行代码,输出结果
cb4a9ede-fa5e-4585-b9bb-d60bce986eaa
,但UUID却并不适用于实际的业务需求。像用作订单号
UUID
这样的字符串没有丝毫的意义,看不出和订单相关的有用信息;而对于数据库来说用作业务
主键ID
,它不仅是太长还是字符串,存储性能差查询也很耗时,所以不推荐用作
分布式ID
。
UUID算法的优缺点:
- 优点:生成速度比较快、简单易用
- 缺点:存储消耗空间大(32 个字符串,128 位)、 不安全(基于 MAC 地址生成 UUID 的算法会造成 MAC 地址泄露)、无序(非自增)、没有具体业务含义、需要解决重复 ID 问题(当机器时间不对的情况下,可能导致会产生重复 ID)
项目中具体如何使用分布式ID
在黑马头条项目中选用雪花算法生成唯一ID,主要实现:
- 在数据库对应实体中的id字段上加入配置,指定其类型为id_worker。
@TableId(value = "id",type = IdType.ID_WORKER)
private Long id;
- 在配置文件application.yml中配置机房ID和机器ID。
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
# 设置别名包扫描路径,通过该属性可以给包中的类注册别名
type-aliases-package: com.heima.model.article.pojos
global-config:
datacenter-id: 1 #取值范围0-31
workerId: 1 #取值范围0-31
模板引擎FreeMarker
freemarker简介
**FreeMarker 是一款 模板引擎: 即一种基于模板和要改变的数据, 并用来生成输出文本(HTML网页,电子邮件,配置文件,源代码等)的通用工具。** 它不是面向最终用户的,而是一个Java类库,是一款程序员可以嵌入他们所开发产品的组件。模板编写为FreeMarker Template Language (FTL)。它是简单的,专用的语言, *不是* 像PHP那样成熟的编程语言。 那就意味着要准备数据在真实编程语言中来显示,比如数据库查询和业务运算, 之后模板显示已经准备好的数据。在模板中,你可以专注于如何展现数据, 而在模板之外可以专注于要展示什么数据。
对象存储服务MinIO
MinIO简介
MinIO基于Apache License v2.0开源协议的对象存储服务,可以做为云存储的解决方案用来保存海量的图片,视频,文档。由于采用Golang实现,服务端可以工作在Windows,Linux, OS X和FreeBSD上。配置简单,基本是复制可执行程序,单行命令可以运行起来。
MinIO兼容亚马逊S3云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小,从几kb到最大5T不等。
MinIO的优点
- 数据保护Minio使用Minio Erasure Code(纠删码)来防止硬件故障。即便损坏一半以上的driver,但是仍然可以从中恢复。
- 高性能作为高性能对象存储,在标准硬件条件下它能达到55GB/s的读、35GB/s的写速率
- 可扩容不同MinIO集群可以组成联邦,并形成一个全局的命名空间,并跨越多个数据中心
- SDK支持基于Minio轻量的特点,它得到类似Java、Python或Go等语言的sdk支持
- 有操作页面面向用户友好的简单操作界面,非常方便的管理Bucket及里面的文件资源
- 功能简单这一设计原则让MinIO不容易出错、更快启动
- 丰富的API支持文件资源的分享连接及分享链接的过期策略、存储桶操作、文件列表访问及文件上传下载的基本功能等。
- 文件变化主动通知存储桶(Bucket)如果发生改变,比如上传对象和删除对象,可以使用存储桶事件通知机制进行监控,并通过以下方式发布出去:AMQP、MQTT、Elasticsearch、Redis、NATS、MySQL、Kafka、Webhooks等。
本项目中使用的FreeMarker和MinIO示例
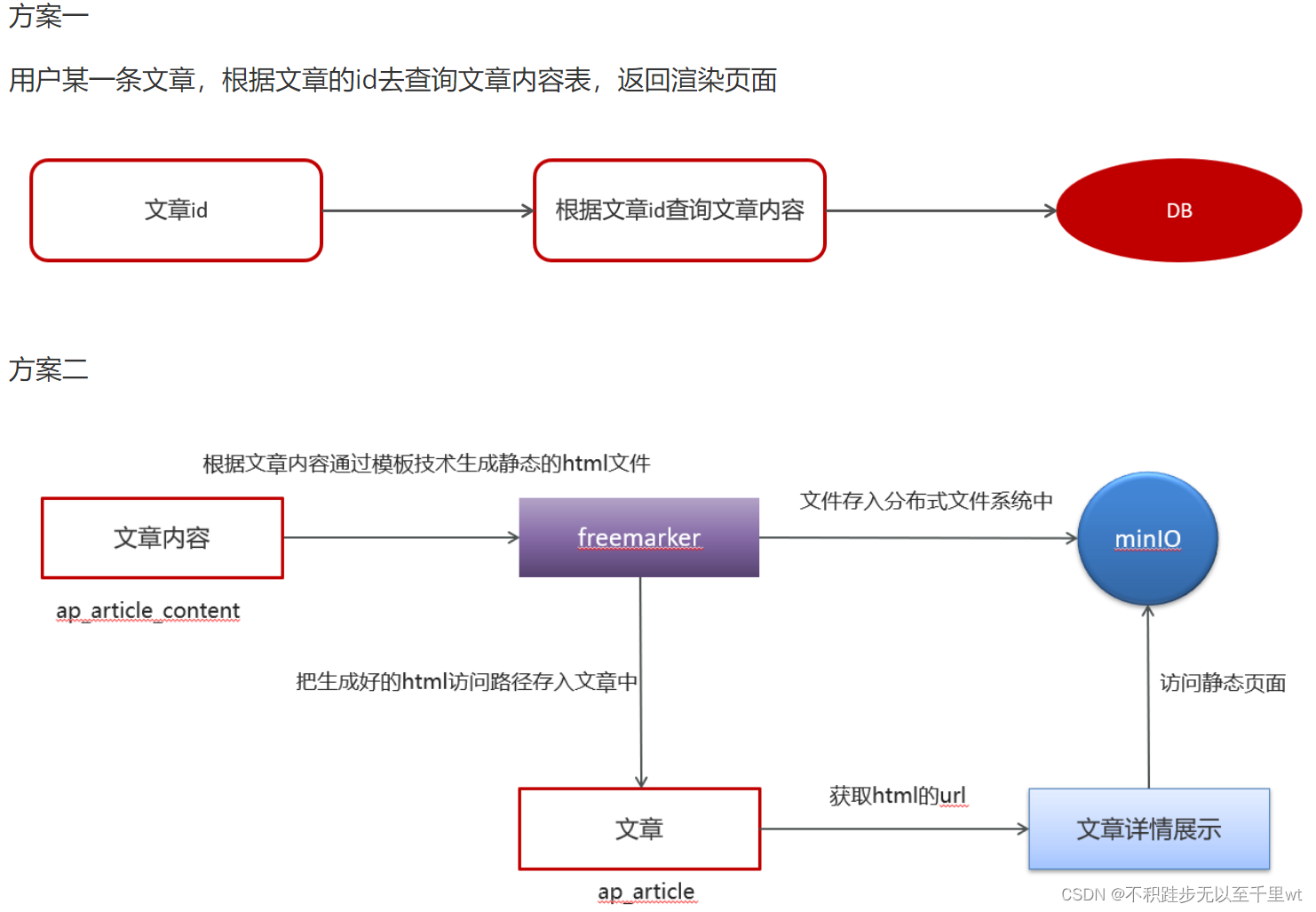
原本打算今天将FreeMarker和MinIO的基本使用方法用代码示例的方式展示出来,写到一半的发现官方讲义挺详细的,自己没有思绪如何去写,暂时就写到这里吧,后续有更新及时补上的。
悲伤的涛
本文转载自: https://blog.csdn.net/weixin_45863010/article/details/136463337
版权归原作者 不积跬步无以至千里wt 所有, 如有侵权,请联系我们删除。
版权归原作者 不积跬步无以至千里wt 所有, 如有侵权,请联系我们删除。