
【云原生之kubernetes实战】在k8s环境下部署Spark分布式计算平台
一、Spark介绍
1.Spark简介
Spark是分布式计算平台,是一个用scala语言编写的计算框架,基于内存的快速、通用、可扩展的大数据分析引擎。
2.Spark作用
Apache Spark 是一个快速的,通用的集群计算系统。它对 Java,Scala,Python 和 R 提供了的高层 API,并有一个经优化的支持通用执行图计算的引擎。它还支持一组丰富的高级工具,包括用于 SQL 和结构化数据处理的 Spark SQL,用于机器学习的 MLlib,用于图计算的 GraphX 和 Spark Streaming。
二、检查本地集群状态
1.检查工作节点状态
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready control-plane 19d v1.24.0
node01 Ready <none> 19d v1.24.0
node02 Ready <none> 19d v1.24.0
2.检查k8s版本
[root@master ~]# kubectl version --short
Flag --short has been deprecated, and will be removed in the future. The --short output will become the default.
Client Version: v1.24.0
Kustomize Version: v4.5.4
Server Version: v1.24.0
二、安装helm工具
1.下载helm软件包
[root@master mysql]# wget https://get.helm.sh/helm-v3.9.0-linux-amd64.tar.gz
--2022-10-22 19:10:12-- https://get.helm.sh/helm-v3.9.0-linux-amd64.tar.gz
Resolving get.helm.sh (get.helm.sh)... 152.199.39.108, 2606:2800:247:1cb7:261b:1f9c:2074:3c
Connecting to get.helm.sh (get.helm.sh)|152.199.39.108|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 13952532(13M)[application/x-tar]
Saving to: ‘helm-v3.9.0-linux-amd64.tar.gz’
100%[========================================================================================>]13,952,532 16.7MB/s in0.8s
2022-10-22 19:10:17 (16.7 MB/s) - ‘helm-v3.9.0-linux-amd64.tar.gz’ saved [13952532/13952532]
2.解压压缩包
[root@master mysql]# tar -xzf helm-v3.9.0-linux-amd64.tar.gz[root@master mysql]# ls
helm-v3.9.0-linux-amd64.tar.gz linux-amd64
3.复制二进制文件
[root@master linux-amd64]# ls
helm LICENSE README.md
[root@master linux-amd64]# cp -a helm /usr/bin/[root@master linux-amd64]#
4.检查helm版本
[root@master linux-amd64]# helm version
version.BuildInfo{Version:"v3.9.0", GitCommit:"7ceeda6c585217a19a1131663d8cd1f7d641b2a7", GitTreeState:"clean", GoVersion:"go1.17.5"}
5.helm命令补全
[root@master spark]# helm completion bash > .helmrc && echo "source .helmrc" >> .bashrc[root@master mysql]# source .helmrc[root@master mysql]#
三、安装nfs服务器
1.安装nfs软件
yum install -y nfs-utils
2.创建共享目录
mkdir -p /nfs &&chmod766 -R /nfs
3配置共享目录
echo"/nfs/ *(insecure,rw,sync,no_root_squash)"> /etc/exports
4.使nfs配置生效
exportfs -r
5.设置nfs服务开机自启
systemctl enable --now rpcbind
systemctl enable --now nfs-server
6.其他节点检查nfs共享情况
[root@node01 ~]# showmount -e 192.168.3.90
Export list for192.168.3.90:
/nfs *
四、部署storageclass
1.编辑sc.yaml
[root@master spark]# cat sc.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-storage
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
archiveOnDelete: "true"## 删除pv的时候,pv的内容是否要备份
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2
# resources:# limits:# cpu: 10m# requests:# cpu: 10m
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 192.168.3.90 ## 指定自己nfs服务器地址
- name: NFS_PATH
value: /nfs ## nfs服务器共享的目录
volumes:
- name: nfs-client-root
nfs:
server: 192.168.3.90
path: /nfs
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
# replace with namespace where provisioner is deployed
namespace: default
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
2.应用sc.yaml文件
[root@master spark]# kubectl apply -f sc.yaml
storageclass.storage.k8s.io/nfs-storage created
deployment.apps/nfs-client-provisioner created
serviceaccount/nfs-client-provisioner created
clusterrole.rbac.authorization.k8s.io/nfs-client-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/run-nfs-client-provisioner created
role.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-client-provisioner created
3.检查storageclass资源对象状态
[root@master spark]# kubectl get storageclasses.storage.k8s.io
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
nfs-storage (default) k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 81s
五、添加helm仓库源
1.添加helm仓库
[root@master spark]# helm repo add bitnami https://charts.bitnami.com/bitnami/"bitnami" has been added to your repositories
2.查看helm仓库列表
[root@master spark]# helm repo list
NAME URL
bitnami https://charts.bitnami.com/bitnami
azure http://mirror.azure.cn/kubernetes/charts/
incubator https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts-incubator/
3.更新helm仓库
[root@master spark]# helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "incubator" chart repository
...Successfully got an update from the "azure" chart repository
...Successfully got an update from the "bitnami" chart repository
Update Complete. ⎈Happy Helming!⎈
4.搜索关于Spark的资源
[root@master spark]# helm search repo spark
NAME CHART VERSION APP VERSION DESCRIPTION
azure/spark 1.0.5 1.5.1 DEPRECATED - Fast and general-purpose cluster c...
azure/spark-history-server 1.4.3 2.4.0 DEPRECATED - A Helm chart for Spark History Server
bitnami/spark 6.3.6 3.3.0 Apache Spark is a high-performance engine for l...
incubator/ack-spark-history-server 0.5.0 2.4.5 A Helm chart for Spark History Server
incubator/ack-spark-operator 0.1.16 2.4.5 A Helm chart for Spark on Kubernetes operator
bitnami/dataplatform-bp1 12.0.2 1.0.1 DEPRECATED This Helm chart can be used for the ...
bitnami/dataplatform-bp2 12.0.5 1.0.1 DEPRECATED This Helm chart can be used for the ...
azure/luigi 2.7.8 2.7.2 DEPRECATED Luigi is a Python module that helps ...
六、安装Spark
1.下载chart
[root@master spark]# helm pull bitnami/spark[root@master spark]# ls
spark-6.3.6.tgz
[root@master spark]# tar -xzf spark-6.3.6.tgz [root@master spark]# ls
spark spark-6.3.6.tgz
2.修改values.yaml
修改部分
service:
## @param service.type Kubernetes Service type##
type: NodePort
## @param service.ports.http Spark client port for HTTP## @param service.ports.https Spark client port for HTTPS## @param service.ports.cluster Spark cluster port##
ports:
http: 80
https: 443
cluster: 7077## Specify the nodePort(s) value(s) for the LoadBalancer and NodePort service types.## ref: https://kubernetes.io/docs/concepts/services-networking/service/#type-nodeport## @param service.nodePorts.http Kubernetes web node port for HTTP## @param service.nodePorts.https Kubernetes web node port for HTTPS## @param service.nodePorts.cluster Kubernetes cluster node port##
nodePorts:
3.helm安装Spark应用
[root@master spark]# helm install myspark ./spark
NAME: myspark
LAST DEPLOYED: Sun Oct 23 00:05:40 2022
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: spark
CHART VERSION: 6.3.6
APP VERSION: 3.3.0
** Please be patient while the chart is being deployed **
1. Get the Spark master WebUI URL by running these commands:
exportNODE_PORT=$(kubectl get --namespace default -o jsonpath="{.spec.ports[?(@.name=='http')].nodePort}" services myspark-master-svc)exportNODE_IP=$(kubectl get nodes --namespace default -o jsonpath="{.items[0].status.addresses[0].address}")echo http://$NODE_IP:$NODE_PORT2. Submit an application to the cluster:
To submit an application to the cluster the spark-submit script must be used. That script can be
obtained at https://github.com/apache/spark/tree/master/bin. Also you can use kubectl run.
Run the commands below to obtain the master IP and submit your application.
exportEXAMPLE_JAR=$(kubectl exec -ti --namespace default myspark-worker-0 -- find examples/jars/ -name 'spark-example*\.jar'|tr -d '\r')exportSUBMIT_PORT=$(kubectl get --namespace default -o jsonpath="{.spec.ports[?(@.name=='cluster')].nodePort}" services myspark-master-svc)exportSUBMIT_IP=$(kubectl get nodes --namespace default -o jsonpath="{.items[0].status.addresses[0].address}")
kubectl run --namespace default myspark-client --rm --tty -i --restart='Never'\
--image docker.io/bitnami/spark:3.3.0-debian-11-r40 \
-- spark-submit --master spark://$SUBMIT_IP:$SUBMIT_PORT\
--class org.apache.spark.examples.SparkPi \
--deploy-mode cluster \$EXAMPLE_JAR1000
2.检查pod状态
[root@master spark]# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-tomcat9 1/1 Running 2(5h55m ago) 19d
myspark-master-0 1/1 Running 0 36m
myspark-worker-0 1/1 Running 0 36m
myspark-worker-1 1/1 Running 0 33m
nfs-client-provisioner-8dcd8c766-2bptf 1/1 Running 0 5h16m
3.检查svc
[root@master spark]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none>443/TCP 20d
myspark-headless ClusterIP None <none><none> 36m
myspark-master-svc NodePort 10.96.2.220 <none>7077:32573/TCP,80:31295/TCP 36m
4.删除spark应用
helm delete --purge myspark
七、访问Spark的Web UI
worker 实例当前为 2 个。
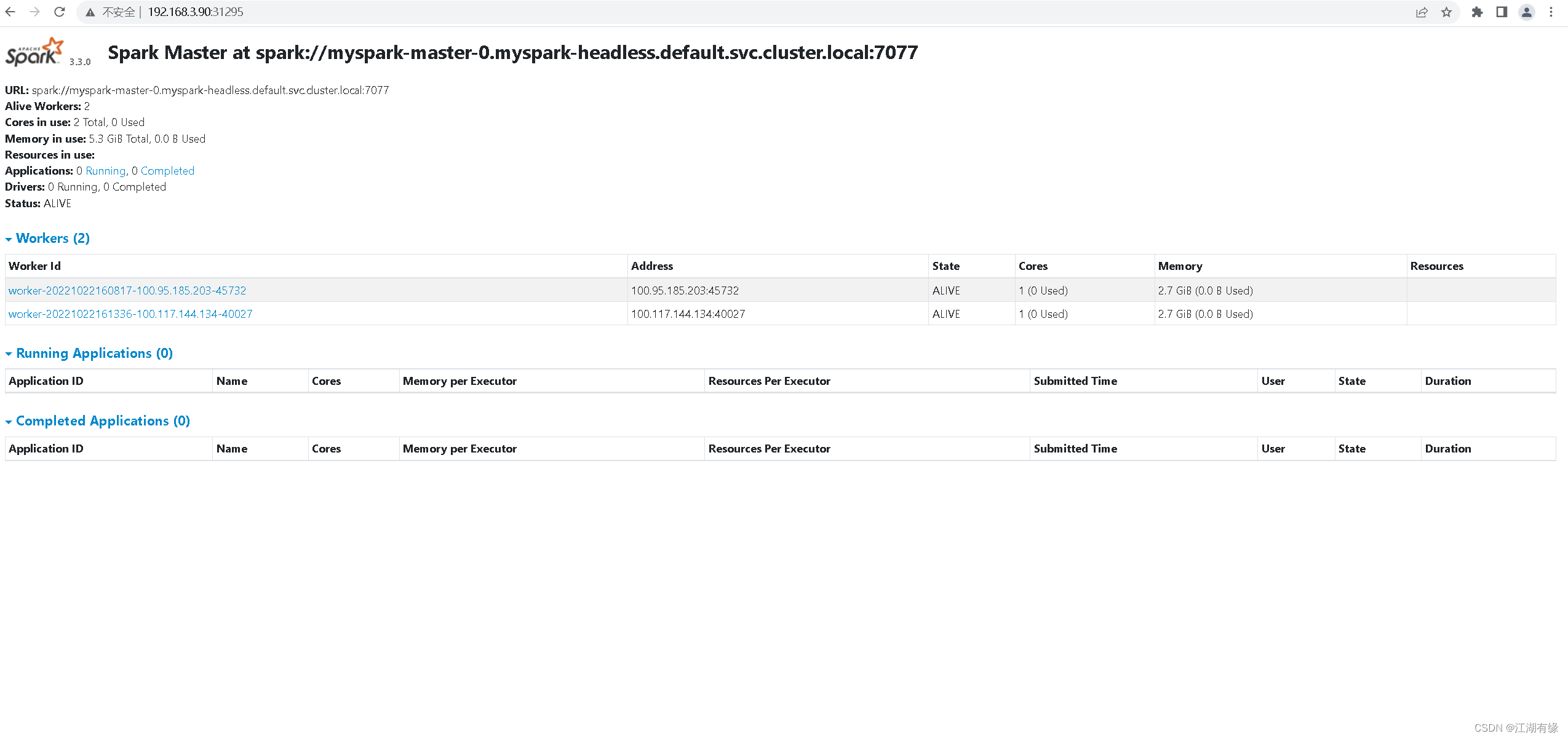
八、新增worker 实例数量
1.修改values.yaml
更改values.yaml中 replicaCount为3
replicaCount: 3## Kubernetes Pods Security Context## https://kubernetes.io/docs/tasks/configure-pod-container/security-context/## @param worker.podSecurityContext.enabled Enable security context## @param worker.podSecurityContext.fsGroup Group ID for the container## @param worker.podSecurityContext.runAsUser User ID for the container## @param worker.podSecurityContext.runAsGroup Group ID for the container## @param worker.podSecurityContext.seLinuxOptions SELinux options for the container##
podSecurityContext:
enabled: true
fsGroup: 1001
runAsUser: 1001
runAsGroup: 0
seLinuxOptions: {}
2.使用helm更新spark应用
[root@master spark]# helm upgrade myspark ./spark
Release "myspark" has been upgraded. Happy Helming!
NAME: myspark
LAST DEPLOYED: Sun Oct 23 00:52:36 2022
NAMESPACE: default
STATUS: deployed
REVISION: 3
TEST SUITE: None
NOTES:
CHART NAME: spark
CHART VERSION: 6.3.6
APP VERSION: 3.3.0
** Please be patient while the chart is being deployed **
1. Get the Spark master WebUI URL by running these commands:
exportNODE_PORT=$(kubectl get --namespace default -o jsonpath="{.spec.ports[?(@.name=='http')].nodePort}" services myspark-master-svc)exportNODE_IP=$(kubectl get nodes --namespace default -o jsonpath="{.items[0].status.addresses[0].address}")echo http://$NODE_IP:$NODE_PORT2. Submit an application to the cluster:
To submit an application to the cluster the spark-submit script must be used. That script can be
obtained at https://github.com/apache/spark/tree/master/bin. Also you can use kubectl run.
Run the commands below to obtain the master IP and submit your application.
exportEXAMPLE_JAR=$(kubectl exec -ti --namespace default myspark-worker-0 -- find examples/jars/ -name 'spark-example*\.jar'|tr -d '\r')exportSUBMIT_PORT=$(kubectl get --namespace default -o jsonpath="{.spec.ports[?(@.name=='cluster')].nodePort}" services myspark-master-svc)exportSUBMIT_IP=$(kubectl get nodes --namespace default -o jsonpath="{.items[0].status.addresses[0].address}")
kubectl run --namespace default myspark-client --rm --tty -i --restart='Never'\
--image docker.io/bitnami/spark:3.3.0-debian-11-r40 \
-- spark-submit --master spark://$SUBMIT_IP:$SUBMIT_PORT\
--class org.apache.spark.examples.SparkPi \
--deploy-mode cluster \$EXAMPLE_JAR1000
3.检查pod状态
[root@master spark]# kubectl get pods
NAME READY STATUS RESTARTS AGE
my-tomcat9 1/1 Running 2(6h7m ago) 20d
my-wordpress-9585b7f4d-5lfzn 1/1 Running 1(78m ago) 82m
my-wordpress-mariadb-0 1/1 Running 0 82m
myspark-master-0 1/1 Running 0 48m
myspark-worker-0 1/1 Running 0 48m
myspark-worker-1 1/1 Running 0 45m
myspark-worker-2 1/1 Running 0 82s
nfs-client-provisioner-8dcd8c766-2bptf 1/1 Running 0 5h28m
4.查看spark的Web UI中worker数量
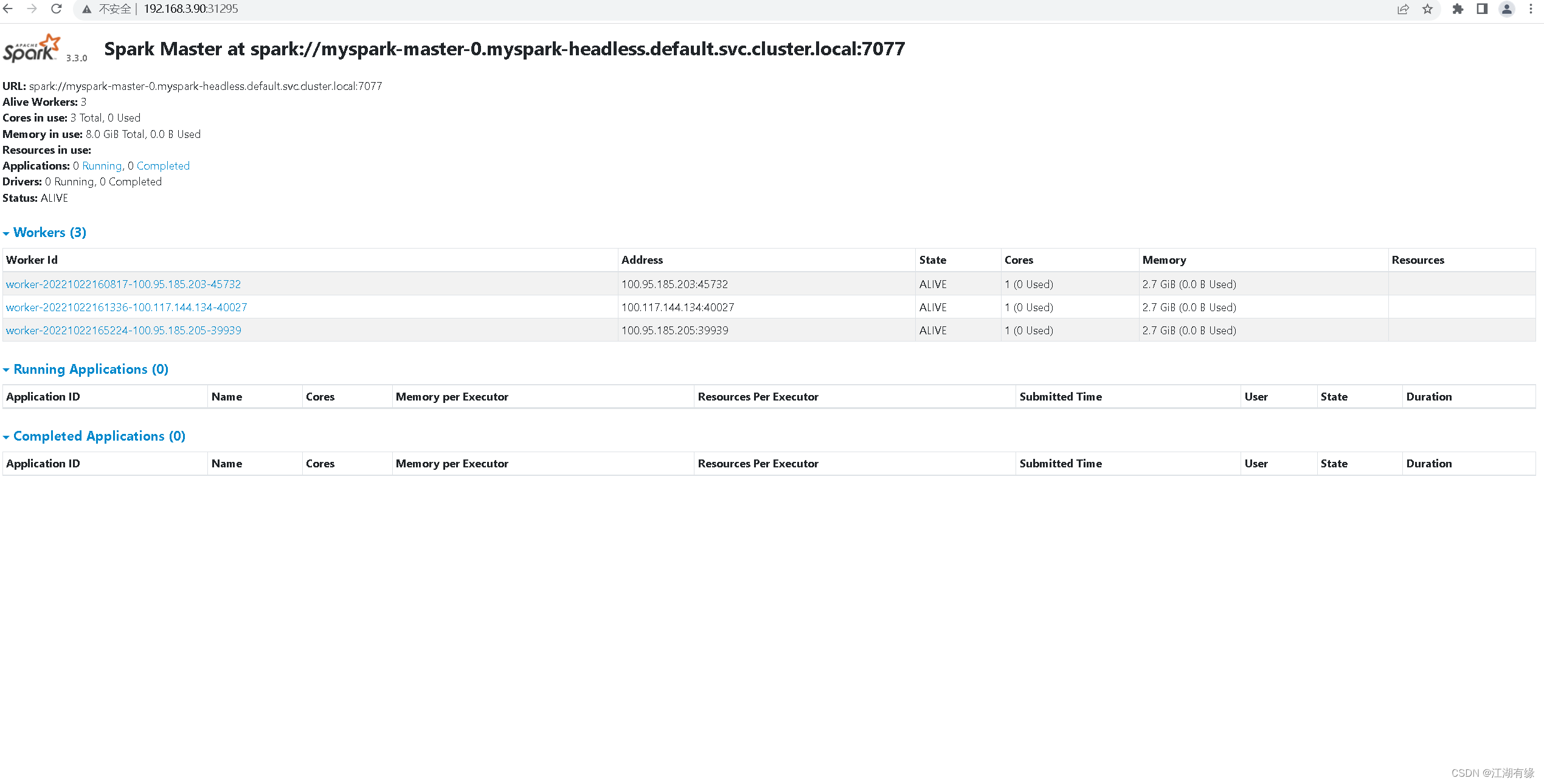
本文转载自: https://blog.csdn.net/jks212454/article/details/127469862
版权归原作者 江湖有缘 所有, 如有侵权,请联系我们删除。
版权归原作者 江湖有缘 所有, 如有侵权,请联系我们删除。