

一、流式计算和交互式计算的区别
交互式计算和流式计算都是大数据处理的重要模式,但它们服务于不同的目的和场景,具有不同的特点和侧重点。
1、交互式计算:
目标:
交互式计算的主要目标是提供快速响应,使用户能够在短时间内得到查询或分析结果,支持数据探索、业务分析和决策制定。它强调即时反馈和用户体验。
数据处理:
交互式计算处理的数据往往不是实时流入的,而是已经存储在数据库或数据仓库中的历史数据。它可以处理大规模数据集,但关键在于查询的响应速度。
应用场景:
适用于数据分析师、业务用户和数据科学家进行即席查询、仪表板查看、数据挖掘和报告生成等场景。
技术特点:
支持SQL查询、可视化工具、内存计算技术等,能够提供亚秒到分钟级别的查询响应时间。
2、流式计算:
目标:
流式计算专注于对连续不断的、实时产生的数据流进行实时处理和分析,强调低延迟和数据的实时性。
数据处理:
数据以流的形式不间断地到达,计算系统需要立即处理这些数据并作出响应,而不是等待数据积累到一定量后再处理。
应用场景:
适合实时监控、在线推荐系统、金融交易分析、物联网(IoT)数据处理等需要实时决策和处理的场景。
技术特点:
采用事件驱动、微批处理或连续查询模型,如Apache Kafka用于数据传输,Apache Flink、Spark Streaming或Apache Storm用于实时数据处理。
3、总结
总结来说,交互式计算关注于对已有数据的快速查询和分析,以支持决策和探索;
而流式计算则侧重于对实时数据流的即时处理,以捕捉数据中的瞬时变化和趋势,两者在大数据处理中扮演着互补的角色。
二、什么是流式计算?流式计算的主要原理是什么?
1 数据的时效性
日常工作中,我们一般会先把数据存储在表,然后对表的数据进行加工、分析。既然先存储在表中,那就会涉及到时效性概念。
如果我们处理以年,月为单位级别的数据处理,进行统计分析,个性化推荐,那么数据的的最新日期离当前有几个甚至上月都没有问题。
但是如果我们处理的是以天为级别,或者一小时甚至更小粒度的数据处理,那么就要求数据的时效性更高了。比如:
对网站的实时监控
对异常日志的监控
这些场景需要工作人员立即响应,这样的场景下,传统的统一收集数据,再存到数据库中,再取出来进行分析就无法满足高时效性的需求了。
2 流式计算和批量计算
上面说到的:
统一收集数据->存储到DB->对数据进行批量处理,就是我们说到的批量计算。
而流式计算,顾名思义,就是对数据流进行处理,是实时计算****
主要原理是:
· 与批量计算那样慢慢积累数据不同,流式计算立刻计算,数据持续流动,计算完之后就丢弃。
· 批量计算是维护一张表,对表进行实施各种计算逻辑。流式计算相反,是必须先定义好计算逻辑,提交到流式计算系统,这个计算作业逻辑在整个运行期间是不可更改的。
· 计算结果上,批量计算对全部数据进行计算后传输结果,流式计算是每次小批量计算后,结果可以立刻实时化展现。
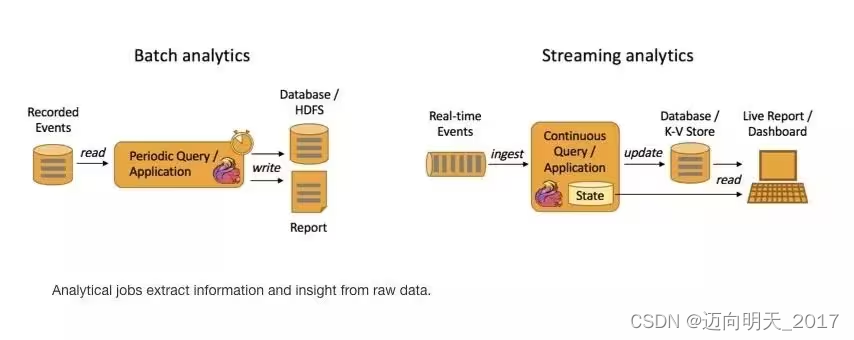
左边是Batch Analytics,右边是 Streaming Analytics。
Batch Analysis 就是传统意义上使用类似于 Map Reduce、Hive、Spark Batch 等,对作业进行分析、处理、生成离线报表
· Streaming Analytics 使用流式分析引擎如 Storm,Flink 实时处理分析数据,应用较多的场景如实时大屏、实时报表。
3 流式计算流程和特性
流程:
提交流计算作业
等待流式数据触发流计算作业
计算结果持续不断对外写出
特性:
实时,低延迟
无界,数据是不断输出无终止的
连续,计算连续进行,计算之后数据就会被丢弃
4 实时即未来
如今的我们正生活在新一次的信息革命浪潮中,5G、物联网、智慧城市、工业4.0、新基建……等新名词层出不穷,唯一不变的就是变化!
对于我们所学习的大数据来说更是这样:数据产生的越来越快、数据量越来越大,数据的来源越来越千变万化,数据中隐藏的价值规律更是越来越被重视!
数字化时代的未来正在被我们创造!
历史的发展从来不会一帆风顺,随着大数据时代的发展,海量数据和多种业务的实时处理需求激增,比如:实时监控报警系统、实时风控系统、实时推荐系统等,传统的批处理方式和早期的流式处理框架因其自身的局限性,难以在延迟性、吞吐量、容错能力,以及使用便捷性等方面满足业务日益苛刻的要求。
在这种形势下,Flink 以其独特的天然流式计算特性和更为先进的架构设计,极大地改善了以前的流式处理框架所存在的问题。
三、什么是流式计算–知乎
1、流式计算的背景
在日常生活中,我们通常会先把数据存储在一张表中,然后再进行加工、分析,这里就涉及到一个时效性的问题。如果我们处理以年、月为单位的级别的数据,那么多数据的实时性要求并不高;但如果我们处理的是以天、小时,甚至分钟为单位的数据,那么对数据的时效性要求就比较高。
在第二种场景下,如果我们仍旧采用传统的数据处理方式,统一收集数据,存储到数据库中,之后在进行分析,就可能无法满足时效性的要求。
2、流式计算与批量计算
大数据的计算模式主要分为:
批量计算(batch computing)
流式计算(stream computing)
交互计算(interactive computing)
图计算(graph computing)
其中,流式计算和批量计算是两种主要的大数据计算模式,分别适用于不同的大数据应用场景。
流数据(或数据流)是指在时间分布和数量上无限的一系列动态数据集合体,数据的价值随着时间的流逝而降低,因此必须实时计算给出秒级响应。
流式计算,顾名思义,就是对数据流进行处理,是实时计算。
批量计算则统一收集数据,存储到数据库中,然后对数据进行批量处理的数据计算方式。主要体现在以下几个方面:
1、数据时效性不同:流式计算实时、低延迟, 批量计算非实时、高延迟。
2、数据特征不同:流式计算的数据一般是动态的、没有边界的,而批处理的数据一般则是静态数据。
3、应用场景不同:流式计算应用在实时场景,时效性要求比较高的场景,如实时推荐、业务监控…批量计算一般说批处理,应用在实时性要求不高、离线计算的场景下,数据分析、离线报表等。
4、运行方式不同:流式计算的任务持续进行的,批量计算的任务则一次性完成。
3、流式计算框架、平台与相关产品
第一类,商业级流式计算平台(IBM InfoSphere Streams、IBM StreamBase等);
第二类,开源流式计算框架(Twitter Storm、S4等);
第三类,公司为支持自身业务开发的流式计算框架。
Strom:Twitter 开发的第一代流处理系统。
Heron:Twitter 开发的第二代流处理系统。
Spark streaming:是Spark核心API的一个扩展,可以实现高吞吐量的、具备容错机制的实时流数据的处理。
Flink:是一个针对流数据和批数据的分布式处理引擎。
Apache Kafka:由Scala写成。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
4、流式计算主要应用场景
流式处理可以用于两种不同场景: 事件流和持续计算。
1、事件流
事件流具能够持续产生大量的数据,这类数据最早出现与传统的银行和股票交易领域,也在互联网监控、无线通信网等领域出现、需要以近实时的方式对更新数据流进行复杂分析如趋势分析、预测、监控等。简单来说,事件流采用的是查询保持静态,语句是固定的,数据不断变化的方式。
2、持续计算
比如对于大型网站的流式数据:网站的访问PV/UV、用户访问了什么内容、搜索了什么内容等,实时的数据计算和分析可以动态实时地刷新用户访问数据,展示网站实时流量的变化情况,分析每天各小时的流量和用户分布情况;
比如金融行业,毫秒级延迟的需求至关重要。一些需要实时处理数据的场景也可以应用Storm,比如根据用户行为产生的日志文件进行实时分析,对用户进行商品的实时推荐等。
5、流式计算的价值
通过大数据处理我们获取了数据的价值,但是数据的价值是恒定不变的吗?
显然不是,一些数据在事情发生后不久就有了更高的价值,而且这种价值会随着时间的推移而迅速减少。
流处理的关键优势在于它能够更快地提供洞察力,通常在毫秒到秒之间。
流式计算的价值在于业务方可在更短的时间内挖掘业务数据中的价值,并将这种低延迟转化为竞争优势。
比方说,在使用流式计算的推荐引擎中,用户的行为偏好可以在更短的时间内反映在推荐模型中,推荐模型能够以更低的延迟捕捉用户的行为偏好以提供更精准、及时的推荐。
流式计算能做到这一点的原因在于,传统的批量计算需要进行数据积累,在积累到一定量的数据后再进行批量处理;
而流式计算能做到数据随到随处理,有效降低了处理延时。
Last、扩展阅读
为什么说流处理即未来?
https://news.qudong.com/article/562521.shtml
版权归原作者 迈向明天_2017 所有, 如有侵权,请联系我们删除。