
Excel 多线程导出大文件
- 前言
对于 10W+ 以上的数据导出,可以有以下思路:
- 异步导出 (@Async 注解 + @EnableAsync 注解)
- 分片导出,利用 多线程 每 2W 条数据打包成一个 Excel ;
- 将这些Excel 打包成一个 Zip流 传到 阿里云 OSS 上;
- 待生成 zip文件之后 ,通过MQ 或者其他模式消息通知到用户,导出失败或者成功;
提示:这里主要讲解如果利用多线程导出 大数据 excel (文件不落地),并生成 zip 流 上传
- Work_easyExcel多线程大数据导出
Pom.xml
maven+1.8jdk+poi+easyExcel
<!--xls--><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.17</version></dependency><!--xlsx--><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>3.17</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml-schemas</artifactId><version>3.17</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>2.2.6</version></dependency>
代码如下:
利用多线程生成 Excel 流
importcom.alibaba.excel.ExcelWriter;importcom.alibaba.excel.metadata.BaseRowModel;importcom.alibaba.excel.metadata.Sheet;importcom.alibaba.excel.support.ExcelTypeEnum;importcom.alibaba.excel.write.metadata.holder.WriteWorkbookHolder;importlombok.extern.log4j.Log4j;importorg.apache.poi.ss.usermodel.Workbook;importjava.io.ByteArrayOutputStream;importjava.io.IOException;importjava.util.List;importjava.util.Map;importjava.util.concurrent.CountDownLatch;/**
* 导出new线程池工具类
*/@Log4jpublicclassPageThreadPool<E>implementsRunnable{privatefinalCountDownLatch countDownLatch;privateString title;privateClass<?extendsBaseRowModel> clazz;privateMap<String,byte[]> byteList;privateList<E> list;publicPageThreadPool(CountDownLatch countDownLatch,String title,List<E> list,Class<?extendsBaseRowModel> clazz,Map<String,byte[]> byteList){this.countDownLatch = countDownLatch;this.title = title;this.list = list;this.clazz = clazz;this.byteList = byteList;}@Overridepublicvoidrun(){ByteArrayOutputStream bos =null;ExcelWriter writer =null;Workbook workbook;try{Sheet sheet1 =newSheet(1,0, clazz);
sheet1.setSheetName("sheet1");ByteArrayOutputStream out =newByteArrayOutputStream();
writer =newExcelWriter(out,ExcelTypeEnum.XLSX);
writer.write(list, sheet1);
workbook = writer.writeContext().getWorkbook();WriteWorkbookHolder holder = writer.writeContext().writeWorkbookHolder();
holder.setAutoCloseStream(true);
bos =newByteArrayOutputStream();
workbook.write(bos);
bos.flush();
out.flush();
out.close();//put 文件名和文件字节数组
byteList.put(this.title, bos.toByteArray());}catch(Exception e){
e.printStackTrace();}finally{try{if(bos !=null){
bos.close();}if(writer !=null){
writer.writeContext().finish(true);}}catch(IOException e){
e.printStackTrace();}if(countDownLatch !=null){
countDownLatch.countDown();}}}}
根据每次生成 Excel 文档的行数计算线程池的大小
importcom.alibaba.excel.ExcelWriter;importcom.alibaba.excel.metadata.BaseRowModel;importcom.alibaba.excel.metadata.Sheet;importcom.alibaba.excel.support.ExcelTypeEnum;importcom.aliyun.oss.OSSClient;importlombok.extern.log4j.Log4j;importorg.apache.poi.ss.usermodel.Workbook;importorg.springframework.beans.BeanUtils;importorg.springframework.beans.factory.annotation.Autowired;importorg.springframework.data.mongodb.core.BulkOperations;importorg.springframework.data.mongodb.core.MongoTemplate;importorg.springframework.data.mongodb.core.query.Criteria;importorg.springframework.data.mongodb.core.query.Query;importorg.springframework.data.mongodb.core.query.Update;importorg.springframework.scheduling.annotation.Async;importorg.springframework.stereotype.Service;importorg.springframework.util.CollectionUtils;importjava.io.*;importjava.text.ParseException;importjava.text.SimpleDateFormat;importjava.util.*;importjava.util.concurrent.CountDownLatch;importjava.util.concurrent.ExecutorService;importjava.util.concurrent.Executors;publicclass bigDataExport{/**
* excel 最大行数
*/privatestaticfinalInteger BIG_EXCEL_ROWS =20000;/**
* excel导出
*
* @param list 数据列表
* @param titleSerialN 生成Excel标题
* @param object 样式
* @param <E>
* @return
*/publicstatic<E>ByteArrayInputStreambigDataExport(List<E> list,String titleSerialN,Class<?extendsBaseRowModel> object){ByteArrayInputStream is;byte[] buffer;Map<String,byte[]> byteList =newHashMap<>();//大于多少行 进行多线程操作if(list.size()> BIG_EXCEL_ROWS){//页数int pageNum = list.size()/ BIG_EXCEL_ROWS;//取余int lastCount = list.size()% BIG_EXCEL_ROWS;// 计算几页int page = lastCount ==0? pageNum : pageNum +1;//倒计时锁CountDownLatch downLatch =newCountDownLatch(page);//定义线程池 按sheet设置线程池量ExecutorService executor =Executors.newFixedThreadPool(page);List<E> subList;for(int c =0; c <= pageNum; c++){int rowNum = BIG_EXCEL_ROWS;String title = titleSerialN +"_"+(c +1)+".xlsx";if(c == pageNum){if(lastCount ==0){continue;}
subList = list.subList(c * rowNum, c * rowNum + lastCount);}else{
subList = list.subList(c * rowNum,(c +1)* rowNum);}//动态生成文件名:
executor.execute(newPageThreadPool(downLatch, title, subList, object, byteList));}try{
downLatch.await();}catch(InterruptedException e){
e.printStackTrace();}
executor.shutdown();}else{ExcelWriter writer =null;Workbook workbook =null;ByteArrayOutputStream out =null;ByteArrayOutputStream bos =null;try{Sheet sheet1 =newSheet(1,0, object);
sheet1.setSheetName("sheet1");
out =newByteArrayOutputStream();
writer =newExcelWriter(out,ExcelTypeEnum.XLSX);
writer.write(list, sheet1);
workbook = writer.writeContext().getWorkbook();
bos =newByteArrayOutputStream();
workbook.write(bos);
byteList.put(titleSerialN +".xlsx", bos.toByteArray());}catch(IOException e){
e.printStackTrace();}finally{try{if(out !=null){
out.close();}if(bos !=null){
bos.close();}if(writer !=null){
writer.writeContext().finish(true);}}catch(IOException e){
e.printStackTrace();}}}
buffer =ZipUtils.zipFileSteam(byteList);
is =newByteArrayInputStream(buffer);return is;}}
将生成的 Excel 流 压缩为 Zip流
importlombok.extern.log4j.Log4j;importjava.io.*;importjava.util.Map;importjava.util.zip.ZipEntry;importjava.util.zip.ZipOutputStream;/**
* 压缩zip工具类
*/@Log4jpublicclassZipUtils{/**
* 压缩工具类
*
* @param byteList 文件字节码Map,k:fileName,v:byte[]
* @return 返回压缩流
*/publicstaticbyte[]zipFileSteam(Map<String,byte[]> byteList){byte[] buffer =null;ByteArrayOutputStream bos =null;try{
bos =newByteArrayOutputStream();ZipOutputStream zipOutputStream =newZipOutputStream(bos);
byteList.forEach((k, v)->{//写入一个条目,我们需要给这个条目起个名字,相当于起一个文件名称try{
zipOutputStream.putNextEntry(newZipEntry(k));
zipOutputStream.write(v);}catch(IOException e){
e.printStackTrace();
log.info(StringUtil.join(LogConstant.SERVICE,LogConstant.RESULT,LogConstant.FAIL,JSONUtil.toStr(e.getMessage())));}});//关闭条目
zipOutputStream.closeEntry();
zipOutputStream.close();
buffer = bos.toByteArray();}catch(IOException e){
e.printStackTrace();}finally{try{
bos.close();}catch(IOException e){
e.printStackTrace();}}return buffer;}
样式实体类
importcom.alibaba.excel.annotation.ExcelProperty;importcom.alibaba.excel.annotation.write.style.ColumnWidth;importcom.alibaba.excel.metadata.BaseRowModel;importio.swagger.annotations.ApiModelProperty;importlombok.Data;importjava.io.Serializable;importjava.math.BigDecimal;@Datapublicclass style extendsBaseRowModelimplementsSerializable{/**
* 日期 YYYY/MM/DD HH:MM:SS
*/@ExcelProperty(value="时间", index =0)@ColumnWidth(12)@ApiModelProperty(value ="时间")privateString dateTime;@ExcelProperty(value="交易时间", index =1)@ColumnWidth(12)@ApiModelProperty(value ="交易时间")privateString dealDatetime;@ExcelProperty(value="个人账户", index =2)@ColumnWidth(15)@ApiModelProperty(value ="个人账户")privateString accountName;@ExcelProperty(value="组名", index =3)@ColumnWidth(15)@ApiModelProperty(value ="组名")privateString groupName;
调用
publicstaticvoidmain(String[] args){/**
*
* list 从数据查出来的数据源
*
* is 打印 输出一个字节流
*
* AnpayAccountMoreDynamicBalanceDetailGridOut 样式
*/String titleSerialN ="生成的文档压缩.zip";List<?> list =newArrayList();InputStream is =null;
is =bigDataExport(list, titleSerialN, style.class);System.out.println("is = "+ is);}
注意:
- 当数据导出数量为 3W 时,项目启动后,第一次,第二次…直到 第四次时导出会抛出warn异常,但是都不会影响结果的导出,也没有准确报出代码中的行数
- 当数据导出 60W 时,项目启动后,第一次导出可以,第二次导出时会抛出抛出warn异常,也没有准确报出代码中的行数,但是都不会影响结果的导出
2022-04-0116:44:38.885[Finalizer] WARN com.alibaba.excel.ExcelWriter-Destroy object failed
com.alibaba.excel.exception.ExcelGenerateException:Can not close IO.
at com.alibaba.excel.context.WriteContextImpl.finish(WriteContextImpl.java:378)
at com.alibaba.excel.write.ExcelBuilderImpl.finish(ExcelBuilderImpl.java:95)
at com.alibaba.excel.ExcelWriter.finish(ExcelWriter.java:329)
at com.alibaba.excel.ExcelWriter.finalize(ExcelWriter.java:340)
at java.lang.System$2.invokeFinalize(System.java:1270)
at java.lang.ref.Finalizer.runFinalizer(Finalizer.java:102)
at java.lang.ref.Finalizer.access$100(Finalizer.java:34)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:217)Caused by:java.io.IOException:Stream closed
at java.io.BufferedWriter.ensureOpen(BufferedWriter.java:116)
at java.io.BufferedWriter.flushBuffer(BufferedWriter.java:126)
at java.io.BufferedWriter.flush(BufferedWriter.java:253)
at org.apache.poi.xssf.streaming.SheetDataWriter.close(SheetDataWriter.java:127)
at org.apache.poi.xssf.streaming.SXSSFSheet.getWorksheetXMLInputStream(SXSSFSheet.java:98)
at org.apache.poi.xssf.streaming.SXSSFWorkbook.injectData(SXSSFWorkbook.java:389)
at org.apache.poi.xssf.streaming.SXSSFWorkbook.write(SXSSFWorkbook.java:936)
at com.alibaba.excel.context.WriteContextImpl.finish(WriteContextImpl.java:339)...7 common frames omitted
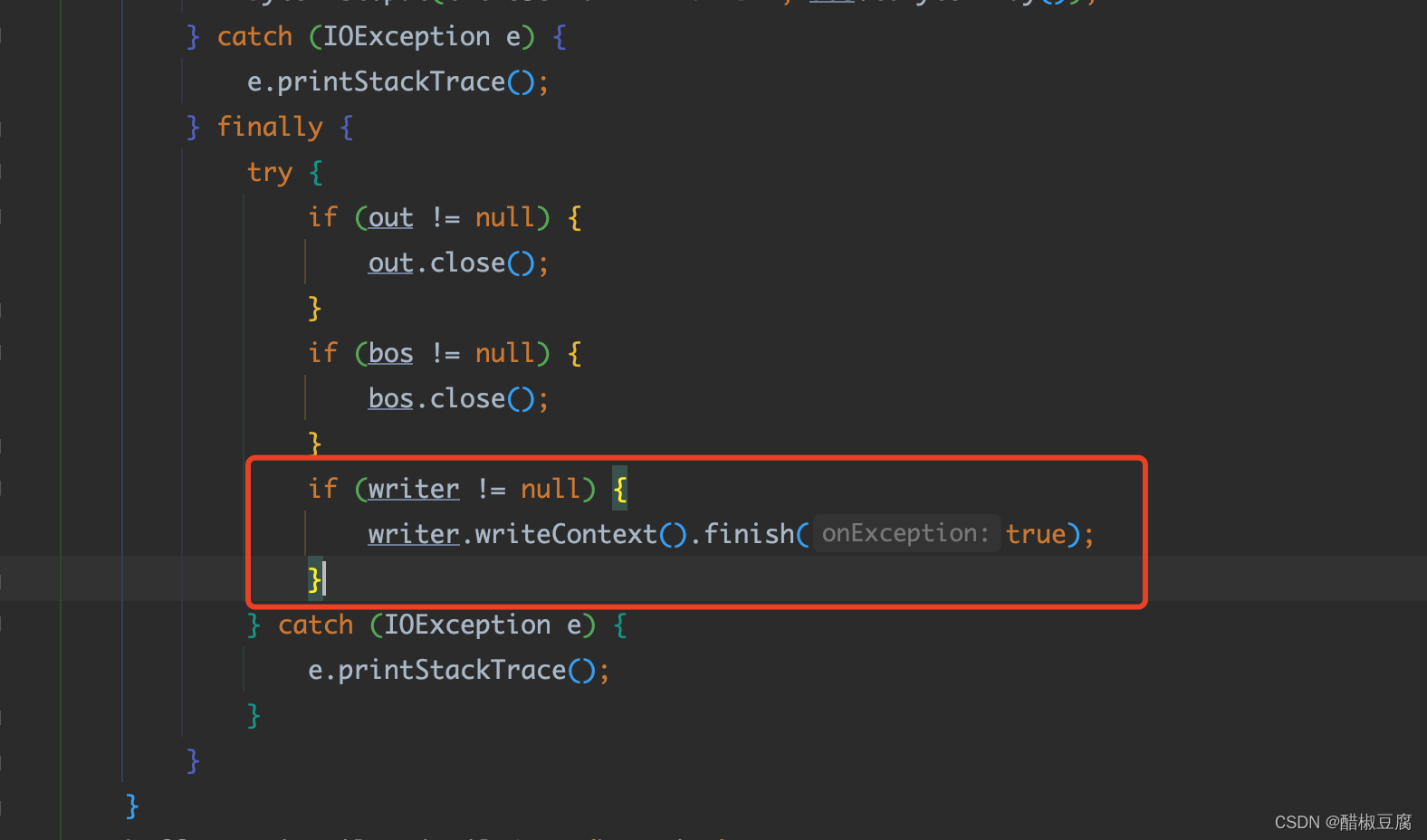
解决 Bug ,在 finally 中可以在 writeContext 强制抑制抛出异常,具体代码可见上面:
- Demo_Excel多线程大数据导出
Pom.xml
<dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>3.17</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-scratchpad</artifactId><version>3.17</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>3.17</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml-schemas</artifactId><version>3.17</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>ooxml-schemas</artifactId><version>1.4</version></dependency>
代码
通过 计算数据源条数 计算线程池的大小
importjava.util.ArrayList;importjava.util.HashMap;importjava.util.List;importjava.util.Map;importjava.util.concurrent.*;publicclassBigDataExport{publicstaticvoidmain(String[] args){int size =70__0000;List<Integer> list =newArrayList<>();for(int i =0; i < size; i++){
list.add(1);}//生成 excel 文件名String title ="GLOOX-SCATTER-CHART_SXSSFW_";//生成 ZIP 目录String zipFilePath ="/Users/fico/Downloads/";//生成 ZIP 文件名String zipFileName ="ZIP";long timeMillis =System.currentTimeMillis();System.out.println("开始 [导出Excel+打包ZIP] 时间为:"+ timeMillis);bigDataExport(list, title, zipFilePath, zipFileName);System.out.println("结束 [导出Excel+打包ZIP] 时间为:"+(System.currentTimeMillis()- timeMillis));}/**
* 默认一个文件 2W
*/publicstaticfinalint BIG_EXCEL_ROWS =2__0000;publicstatic<E>voidbigDataExport(List<E> list,String titleSerialN,String zipFilePath,String zipFileName){long timeMillis =System.currentTimeMillis();System.out.println("开始 导出excel 时间为:"+ timeMillis);Map<String,byte[]> byteList =newHashMap<>();//大于多少行 进行多线程操作if(list.size()> BIG_EXCEL_ROWS){//页数int pageNum = list.size()/ BIG_EXCEL_ROWS;//取余int lastCount = list.size()% BIG_EXCEL_ROWS;// 计算几页int page = lastCount ==0? pageNum : pageNum +1;//倒计时锁CountDownLatch downLatch =newCountDownLatch(page);//定义线程池 按 page 设置线程池量int processor =Runtime.getRuntime().availableProcessors();ExecutorService executor =Executors.newFixedThreadPool(page);List<E> subList;for(int c =0; c <= pageNum; c++){int rowNum = BIG_EXCEL_ROWS;String title = titleSerialN +"_"+(c +1)+".xlsx";if(c == pageNum){if(lastCount ==0){continue;}
subList = list.subList(c * rowNum, c * rowNum + lastCount);}else{
subList = list.subList(c * rowNum,(c +1)* rowNum);}//动态生成文件名:
executor.execute(newPageThreadPool(downLatch, title, subList, byteList));}try{
downLatch.await();}catch(InterruptedException e){
e.printStackTrace();}
executor.shutdown();}System.out.println("结束 导出excel 时间为:"+(System.currentTimeMillis()- timeMillis));if(byteList !=null){ZipUtils.zipFileSteam(byteList, zipFilePath, zipFileName);}}}
利用多线程 + SXSSFWorkbook (excel 大文件一定要用这个)生成 excel 流 放入 Map<excel文件名,excel流>
importorg.apache.poi.xssf.streaming.SXSSFRow;importorg.apache.poi.xssf.streaming.SXSSFSheet;importorg.apache.poi.xssf.streaming.SXSSFWorkbook;importjava.io.ByteArrayOutputStream;importjava.io.IOException;importjava.util.List;importjava.util.Map;importjava.util.concurrent.CountDownLatch;/**
* 导出new线程池工具类
*/publicclassPageThreadPool<E>implementsRunnable{privateCountDownLatch countDownLatch;privateString title;privateMap<String,byte[]> byteList;privateList<E> list;publicPageThreadPool(CountDownLatch countDownLatch,String title,List<E> list,Map<String,byte[]> byteList){this.countDownLatch = countDownLatch;this.title = title;this.list = list;this.byteList = byteList;}@Overridepublicvoidrun(){ByteArrayOutputStream bos =newByteArrayOutputStream();SXSSFWorkbook workbook =null;try{//默认100行,超100行将写入临时文件
workbook =newSXSSFWorkbook();//压缩临时文件,很重要,否则磁盘很快就会被写满
workbook.setCompressTempFiles(true);SXSSFSheet sheet = workbook.createSheet("sheet");for(int j =0; j < list.size(); j++){SXSSFRow row = sheet.createRow(j);for(int k =0; k <10; k++){
row.createCell(k).setCellValue(newRandom().nextInt(10));}}
workbook.write(bos);//put 文件名和文件字节数组
byteList.put(this.title, bos.toByteArray());}catch(Exception e){
e.printStackTrace();}finally{try{if(bos !=null){
bos.close();}// 删除临时文件,很重要,否则磁盘可能会被写满if(workbook !=null){
workbook.dispose();}}catch(IOException e){
e.printStackTrace();}if(countDownLatch !=null){
countDownLatch.countDown();}}}}
将 Map<K,V> 压缩成ZIP 流并生成本地文件
importjava.io.*;importjava.util.Map;importjava.util.zip.ZipEntry;importjava.util.zip.ZipOutputStream;publicclassZipUtils{/**
* 压缩工具类
*
* @param byteList 文件字节码Map,k:fileName,v:byte[]
* @return 返回压缩流
*//**
*
* @param byteList 文件字节码Map,k:fileName,v:byte[]
* @param zipFilePath ZIP 生成目录
* @param zipFileName ZIP 文件名
*/publicstaticvoidzipFileSteam(Map<String,byte[]> byteList,String zipFilePath,String zipFileName){long timeMillis =System.currentTimeMillis();System.out.println("开始生成 ZIP 开始时间为:"+ timeMillis);//如果文件夹不存在就创建文件夹,防止报错File file =newFile(zipFilePath);if(!file.exists()&&!file.isDirectory()){System.out.println("文件夹不存在,创建新文件夹!");
file.mkdirs();}try{FileOutputStream fileOutputStream =newFileOutputStream(String.format("%s%s%s", zipFilePath, zipFileName,".zip"));ZipOutputStream zipOutputStream =newZipOutputStream(fileOutputStream);
byteList.forEach((k, v)->{//写入一个条目,我们需要给这个条目起个名字,相当于起一个文件名称try{
zipOutputStream.putNextEntry(newZipEntry(k));
zipOutputStream.write(v);}catch(IOException e){
e.printStackTrace();}});//关闭条目
zipOutputStream.closeEntry();
zipOutputStream.close();System.out.println("结束生成 ZIP 结束时间为:"+(System.currentTimeMillis()- timeMillis));}catch(IOException e){
e.printStackTrace();}}/**
* 将文件转换成byte数组
*
* @param filePath 文件File类 通过new File(文件路径)
* @return byte数组
*/publicstaticbyte[]File2byte(File filePath){byte[] buffer =null;FileInputStream fis =null;ByteArrayOutputStream bos =null;try{
fis =newFileInputStream(filePath);
bos =newByteArrayOutputStream();byte[] b =newbyte[1024];int n;while((n = fis.read(b))!=-1){
bos.write(b,0, n);}
fis.close();
bos.close();
buffer = bos.toByteArray();}catch(FileNotFoundException e){
e.printStackTrace();}catch(IOException e){
e.printStackTrace();}finally{try{if(fis !=null){
fis.close();}if(bos !=null){
bos.close();}}catch(IOException e){
e.printStackTrace();}}return buffer;}}
- 多快
导出数据条数为 :700200 条
开始 [导出Excel+打包ZIP] 时间(毫秒)为:1649140344506
开始 导出excel 时间(毫秒)为:1649140344506
结束 导出excel 时间(毫秒)为:9581
开始生成 ZIP 开始时间(毫秒)为:1649140354097
结束生成 ZIP 结束时间(毫秒)为:2258
结束 [导出Excel+打包ZIP] 时间(毫秒)为:11849
本文转载自: https://blog.csdn.net/weixin_44748605/article/details/123965559
版权归原作者 醋椒豆腐 所有, 如有侵权,请联系我们删除。
版权归原作者 醋椒豆腐 所有, 如有侵权,请联系我们删除。