
一、基础介绍
FIO是一个开源的I/O压力测试工具,主要是用来测试磁盘的IO性能,也可测试cpu,nic的IO性能。它可以支持13种不同的I/O引擎,包括:sync,mmap, libaio, posixaio, SG v3, splice, network, syslet, guasi, solarisaio, I/Opriorities (针对新的Linux内核), rate I/O, forked or threaded jobs等。
FIO使用简单,支持的文件操作非常多,基本可以覆盖到常用的的文件使用方式
二、安装
本次以centos7环境为例
yum install fio
三、fio使用
基础命令
fio --filename=/dev/sda --bs=4k --ioengine=libaio --iodepth=32 --direct=1 --rw=randwrite --time_based --runtime=600 --refill_buffers --norandommap --randrepeat=0 --group_reporting --name=fio-randwrite-iops --size=10G
参数解释
–filename
待测试的文件或块设备
若为文件,则代表测试文件系统的性能;例:–filename=/opt/test.img
若为块设备,则代表测试裸设备的性能; 例:–filename=/dev/sda
–bs
单次IO的块大小(测试磁盘的io,尽量使用小文件)
–bsrange
bsrange=512-2048 数据块的大小范围
–ioengine
采用的文件读写方式
- –sync:采用read,write,使用fseek定位读写位置。
- –psync:采用pread、pwrite进行文件读写操作
- –vsync:采用readv(2) orwritev(2)进行文件读写操作
read()和write()系统调用每次在文件和进程的地址空间之间传送一块连续的数据。但是,应用有时也需要将分散在内存多处地方的数据连续写到文件中,或者反之。在这种情况下,如果要从文件中读一片连续的数据至进程的不同区域,使用read()则要么一次将它们读至一个较大的缓冲区中,然后将它们分成若干部分复制到不同的区域,要么调用read()若干次分批将它们读至不同区域。同样,如果想将程序中不同区域的数据块连续地写至文件,也必须进行类似的处理。UNIX提供了另外两个函数—readv()和writev(),它们只需一次系统调用就可以实现在文件和进程的多个缓冲区之间传送数据,免除了多次系统调用或复制数据的开销。readv()称为散布读,即将文件中若干连续的数据块读入内存分散的缓冲区中。writev()称为聚集写,即收集内存中分散的若干缓冲区中的数据写至文件的连续区域中。
- –libaio:Linux异步读写IO(Linuxnative asynchronous I/O)
- –posixaio: glibc POSIX 异步IO读写,使用aio_read(3)and aio_write(3)实现IO读写。
–iodepth
IO队列深入,即一次下发的IO的个数
–direct
当前测试是否采用直接IO方式进行读写,如果采用直接IO,则取值-direct=1,否则取值-direct=0。
采用直接IO写测试,会使得测试结果更加真实。
–rw
读写模式。
- read:顺序读测试,使用方式–rw=read
- write:顺序写测试,使用方式–rw=write
- randread:随机读测试,使用方式–rw=randread
- randwrite:随机写测试,使用方式–rw=randwrite
- randrw:随机读写,–rw=randrw;默认比率为5:5,通过参数–rwmixread设定读的比率,如–rw=randrw-rwmixread=70,说明读写比率为70:30。或rwmixwrite
–rwmixwrite
rwmixwrite=30 在混合读写的模式下,写占30%
–time_based
如果设置的job已被完全读写或写完,也会执行完runtime规定的时间。它是通过循环执行相同的负载来实现的。加上这个参数可以防止job提前结束。
–runtime
测试运行时间,单位为s
–refill_buffers
每次提交后都重复填充io buffer
–norandommap
在进行随机 I/O 时,FIO 将覆盖文件的每个块。若给出此参数,则将选择新的偏移量而不查看 I/O 历史记录。
–randrepeat
对于随机IO负载,配置生成器的种子,使得路径是可以预估的,使得每次重复执行生成的序列是一样的
–lockmem
测试的收使用的内存大小
–group_reporting
关于显示结果的,汇总每个进程的信息
–name
测试结果输出的文件名称
–size
测试的文件大小
– nrfiles
每个进程生成的文件数量
– zero_buffers
用0初始化系统buffer
– randrepeat
随机序列是否可重复,True(1)表示随机序列可重复,False(0)表示随机序列不可重复。默认为 True(1)。
– sync
设置同步模式,同步–sync=1,异步–sync=0
– fsync
设置数据同步模式,同步-fsync=1,异步-fsync=0(有一个io就同步)
– numjobs
测试进程的并发数,默认为16(这个值和cpu数量有关)
四、测试结果
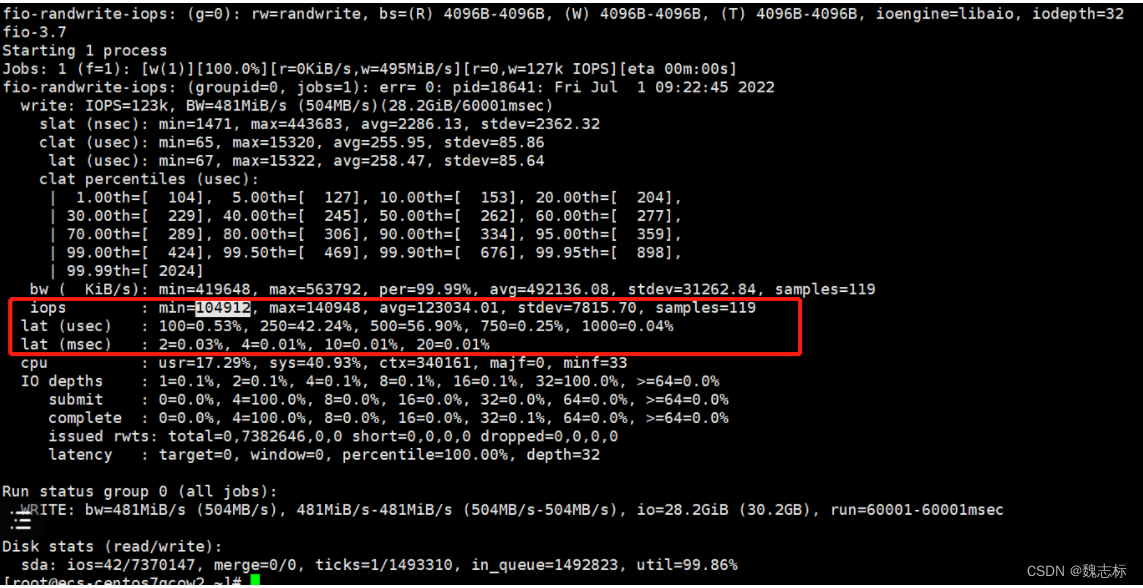
结果解释
可以看到iops值为123K,带宽为481MiB
IO depths中可以看到在submit和complete在4=100%时测试已经完成,所以使用iodepth值时,并非越大越好
版权归原作者 魏志标 所有, 如有侵权,请联系我们删除。