
汝之观览,吾之幸也!本文主要讲解Hadoop运行环境的搭建(三台虚拟机),一键脚本部署,全自动化,不再需要按照文档一个一个进行配置,脚本执行后就可登录hadoop集群。
文章目录
一、最小安装CentOS
如果使用Vmware安装虚拟机请看【大数据】用VMware搭建自己的虚拟机(选择最小安装,内存4G、磁盘50G)
最小安装好虚拟机后一般使用ifconfig 查看ip,但最小安装后是没有这个命令,我们也可以使用 ip addr show查看
ip addr show
二、准备jdk与hadoop包
在/opt 目录下建software、module文件夹,将压缩包放到software下
具体安装包可加公众号【纯码农(purecodefarmer)】输入“hadoop”即可获取下载链接
三、一键部署脚本分解
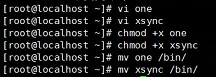
新建one、xsync脚本放到/bin目录下,赋权限
chmod +x one
chmod +x xsync
mv one /bin/
mv xsync /bin/
1、安装工具包
expect:expect工具包,实现自动交互功能
epel-release:额外的软件源,就可以安装更多的软件包
psmisc:工具包
nc:工具包
net-tools:网络工具(ifconfig)
rsync:远程同步
vim:vim编辑器
lrzsz: 同步
ntp:时间同步
git:git库
libzstd、openssl-static、tree、 iotop:hadoop的标准库
脚本内容
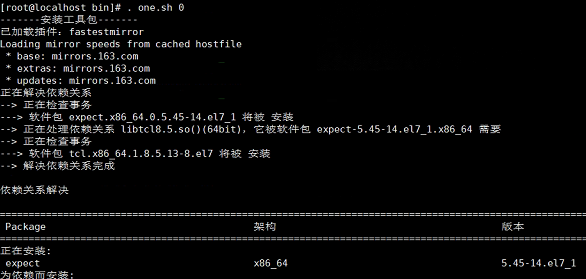
yum install -y expect
yum install -y epel-release
yum install -y psmisc nc net-tools rsyncvim lrzsz ntp libzstd openssl-static tree iotop git
执行脚本命令
one 0
2、修改主机名
脚本内容
echo"-------修改系统名称-------"
hostnamectl --static set-hostname $1
执行脚本命令
one 2 hdp101 101
3、修改ip
脚本内容
echo"-------修改IP静态地址-------"#先检查文件是否已被修改过chk=`cat /etc/sysconfig/network-scripts/ifcfg-ens33 |grep static`if["$chk"==""];then#修改/etc/sysconfig/network-scripts/ifcfg-ens33文件中的dhcpsed -i 's/dhcp/static/' /etc/sysconfig/network-scripts/ifcfg-ens33
echo"IPADDR=192.168.10.$1">> /etc/sysconfig/network-scripts/ifcfg-ens33
echo"NETMASK=255.255.255.0">> /etc/sysconfig/network-scripts/ifcfg-ens33
echo"GATEWAY=192.168.10.2">> /etc/sysconfig/network-scripts/ifcfg-ens33
echo"DNS1=192.168.10.2">> /etc/sysconfig/network-scripts/ifcfg-ens33
echo"PREFIX=24">> /etc/sysconfig/network-scripts/ifcfg-ens33
systemctl restart network
elsesed -i "s/IPADDR=192.168.10.101/IPADDR=192.168.10."$1"/" /etc/sysconfig/network-scripts/ifcfg-ens33
systemctl restart network
fi
执行脚本命令
one 3 hdp101 101
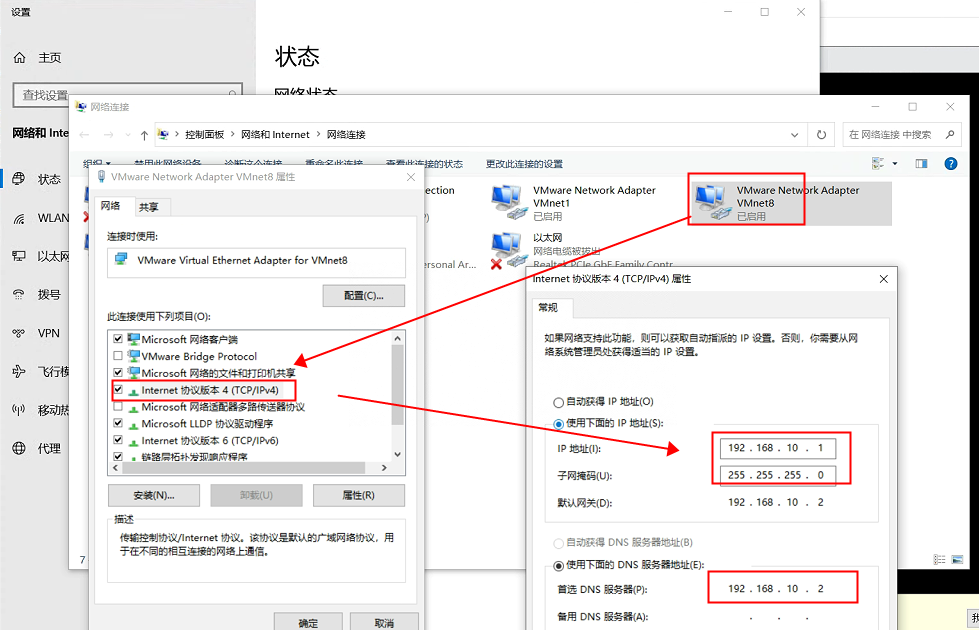
备注:需要看本机的ip与网关,修改ip之后需要重新登录
4、关闭防火墙
脚本内容
echo"-------关闭防火墙-------"
systemctl stop firewalld
systemctl disable firewalld
执行脚本命令
one 4

5、创建用户
脚本内容
echo"请注意,在创建用户时会先对该用户进行删除操作以确保脚本运行成功, 如已有该用户请慎重输入用户名!"read -p "继续请输入 1 ,停止请输入 2. : " IS_CONTINUE
if[${IS_CONTINUE} -ne 1];thenecho"停止运行该脚本!"exitfiread -p "请输入新增用户用户名 : " username
read -p "请输入新增用户密码 : " password
userdel -r ${username}useradd -d /home/${username}${username}expect -c"
spawn passwd ${username}
expect {
"*yes/no*" {send "yes\r";exp_continue}
"*New password:*" {send "${password}\r";exp_continue}
"*Retype new password:*" {send "${password}\r";exp_continue}
}"echo"配置新增用户root权限"sed -i "93a "${username}" ALL=(ALL) NOPASSWD:ALL" /etc/sudoers
echo"创建software、module文件夹"mkdir /opt/module /opt/software
chown${username}:${username} /opt/module /opt/software
echo"切换用户"su - ${username}
执行脚本命令
one 1

6、解压jdk压缩包并配置jdk的环境变量
先建好文件夹
mkdir /opt/software /opt/module
脚本内容
echo"-------安装JDK并配置环境变量-------"#检查JDK是否已经安装过
check_soft_folder jdk8
if[$?==1];then#在opt文件夹下搜索jdk的tar.gz文件jdkName=`ls /opt/software/ |grep jdk*`#将文件解压到对应的soft文件夹下tar -zxvf /opt/software/$jdkName -C /opt/module/jdk8 --strip-components 1#配置/etc/profile文件sudotouch /etc/profile.d/my_env.sh
echo"配置jdk环境变量"echo"">> /etc/profile.d/my_env.sh
echo"#java environment">> /etc/profile.d/my_env.sh
echo"export JAVA_HOME=/opt/module/jdk8">> /etc/profile.d/my_env.sh
echo"export CLASSPATH=.:\${JAVA_HOME}/jre/lib/rt.jar:\${JAVA_HOME}/lib/dt.jar:\${JAVA_HOME}/lib/tools.jar">> /etc/profile.d/my_env.sh
echo"export PATH=\$PATH:\${JAVA_HOME}/bin">> /etc/profile.d/my_env.sh
fi
执行脚本命令
one 5
7、解压hadoop压缩包并配置hadoop的环境变量
脚本内容
echo"-------安装Hadoop并配置环境变量-------"#检查JDK是否已经安装过
check_soft_folder hadoop330
if[$?==1];then#在opt文件夹下搜索Hadoop的tar.gz文件hadoopName=`ls /opt/software/ |grep hadoop*`#将文件解压到对应的soft文件夹下tar -zxvf /opt/software/$hadoopName -C /opt/module/hadoop330 --strip-components 1#配置/etc/profile.d/my_env.sh文件echo"配置hadoop环境变量"echo"">> /etc/profile.d/my_env.sh
echo"#hadoop environment">> /etc/profile.d/my_env.sh
echo"export HADOOP_HOME=/opt/module/hadoop330">> /etc/profile.d/my_env.sh
echo"export PATH=\$PATH:\${HADOOP_HOME}/bin">> /etc/profile.d/my_env.sh
echo"export PATH=\$PATH:\${HADOOP_HOME}/sbin">> /etc/profile.d/my_env.sh
fi
执行脚本命令
one 6
备注:非root用户配置环境变量
touch /etc/profile.d/my_env.sh
将下面的内容复制到my_env.sh中
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk8
export PATH=$PATH:$JAVA_HOME/bin
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop330
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
8、克隆虚拟机(无脚本)

9、分发脚本xsync
脚本内容
# 获取输入参数个数,如果没有参数,直接退出pcount=$#if((pcount==0));thenecho no args...;exit;fi# 获取文件名称pname=$1fname=`basename $pname`echofname=$fname# 获取上级目录到绝对路径pdir=`cd -P $(dirname $pname);pwd`echopdir=$pdir# 获取当前用户名称user=`whoami`# 循环for((host=2; host<=3; host++));doecho$pdir/$fname$user@hdp10$host:$pdirecho==================hdp10$host==================rsync -rvl $pdir/$fname$user@hdp10$host:$pdirdone#Note:这里的slave对应自己主机名,需要做相应修改。另外,for循环中的host的边界值
执行脚本命令
xsync /bin/one
xsync /bin/xsync
备注:在101修改配置文件后可使用xsync命令将所修改的文件分发到102、103
8、免密登录
脚本内容
echo"-------免密登录-------"if[! -f ~/.ssh/id_rsa ];thenecho"-------生成ssh密钥-------"
ssh-keygen -t rsa
expect -c"
expect {
"*.ssh/id_rsa*" {send "\r";exp_continue}
"*empty for no passphrase:*" {send "\r";exp_continue}
"*fingerprint is:*" {send "\r";exp_continue}
}"echo"-------分发密钥-------"forhostin hdp101 hdp102 hdp103
do
ssh-copy-id $hostdoneelseecho"-------id_rsa已存在,直接分发-------"forhostin hdp101 hdp102 hdp103
do
ssh-copy-id $hostdonefi
执行脚本命令
one 8
备注:需要在101、102都执行一次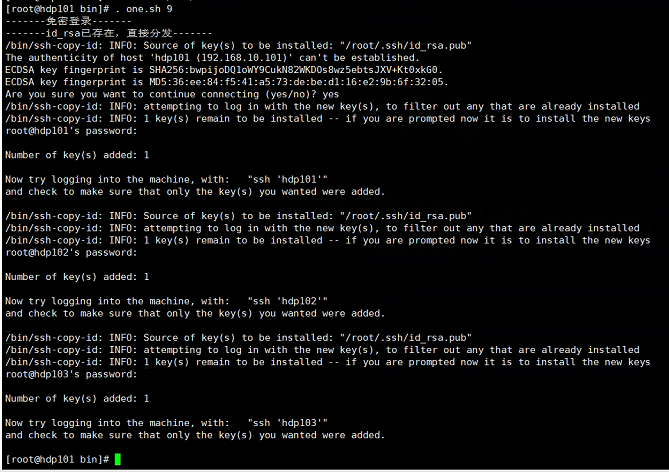
8、配置当前的hadoop配置文件
脚本内容
cd /opt/module/hadoop330/etc/hadoop
# 配置hadoop-env.sh文件sed -i '25c export JAVA_HOME=/opt/module/jdk8' hadoop-env.sh
echo"-------配置hadoop-env.sh文件完成------"# 配置core-site.xml文件 root是用户名,可更改sed -i '19a <property>' core-site.xml
sed -i '20a <name>fs.defaultFS</name>' core-site.xml
sed -i '21a <value>hdfs://hdp101:8020</value>' core-site.xml
sed -i '22a </property>' core-site.xml
sed -i '23a <property>' core-site.xml
sed -i '24a <name>hadoop.data.dir</name>' core-site.xml
sed -i '25a <value>/opt/module/hadoop330/data</value>' core-site.xml
sed -i '26a </property>' core-site.xml
sed -i '27a <property>' core-site.xml
sed -i '28a <name>hadoop.proxyuser.root.groups</name>' core-site.xml
sed -i '29a <value>*</value>' core-site.xml
sed -i '30a </property>' core-site.xml
sed -i '31a <property>' core-site.xml
sed -i '32a <name>hadoop.proxyuser.root.hosts</name>' core-site.xml
sed -i '33a <value>*</value>' core-site.xml
sed -i '34a </property>' core-site.xml
echo"-------配置core-site.xml文件完成-------"# 配置hdfs-site.xml文件sed -i '19a <property>' hdfs-site.xml
sed -i '20a <name>dfs.namenode.secondary.http-address</name>' hdfs-site.xml
sed -i '21a <value>hdp103:9868</value>' hdfs-site.xml
sed -i '22a </property>' hdfs-site.xml
sed -i '23a <property>' hdfs-site.xml
sed -i '24a <name>dfs.namenode.name.dir</name>' hdfs-site.xml
sed -i '25a <value>file://${hadoop.data.dir}/name</value>' hdfs-site.xml
sed -i '26a </property>' hdfs-site.xml
sed -i '27a <property>' hdfs-site.xml
sed -i '28a <name>dfs.datanode.data.dir</name>' hdfs-site.xml
sed -i '29a <value>file://${hadoop.data.dir}/data</value>' hdfs-site.xml
sed -i '30a </property>' hdfs-site.xml
sed -i '31a <property>' hdfs-site.xml
sed -i '32a <name>dfs.namenode.checkpoint.dir</name>' hdfs-site.xml
sed -i '33a <value>file://${hadoop.data.dir}/namesecondary</value>' hdfs-site.xml
sed -i '34a </property>' hdfs-site.xml
sed -i '35a <property>' hdfs-site.xml
sed -i '36a <name>dfs.client.datanode-restart.timeout</name>' hdfs-site.xml
sed -i '37a <value>30</value>' hdfs-site.xml
sed -i '38a </property>' hdfs-site.xml
sed -i '39a <property>' hdfs-site.xml
sed -i '40a <name>dfs.namenode.http-address</name>' hdfs-site.xml
sed -i '41a <value>hadoop101:9870</value>' hdfs-site.xml
sed -i '42a </property>' hdfs-site.xml
echo"-------配置hdfs-site.xml文件完成-------"# 配置yarn-site.xml文件sed -i '18a <property>' yarn-site.xml
sed -i '19a <name>yarn.resourcemanager.hostname</name>' yarn-site.xml
sed -i '20a <value>hdp102</value>' yarn-site.xml
sed -i '21a </property>' yarn-site.xml
sed -i '22a <property>' yarn-site.xml
sed -i '23a <name>yarn.nodemanager.aux-services</name>' yarn-site.xml
sed -i '24a <value>mapreduce_shuffle</value>' yarn-site.xml
sed -i '25a </property>' yarn-site.xml
sed -i '26a <property>' yarn-site.xml
sed -i '27a <name>yarn.nodemanager.env-whitelist</name>' yarn-site.xml
sed -i '28a <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>' yarn-site.xml
sed -i '29a </property>' yarn-site.xml
echo"-------配置yarn-site.xml文件完成-------"# 配置mapred-site.xmlsed -i '20a <property>' mapred-site.xml
sed -i '21a <name>mapreduce.framework.name</name>' mapred-site.xml
sed -i '22a <value>yarn</value>' mapred-site.xml
sed -i '23a </property>' mapred-site.xml
echo"-------配置mapred-site.xml文件完成-------"# 配置workerssed -i '2a hdp101' workers
sed -i '3a hdp102' workers
sed -i '4a hdp103' workers
echo"-------配置workers文件完成-------"# 配置hadoop-env.shsed -i '26a export HDFS_NAMENODE_USER=root' hadoop-env.sh
sed -i '27a export HDFS_SECONDARYNAMENODE_USER=root' hadoop-env.sh
sed -i '28a export HDFS_DATANODE_USER=root' hadoop-env.sh
echo"-------配置hadoop-env.sh文件完成-------"cd /opt/module/hadoop330/sbin
sed -i '2a HDFS_DATANODE_USER=root' start-dfs.sh
sed -i '3a HDFS_DATANODE_SECURE_USER=hdfs' start-dfs.sh
sed -i '4a HDFS_NAMENODE_USER=root' start-dfs.sh
sed -i '5a HDFS_SECONDARYNAMENODE_USER=root' start-dfs.sh
echo"-------配置start-dfs.sh文件完成-------"sed -i '2a HDFS_DATANODE_USER=root' stop-dfs.sh
sed -i '3a HDFS_DATANODE_SECURE_USER=hdfs' stop-dfs.sh
sed -i '4a HDFS_NAMENODE_USER=root' stop-dfs.sh
sed -i '5a HDFS_SECONDARYNAMENODE_USER=root' stop-dfs.sh
echo"-------配置stop-dfs.sh文件完成-------"sed -i '2a YARN_RESOURCEMANAGER_USER=root' start-yarn.sh
sed -i '3a HDFS_DATANODE_SECURE_USER=yarn' start-yarn.sh
sed -i '4a YARN_NODEMANAGER_USER=root' start-yarn.sh
echo"-------配置start-yarn.sh文件完成-------"sed -i '2a YARN_RESOURCEMANAGER_USER=root' stop-yarn.sh
sed -i '3a HDFS_DATANODE_SECURE_USER=yarn' stop-yarn.sh
sed -i '4a YARN_NODEMANAGER_USER=root' stop-yarn.sh
echo"-------配置stop-yarn.sh文件完成-------"# 格式化namenode并启动hadoop
hadoop namenode -format
echo"-------格式化namenode完成-------"
执行脚本命令
one 9
11、一键启动hadoop集群
脚本内容
echo"-------hadoop集群启动-------"echo" --------------- 启动 hdfs ---------------"ssh hdp101 "/opt/module/hadoop330/sbin/start-dfs.sh"echo" --------------- 启动 yarn ---------------"ssh hdp102 "/opt/module/hadoop330/sbin/start-yarn.sh"echo" --------------- 启动 historyserver ---------------"ssh hdp102 "/opt/module/hadoop330/bin/mapred --daemon start historyserver"
执行脚本命令
one 10
12、一键停止hadoop集群
脚本内容
echo"-------hadoop集群停止-------"echo" --------------- 关闭 historyserver ---------------"ssh hdp102 "/opt/module/hadoop330/bin/mapred --daemon stop historyserver"echo" --------------- 关闭 yarn ---------------"ssh hdp102 "/opt/module/hadoop330/sbin/stop-yarn.sh"echo" --------------- 关闭 hdfs ---------------"ssh hdp101 "/opt/module/hadoop330/sbin/stop-dfs.sh"
执行脚本命令
one 11
13、查看hadoop集群
jps
四、一键部署脚本集合
脚本内容
#!/bin/bash# 安装工具包install_package(){echo"-------安装工具包-------"
yum install -y expect
yum install -y epel-release
yum install -y psmisc nc net-tools rsyncvim lrzsz ntp libzstd openssl-static tree iotop git dos2unix
}# 统一配置hosts文件modify_syshosts(){echo"-------修改hosts文件-------"forhostsin101102103104105106doecho"192.168.10."$hosts" hdp"$hosts"">> /etc/hosts
done}#修改系统名称 同时修改hosts文件modify_sysname(){echo"-------修改系统名称-------"
hostnamectl --static set-hostname $1}#修改IP静态地址modify_staticip(){echo"-------修改IP静态地址-------"#先检查文件是否已被修改过chk=`cat /etc/sysconfig/network-scripts/ifcfg-ens33 |grep static`if["$chk"==""];then#修改/etc/sysconfig/network-scripts/ifcfg-ens33文件中的dhcpsed -i 's/dhcp/static/' /etc/sysconfig/network-scripts/ifcfg-ens33
echo"IPADDR=192.168.10.$1">> /etc/sysconfig/network-scripts/ifcfg-ens33
echo"NETMASK=255.255.255.0">> /etc/sysconfig/network-scripts/ifcfg-ens33
echo"GATEWAY=192.168.10.2">> /etc/sysconfig/network-scripts/ifcfg-ens33
echo"DNS1=192.168.10.2">> /etc/sysconfig/network-scripts/ifcfg-ens33
echo"PREFIX=24">> /etc/sysconfig/network-scripts/ifcfg-ens33
systemctl restart network
elsesed -i "s/IPADDR=192.168.10.101/IPADDR=192.168.10."$1"/" /etc/sysconfig/network-scripts/ifcfg-ens33
systemctl restart network
fi}#关闭防火墙close_firewalld(){echo"-------关闭防火墙-------"
systemctl stop firewalld
systemctl disable firewalld
}#修改yum源为阿里源modify_yumsource(){echo"-------修改yum源为阿里源-------"# 检查是否已有备份文件 如果有则说明已经做过了if[ -e /etc/yum.repos.d/CentOS-Base.repo_bak ];thenecho"don't nothing!"else#首先安装wget命令
yum install -y wget#修改yumcd /etc/yum.repos.d/
mv CentOS-Base.repo CentOS-Base.repo_bak
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
yum makecache
ficd /
}# 创建用户并切换用户add_user(){echo"请注意,在创建用户时会先对该用户进行删除操作以确保脚本运行成功, 如已有该用户请慎重输入用户名!"read -p "继续请输入 1 ,停止请输入 2. : " IS_CONTINUE
if[${IS_CONTINUE} -ne 1];thenecho"停止运行该脚本!"exitfiread -p "请输入新增用户用户名 : " username
read -p "请输入新增用户密码 : " password
userdel -r ${username}useradd -d /home/${username}${username}expect -c"
spawn passwd ${username}
expect {
"*yes/no*" {send "yes\r";exp_continue}
"*New password:*" {send "${password}\r";exp_continue}
"*Retype new password:*" {send "${password}\r";exp_continue}
}"echo"配置新增用户root权限"sed -i "93a "${username}" ALL=(ALL) NOPASSWD:ALL" /etc/sudoers
echo"创建software、module文件夹"mkdir /opt/module /opt/software
chown${username}:${username} /opt/module /opt/software
echo"切换用户"su - ${username}}#检查文件的文件夹是否存在不存在就创建1个check_soft_folder(){echo"-------检查文件夹是否存在-------"if[ -e /opt/module/$1];thenecho"/opt/module/$1 folder already exists"rm -rf $1return1elsemkdir /opt/module/$1return1fi}#安装JDK 软件目录必须在/opt/software下 jdk目录命名为jdk8setup_jdk(){echo"-------安装JDK并配置环境变量-------"#检查JDK是否已经安装过
check_soft_folder jdk8
if[$?==1];then#在opt文件夹下搜索jdk的tar.gz文件jdkName=`ls /opt/software/ |grep jdk*`#将文件解压到对应的soft文件夹下tar -zxvf /opt/software/$jdkName -C /opt/module/jdk8 --strip-components 1#配置/etc/profile文件sudotouch /etc/profile.d/my_env.sh
echo"配置jdk环境变量"echo"">> /etc/profile.d/my_env.sh
echo"#java environment">> /etc/profile.d/my_env.sh
echo"export JAVA_HOME=/opt/module/jdk8">> /etc/profile.d/my_env.sh
echo"export CLASSPATH=.:\${JAVA_HOME}/jre/lib/rt.jar:\${JAVA_HOME}/lib/dt.jar:\${JAVA_HOME}/lib/tools.jar">> /etc/profile.d/my_env.sh
echo"export PATH=\$PATH:\${JAVA_HOME}/bin">> /etc/profile.d/my_env.sh
fi}#安装Hadoop 软件目录必须在/opt/software下 hadoop目录命名为hadoop330setup_hadoop(){echo"-------安装Hadoop并配置环境变量-------"#检查JDK是否已经安装过
check_soft_folder hadoop330
if[$?==1];then#在opt文件夹下搜索Hadoop的tar.gz文件hadoopName=`ls /opt/software/ |grep hadoop*`#将文件解压到对应的soft文件夹下tar -zxvf /opt/software/$hadoopName -C /opt/module/hadoop330 --strip-components 1#配置/etc/profile.d/my_env.sh文件echo"配置hadoop环境变量"echo"">> /etc/profile.d/my_env.sh
echo"#hadoop environment">> /etc/profile.d/my_env.sh
echo"export HADOOP_HOME=/opt/module/hadoop330">> /etc/profile.d/my_env.sh
echo"export PATH=\$PATH:\${HADOOP_HOME}/bin">> /etc/profile.d/my_env.sh
echo"export PATH=\$PATH:\${HADOOP_HOME}/sbin">> /etc/profile.d/my_env.sh
fi}IP_LIST=(
hdp101
hdp102
hdp103
)# 生成ssh密钥,用于免密登录create_ssh(){echo"-------免密登录-------"if[! -f ~/.ssh/id_rsa ];thenecho"-------生成ssh密钥-------"
ssh-keygen -t rsa
expect -c"
expect {
"*.ssh/id_rsa*" {send "\r";exp_continue}
"*empty for no passphrase:*" {send "\r";exp_continue}
"*fingerprint is:*" {send "\r";exp_continue}
}"echo"-------分发密钥-------"forhostin hdp101 hdp102 hdp103
do
ssh-copy-id $hostdoneelseecho"-------id_rsa已存在,直接分发-------"forhostin hdp101 hdp102 hdp103
do
ssh-copy-id $hostdonefi}# hadoop配置脚本hadoop_config(){cd /opt/module/hadoop330/etc/hadoop
# 配置hadoop-env.sh文件sed -i '25c export JAVA_HOME=/opt/module/jdk8' hadoop-env.sh
echo"-------配置hadoop-env.sh文件完成------"# 配置core-site.xml文件 root是用户名,可更改sed -i '19a <property>' core-site.xml
sed -i '20a <name>fs.defaultFS</name>' core-site.xml
sed -i '21a <value>hdfs://hdp101:8020</value>' core-site.xml
sed -i '22a </property>' core-site.xml
sed -i '23a <property>' core-site.xml
sed -i '24a <name>hadoop.data.dir</name>' core-site.xml
sed -i '25a <value>/opt/module/hadoop330/data</value>' core-site.xml
sed -i '26a </property>' core-site.xml
sed -i '27a <property>' core-site.xml
sed -i '28a <name>hadoop.proxyuser.root.groups</name>' core-site.xml
sed -i '29a <value>*</value>' core-site.xml
sed -i '30a </property>' core-site.xml
sed -i '31a <property>' core-site.xml
sed -i '32a <name>hadoop.proxyuser.root.hosts</name>' core-site.xml
sed -i '33a <value>*</value>' core-site.xml
sed -i '34a </property>' core-site.xml
echo"-------配置core-site.xml文件完成-------"# 配置hdfs-site.xml文件sed -i '19a <property>' hdfs-site.xml
sed -i '20a <name>dfs.namenode.secondary.http-address</name>' hdfs-site.xml
sed -i '21a <value>hdp103:9868</value>' hdfs-site.xml
sed -i '22a </property>' hdfs-site.xml
sed -i '23a <property>' hdfs-site.xml
sed -i '24a <name>dfs.namenode.name.dir</name>' hdfs-site.xml
sed -i '25a <value>file://${hadoop.data.dir}/name</value>' hdfs-site.xml
sed -i '26a </property>' hdfs-site.xml
sed -i '27a <property>' hdfs-site.xml
sed -i '28a <name>dfs.datanode.data.dir</name>' hdfs-site.xml
sed -i '29a <value>file://${hadoop.data.dir}/data</value>' hdfs-site.xml
sed -i '30a </property>' hdfs-site.xml
sed -i '31a <property>' hdfs-site.xml
sed -i '32a <name>dfs.namenode.checkpoint.dir</name>' hdfs-site.xml
sed -i '33a <value>file://${hadoop.data.dir}/namesecondary</value>' hdfs-site.xml
sed -i '34a </property>' hdfs-site.xml
sed -i '35a <property>' hdfs-site.xml
sed -i '36a <name>dfs.client.datanode-restart.timeout</name>' hdfs-site.xml
sed -i '37a <value>30</value>' hdfs-site.xml
sed -i '38a </property>' hdfs-site.xml
sed -i '39a <property>' hdfs-site.xml
sed -i '40a <name>dfs.namenode.http-address</name>' hdfs-site.xml
sed -i '41a <value>hadoop101:9870</value>' hdfs-site.xml
sed -i '42a </property>' hdfs-site.xml
echo"-------配置hdfs-site.xml文件完成-------"# 配置yarn-site.xml文件sed -i '18a <property>' yarn-site.xml
sed -i '19a <name>yarn.resourcemanager.hostname</name>' yarn-site.xml
sed -i '20a <value>hdp102</value>' yarn-site.xml
sed -i '21a </property>' yarn-site.xml
sed -i '22a <property>' yarn-site.xml
sed -i '23a <name>yarn.nodemanager.aux-services</name>' yarn-site.xml
sed -i '24a <value>mapreduce_shuffle</value>' yarn-site.xml
sed -i '25a </property>' yarn-site.xml
sed -i '26a <property>' yarn-site.xml
sed -i '27a <name>yarn.nodemanager.env-whitelist</name>' yarn-site.xml
sed -i '28a <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>' yarn-site.xml
sed -i '29a </property>' yarn-site.xml
echo"-------配置yarn-site.xml文件完成-------"# 配置mapred-site.xmlsed -i '20a <property>' mapred-site.xml
sed -i '21a <name>mapreduce.framework.name</name>' mapred-site.xml
sed -i '22a <value>yarn</value>' mapred-site.xml
sed -i '23a </property>' mapred-site.xml
echo"-------配置mapred-site.xml文件完成-------"# 配置workerssed -i '2a hdp101' workers
sed -i '3a hdp102' workers
sed -i '4a hdp103' workers
echo"-------配置workers文件完成-------"# 配置hadoop-env.shsed -i '26a export HDFS_NAMENODE_USER=root' hadoop-env.sh
sed -i '27a export HDFS_SECONDARYNAMENODE_USER=root' hadoop-env.sh
sed -i '28a export HDFS_DATANODE_USER=root' hadoop-env.sh
echo"-------配置hadoop-env.sh文件完成-------"cd /opt/module/hadoop330/sbin
sed -i '2a HDFS_DATANODE_USER=root' start-dfs.sh
sed -i '3a HDFS_DATANODE_SECURE_USER=hdfs' start-dfs.sh
sed -i '4a HDFS_NAMENODE_USER=root' start-dfs.sh
sed -i '5a HDFS_SECONDARYNAMENODE_USER=root' start-dfs.sh
echo"-------配置start-dfs.sh文件完成-------"sed -i '2a HDFS_DATANODE_USER=root' stop-dfs.sh
sed -i '3a HDFS_DATANODE_SECURE_USER=hdfs' stop-dfs.sh
sed -i '4a HDFS_NAMENODE_USER=root' stop-dfs.sh
sed -i '5a HDFS_SECONDARYNAMENODE_USER=root' stop-dfs.sh
echo"-------配置stop-dfs.sh文件完成-------"sed -i '2a YARN_RESOURCEMANAGER_USER=root' start-yarn.sh
sed -i '3a HDFS_DATANODE_SECURE_USER=yarn' start-yarn.sh
sed -i '4a YARN_NODEMANAGER_USER=root' start-yarn.sh
echo"-------配置start-yarn.sh文件完成-------"sed -i '2a YARN_RESOURCEMANAGER_USER=root' stop-yarn.sh
sed -i '3a HDFS_DATANODE_SECURE_USER=yarn' stop-yarn.sh
sed -i '4a YARN_NODEMANAGER_USER=root' stop-yarn.sh
echo"-------配置stop-yarn.sh文件完成-------"# 格式化namenode并启动hadoop
hadoop namenode -format
echo"-------格式化namenode完成-------"}# hadoop集群启动hadoop_start(){echo"-------hadoop集群启动-------"echo" --------------- 启动 hdfs ---------------"ssh hdp101 "/opt/module/hadoop330/sbin/start-dfs.sh"echo" --------------- 启动 yarn ---------------"ssh hdp102 "/opt/module/hadoop330/sbin/start-yarn.sh"echo" --------------- 启动 historyserver ---------------"ssh hdp102 "/opt/module/hadoop330/bin/mapred --daemon start historyserver"}# hadoop集群停止hadoop_stop(){echo"-------hadoop集群停止-------"echo" --------------- 关闭 historyserver ---------------"ssh hdp102 "/opt/module/hadoop330/bin/mapred --daemon stop historyserver"echo" --------------- 关闭 yarn ---------------"ssh hdp102 "/opt/module/hadoop330/sbin/stop-yarn.sh"echo" --------------- 关闭 hdfs ---------------"ssh hdp101 "/opt/module/hadoop330/sbin/stop-dfs.sh"}# 分发脚本xsync(){# 获取输入参数个数,如果没有参数,直接退出pcount=$#if((pcount==0));thenecho no args...;exit;fi# 获取文件名称pname=$1fname=`basename $pname`echofname=$fname# 获取上级目录到绝对路径pdir=`cd -P $(dirname $pname);pwd`echopdir=$pdir# 获取当前用户名称user=`whoami`# 循环for((host=2; host<=3; host++));doecho$pdir/$fname$user@hdp10$host:$pdirecho==================hdp10$host==================rsync -rvl $pdir/$fname$user@hdp10$host:$pdirdone#Note:这里的slave对应自己主机名,需要做相应修改。另外,for循环中的host的边界值}#安装mysql5.7setup_mysql(){#检查linux的mariadb是否卸载 如果没有说明没有安装过mysqlmdb=`rpm -qa |grep mariadb`if["$mdb"!=""];thenrpm -e --nodeps $mdbcd /opt/
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql-community-server
#修改/etc/my.cnf文件解决中文乱码sed -i '/socket/a character-set-server=utf8' /etc/my.cnf
echo"[client]">> /etc/my.cnf
echo"default-character-set=utf8">> /etc/my.cnf
echo"[mysql]">> /etc/my.cnf
echo"default-character-set=utf8">> /etc/my.cnf
systemctl start mysqld.service
#获取临时密码pwdinfo=`grep"password" /var/log/mysqld.log|grep -wF "temporary password"`passwd=${pwdinfo#*localhost:}passwd=$(echo $passwd)#执行修改密码语句
mysql -uroot -p$passwd --connect-expired-password -e "set global validate_password_policy=0"
mysql -uroot -p$passwd --connect-expired-password -e "set global validate_password_length=1"
mysql -uroot -p$passwd --connect-expired-password -e "ALTER USER 'root'@'localhost' IDENTIFIED BY 'okok'"#修改远程登录
mysql -uroot -pokok -e "GRANT ALL PRIVILEGES ON *.* TO root@'%' IDENTIFIED BY 'okok'"
mysql -uroot -pokok -e "flush privileges"#重启服务
systemctl restart mysqld.service
fi}#根据用户的选择进行对应的安装custom_option(){case$1in0)
install_package
;;1)
add_user
;;2)
modify_sysname $2$3
modify_staticip $3;;3)
close_firewalld
;;4)
modify_yumsource
;;5)
setup_jdk
;;6)
setup_hadoop
;;7)
setup_mysql
;;8)
create_ssh
;;9)
hadoop_config
;;10)
hadoop_start
;;11)
hadoop_stop
;;12)
xsync
;;98)
install_package
modify_sysname $2$3
modify_staticip $3
modify_syshosts
close_firewalld
;;99)
setup_jdk
setup_hadoop
hadoop_config
;;
*)echo"please option 1~12、98、99"esac}#规定$1用户安装软件选择[] $2用户传入必须是系统的名称(hdp101~hdp103) $3用户传入必须是IP地址(101~103)
custom_option $1$2$3
执行脚本命令
# 不同命令0:安装工具包
1:新增用户
2:修改主机名与ip
3:关闭防火墙
4:配置yum源
5:安装jdk
6:安装hadoop
7:安装mysql
8:设置免密
9:配置hadoop文件
10:启动hadoop集群
11:关闭hadoop集群
12:xsync同步文件
98:从安装工具包到关闭防火墙
99:安装jdk、hadoop、配置hadoop
one [0~12|98|99] hdp101~hdp103 101~103

本文转载自: https://blog.csdn.net/m0_37172770/article/details/126452824
版权归原作者 纯码农 所有, 如有侵权,请联系我们删除。
版权归原作者 纯码农 所有, 如有侵权,请联系我们删除。