
1. 背景
做了一个手机版本的人流量计数,显然不能最终真实环境实施,因为数据集不够,并且硬件还需要搭载其他设备,所以使用的是安卓工控机,但推理速度非常慢,接近500ms,换一个好的CPU,比如3568工控机等,速度也是在150ms左右,但是发现了 Firefly相关文档 ,瑞芯微 ,可以用NPU做计算,那开始吧。
2. 先快速体验一下NPU
ROC-RK3568-PC板子这是一款次旗舰级,3588性能会更高,目前使用的3568做的开发。
rknn-toolkit 主要是针对RK1808/RK1806/RV1109/RV1126,对应需要的库地址 rknpu ,所以这个忽略,使用下面的工具。
rknn-toolkit2 主要是针对RK3566/RK3568/RK3588/RK3588S/RV1103/RV1106,对应需要的库地址 rknpu2 。
使用说明可以参考 NPU使用 。
- 下载rknpu2 ,将so库导入到对应的目录,这是为了简单的测试NPU功能,后面安卓使用,还是会放到项目的jnilib下。
adb root && adb remount
adb push rknpu2_1.4.0/runtime/RK356X/Android/librknn_api/arm64-v8a/* /vendor/lib64
adb push rknpu2_1.4.0/runtime/RK356X/Android/librknn_api/arm64-v8a/* /vendor/lib
- 将 demo 放入 ROC-RK3568-PC ,运行 demo 如下
:/ # cd /data/rknn_ssd_demo_Android/ (Linux 系统使用 rknn_ssd_demo_Linux 即可)
:/data/rknn_ssd_demo_Android # chmod 777 rknn_ssd_demo
:/data/rknn_ssd_demo_Android # export LD_LIBRARY_PATH=./lib
:/data/rknn_ssd_demo_Android # ./rknn_ssd_demo model/RK356X/ssd_inception_v2.rknn model/road.bmp (Linux 为 bus.jpg)
Loading model ...
rknn_init ...
model input num: 1, output num: 2
input tensors:
index=0, name=Preprocessor/sub:0, n_dims=4, dims=[1, 300, 300, 3], n_elems=270000, size=270000, fmt=NHWC, type=UINT8, qnt_type=AFFINE, zp=0, scale=0.007812
output tensors:
index=0, name=concat:0, n_dims=4, dims=[1, 1917, 1, 4], n_elems=7668, size=30672, fmt=NHWC, type=FP32, qnt_type=AFFINE, zp=53, scale=0.089455
index=1, name=concat_1:0, n_dims=4, dims=[1, 1917, 91, 1], n_elems=174447, size=697788, fmt=NHWC, type=FP32, qnt_type=AFFINE, zp=53, scale=0.143593
rknn_run
loadLabelName
ssd - loadLabelName ./model/coco_labels_list.txt
loadBoxPriors
person @ (13 125 59 212) 0.984696
person @ (110 119 152 197) 0.969119
bicycle @ (171 165 278 234) 0.969119
person @ (206 113 256 216) 0.964519
car @ (146 133 216 170) 0.959264
person @ (49 133 58 156) 0.606060
person @ (83 134 92 158) 0.606060
person @ (96 135 106 162) 0.464163
这就体验完成了。接下来模型转换环境搭建。
3. RKNN模型转换
- 下载rknn-toolkit2 ,RKNN-Toolkit2 目前版本适用系统Ubuntu,建议使用Docker, 我装的是双系统, 切换起来难受。必须是 Ubuntu 18.04 python 3.6 / Ubuntu 20.04 python 3.8,只能选其一, 只能选其一, 只能选其一
- 装好系统后,安装需要的Python环境,以18.04为例
#Python3.6
cat doc/requirements_cp36-1.3.0.txt
numpy==1.16.6
onnx==1.7.0
onnxoptimizer==0.1.0
onnxruntime==1.6.0
tensorflow==1.14.0
tensorboard==1.14.0
protobuf==3.12.0
torch==1.6.0
torchvision==0.7.0
psutil==5.6.2
ruamel.yaml==0.15.81
scipy==1.2.1
tqdm==4.27.0
requests==2.21.0
opencv-python==4.4.0.46
PuLP==2.4
scikit_image==0.17.2
# if install bfloat16 failed, please install numpy manually first. "pip install numpy==1.16.6"
bfloat16==1.1
flatbuffers==1.12
- 建议使用 virtualenv 管理 Python 环境,因为系统中可能同时有多个版本的 Python 环境,以 Python3.6 为例
# 1)安装virtualenv 环境、Python3.6 和 pip3
sudo apt-get install virtualenv \
sudo apt-get install python3 python3-dev python3-pip
# 2)安装相关依赖
sudo apt-get install libxslt1-dev zlib1g zlib1g-dev libglib2.0-0 libsm6 \
libgl1-mesa-glx libprotobuf-dev gcc
# 3)使用 virtualenv 管理 Python 环境并安装 Python 依赖,Python3.6用requirements_cp36-1.3.0.txt
virtualenv -p /usr/bin/python3 venv
source venv/bin/activate
pip3 install -r doc/requirements_cp36-*.txt
# 4)安装 RKNN-Toolkit2,如rknn_toolkit2-1.3.0_11912b58-cp36-cp36m-linux_x86_64.whl
sudo pip3 install packages/rknn_toolkit2*cp36*.whl
# 5)检查RKNN-Toolkit2是否安装成功,可按ctrl+d组合键退出
(venv) firefly@T-chip:~/rknn-toolkit2$ python3
>>> from rknn.api import RKNN
>>>
- 我使用的是yolov5模型, 不使用rknn-toolkit2进行转换,yolo模型使用官方推荐的rknn_model_zoo , 使用 airockchip 修改后的 yolov5/ yolov7/ YOLOX 仓库进行模型训练,并导出对应的onnx,这样在输入输出时与Demo能保持一致。如下图所示,左边是支持的转换模型结构,右边是yolov5官方的,我们需要得到左边的这种,而不是右边的。除非你很了解模型结构,并能够正确处理输出结果。
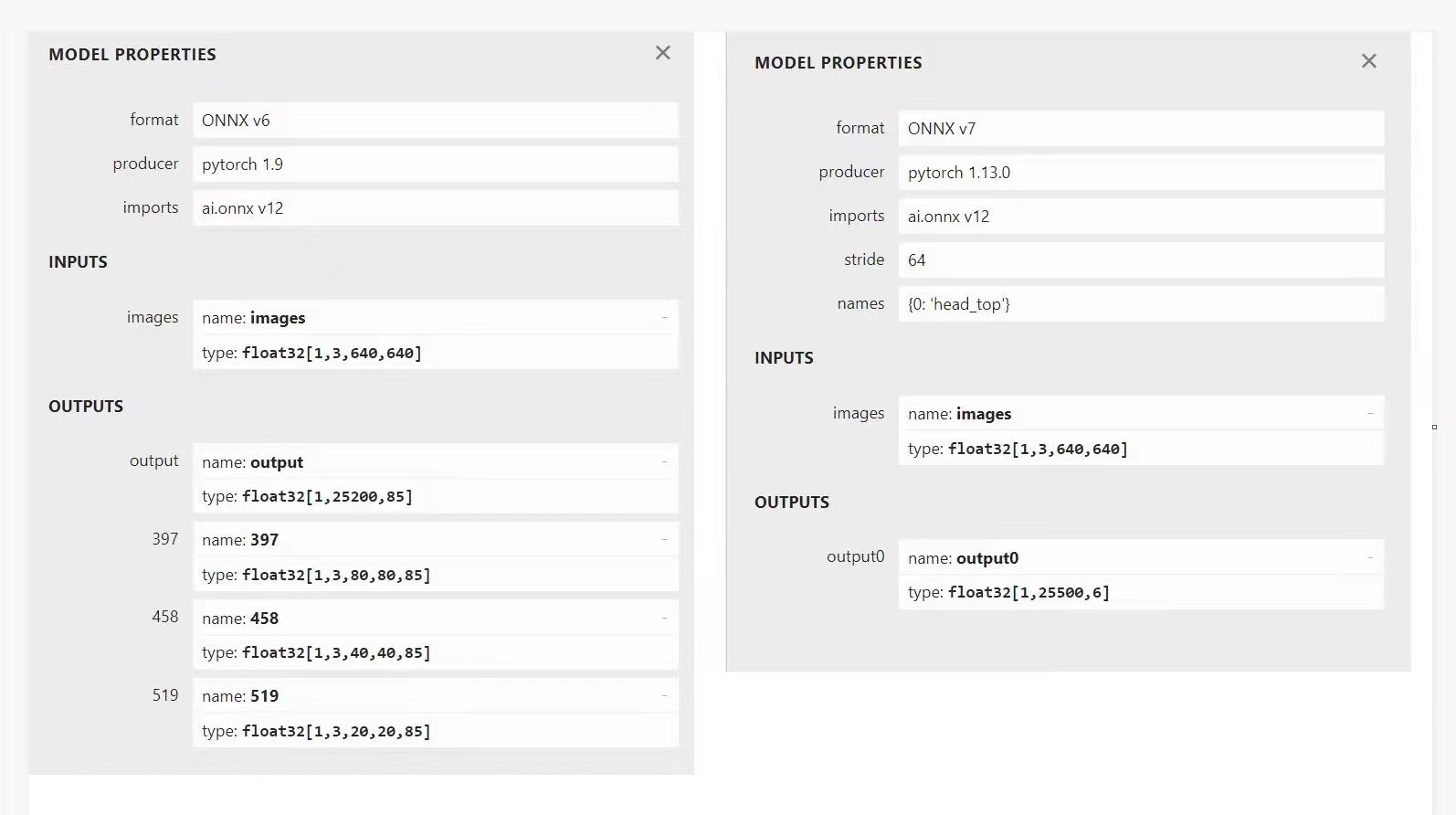
- 使用 airockchip 修改后的 yolov5 模型训练, 人头数据集 ,权重也可以使用他提供的yolov5s_relu.pt。
- 导出onnx模型
导出模型时 python export.py --rknpu {rk_platform} 即可导出优化模型
(rk_platform支持 rk1808, rv1109, rv1126, rk3399pro, rk3566, rk3568, rk3588, rv1103, rv1106)
- 模型转换参考rknn_model_zoo/models/CV/object_detection/yolo/RKNN_model_convert
- 推理测试参考rknn_model_zoo/models/CV/object_detection/yolo/RKNN_python_demo
4. 安卓上使用RKNN模型
方式 1. 使用rknn_yolov5_android_apk_demo , 图像输入时,数据的处理缺少对应的rga库,我这个板子底层驱动应该被联想改过,想让他们集成,说要加钱,没弄了。
方式 2. 使用RK356X NPU Demo 对比上面的Demo,图像的输入只用direct_texture处理的data,只需要修改一下后处理函数,参照rknn_yolo_demo ,可以看出并没有使用sigmoid处理 。
static int process_i8(int8_t *input, int *anchor, int grid_h, int grid_w, int height,
int width, int stride,
std::vector<float> &boxes, std::vector<float> &boxScores, std::vector<int> &classId,
float threshold, int32_t zp, float scale) {
int validCount = 0;
int grid_len = grid_h * grid_w;
float thres = threshold;
auto thres_i8 = qnt_f32_to_affine(thres, zp, scale);
// puts("==================================");
// printf("threash %f\n", thres);
// printf("thres_i8 %u\n", thres_i8);
// printf("scale %f\n", scale);
// printf("zp %d\n", zp);
// puts("==================================");
//printf("it goes here: file %s, at line %d\n", __FILE__, __LINE__);
for (int a = 0; a < 3; a++) {
for (int i = 0; i < grid_h; i++) {
for (int j = 0; j < grid_w; j++) {
int8_t box_confidence = input[(YOLOV5_PROP_BOX_SIZE * a + 4) * grid_len +
i * grid_w + j];
//printf("The box confidence in i8: %d\n", box_confidence);
if (box_confidence >= thres_i8) {
// printf("box_conf %u, thres_i8 %u\n", box_confidence, thres_i8);
int offset = (YOLOV5_PROP_BOX_SIZE * a) * grid_len + i * grid_w + j;
int8_t *in_ptr = input + offset;
int8_t maxClassProbs = in_ptr[5 * grid_len];
int maxClassId = 0;
for (int k = 1; k < YOLOV5_OBJ_CLASS_NUM; ++k) {
int8_t prob = in_ptr[(5 + k) * grid_len];
if (prob > maxClassProbs) {
maxClassId = k;
maxClassProbs = prob;
}
}
float box_conf_f32 = deqnt_affine_to_f32(box_confidence, zp, scale);
float class_prob_f32 = deqnt_affine_to_f32(maxClassProbs, zp, scale);
float limit_score = box_conf_f32 * class_prob_f32;
// LOGI("limit score: %f\n", limit_score);
if (limit_score > YOLOV5_CONF_THRESHOLD) {
float box_x, box_y, box_w, box_h;
box_x = deqnt_affine_to_f32(*in_ptr, zp, scale) * 2.0 - 0.5;
box_y = deqnt_affine_to_f32(in_ptr[grid_len], zp, scale) * 2.0 - 0.5;
box_w = deqnt_affine_to_f32(in_ptr[2 * grid_len], zp, scale) * 2.0;
box_h = deqnt_affine_to_f32(in_ptr[3 * grid_len], zp, scale) * 2.0;
box_w = box_w * box_w;
box_h = box_h * box_h;
box_x = (box_x + j) * (float) stride;
box_y = (box_y + i) * (float) stride;
box_w *= (float) anchor[a * 2];
box_h *= (float) anchor[a * 2 + 1];
box_x -= (box_w / 2.0);
box_y -= (box_h / 2.0);
boxes.push_back(box_x);
boxes.push_back(box_y);
boxes.push_back(box_w);
boxes.push_back(box_h);
boxScores.push_back(box_conf_f32 * class_prob_f32);
classId.push_back(maxClassId);
validCount++;
}
}
}
}
}
return validCount;
}
遇到的问题
- rknn-toolkit2/examples/onnx/yolov5/ 使用这个转换,也是可以的,但是YOLO模型最好使用rknn_model_zoo 进行转换,因为包含了训练-导出-转换-测试一系列套餐。
- 推理结果出现花屏问题,是sigmoid函数造成的,因为模型结果中没有sigmoid的处理,而你的测试方法用到了,可以查看上面的第8步的,去掉相关函数。

- 连扳进行模型转换时,需要启动rknn-server,具体操作参考rknpu2/rknn_server_proxy
- 尝试直接将摄像的数据,转成bitmap,转cv Mat,作为输入,但是没有效果,失败了。
总结
凡事都试一试。
其他的一些AI库。
TensorflowLite
腾讯TNN
小米Mace
阿里MNN
计算机视觉学习视频,极力推荐北京邮电大学鲁鹏讲的
计算机视觉与深度学习
本文转载自: https://blog.csdn.net/weixin_43141131/article/details/128407827
版权归原作者 wantao1008hh 所有, 如有侵权,请联系我们删除。
版权归原作者 wantao1008hh 所有, 如有侵权,请联系我们删除。