
AbstractFetcherThread:拉取消息的步骤
副本机制是Kafka实现数据高可靠性的基础:同一个分区下的多个副本分散在不同的Broker机器上,它们保存相同的消息数据以实现高可靠性。那如何确保所有副本上的数据一致性呢?最常见方案当属Leader/Follower备份机制(Leader/Follower Replication)。Kafka分区的:
- 某个副本会被指定为Leader,负责响应客户端的读、写请求
- 其他副本自动成为Follower,被动同步Leader副本中的数据被动同步:Follower副本不断向Leader副本发送读取请求,以获取Leader处写入的最新消息数据
本文就研究Follower副本如何通过拉取线程实现这一目标。Follower副本在副本同步过程中,还可能发生截断(Truncation),其原理又是为何?
案例
这部分源码贴近底层设计架构原理。阅读它对我实际有啥用?
生产环境曾发现,一旦Broker上副本数过多,Broker内存占用就会很高。HeapDump后,发现在于ReplicaFetcherThread#buildFetch有这么一行代码:
val builder = fetchSessionHandler.newBuilder()
内部会实例化一个LinkedHashMap。若分区数很多,该Map会被扩容数次,带来大量不必要的数据拷贝,既增加内存Footprint,又浪费CPU。后续通过将负载转移到其他Broker解决该问题。
Kafka社区也发现了这个Bug,所以现在变成:
 修改后语句直接传入FETCH请求中总的分区数,并直接将其传给LinkedHashMap,避免再执行扩容。
修改后语句直接传入FETCH请求中总的分区数,并直接将其传给LinkedHashMap,避免再执行扩容。
说回Follower副本从Leader副本拉取数据。Kafka就是通过ReplicaFetcherThread,副本获取线程实现的消息拉取及处理。
本文先从抽象基类AbstractFetcherThread研究,最终彻底搞明白Follower端同步Leader端消息的原理。
AbstractFetcherThread
抽象类,从Broker获取多个分区的消息数据,至于获取之后如何对这些数据进行处理,则交由子类来实现。
类定义及字段

除了构造器的这几个字段,AbstractFetcherThread还定义了两个type类型。关键字type定义一个类型,可当做一个快捷方式,如FetchData:
type FetchData = FetchResponse.PartitionData[Records]
类似快捷方式:凡源码用到FetchResponse.PartitionData[Records],都可使用FetchData替换,EpochData同理。
FetchData定义里的PartitionData类型,是客户端clients工程中FetchResponse类的嵌套类。FetchResponse类封装的是FETCH请求的Response对象,其内PartitionData是个POJO,保存Response中单个分区数据拉取的各项数据:
- 从该分区的Leader副本拉取回来的消息
- 该分区的高水位值
- 日志起始位移值
- …
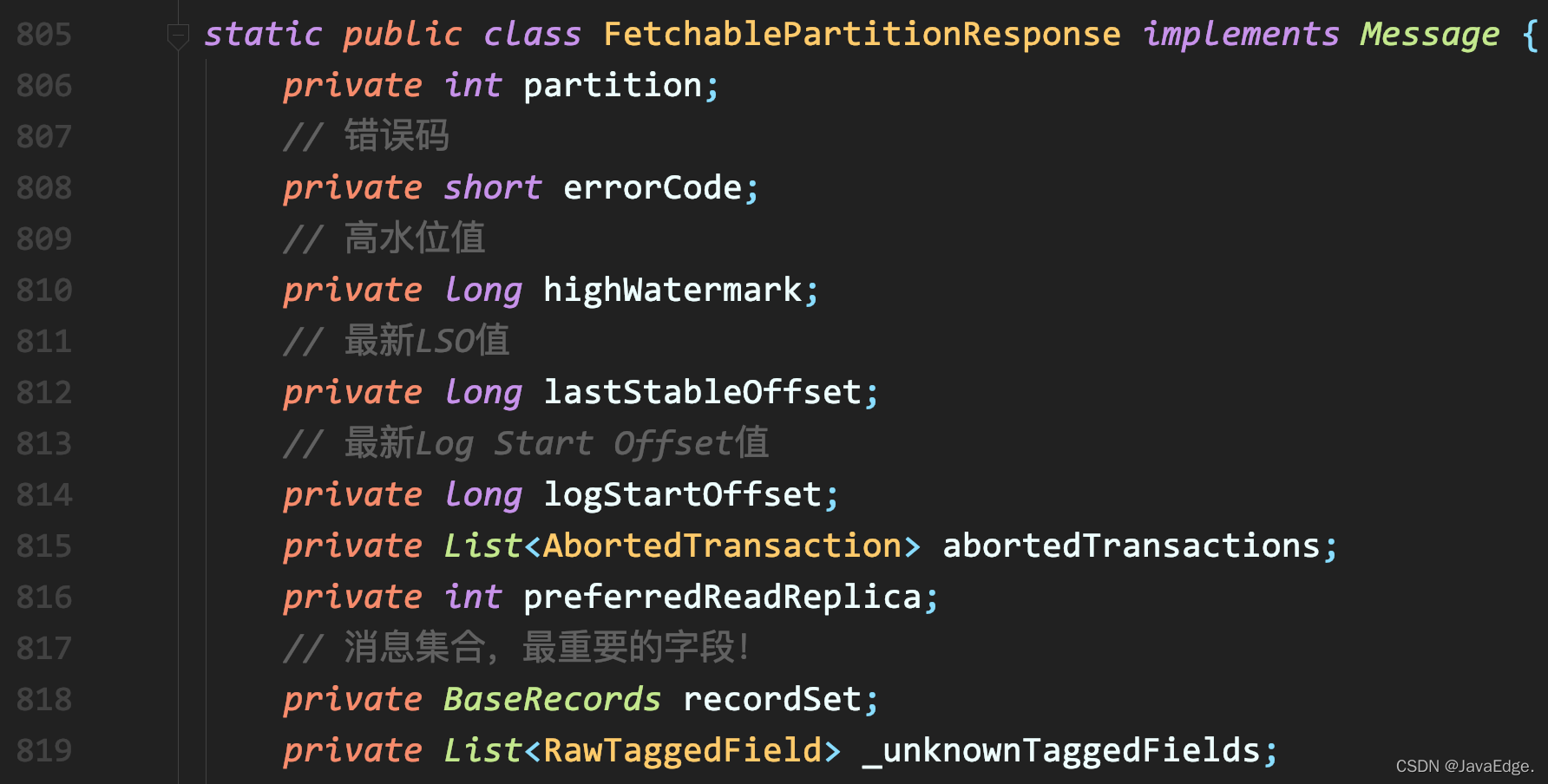

在PartitionData中,最需关注的是recordSet,保存了实际的消息集合。
- 注意到EpochData定义位置,它也是PartitionData类型,但EpochData的PartitionData是OffsetsForLeaderEpochRequest的PartitionData类型Kafka源码有很多名为PartitionData的嵌套类。很多请求类型中的数据都是按分区层级分组,因此源码很自然地在这些请求类中创建同名嵌套类。所以,注意区分PartitionData嵌套类是定义在哪类请求中的!
分区读取状态类
AbstractFetcherThread构造器中,还有个**PartitionStates[PartitionFetchState]**类型的字段:
- 泛型参数类型PartitionFetchState类,表征分区读取状态,保存分区的已读取位移值和对应副本状态。
这里的状态有二:
副本读取状态
副本读取状态由ReplicaState接口表示:
分区读取状态:
- 可获取,表明副本获取线程当前能够读取数据。
- 截断中,表明分区副本正在执行截断操作(比如该副本刚刚成为Follower副本)。
- 被推迟,表明副本获取线程获取数据时出现错误,需要等待一段时间后重试。
分区读取状态中的【可获取、截断中】与副本读取状态的【获取中、截断中】并非严格对应。副本读取状态处获取中,并不一定表示分区读取状态就是可获取状态。对于分区,它是否能被获取的条件要比副本严格。
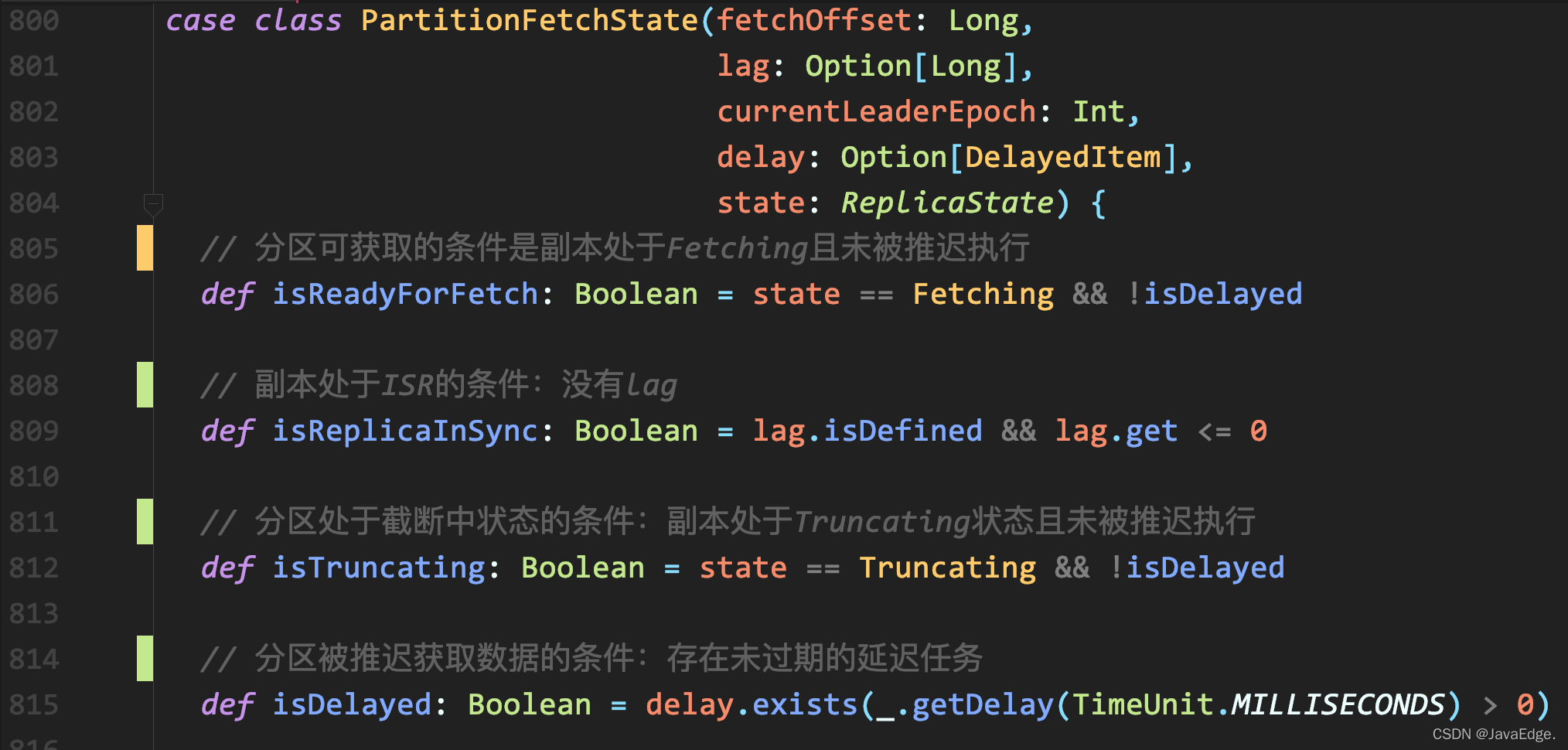
副本获取线程做的事情,日志截断和消息获取:
- isReplicaInSync,副本限流,出镜率不高
- isDelayed,判断是否需要推迟获取对应分区的消息源码会不断调整那些不需要推迟的分区的读取顺序,以保证读取公平性。公平性实现在partitionStates字段的PartitionStates类,定义在clients工程。会接收一组要读取的主题分区,然后轮询读取这些分区以确保公平性。
clients端源码自行查阅。
public class PartitionStates<S>{privatefinal LinkedHashMap<TopicPartition,S> map =new LinkedHashMap<>();......
public void updateAndMoveToEnd(TopicPartition topicPartition, S state){
map.remove(topicPartition);
map.put(topicPartition, state);
updateSize();}......}
PartitionStates轮询处理要读取的多个分区,依靠LinkedHashMap保存所有主题分区,其元素有明确迭代顺序,默认为元素插入的顺序。
假设Kafka要读5个分区的消息:A、B、C、D和E。若插入顺序:ABCDE,则首先读分区A。一旦A被读取后,为确保各分区都有同等机会被读取,代码需将A插入到分区列表的最后一位,这就是updateAndMoveToEnd:把A从map中移除,再插回去,这样A自然就处于列表的最后一位了。这便是PartitionStates的作用。
core API
processPartitionData、truncate、buildFetch和doWork,涵盖拉取线程所做的最重要的3件事:
- 构建FETCH请求
- 执行截断操作
- 处理拉取后的结果
doWork串联起前面的这3方法。
最重要的processPartitionData,用于处理读取回来的消息集合。它是个抽象方法,因此需子类实现它的逻辑。具体到Follower副本而言, 由ReplicaFetcherThread类实现:
protecteddef processPartitionData(
topicPartition: TopicPartition,// 读取哪个分区的数据
fetchOffset:Long,// 读取到的最新位移值
partitionData: FetchData // 读取到的分区消息数据): Option[LogAppendInfo]// 写入已读取消息数据前的元数据
返回值Option[LogAppendInfo]:
- 对Follower副本读消息写入日志,可忽略Option,因为肯定会返回具体LogAppendInfo实例,而不是None
- LogAppendInfo类封装了很多消息数据被写入到日志前的重要元数据信息,如首条消息的位移值、最后一条消息位移值、最大时间戳等
truncate
protecteddef truncate(
topicPartition: TopicPartition,// 要对哪个分区下副本执行截断操作
truncationState: OffsetTruncationState // Offset + 截断状态):Unit
OffsetTruncationState类告诉Kafka要把指定分区下副本截断到哪个位移值,封装了:
- 一个位移值
- 一个截断完成与否的布尔值状态
buildFetch
protecteddef buildFetch(// 一组要读取的分区列表// 分区是否可读取取决于PartitionFetchState中的状态
partitionMap: Map[TopicPartition, PartitionFetchState]):// 封装FetchRequest.Builder对象
ResultWithPartitions[Option[ReplicaFetch]]
本质为指定分区构建对应FetchRequest.Builder对象,而该对象是构建FetchRequest的核心组件。Kafka中任何类型的消息读取,都是通过给指定Broker发送FetchRequest请求来完成的。
doWork
串联前面3个方法的主要入口方法。
总结
本文研究Kafka的副本同步机制和副本管理器组件。Kafka副本间的消息同步依赖ReplicaFetcherThread线程。AbstractFetcherThread作为拉取线程的公共基类,AbstractFetcherThread类定义了很多重要方法。
- AbstractFetcherThread类:拉取线程的抽象基类。它定义了公共方法处理所有拉取线程的共同逻辑,如执行截断操作,获取消息。
- 拉取线程逻辑:循环执行截断操作和获取数据操作。
- 分区读取状态:当前,源码定义了3类分区读取状态。拉取线程只能拉取处于可读取状态的分区的数据

版权归原作者 JavaEdge. 所有, 如有侵权,请联系我们删除。