
文章目录
前言
经过我们上一篇对linux系统文件操作的学习想必我们已经会使用系统文件接口了,今天我们就用系统文件接口来封装一个像C语言库那样的文件操作函数的函数来加深我们对文件操作的学习。
一、模拟C库文件操作
首先我们创建相应的.c .h 以及main.c头文件,然后我们写一个makefile:
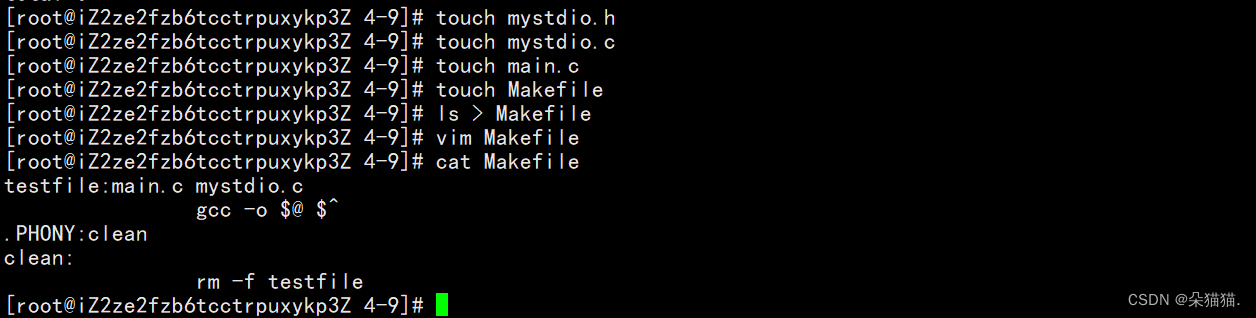
接下来我们完善.h里面的代码:
#pragma once
#include <stdio.h>
#define NUM 1024
#define BUFF_NONE 0x1
#define BUFF_LINE 0x2
#define BUFF_ALL 0x4
typedef struct _MY_FILE
{
int fd;
char outputbuffer[NUM];
int flags; //刷新策略
}MY_FILE;
MY_FILE* my_fopen(const char* path,const char* mode);
size_t my_fwrite(const void* ptr,size_t size,size_t nmemb,MY_FILE* stream);
int my_fclose(MY_FILE* fp);
首先有一个文件结构体,在这个结构体中有文件描述符,有一个1024大小的缓冲区,还有控制刷新的标志,我们为了方便将结构体重命名为MY_FILE,既然有刷新策略那么我们就#define3个刷新策略,分别是无缓冲,行缓冲,全缓冲。然后我们实现三个函数,分别是打开文件,写入文件和关闭文件,这些函数我们都是通过系统接口调用所以参数与系统接口一致,下面我们进行函数主体的编写:
#include "mystdio.h"
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <malloc.h>
#include <assert.h>
#include <unistd.h>
MY_FILE* my_fopen(const char* path,const char* mode)
{
//.识别标识位
int flag = 0;
if (strcmp(mode,"r")==0)
{
flag|=O_RDONLY;
}
else if(strcmp(mode,"w")==0)
{
flag|=(O_CREAT | O_WRONLY | O_TRUNC);
}
else if(strcmp(mode,"a")==0)
{
flag|=(O_CREAT | O_WRONLY | O_APPEND);
}
else
{
}
//2.尝试打开文件
mode_t m = 0666;
int fd = 0;
if (flag & O_CREAT)
{
fd = open(path,flag,m);
}
else
{
fd = open(path,flag);
}
if (fd<0)
{
return NULL;
}
//给用户返回MY_FILE对象,需要先进行构建
MY_FILE* mf = (MY_FILE*)malloc(sizeof(MY_FILE));
if (mf==NULL)
{
close(fd);
return NULL;
}
//4.初始化MY_FILE对象
mf->fd = fd;
mf->flags = BUFF_LINE;
memset(mf->outputbuffer,'\0',sizeof(mf->outputbuffer));
//my_outputbuffer[0] = 0; //初始化缓冲区
//5.返回打开的文件
return mf;
}
int my_fflush(MY_FILE* fp)
{
return 0;
}
size_t my_fwrite(const void* ptr,size_t size,size_t nmemb,MY_FILE* stream)
{
return 0;
}
int my_fclose(MY_FILE* fp)
{
assert(fp);
//1.冲刷缓冲区
if (fp->current >0)
{
my_fflush(fp);
}
//2.关闭文件
close(fp->fd);
//3.释放堆空间
free(fp);
//4.指针置NULL --- 可以设置可以不设置
fp = NULL;
return 0;
}
下面我们一个函数一个函数的进行讲解,首先是fopen函数:
MY_FILE* my_fopen(const char* path,const char* mode)
{
//.识别标识位
int flag = 0;
if (strcmp(mode,"r")==0)
{
flag|=O_RDONLY;
}
else if(strcmp(mode,"w")==0)
{
flag|=(O_CREAT | O_WRONLY | O_TRUNC);
}
else if(strcmp(mode,"a")==0)
{
flag|=(O_CREAT | O_WRONLY | O_APPEND);
}
else
{
}
}
对于打开文件的函数我们要判断用户是什么模式下的打开文件,我们设置标志位为0,如果用户输入的方式是r只读模式,就让标志位或上只读选项,如果是w写模式,这个时候要有三种实现,文件不存在就创建文件,只写文件,写之前先清空文件,搞定w模式后我们完成追加模式,对于a来讲也有三种情况,文件不存在就创建文件,只写文件,追加文件不进行清空,搞定第一步后我们完成第二步打开文件:
//2.尝试打开文件
mode_t m = 0666;
int fd = 0;
if (flag & O_CREAT)
{
fd = open(path,flag,m);
}
else
{
fd = open(path,flag);
}
if (fd<0)
{
return NULL;
}
要打开文件我们先创建一个默认的文件权限0666,并且创建一个文件标识符变量,判断文件是否存在,如果存在就用不需要权限参数的open函数代开文件,如果不存在则需要用三个参数的open函数打开文件。如果返回值小于0说明打开文件失败返回空指针。
//3.给用户返回MY_FILE对象,需要先进行构建
MY_FILE* mf = (MY_FILE*)malloc(sizeof(MY_FILE));
if (mf==NULL)
{
close(fd);
return NULL;
}
//4.初始化MY_FILE对象
mf->fd = fd;
mf->flags = BUFF_LINE;
memset(mf->outputbuffer,'\0',sizeof(mf->outputbuffer));
//my_outputbuffer[0] = 0; //初始化缓冲区
//5.返回打开的文件
return mf;
第三步给用户返回一个文件对象,先创建一个指针用来开一个MY_FILE的结构体,然后判断是否创建成功如果不成功我们就将文件关闭并且返回NULL,如果成功我们就初始化MY_struct中的参数,将文件标识符传过去,因为C语言是行缓冲所以我们直接设为行缓冲,然后给结构体中的缓冲区初始化。这些过程都结束了就返回打开的文件。
int my_fclose(MY_FILE* fp)
{
assert(fp);
//1.冲刷缓冲区
if (fp->current >0)
{
my_fflush(fp);
}
//2.关闭文件
close(fp->fd);
//3.释放堆空间
free(fp);
//4.指针置NULL --- 可以设置可以不设置
fp = NULL;
return 0;
}
关闭文件的函数很简单,因为关闭文件前需要先刷新缓冲区所以我们在struct中添加一个变量current来判断是否需要刷新缓冲区,冲刷完缓冲区后将文件关闭,最后将malloc出来的struct结构体空间释放掉,为了安全起见可以将fp指针置为NULL。
#include "mystdio.h"
#define MYFILE "log.txt"
int main()
{
MY_FILE* fp = my_fopen(MYFILE,"w");
if (fp==NULL)
{
return 1;
}
my_fclose(fp);
return 0;
}
下面我们演示一下我们的文件操作成功与否:
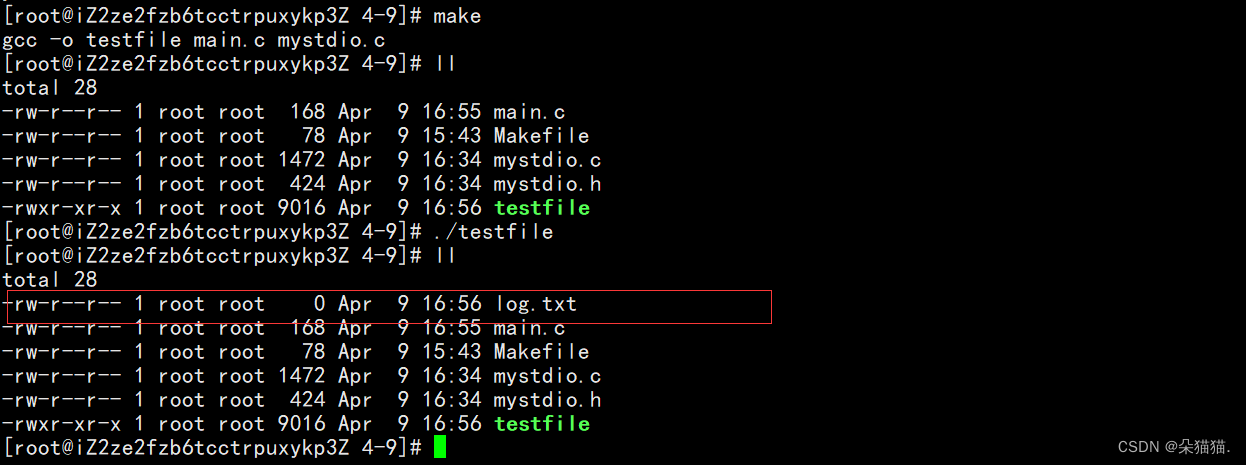
通过上图我们可以看到我们写的文件操作函数是成功的,只是有些功能我们还没有去完善,如果都完善了可以替代C语言库用我们自己的库。
下面我们将fwrite接口补充完整:
//我们今天返回的就是一次实际写入的字节数,我们就不返回个数了
size_t my_fwrite(const void* ptr,size_t size,size_t nmemb,MY_FILE* stream)
{
//1.缓冲区如果已经满了,就直接写入
if (stream->current==NUM)
{
my_fflush(stream);
}
//2.根据缓冲区剩余情况,进行数据拷贝即可
size_t user_size = size*nmemb;
size_t my_size = NUM-stream->current;
size_t writen = 0;
if (my_size>=user_size)
{
memcpy(stream->outputbuffer+stream->current,ptr,user_size);
//3.更新计数器字段
stream->current+=user_size;
writen = user_size;
}
else
{
memcpy(stream->outputbuffer+stream->current,ptr,my_size);
stream->current+=my_size;
writen = my_size;
}
//4.开始计划刷新
if (stream->flags & BUFF_ALL)
{
if (stream->current==NUM)
{
my_fflush(stream);
}
}
else if(stream->flags & BUFF_LINE)
{
if (stream->outputbuffer[stream->current-1]=='\n')
{
my_fflush(stream);
}
}
else
{
}
return writen;
}
我们写入的第一件事就是判断缓冲区是否有空间,如果我们的缓冲区已经满了我们就直接把数据刷新出去。如果我们期望写入4096字节,但是缓冲区只有1024字节,所以最后缓冲区只能输出1024字节,所以下一步我们要根据缓冲区剩余情况进行数据拷贝即可。current是当前缓冲区有多少字符,并且current也是下一次缓冲区继续写入的下标。接下来我们计算用户传的缓冲区有多大,再计算我们自己的缓冲区还剩下多少,如果我们的剩余空间是大于用户的数据的,说明我们的空间是足够的,直接把用户的缓冲区的数据拷贝到我们自己的缓冲区即可,在这里要注意不能直接拷贝到stream->outbuffer,因为当前缓冲区很可能是有数据的我们不能覆盖,只能从current的位置继续拷贝,拷贝完成后记得更新我们缓冲区的位置,由于fwrite函数写入成功会返回当前写入多少字节,所以我们用一个变量记录当前写入了多少字节,如果我们当前的空间不足以容纳用户传来的空间,我们就只能拷贝我们剩余大小的空间,然后接下来我们计划开始刷新缓冲区,如果是全缓冲就等下标等于NUM的时候刷新,如果是行刷新我们直接判断current-1的位置是不是\n,如果是\n我们就进行行刷新。最后返回写入了多少字节就完成了,接下来我们完成刷新函数:
int my_fflush(MY_FILE* fp)
{
assert(fp);
write(fp->fd,fp->outputbuffer,fp->current);
return 0;
}
首先判断fp是否为空指针,如果不是我们就进行刷新,刷新我们直接用write函数,第一个参数是文件描述符,第二个参数是缓冲区,第三个参数是写入多少的大小,总体就是向文件描述符中写入特定的缓冲区中的特定大小,接下来我们在main函数中试试我们的fwrite函数。
#include "mystdio.h"
#define MYFILE "log.txt"
#include <string.h>
#include <unistd.h>
int main()
{
MY_FILE* fp = my_fopen(MYFILE,"w");
if (fp==NULL)
{
return 1;
}
const char* str = "hello my fwrite";
int cnt = 5;
while (cnt)
{
char buffer[1024];
snprintf(buffer,sizeof(buffer),"%s:%d\n",str,cnt--);
size_t size = my_fwrite(buffer,strlen(buffer),1,fp);
sleep(1);
printf("当前成功写入:%lu个字节\n",size);
}
my_fclose(fp);
return 0;
}
接下来我们运行一下看看效果:

当我们运行后发现,其他的都没问题但是为什么多打印了那么多?因为我们每次打印后都要重新刷新一下缓冲区再进行打印,否则每次都带有之前旧的数据被打印出来,下面我们将缓冲区函数改一下:
int my_fflush(MY_FILE* fp)
{
assert(fp);
write(fp->fd,fp->outputbuffer,fp->current);
//刷新后清理缓冲区
fp->current = 0;
return 0;
}
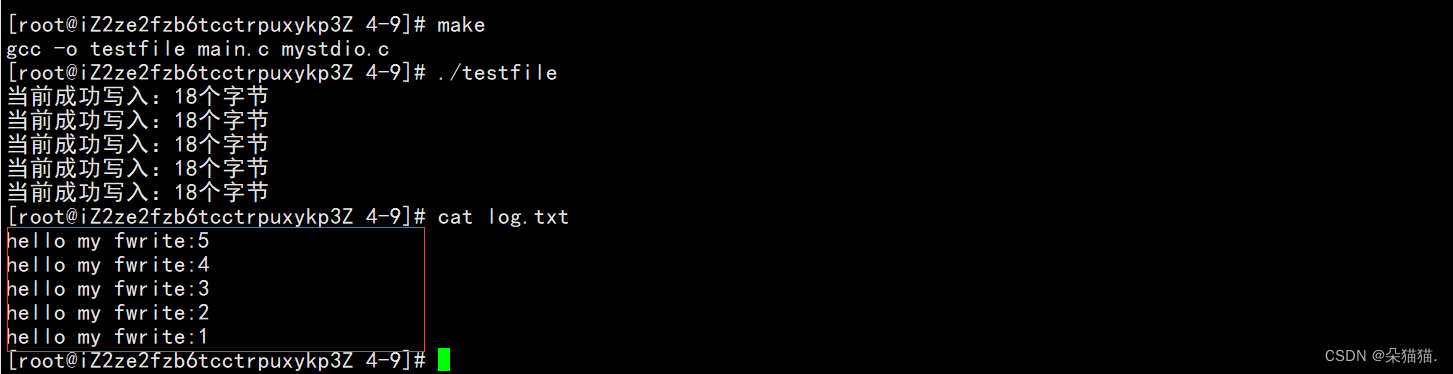
通过上图我们可以看到这次的程序是成功完成。这就是我们模拟的文件操作,通过这样的实现我们更深刻的理解了系统文件操作。
二、磁盘文件
一个文件在不被打开的时候是存储在磁盘中的,那么这个文件如何在磁盘中合理的存储呢?要了解文件如何在磁盘中存储,我们要先了解磁盘,如下图所示:

磁盘有几个重要的接口,分别是马达,盘片,磁头,一个磁头可以读取一个面的数据。磁盘中每个数据都是0 1,,01 的表示有很多种,波峰波谷,南极北极等,并且磁头和盘面是不接触的,只不过他们离的距离很近,下面是盘面的结构:
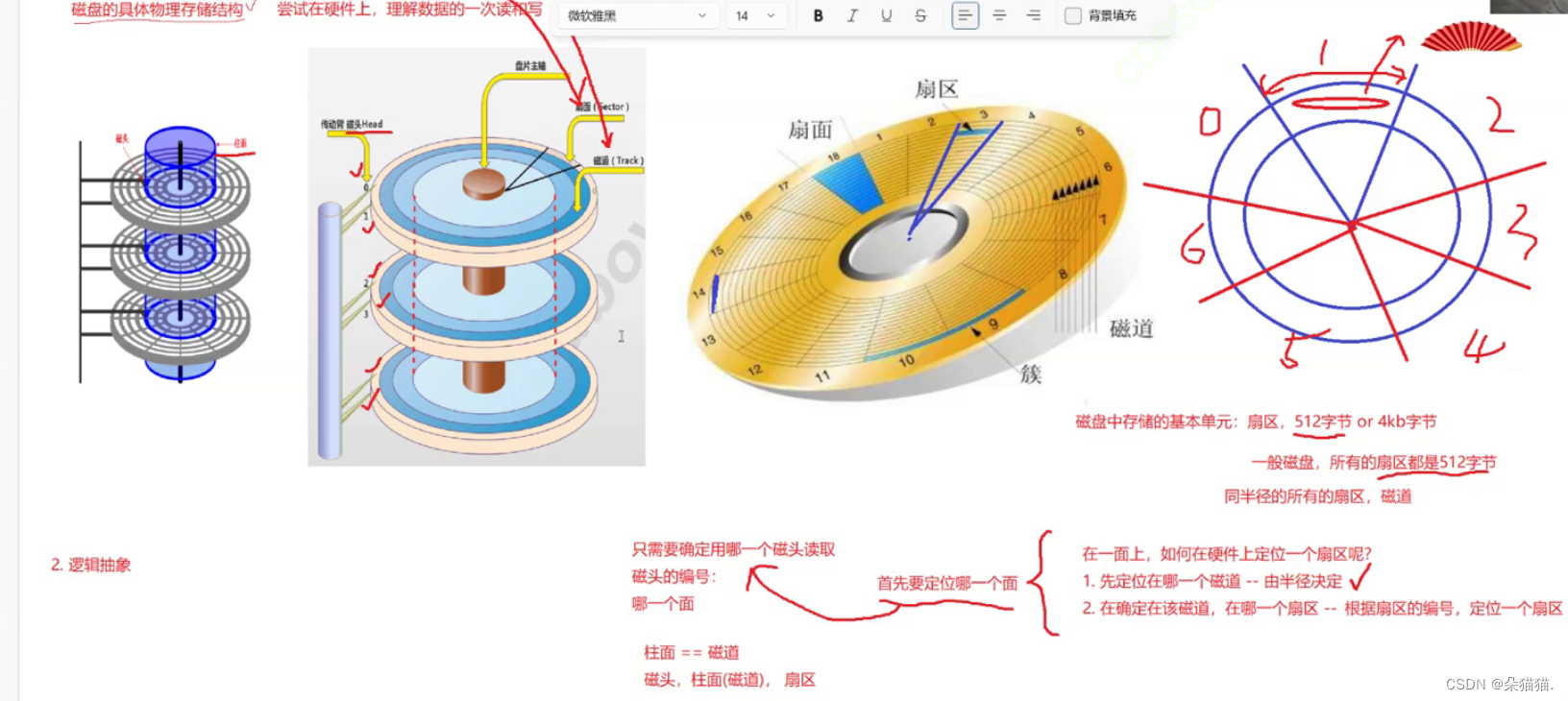
在盘面上有扇区和磁道,一般的磁盘所有的扇区都是512字节,那么如何在硬件上定位一个扇区呢?要定位扇区首先要定位哪一个盘面,而盘面又是通过磁头确定的,因为磁头有相应的编号,通过磁头的编号就能找到哪个面了,找到面后我们要找扇区需要先定位在哪一个磁道,而磁道是通过半径决定的,在确定在该磁道在哪一个扇区,根据扇区的编号定位一个扇区。理解了以上的知识,我们就能谈文件是如何在磁盘中存储的了,一个普通文件(属性+数据)都是数据0,1,对于0 1这样的数据无非就是占用一个或者多个扇区,来进行自己的数据存储的,我们既然能够用CHS定位任意一个扇区,我们就能定位任意多个扇区,从而将文件从硬件角度,进行读取或者写入。
下面我们根据操作系统和磁盘的关系分析一下磁盘:
根据我们上面的描述,如果操作系统能够得知任意一个CHS地址,就能访问任意一个扇区,那么操作系统内部是不是直接使用的CHS地址呢?答案其实不是,因为操作系统是软件,磁盘是硬件,硬件定位一个地址,如果操作系统直接用了这个地址,玩意硬件变了呢?这样的话操作系统也要发生变化,操作系统要和硬件做好解耦工作所以不能直接用硬件上的地址。并且扇区才512字节,操作系统实际向外设写入的基本单位是4KB,与扇区并不符合,所以操作系统需要有一套新的地址来进行块级别的访问。现在我们画一张图表示一下磁道中的扇区结构:

每一个扇区都是512,我们从头开始数512就找到了第一个扇区。这就印证了计算机常规的访问方式:起始地址 + 偏移量的方式,也就是说我们只需要知道数据块的起始地址(第一个扇区的下标地址)+4KB(块的类型)如下图所示:

所以块的地址,本质就是数组的一个下标N,以后我们表示一个块,我们可以采用线性下标N的方式定位任何一个块了。OS->N->LBA->逻辑块地址,前面我们说了,磁盘只认CHS方式,所以要让这两个联系起来就需要LBA到CHS互相转化。就拿我们的电脑而言,我们进入我的电脑发现有ABCD 4个盘或者几个盘,而实际只有一个盘,是因为将这一个盘分区管理得到的四个盘,就如下图所示:
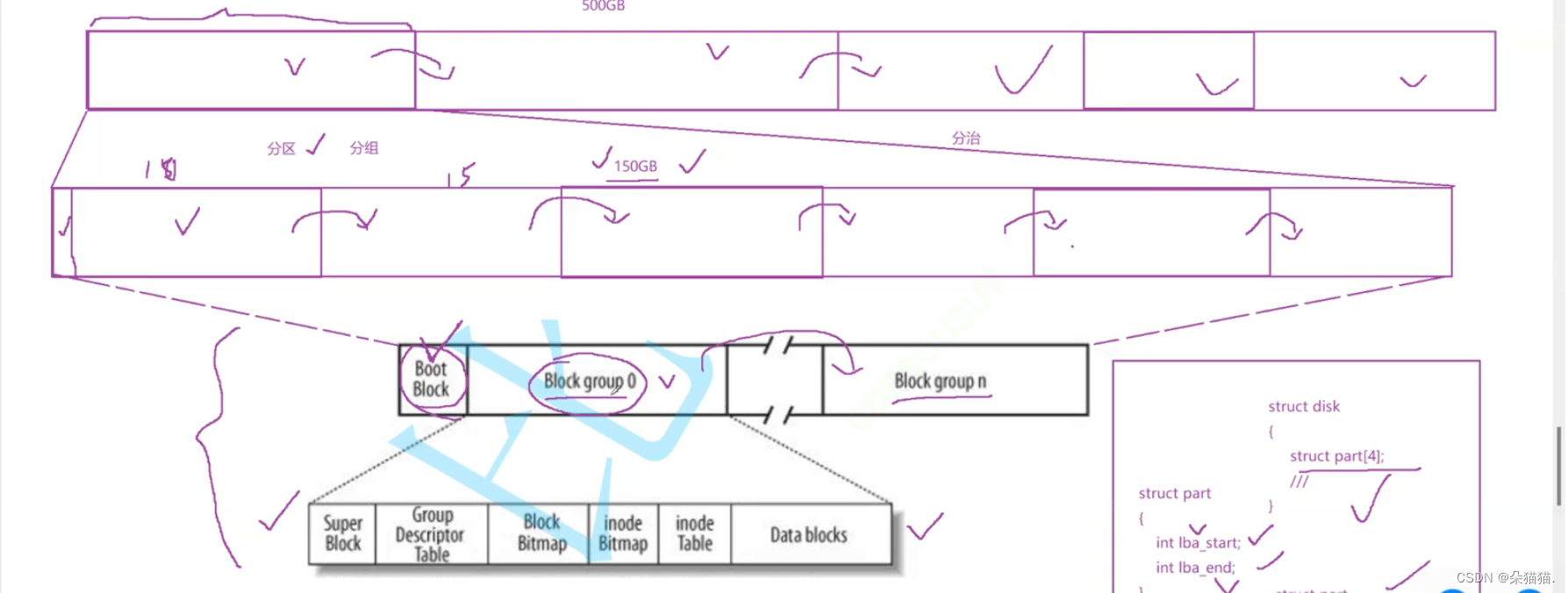
如上图所示,我们将500G的磁盘分为150G一组,那么在这个150G的盘中都有什么呢?其实上图已经给出答案了,Boot Block主要保存与操作系统启动相关的内容,比如分区表,操作系统镜像的地址等,所以一般分区会在0号盘面0号磁道1号扇区保存的,对应的在C盘的某个区域存储,而这个块又被称为启动块,如果这个块坏了就不能开机了。文件= 内容+属性,linux下是将内容和属性分离的。
1.SuperBlock保存的是文件系统的所有属性信息,比如文件系统的类型,整个分组的情况。而SuperBlock在各个分组里面可能都存在,而且是统一更新的,这样做的原因是防止SuperBlock区域坏掉,如果出现故障,整个分区不可以再被使用。
2.GroupDescriptorTable:组描述符,改组内的详细统计等属性信息。
3.inodeTable:一个文件内部所有属性的集合,inode节点(128字节),一个文件一个inode,其中即便是一个分区,内部也会存在大量的文件即会存在大量的inode节点,一个group需要有一个区域,专门保存该group内的所有文件的inode节点。分组内部,可能存在多个inode,需要将inode区分开来,每一个inode都有自己的inode编号,inode编号也属于对应文件的属性id。
4.DateBlocks:文件的内容是变化的,我们是用数据块来进行文件的内容的保存的,所以一个有效文件要保存内容,就需要[1,n]数据块,那么如果是多个文件所以就需要更多的数据块,而DateBlock就是保存这些数据块的。而linux查找文件是要根据inode编号来进行文件查找的,包括读取内容,一个inode对应一个文件,而改文件inode属性和改文件对应的数据块是有映射关系的。
5.块位图BlockBitmap:BlockBitmap中记录着DateBlock中哪个数据块已经被占用,哪个数据块没有被占用。
6.inode位图inodeBitmap:每个bit表示一个inode是否空闲可用
总结
本篇文章的主要内容是在上一篇文件操作的基础上再次深刻理解系统文件操作,然后我们又大致讲解了磁盘的物理空间是什么样的是如何存储数据的,通过软硬件共同学习我们能知道文件的各个属性在磁盘中是如何存储的,每个分区又有什么块的知识,下一篇文章我们将详细介绍文件的软硬链接。
版权归原作者 朵猫猫. 所有, 如有侵权,请联系我们删除。