
🎇Linux:
- 博客主页:一起去看日落吗
- 分享博主的在Linux中学习到的知识和遇到的问题
博主的能力有限,出现错误希望大家不吝赐教- 分享给大家一句我很喜欢的话: 看似不起波澜的日复一日,一定会在某一天让你看见坚持的意义,祝我们都能在鸡零狗碎里找到闪闪的快乐🌿🌞🐾。

✨ ⭐️ 🌟 💫
目录
💫1. 简单的TCP英译汉服务器
✨1.1 简单回顾
在上一篇博客当中实现了简单的TCP服务器,最开始我们实现的是单执行流的TCP服务器,之后通过代码测试发现单执行流的TCP服务器无法同时为多个客户端提供服务,于是又转而实现了多执行流的TCP服务器。
在实现多执行流的TCP服务器时,分别演示了多进程和多线程的实现方式,为了进一步优化基于多线程的TCP服务器,最终还将线程池接入到了TCP服务器当中。此时访问TCP服务器的各个客户端,分别由不同的执行流为其提供服务,因此这些客户端能够同时享受服务器提供的服务。
如果想要让这里的TCP服务器处理其他任务,只需要修改对应的处理函数即可。对应到最终实现的线程池版本的TCP服务器,我们要修改的其实就只是任务类当中的handler方法。下面我们以实现简单的TCP英译汉服务器为例,看看更改后我们的TCP服务器能否正常为客户端提供英译汉服务。
✨1.2 更改handler方法
英译汉TCP服务器要做的就是,根据客户端发来的英文单词找到其对应的中文意思,然后将该中文意思作为响应数据发给客户端。
之前我们是以回调的方式处理任务的,当线程池当中的线程从任务队列中拿出一个任务后,会调用该任务对应的Run方法处理该任务,而实际在这个Run方法当中会以仿函数的方式调用handler方法,因此我们只需更改Handler类当中对()的重载函数即可,而其他与通信相关的代码我们一律不用更改。
英译汉时需要根据英文单词找到其对应的中文意思,因此我们需要建立一张映射表,其中英文单词作为映射表中的键值key,而中文意思作为与键值相对应的value,这里可以直接使用C++STL容器当中的unordered_map容器。
classHandler{public:Handler(){}~Handler(){}voidoperator()(int sock, std::string client_ip,int client_port){//only for test
std::unordered_map<std::string, std::string> dict;
dict.insert(std::make_pair("apple","苹果"));
dict.insert(std::make_pair("water","水"));
dict.insert(std::make_pair("computer","电脑"));char buffer[1024];
std::string value;while(true){
ssize_t size =read(sock, buffer,sizeof(buffer)-1);if(size >0){//读取成功
buffer[size]='\0';
std::cout << client_ip <<":"<< client_port <<"# "<< buffer << std::endl;
std::string key = buffer;auto it = dict.find(key);if(it != dict.end()){
value = it->second;}else{
value = key;}write(sock, value.c_str(), value.size());}elseif(size ==0){//对端关闭连接
std::cout << client_ip <<":"<< client_port <<" close!"<< std::endl;break;}else{//读取失败
std::cerr << sock <<" read error!"<< std::endl;break;}}close(sock);//归还文件描述符
std::cout << client_ip <<":"<< client_port <<" service done!"<< std::endl;}};
说明一下:
- 这里只是测试更改后的服务器能否为客户端提供英译汉服务,因此直接将这张映射表定义在了()重载函数当中。
- 初始化这张映射表对应的操作,就是建立单词与其中文意思之间的映射关系,代码中为了测试只简单建立了三组映射关系。此外,初始化映射表的操作应该重新封装出一个初始化函数,否则每次为客户端提供英译汉服务时都会重新建立映射关系。
- 如果你自己要实现一个英译汉服务器,应该将这张映射表定义为静态,保证全局只有一张映射表,在启动服务器时就可以对这张映射表进行初始化。可以将中英文对照单独写在一个文件当中,在启动服务器时就可以将该文件加载进来,建立对应的映射关系。(这里我们只是做测试的,就不做过多的设计了)
- 当服务端在为客户端提供英译汉服务时,如果在映射表中不存在对应key值的键值对,则服务端会直接将用户发来的数据响应给客户端。
✨1.3 代码测试
现在这个TCP服务器就能够给客户端提供英译汉的服务了,客户端发来的单词如果能够在映射表当中找到,那么服务端会将该单词对应发中文意思响应给客户端,否则会将客户端发来的单词原封不动的响应给客户端。

注意: 这里只是想告诉大家,我们可以通过改变这里的handler方法来改变服务器处理任务的逻辑。如果你还想对当前这个英译汉服务器进行完善,可以在网上找一找牛津词典对应的文件,将其中单词和中文的翻译做出kv的映射关系,当服务器启动的时候就可以加载这个文件,建立对应的映射关系,此时就完成了一个网络版的英译汉服务器。
💫2. 地址转换函数
✨2.1 字符串IP转整数IP
- inet_ntoa函数
intinet_aton(constchar*cp,structin_addr*inp);
参数说明:
- cp:待转换的字符串IP。
- inp:转换后的整数IP,这是一个输出型参数。
返回值说明:
- 如果转换成功则返回一个非零值,如果输入的地址不正确则返回零值。
- inet_addr函数
in_addr_t inet_addr(constchar*cp);
参数说明:
- cp:待转换的字符串IP。
返回值说明:
- 如果输入的地址有效,则返回转换后的整数IP;如果输入的地址无效,则返回INADDR_NONE(通常为-1)。
- inet_pton函数
intinet_pton(int af,constchar*src,void*dst);
参数说明:
- af:协议家族。
- src:待转换的字符串IP。
- dst:转换后的整数IP,这是一个输出型参数。
返回值说明:
- 如果转换成功,则返回1。
- 如果输入的字符串IP无效,则返回0。
- 如果输入的协议家族af无效,则返回-1,并将errno设置为EAFNOSUPPORT。
✨2.2 整数IP转字符串IP
- inet_ntoa函数
参数说明:
- in:待转换的整数IP。
返回值说明:
- 返回转换后的字符串IP。
- inet_ntop函数
constchar*inet_ntop(int af,constvoid*src,char*dst, socklen_t size);
参数说明:
- af:协议家族。
- src:待转换的整数IP。
- dst:转换后的字符串IP,这是一个输出型参数。
- size:用于指明dst中可用的字节数。
返回值说明:
- 如果转换成功,则返回一个指向dst的非空指针;如果转换失败,则返回NULL。
说明一下
- 我们最常用的两个转换函数是inet_addr和inet_ntoa,因为这两个函数足够简单。这两个函数的参数就是需要转换的字符串IP或整数IP,而这两个函数的返回值就是对应的整数IP和字符串IP。
- 其中inet_pton和inet_ntop函数不仅可以转换IPv4的in_addr,还可以转换IPv6的in6_addr,因此这两个函数中对应的参数类型是void*。
- 实际这些转换函数都是为了满足某些打印场景的,除此之外,更多的是用来做某些数据分析,比如网络安全方面的数据分析。
✨2.3 关于inet_ntoa函数
inet_ntoa函数可以将四字节的整数IP转换成字符串IP,其中该函数返回的这个转换后的字符串IP是存储在静态存储区的,不需要调用者手动进行释放,但如果我们多次调用inet_ntoa函数,此时就会出现数据覆盖的问题。
如果需要多次调用inet_ntoa函数,那么就要及时保存inet_ntoa的转换结果。
- 并发场景下的inet_ntoa函数
inet_ntoa函数内部只在静态存储区申请了一块区域,用于存储转换后的字符串IP,那么在线程场景下这块区域就叫做临界区,多线程在不加锁的情况下同时访问临界区必然会出现异常情况。并且在APUE中,也明确提出inet_ntoa不是线程安全的函数。
#include<iostream>#include<netinet/in.h>#include<arpa/inet.h>#include<pthread.h>#include<unistd.h>void*Func1(void* arg){structsockaddr_in* p =(structsockaddr_in*)arg;while(1){char* ptr1 =inet_ntoa(p->sin_addr);
std::cout <<"ptr1: "<< ptr1 << std::endl;sleep(1);}}void*Func2(void* arg){structsockaddr_in* p =(structsockaddr_in*)arg;while(1){char* ptr2 =inet_ntoa(p->sin_addr);
std::cout <<"ptr2: "<< ptr2 << std::endl;sleep(1);}}intmain(){structsockaddr_in addr1;structsockaddr_in addr2;
addr1.sin_addr.s_addr =0;
addr2.sin_addr.s_addr =0xffffffff;
pthread_t tid1 =0;pthread_create(&tid1,nullptr, Func1,&addr1);
pthread_t tid2 =0;pthread_create(&tid2,nullptr, Func2,&addr2);pthread_join(tid1,nullptr);pthread_join(tid2,nullptr);return0;}
但是实际在centos7上测试时,在多线程场景下调用inet_ntoa函数并没有出现问题,可能是该函数内部的实现加了互斥锁,这就跟接口本身的设计也是有关系的。
鉴于此,在多线程环境下更加推荐使用inet_ntop函数进行转换,因为该函数是由调用者自己提供缓冲区保存转换结果的,可以规避线程安全的问题。
💫3. TCP协议通讯流程
✨3.1 通讯流程总览
下图是基于TCP协议的客户端/服务器程序的一般流程:
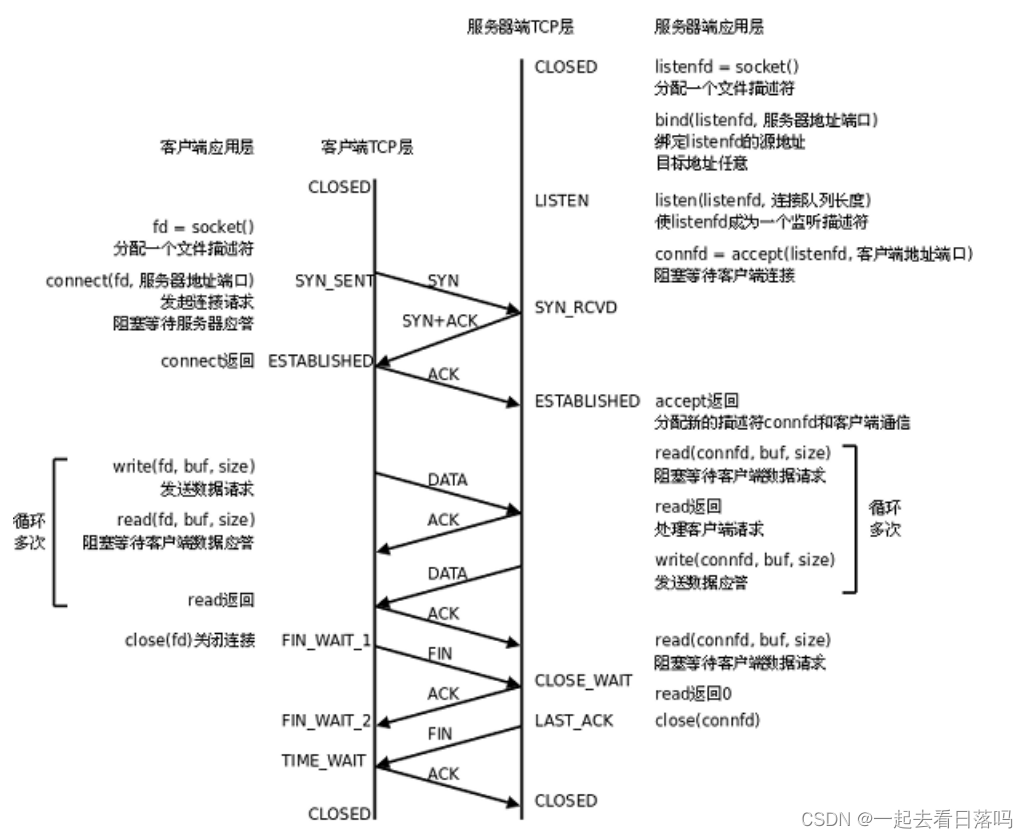 下面我们结合TCP协议的通信流程,来初步认识一下三次握手和四次挥手,以及建立连接和断开连接与各个网络接口之间的对应关系。
下面我们结合TCP协议的通信流程,来初步认识一下三次握手和四次挥手,以及建立连接和断开连接与各个网络接口之间的对应关系。
✨3.2 三次握手的过程
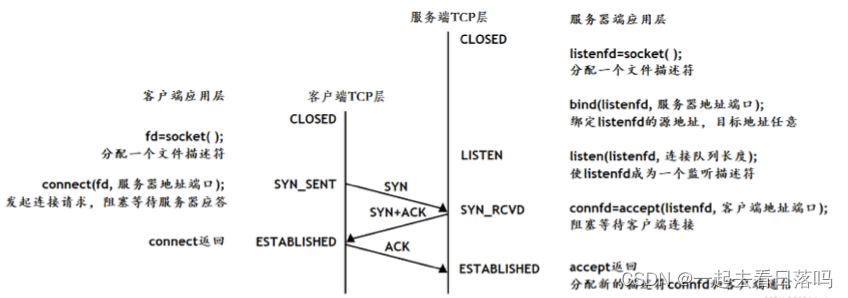
初始化服务器
当服务器完成套接字创建、绑定以及监听的初始化动作之后,就可以调用accept函数阻塞等待客户端发起请求连接了。
服务器初始化:
- 调用socket,创建文件描述符。
- 调用bind,将当前的文件描述符和IP/PORT绑定在一起,如果这个端口已经被其他进程占用了,就会bind失败。
- 调用listen,声明当前这个文件描述符作为一个服务器的文件描述符,为后面的accept做好准备。
- 调用accept,并阻塞,等待客户端连接到来。
建立连接
而客户端在完成套接字创建后,就会在合适的时候通过connect函数向服务器发起连接请求,而客户端在connect的时候本质是通过某种方式向服务器三次握手,因此connect的作用实际就是触发三次握手。
建立连接的过程:
- 调用socket,创建文件描述符。
- 调用connect,向服务器发起连接请求。
- connect会发出SYN段并阻塞等待服务器应答(第一次)。
- 服务器收到客户端的SYN,会应答一个SYN-ACK段表示“同意建立连接”(第二次)。
- 客户端收到SYN-ACK后会从connect返回,同时应答一个ACK段(第三次)。
这个建立连接的过程,通常称为三次握手。
需要注意的是,连接并不是立马建立成功的,由于TCP属于传输层协议,因此在建立连接时双方的操作系统会自主进行三次协商,最后连接才会建立成功。
✨3.3 数据传输的过程
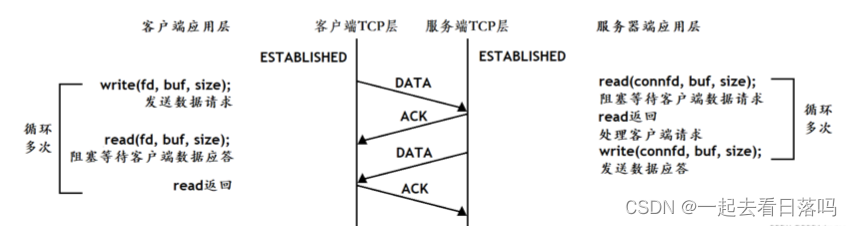
- 数据交互
连接一旦建立成功并且被accept获取上来后,此时客户端和服务器就可以进行数据交互了。需要注意的是,连接建立和连接被拿到用户层是两码事,accept函数实际不参与三次握手这个过程,因为三次握手本身就是底层TCP所做的工作。accept要做的只是将底层已经建立好的连接拿到用户层,如果底层没有建立好的连接,那么accept函数就会阻塞住直到有建立好的连接。
而双方在进行数据交互时使用的实际就是read和write,其中write就叫做写数据,read就叫做读数据。write的任务就是把用户数据拷贝到操作系统,而拷贝过去的数据何时发以及发多少,就是由TCP决定的。而read的任务就是把数据从内核读到用户。
数据传输的过程“:
- 建立连接后,TCP协议提供全双工的通信服务,所谓全双工的意思是,在同一条连接中,同一时刻,通信双方可以同时写数据,相对的概念叫做半双工,同一条连接在同一时刻,只能由一方来写数据。
- 服务器从accept返回后立刻调用read,读socket就像读管道一样,如果没有数据到达就阻塞等待。
- 这时客户端调用write发送请求给服务器,服务器收到后从read返回,对客户端的请求进行处理,在此期间客户端调用read阻塞等待服务器端应答。
- 服务器调用write将处理的结果发回给客户端,再次调用read阻塞等待下一条请求。 客户端收到后从read返回,发送下一条请求,如此循环下去。
✨3.4 四次挥手的过程
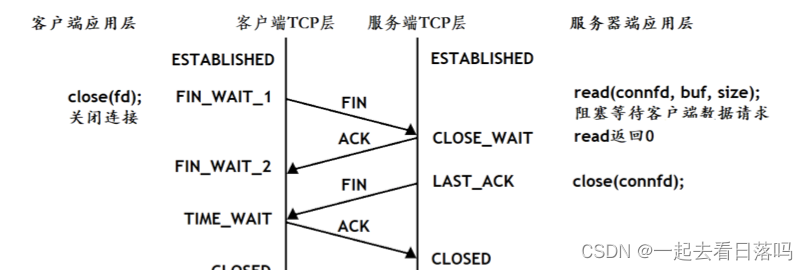
- 端口连接
当双方通信结束之后,需要通过四次挥手的方案使双方断开连接,当客户端调用close关闭连接后,服务器最终也会关闭对应的连接。而其中一次close就对应两次挥手,因此一对close最终对应的就是四次挥手。
断开连接的过程:
- 如果客户端没有更多的请求了,就调用close关闭连接,客户端会向服务器发送FIN段(第一次)。
- 此时服务器收到FIN后,会回应一个ACK,同时read会返回0(第二次)。
- read返回之后,服务器就知道客户端关闭了连接,也调用close关闭连接,这个时候服务器会向客户端发送一个FIN(第三次)。
- 客户端收到FIN,再返回一个ACK给服务器(第四次)。
这个断开连接的过程,通常称为四次挥手。
注意通讯流程与socket API之间的对应关系
在学习socket API时要注意应用程序和TCP协议是如何交互的:
- 应用程序调用某个socket函数时TCP协议层完成什么动作,比如调用connect会发出SYN段。
- 应用程序如何知道TCP协议层的状态变化,比如从某个阻塞的socket函数返回就表明TCP协议收到了某些段,再比如read返回0就表明收到了FIN段。
为什么要断开连接?
建立连接本质上是为了保证通信双方都有专属的连接,这样我们就可以加入很多的传输策略,从而保证数据传输的可靠性。但如果双方通信结束后不断开对应的连接,那么系统的资源就会越来越少。
因为服务器是会收到大量连接的,操作系统必须要对这些连接进行管理,在管理连接时我们需要“先描述再组织”。因此当一个连接建立后,在服务端就会为该连接维护对应的数据结构,并且会将这些连接的数据结构组织起来,此时操作系统对连接的管理就变成了对链表的增删查改。
如果一个连接建立后不断开,那么操作系统就需要一直为其维护对应的数据结构,而维护这个数据结构是需要花费时间和空间的,因此当双方通信结束后就应该将这个连接断开,避免系统资源的浪费,这其实就是TCP比UDP更复杂的原因之一,因为TCP需要对连接进行管理。
💫4. TCP和UDP对比
- 可靠传输 vs 不可靠传输
- 有连接 vs 无连接
- 字节流 vs 数据报
版权归原作者 一起去看日落吗 所有, 如有侵权,请联系我们删除。