
实训指导书
一、实训目的
利用python从指定接口爬取广东省各个地市的气象数据,存储并进行数据分析和可视化
二、****实训任务列表
给定以下3个接口:
1.http://www.nmc.cn/f/rest/province ,用于获取全国各省份数据
2.http://www.nmc.cn/f/rest/province/省份编码,用于获取某个省份的城市数据
3.http://www.nmc.cn/f/rest/passed/城市编号,用于获取某城市最近24小时天气数据
示例:省份编码需从接口1,例如广东省编码为ABC,城市编码利用省份编码从接口2获取,如广州市编号为123456,气象数据利用城市编码从接口3获取
利用python编程从以上3个接口爬取数据,在本地存储为csv文件,csv文件包括:省份数据(provice.csv)、地市数据(city.csv)、广东省各地市气象数据(weather.csv),同时将3个csv文件数据存入mysql数据库中
从数据库读取数据,求各个城市过去24小时的温度(temperature)、湿度(humidity)、气压(pressure)、风速(windSpeed)、最大值、最小值、平均值、众数
计算广州,深圳,佛山三个城市下午13:00温度(temperature)、湿度(humidity)、气压(pressure)、风速(windSpeed)的平均值
分别求各个城市过去24小时的温度(temperature)、湿度(humidity)、气压(pressure)、风速(windSpeed)的top10,用matplotlib进行画图,使用展示的图类型为4种
利用线性回归模型作图,显示温度和湿度二者之间的关联
加分项:利用地图进行展示
一.利用python编程从以上3个接口爬取数据
接口:http://www.nmc.cn/f/rest/province
数据格式如下:

爬取(provice.py)省份数据生成(provice.csv)
# -*- coding: utf-8 -*-
import csv
import json
import requests
#全国各省的数据
url = "http://www.nmc.cn/f/rest/province"
strhtml = requests.get(url) #获取响应结果,构造一个向服务器请求资源的Request对象
province = json.loads(strhtml.text) #json.loads 用于解码 JSON 数据,返回 Python 字段的数据类型
#mode='w'打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
fo = open('province.csv', 'w', newline='', encoding='utf-8-sig')
header = ['code', 'name', 'url']
writer = csv.DictWriter(fo, header)
writer.writeheader()#写入表头
writer.writerows(province)
fo.close()
province.csv表的数据如下:
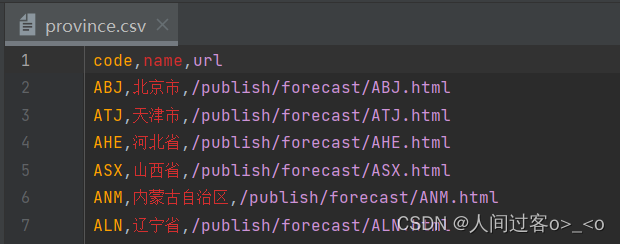
我所在地是广东,所以我选择 广东省的城市数据(AGD)
接口:http://www.nmc.cn/f/rest/province/AGD
数据格式如下:

爬取(city.py)城市数据生成(city.csv)
# -*- coding: utf-8 -*-
import csv
import json
import requests
#广东省的城市数据(AGD)
url = 'http://www.nmc.cn/f/rest/province/AGD'
strhtml = requests.get(url)
city = json.loads(strhtml.text)
fo = open('city.csv', 'w', newline='', encoding='utf-8-sig')
header = ['code', 'province', 'city','url']
writer = csv.DictWriter(fo, header)
writer.writeheader()
writer.writerows(city)
fo.close()
city表的数据格式如下:
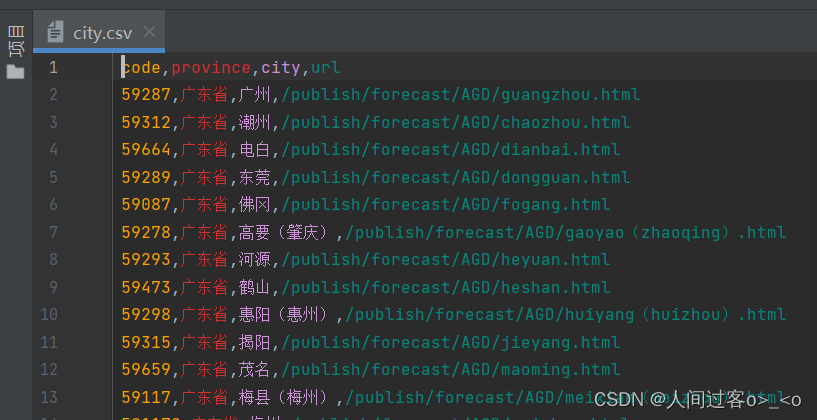
爬取(weather.py)广东省各地市气象数据生成(weather.csv)
import urllib.request
import csv
import pandas as pd
#广东省的城市数据(AGD)
url = 'http://www.nmc.cn/f/rest/province/AGD'
strhtml = urllib.request.urlopen(url) #获取响应结果
GDweather = strhtml.read().decode('utf-8') #进行转码并设置为变量“str”的值
GDweather = eval(GDweather) #将字符串转换为代码执行
for i in range(len(GDweather)):
weather = GDweather[i]
page = weather["code"] # 获取城市编号
city = weather["city"] # 获取城市名
province = weather["province"] # 获取省份
url = "http://www.nmc.cn/f/rest/passed/" + page # 拿到省内具体城市气候数据
strhtml = urllib.request.urlopen(url)
cityweather = strhtml.read().decode('utf-8')
cityweather = eval(cityweather)
weather = []
for i in range(len(cityweather)):
GD = cityweather[i]
new_code = {"code":page}
new_city = {"city":city}
new_provice = {"province": province}
GD.update(new_code) #字典覆盖
GD.update(new_city)
GD.update(new_provice)
weather.append(GD) #往weather = [] 这个空数组中添加从GD中取得的元素
# mode='a+'表示在已有数据基础上添加新数据,并不覆盖已有数据
with open("weather.csv", "a", encoding='utf-8-sig', newline="") as fo:
header = ["code", "province", "city", "rain1h", "rain24h", "rain12h", "rain6h",
"temperature", "tempDiff", "humidity", "pressure",
"windDirection", "windSpeed", "time"]
writer = csv.DictWriter(fo, header)
writer.writeheader()
writer.writerows(weather)
fo.close()
# 数据处理,将weather.csv表,去除重复表头
frame=pd.read_csv('F:\大数据基础实训\weather.csv',engine='python')
data = frame.drop_duplicates(subset=['code','province','city','rain1h','rain24h',
'rain12h','rain6h','temperature','tempDiff',
'humidity','pressure','windDirection',
'windSpeed','time'], keep = False, inplace=False)
data.to_csv('F:\大数据基础实训\weather.csv', encoding='utf8')
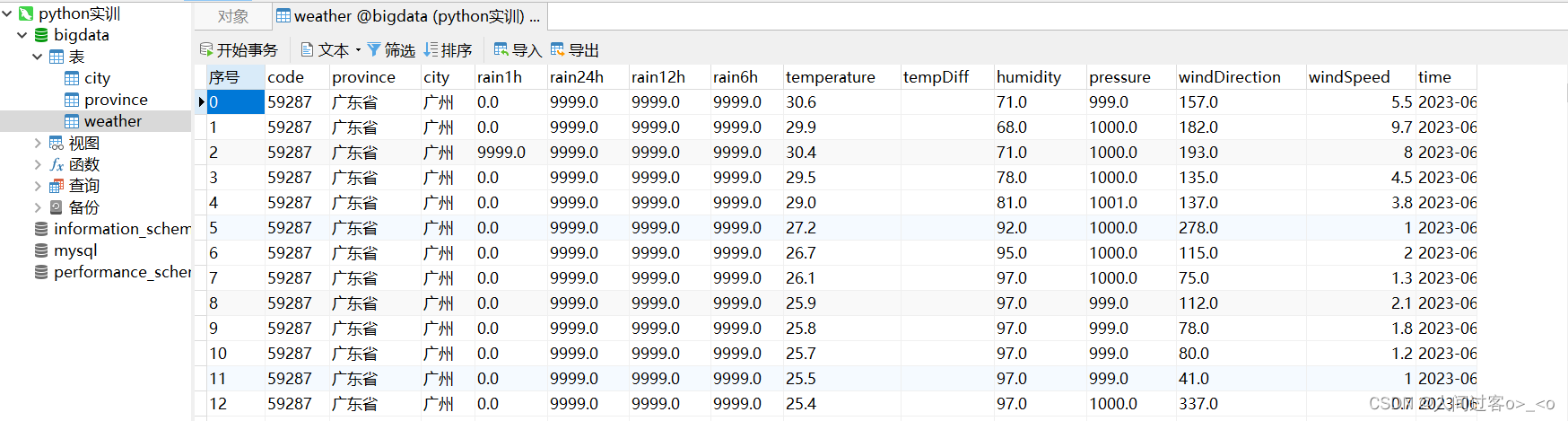
weather表的数据格式如下:
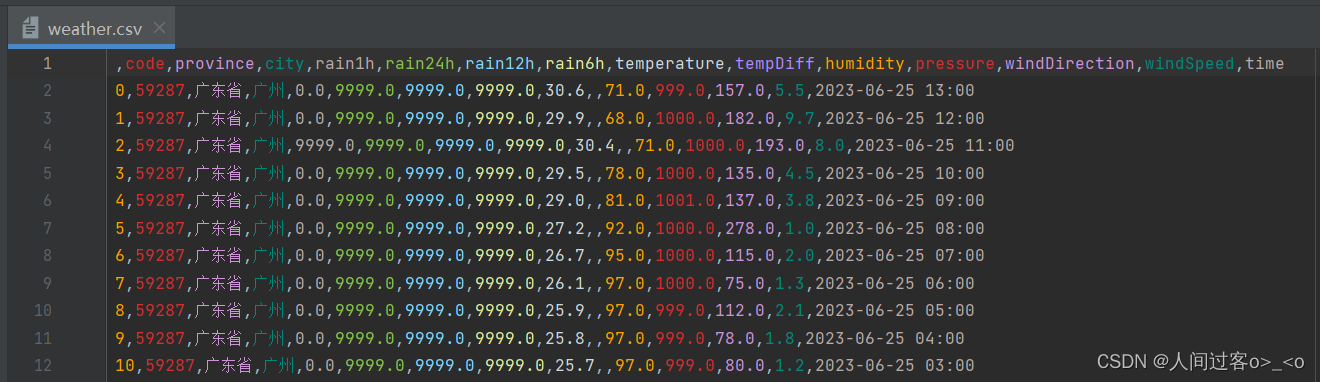
将生成的3个csv文件中的数据分别存入到mysql中
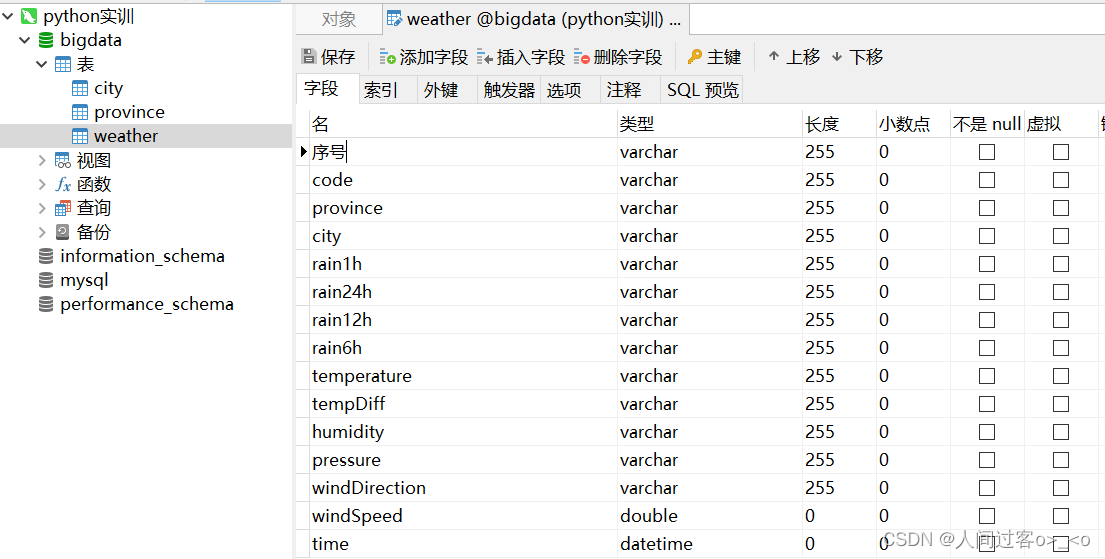
需要先在Navicat中建数据库,我给这个数据库起名为bigdata,然后先在数据库中建3个表,每个表都要有一个和csv文件对应的表头,格式如下:
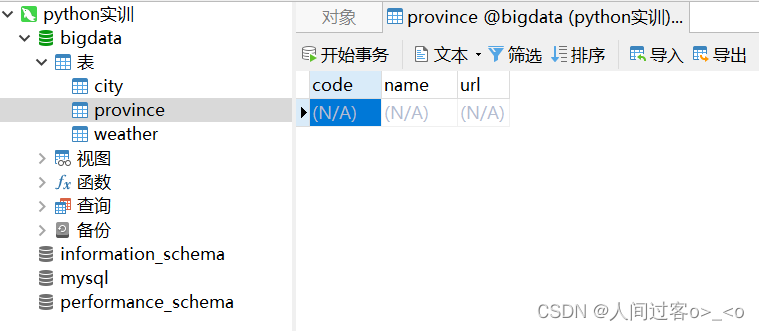
注意:
在weather.csv中的第一列是序号,所以在sql中建weather表的时候也要给第一列起个名,我给它起名为 序号
代码如下:
import csv
import pymysql
def read_csv(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
reader = csv.reader(f)
content = list(reader)[1:]
return content
def insert_data(table_name, data):
# 与数据库建立连接
conn = pymysql.connect(host='localhost', user='root', password='123456', database='bigdata', charset='utf8')
cursor = conn.cursor() # 创建游标对象
# 组装插入数据的SQL语句
sql = "insert into {} values".format(table_name) + str(tuple(data))
cursor.execute(sql) # 执行插入数据的SQL语句
conn.commit() # 提交数据
cursor.close() # 关闭游标
conn.close() # 关闭数据库连接
# 读取并插入Province表数据
province_data = read_csv('F:\大数据基础实训\province.csv')
for data in province_data:
insert_data('province', data)
# 读取并插入City表数据
city_data = read_csv('city.csv')
for data in city_data:
insert_data('city', data)
# 读取并插入Weather表数据
weather_data = read_csv('weather.csv')
for data in weather_data:
insert_data('weather', data)
** 存入数据库成功!! **
如下:
二.从数据库读取数据,求各个城市过去24小时的温度(temperature)、湿度(humidity)、气压(pressure)、风速(windSpeed)、最大值、最小值、平均值、众数
从数据库读取数据各个城市过去24小时的温度(temperature)、湿度(humidity)、气压(pressure)、风速(windSpeed)的最大值、最小值、平均值 。
import pymysql
import csv
#打开数据库连接
db = pymysql.connect(host='localhost',user='root',password='123456',database='bigdata',charset='utf8')
# print("从数据库读取数据,求各个城市过去24小时的温度(temperature)、湿度(humidity)、气压(pressure)、风速(windSpeed)、最大值、最小值、平均值")
cursor = db.cursor() #使用cursor()方法创建一个游标对象cursor
cursor.execute("SELECT "
"city,"
"AVG(temperature) as 温度平均值,"
"MAX(temperature) as 温度最大值,"
"MIN(temperature) as 温度最小值,"
"AVG(humidity) as 湿度平均值,"
"MAX(humidity) as 湿度最大值,"
"MIN(humidity) as 湿度最小值,"
"AVG(pressure) as 气压平均值,"
"MAX(pressure) as 气压最大值,"
"MIN(pressure) as 气压最小值,"
"AVG(windSpeed) as 风速平均值,"
"MAX(windSpeed) as 风速最大值,"
"MIN(windSpeed) as 风速最小值 FROM weather GROUP BY city") #使用 execute()方法执行SQL查询
data = cursor.fetchall() #使用fetchall()方法获取所有的数据,以元组形式返回
#关闭数据库连接
db.close()
with open("max-min-avg.csv", "w+", newline="", encoding='utf-8-sig') as file:
header = ('城市', '温度平均值', '温度最大值', '温度最小值', '湿度平均值',
'湿度最大值', ' 湿度最小值', '气压平均值', '气压最大值',
'气压最小值', '风速平均值', '风速最大值', '风速最小值')
pen = csv.writer(file)
pen.writerow(header)
# 遍历data中的每一行,并且转换为列表格式 (默认 tuple)
for i in data:
a = list(i)
pen.writerow(a)
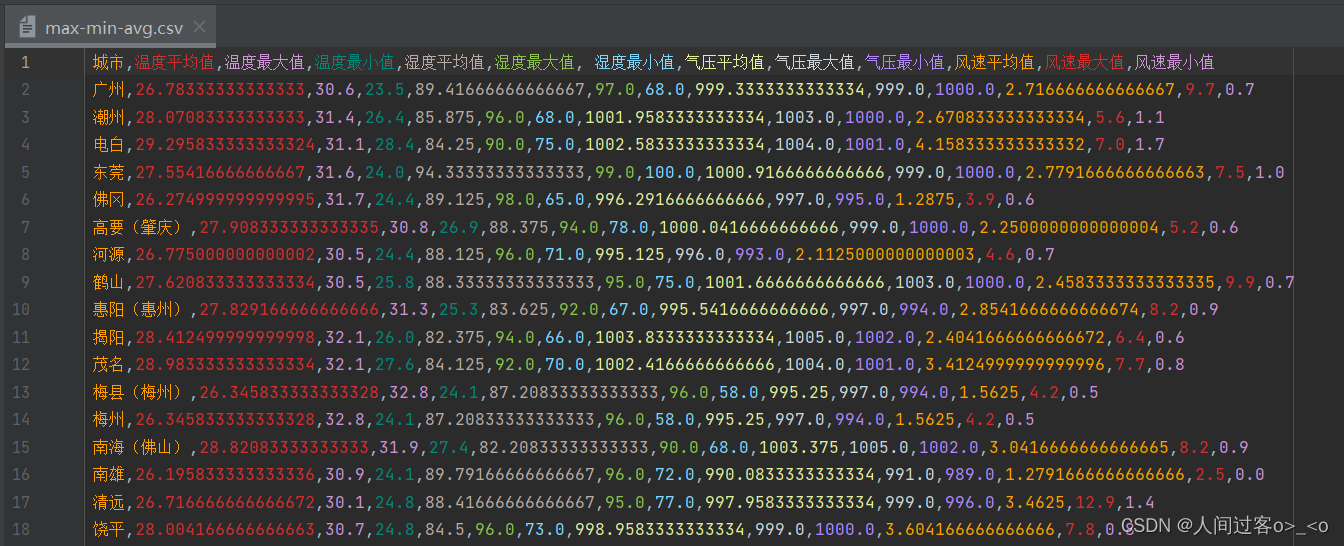
max-min-avg.csv表数据如下:
从数据库读取数据,广东省各个城市过去24小时的温度(temperature)、湿度(humidity)、气压(pressure)、风速(windSpeed)的众数。
代码如下:
import pymysql
conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='bigdata', port=3306, charset='utf8')
cursor = conn.cursor()
sql = "SELECT city, temperature, humidity, pressure, windSpeed FROM weather WHERE time >= DATE_SUB(NOW(), INTERVAL 1 DAY)"
cursor.execute(sql)
rows = cursor.fetchall()
from statistics import mode
cities = {}
for row in rows:
city, temperature, humidity, pressure, windSpeed = row
if city not in cities:
cities[city] = {}
cities[city]['temperature'] = cities[city].get('temperature', []) + [temperature]
cities[city]['humidity'] = cities[city].get('humidity', []) + [humidity]
cities[city]['pressure'] = cities[city].get('pressure', []) + [pressure]
cities[city]['windSpeed'] = cities[city].get('windSpeed', []) + [windSpeed]
result = []
for city in cities:
temperature_mode = mode(cities[city]['temperature'])
humidity_mode = mode(cities[city]['humidity'])
pressure_mode = mode(cities[city]['pressure'])
windSpeed_mode = mode(cities[city]['windSpeed'])
result.append([city, temperature_mode, humidity_mode, pressure_mode, windSpeed_mode])
import csv
with open('zhongshu.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(['城市', '温度众数', '湿度众数', '气压众数', '风速众数'])
writer.writerows(result)
zhongshu.csv的数据如下:

三. 计算广州,深圳,佛山三个城市下午13:00温度(temperature)、湿度(humidity)、气压(pressure)、风速(windSpeed)的平均值
代码如下:
import pymysql
import csv
#打开数据库连接
db = pymysql.connect(host='localhost',user='root',password='123456',database='bigdata',charset='utf8')
# 计算广州,深圳,佛山三个城市下午14:00温度(temperature)、湿度(humidity)、气压(pressure)、风速(windSpeed)的平均值
sor = db.cursor()
sor.execute("SELECT "
"AVG(temperature) as 平均温度,"
"AVG(humidity) as 平均湿度,"
"AVG(pressure) as 平均气压,"
"AVG(windSpeed) as 平均风速 "
"FROM weather where city in('广州','深圳','佛山') and time = '2023-6-25 13:00'")
data = sor.fetchall()
print(data)
# 关闭数据库连接
db.close()
运行结果如下:

四. 分别求各个城市过去24小时的温度(temperature)、湿度(humidity)、气压(pressure)、风速(windSpeed)的top10,用matplotlib进行画图,使用展示的图类型为4种
1.先求不同指标的top10,存为csv文件。代码如下:
import pymysql
import csv
db = pymysql.connect(host='localhost', user='root', password='123456', database='bigdata', charset='utf8')
data = {
'温度': 'temperature',
'湿度': 'humidity',
'气压': 'pressure',
'风速': 'windSpeed'
}
for key, value in data.items():
cursor = db.cursor()
cursor.execute(f"SELECT city, {value} FROM weather GROUP BY city ORDER BY {value}+0 DESC LIMIT 10;")
result = cursor.fetchall()
with open(f"top10-{value}.csv", "a+", newline="", encoding='utf-8-sig') as file:
header = ('city', value)
pen = csv.writer(file)
pen.writerow(header)
for i in result:
a = list(i)
pen.writerow(a)
db.close()
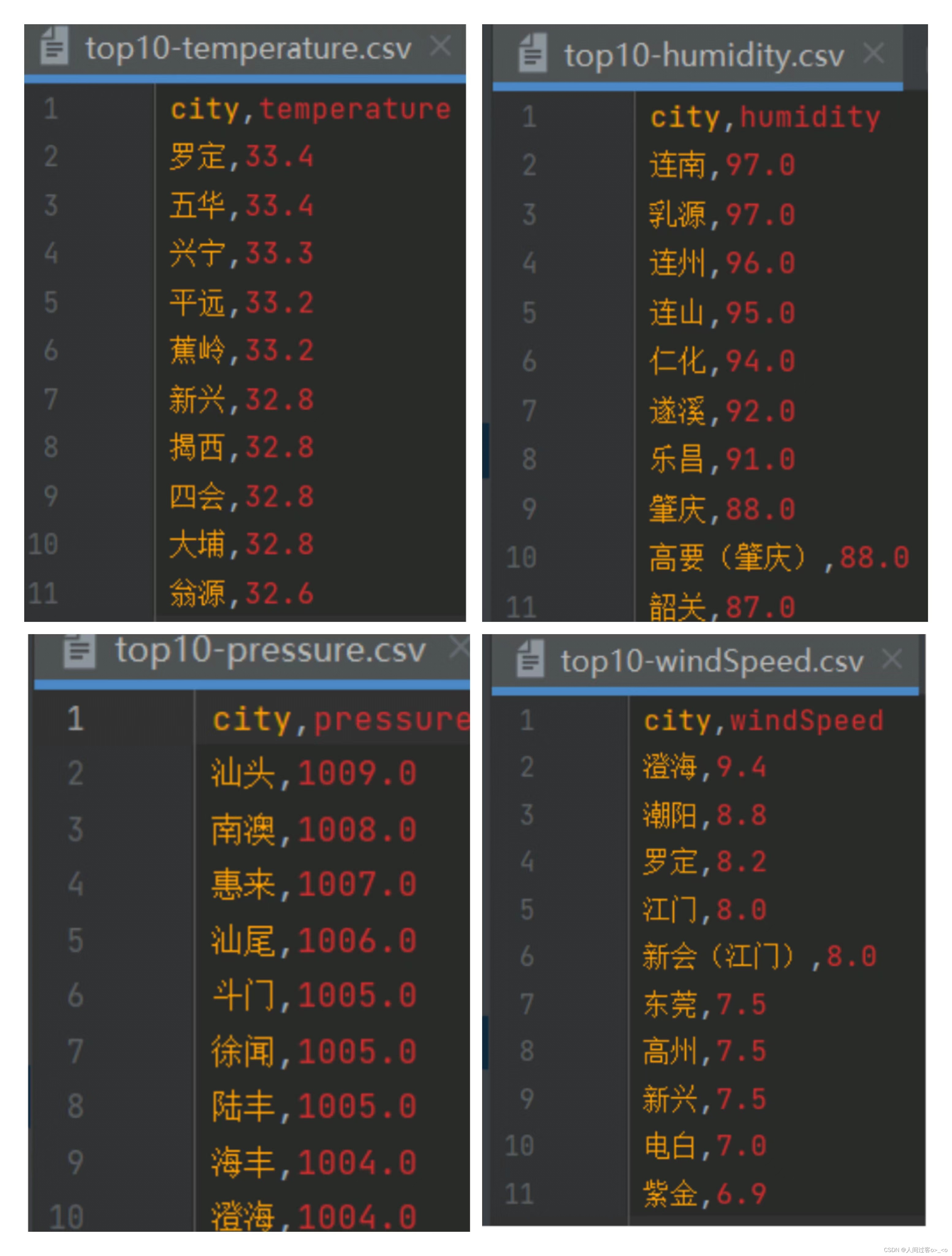
csv文件,分别为(如下图):
2.用matplotlib进行画图,使用展示的图类型为4种。(这里我用折线图、柱状图,饼图,散点图)。
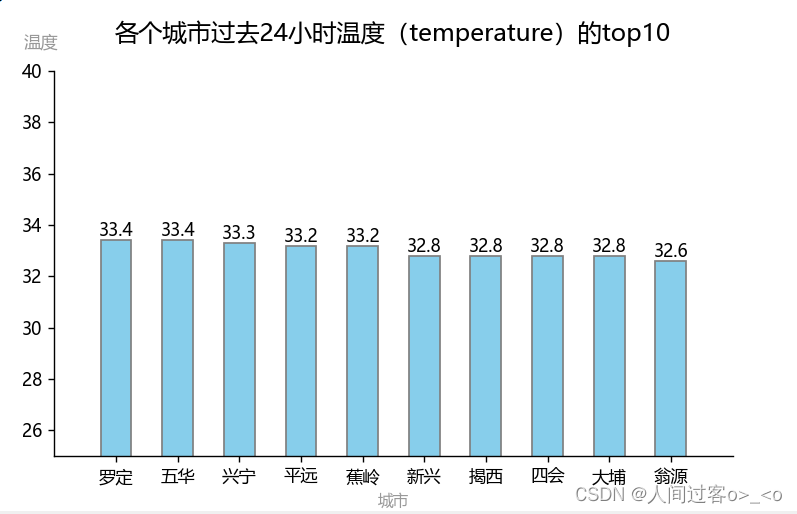
** 用各个城市过去24小时的温度的top10,作柱状图,代码如下:**
import pandas as pd
import matplotlib.pyplot as plt
#如遇中文显示问题可加入以下代码
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] # 指定默认字体['SimHei']
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#最方便的写法
frame = pd.read_csv('F:/大数据基础实训/top10-temperature.csv', engine='python')
fig, ax = plt.subplots(figsize=(7,4), dpi=100)
x = frame['city']
y = frame['temperature'] #直接拿
# 柱状图 0.5是柱子的大小,edgecolor是柱子周边的颜色
bar = plt.bar(x, y, 0.5,color='skyblue', edgecolor='gray')
# 设置标题,y=1.05表示标题距离图上边框的距离
ax.set_title('各个城市过去24小时温度(temperature)的top10',fontsize=14,y=1.05)
# 设置Y坐标轴标题,字体颜色的深浅值越大颜色越深alpha = 0.4,rotation=300可以调整Y坐标的角度
ax.set_ylabel("温度",fontsize = 10,alpha = 0.4,rotation=360)
ax.yaxis.set_label_coords(-0.02,1.05) #温度的位置
# 设置Y轴区间
ax.set_ylim(25,40)
# 设置X坐标轴标题
ax.set_xlabel("城市",fontsize = 9,color = 'black',alpha = 0.4,rotation=360)
ax.set_xlim(-1,10)
# 显示数据标签
plt.bar_label(bar, label_type='edge')
# 边框隐藏
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
# ax.spines['bottom'].set_visible(False)
# ax.spines['left'].set_visible(False)
plt.show()
运行结果如下:
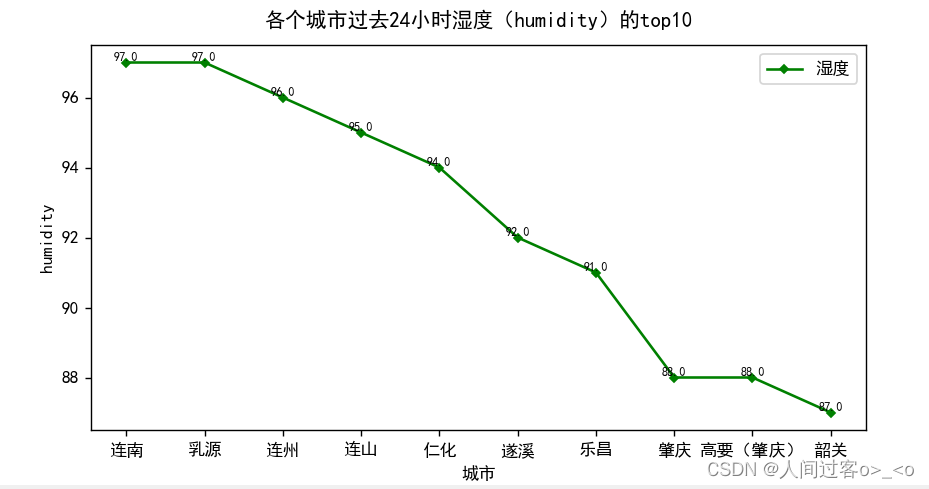
用各个城市过去24小时的湿度的top10,作折线图,代码如下:
import matplotlib.pyplot as plt
import pandas as pd
#如遇中文显示问题可加入以下代码
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
frame = pd.read_csv('F:/大数据基础实训/top10-humidity.csv', engine='python')
#准备绘制数据
fig, ax = plt.subplots(figsize=(8,4), dpi=100)
x = frame['city']
y = frame['humidity'] #直接拿
# "g" 表示红色,marksize用来设置'D'菱形的大小
plt.plot(x, y, "g", marker='D', markersize=3, label="湿度")
#绘制坐标轴标签
plt.xlabel("城市")
plt.ylabel("humidity")
plt.title("各个城市过去24小时湿度(humidity)的top10",y=1.02)
# plt.xlim((-1,10))#坐标轴设定
#显示图例
plt.legend(loc="upper right")
#调用 text()在图像上绘制注释文本
#x1、y1表示文本所处坐标位置,ha参数控制水平对齐方式, va控制垂直对齐方式,str(y1)表示要绘制的文本
for x1, y1 in zip(x, y):
plt.text(x1, y1, str(y1), ha='center', va='bottom', fontsize=7)
plt.show()
运行结果如下:
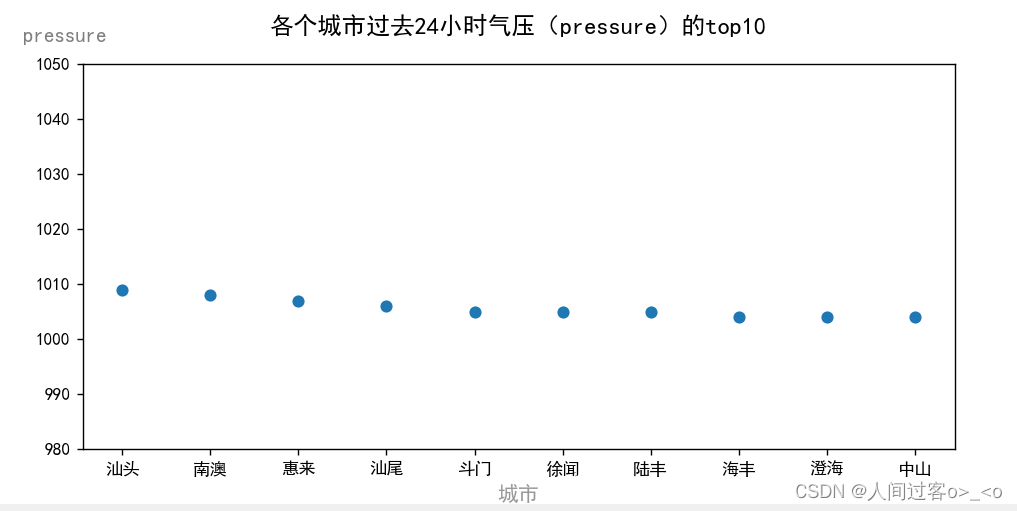
用各个城市过去24小时的气压的top10,作散点图,代码如下:
# coding=utf-8
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体,解决中文乱码
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
frame = pd.read_csv('F:/大数据基础实训/top10-pressure.csv', engine='python')
fig, ax = plt.subplots(figsize=(9,4), dpi=100)
city = frame['city']
pressure = frame['pressure']
plt.xlabel("城市",fontsize = 12,color = 'black',alpha = 0.4,rotation=360)
plt.ylabel("pressure",fontsize = 12,color = 'black',alpha = 0.5,rotation=360)
ax.yaxis.set_label_coords(-0.02,1.05)
ax.set_ylim(980,1050)
# 设置标题,y=1.05表示标题距离图上边框的距离
ax.set_title('各个城市过去24小时气压(pressure)的top10',fontsize=14,y=1.05)
plt.scatter(city,pressure)
plt.show()
运行结果如下:
用各个城市过去24小时的风速的top10,作饼图,代码如下:
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
frame = pd.read_csv('F:/大数据基础实训/top10-windSpeed.csv', engine='python')
y = frame['city']
x = frame['windSpeed']
explode = (0.1, 0, 0, 0,0,0,0,0,0,0) #它指定偏移每个楔形的半径的分数
colors = ['r', 'g', 'skyblue', 'c', 'pink', 'yellow', 'aquamarine',"#377eb8","#4daf4a","#984ea3"]
fig,ax1 = plt.subplots() #返回一个包含figure和axes对象的元组,将元组分解为fig和ax两个变量。
#绘制饼状图,labels数据对应标签,autopct用于指定每个扇形块标注文本的样式,比如:定义百分数精度,shadow阴影,startangle起始角度
ax1.pie(x, explode=explode,colors = colors,
labels=y, autopct='% 1.5f %%',
shadow=True, startangle=90)
ax1.axis('equal')#让圆更像圆
ax1.set_title('各个城市过去24小时风速(windSpeed)的top10') #标题
plt.show()
运行结果如下:

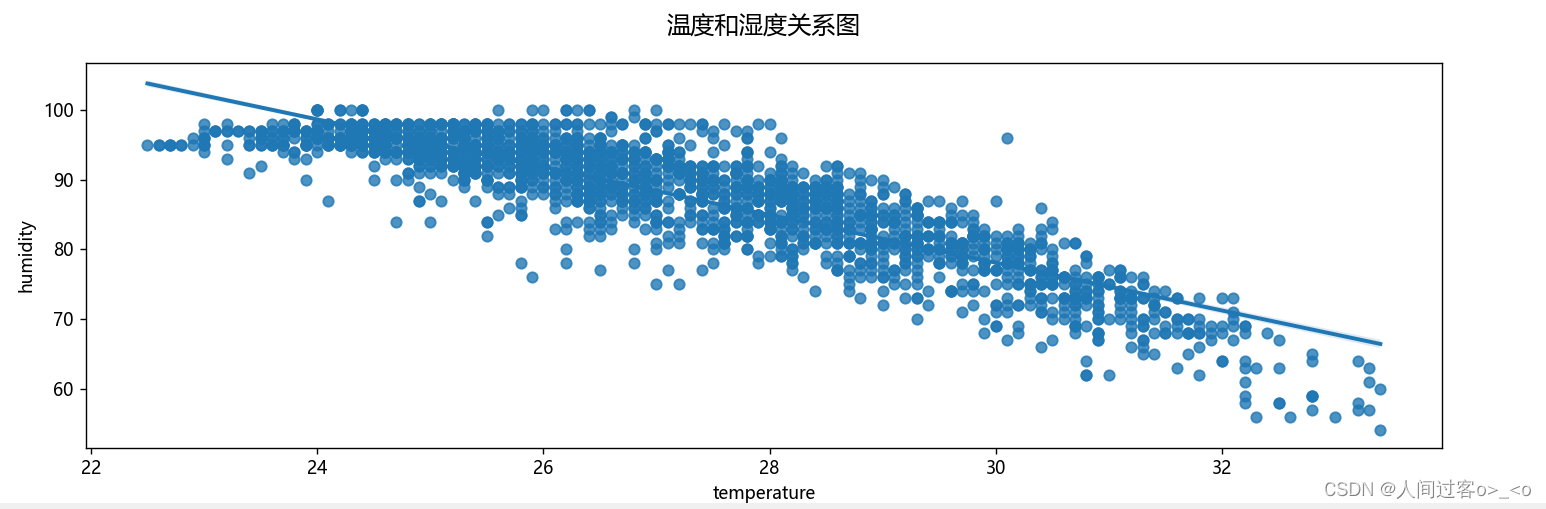
五. 利用线性回归模型作图,显示温度和湿度二者之间的关联
我先查看了温度和湿度的相关性,然后再进行的线性回归模型的绘画,代码如下:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from pylab import mpl
from sklearn.preprocessing import MinMaxScaler
from sklearn.linear_model import LinearRegression as LR
from sklearn.model_selection import train_test_split
mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei']
mpl.rcParams['axes.unicode_minus'] = False
GDweather = pd.read_csv("F:\大数据基础实训\weather.csv")
# 数据集中不同变量之间的相关性
print(GDweather.corr(numeric_only=True))
# 检查相关性
data_set = GDweather.iloc[:,[8,10]]
print(data_set.corr())
fig, ax = plt.subplots(figsize=(14,4), dpi=100)
ax.set_title('温度和湿度关系图',fontsize=14,y=1.05)
# 绘制温度和湿度的关系图
sns.regplot(x=data_set["temperature"], y=data_set["humidity"],data=data_set)
plt.show()
# 数据预处理
data = GDweather[['temperature', 'humidity']]
# 数据缩放
scaler = MinMaxScaler()
data = scaler.fit_transform(data)
print(data)
#数据集划分为训练集和测试集
x = data[:, 0].reshape(-1, 1)
y = data[:, 1].reshape(-1, 1)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
#模型初始化
lr=LR()
#模型训练
lr.fit(x_train,y_train)
# 模型预测
y_train_pred = lr.predict(x_train)
y_test_pred = lr.predict(x_test)
#分别计算误差,确定是否过拟合;评估模型的泛化能力
from sklearn import metrics as ms
train_err = ms.mean_squared_error(y_train,y_train_pred)
test_err = ms.mean_absolute_error(y_test,y_test_pred)
print("训练集均方误差:",train_err)
print("测试集平均绝对误差:",test_err)
# 性能评估 决定系数
predict_score = lr.score(x_test,y_test)
print('得分::{:.2f}'.format(predict_score))
# 绘制关系图
import matplotlib.pyplot as plt
plt.scatter(x_test, y_test)
plt.plot(x_test, y_test_pred, color='red', linewidth=2)
plt.xlabel('temperature')
plt.ylabel('humidity')
plt.title('温度和湿度回归图',fontsize=14,y=1.05)
plt.show()
运行出来的图如下:

6. 加分项:利用地图进行展示
我这里是选择了爬取中国各省市的气候情况,对数据进行预处理后,将其提取各省气温的平均值进行可视化。
全国各省市天气的爬取代码如下:
import urllib.request
import csv
url = "http://www.nmc.cn/f/rest/province" #全国各省的数据
strhtml = urllib.request.urlopen(url)#获取响应结果
data = strhtml.read().decode('utf-8')
data = eval(data)
for i in range(len(data)):#循环爬取全国数据
try: #抛出异常
pro = data[i]
print(pro)
page = pro["code"] # 获取省份编号
# 全国各个省份
url = "http://www.nmc.cn/f/rest/province/" + page # 按照省份编号code循环获取地市数据
strhtml = urllib.request.urlopen(url)
allc = strhtml.read().decode('utf-8')
allc = eval(allc) # 得到全国各省市
city = []
for i in range(len(allc)): # len(allc)表示一个省内市的个数
citys = allc[i] # c 里面是各省市的数据
pages = citys["code"] # 获取城市编号
province = citys["province"] # 获取省份
city = citys["city"] # 获取城市名
url = "http://www.nmc.cn/f/rest/passed/" + pages # 拿到省内具体城市气候数据
strhtml = urllib.request.urlopen(url)
weathers = strhtml.read().decode('utf-8')
weathers = eval(weathers) # 得到全国各省市天气数据
weather = [] # 空数组
for i in range(len(weathers)): # 循环爬取
weath = weathers[i]
code = {"code":pages}
provi = {"province": province}
city1 = {"city": city}
weath.update(code)
weath.update(provi)
weath.update(city1)
weather.append(weath)
# mode='a+'表示在已有数据基础上添加新数据,并不覆盖已有数据
with open("China-Weather.csv", "a+", encoding='utf-8-sig', newline="") as fo:
header = ["code","province", "city", "rain1h", "rain24h", "rain12h", "rain6h",
"temperature", "tempDiff", "humidity", "pressure",
"windDirection", "windSpeed", "time"]
writer = csv.DictWriter(fo, header)
writer.writeheader()
writer.writerows(weather)
fo.close()
print(weather)
except Exception as emmm:
pass
continue
代码中有一个抛出异常值处理,有一些地方爬取数据是会报错,直接跳过。爬取到的数据格式如下:
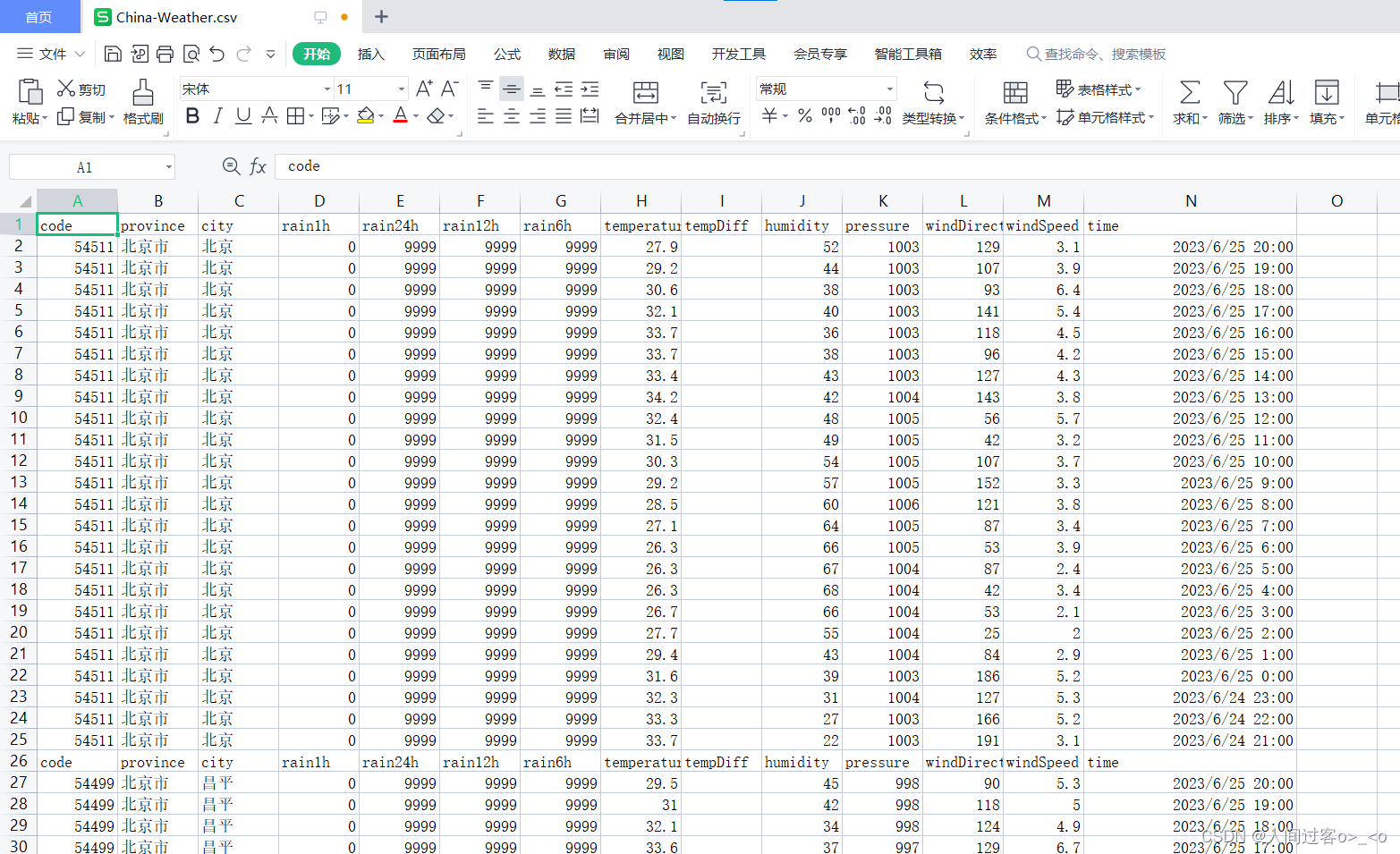
通过上图,将 数据进行预处理,去除重复的表头,删除不要的列(保留省份,城市,温度),代码如下:
# 处理China-Weather.csv表,去除重复表头
import pandas as pd
frame = pd.read_csv('F:\大数据基础实训\China-Weather.csv', engine='python')
df = frame.drop_duplicates(subset=['code','province','city','rain1h','rain24h',
'rain12h','rain6h','temperature','tempDiff',
'humidity','pressure','windDirection',
'windSpeed','time'], keep=False, inplace=False)
#删除不要的列
df = df.drop(['code','rain1h','rain24h','rain12h','rain6h','tempDiff',
'humidity','pressure','windDirection',
'windSpeed','time'], axis = 1) # 按列名称
# 写为China-weather1
df.to_csv('F:\大数据基础实训\China-Weather1.csv',index=False)
处理完的数据如下:
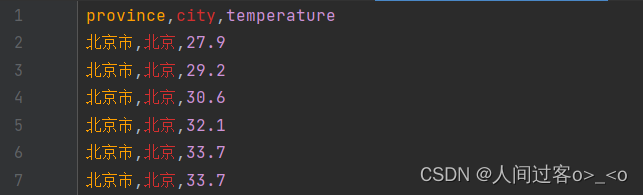
数据可视化,先通过省份来求温度的平均值,最后进行数据可视化,代码如下:
import pandas as pd #pandas是强大的数据处理库
from pyecharts.charts import Map
from pyecharts import options as opts
from pyecharts.globals import ThemeType #引入主题
Map(init_opts=opts.InitOpts(width="1000px", height="600px",theme = ThemeType.DARK)) #添加主题ThemeType.DARK
data = pd.read_csv('F:\大数据基础实训\China-Weather1.csv', encoding='gbk')
# 使用groupby按照省份分组
data = data.groupby('province')
# 计算每个分组temperature平均值,使用unstack()将第一级索引转换为列
mean_temperature = data.temperature.mean()
mean_temperature.to_csv('F:\大数据基础实训\province-temperature.csv', encoding='gbk')
data = pd.read_csv('F:\大数据基础实训\province-temperature.csv', encoding='gbk')
province = list(data["province"])
temperature = list(data["temperature"])
list = [list(z) for z in zip(province,temperature)]
China = (
Map(init_opts=opts.InitOpts(width="1200px", height="800px",theme = ThemeType.DARK)) #添加主题ThemeType.DARK
.set_global_opts(
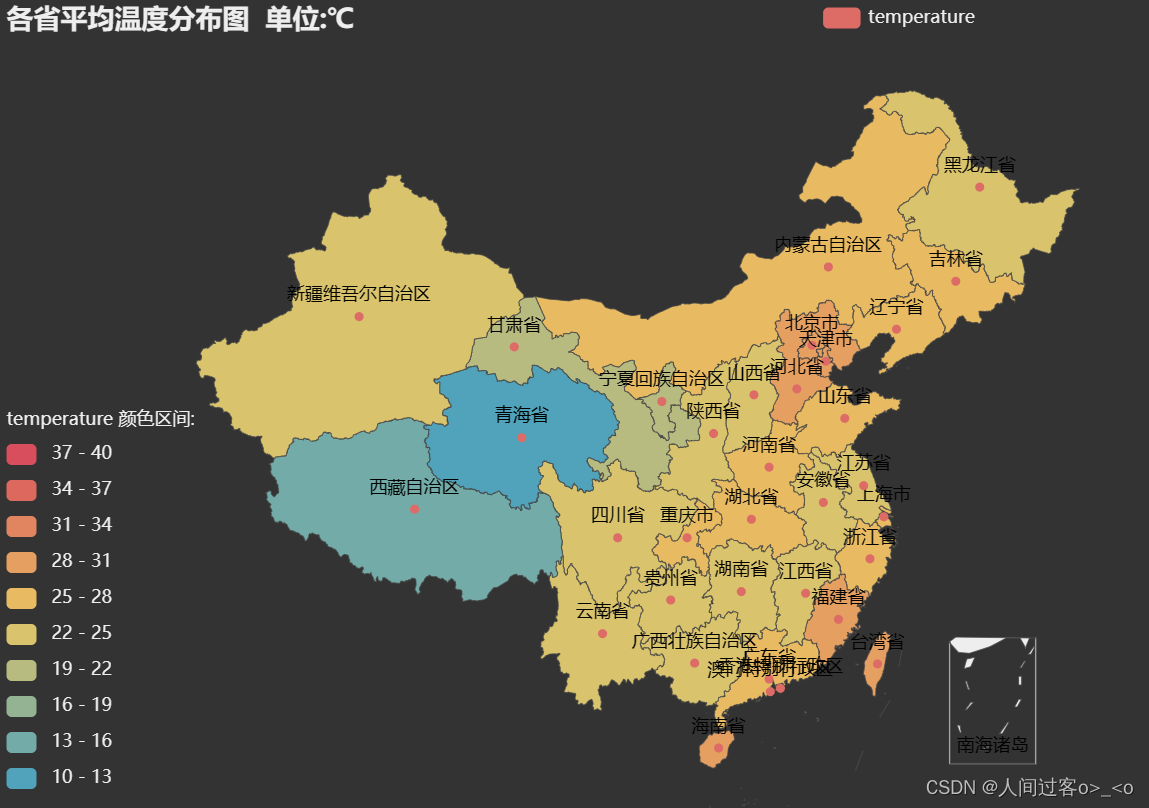
title_opts=opts.TitleOpts(title="各省平均温度分布图 单位:℃"),
visualmap_opts=opts.VisualMapOpts(
min_=10,
max_=40,
range_text = ['temperature 颜色区间:', ''], #分区间
is_piecewise=True, #定义图例为分段型,默认为连续的图例
pos_top= "middle", #分段位置
pos_left="top left",
orient="vertical",
split_number=10 #分成10个区间
)
)
.add("temperature",list,maptype="china")
.render("temperature.html")
)
可视化结果如下:
数据可视化,先通过全国各城市来求温度的平均值,最后进行数据可视化,代码如下:
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Geo
from pyecharts.globals import ChartType
data = pd.read_csv('F:\大数据基础实训\China-Weather.csv', encoding='gbk')
# 使用groupby按照城市分组
data = data.groupby('city')
# 计算每个分组温度平均值,使用unstack()将第一级索引转换为列
mean_temperature = data.temperature.mean()
mean_temperature.to_csv('F:\大数据基础实训\city-temperature.csv', encoding='gbk')
data = pd.read_csv('F:\大数据基础实训\city-temperature.csv', encoding='gbk')
c = (
Geo(is_ignore_nonexistent_coord=True, init_opts=opts.InitOpts(width="1280px", height="800px", theme='dark')) # 图表大小, 主题风格
.add_schema(maptype="china", # 地图
itemstyle_opts=opts.ItemStyleOpts(color="#28527a", # 背景颜色
border_color="#9ba4b4")) # 边框颜色, 可在 https://colorhunt.co/选择颜色
.add(
"", # 系列名称, 可不设置
[(i, j) for i, j in zip(data['city'], data['temperature'])], # 数据
type_=ChartType.EFFECT_SCATTER, # 涟漪散点
effect_opts=opts.EffectOpts(symbol_size=1), # 标记大小
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # 不显示标签
.set_global_opts(title_opts=opts.TitleOpts(title="全国城市气温", # 图表标题
pos_left='center', # 标题位置
subtitle='更新日期:2023-6-26', # 副标题
subtitle_link='http://tianqi.2345.com/air-rank.html'), # 副标题链接
visualmap_opts=opts.VisualMapOpts(max_=200,
range_text=['temperature', ''], # 上下的名称
split_number=4, # 如果是连续数据, 分成几段
pos_left='5%', # pos_right
pos_top='40%', # pos_bottom
is_piecewise=True, # 是否为分段显示
pieces=[{"min":10 , "max": 11.9, "color": "blue",'label': '温凉'},
{"min":12, "max":13.9, "color": "lightblue",'label': '微温凉'},
{"min":14 , "max":15.9 , "color": "green",'label': '温和'},
{"min": 16, "max": 17.9, "color": "lightgreen",'label': '微温和'},
{"min": 18, "max": 19.9, "color": "yellow",'label': '温和'},
{"min": 20, "max":21.9 , "color": "orange",'label': '暖'},
{"min": 22, "max": 24.9, "color": "darkorange",'label': '热'},
{"min": 25, "max": 27.9, "color": "red",'label': '炎热'},
{"min": 28, "max": 29.9, "color": "crimson",'label': '暑热'},
{"min": 30, "max": 34.9, "color": "purple",'label': '酷热'},
{"min": 35, "max": 39.9, "color": "pink",'label': '奇热'},
{"min": 40, "max": 44.9, "color": "brown",'label': '极热'}
])))
c.render('F:\大数据基础实训\city_tem.html')
可视化结果如下:

版权归原作者 人间过客o>_<o 所有, 如有侵权,请联系我们删除。