
代码有点长,完整代码放在文章最后了。
最后的数据存储为了3个表,表的各字段如下:
# csv头部
writer.writerow(('话题链接', '话题内容', '楼主ID', '楼主昵称', '楼主性别', '发布日期',
'发布时间', '转发量', '评论量', '点赞量', '评论者ID', '评论者昵称',
'评论者性别', '评论日期', '评论时间', '评论内容')) #微博博文与评论的全部信息
writer_1.writerow(('话题链接', '楼主ID', '话题内容','楼主昵称', '楼主性别','是否认证','认证类型',
'是否认证金v','发博数量','关注人数','粉丝数','微博等级', '发布日期',
'发布时间', '转发量', '评论量', '点赞量')) #微博博文的信息(不包含评论)
writer_2.writerow(('楼主ID','评论者ID','话题内容','评论内容','评论者昵称', '评论者性别','是否认证','认证类型',
'是否认证金v','发博数量','关注人数','粉丝数','微博等级', '发布日期','评论日期',
'评论时间', '回复量', '点赞量')) #评论的信息
1.爬取前的准备工作:
建议使用谷歌浏览器,通过cookie和headers来登录微博,注意cookie是手机登录模式下的cookie,否则评论会获取不全

headers = {
'cookie': cookie,
'user-agent': ua,
'Referer':'https://s.weibo.com/weibo?q=%E5%9B%BD%E8%B6%B3%E6%AD%A6%E7%A3%8A&typeall=1&suball=1×cope=custom:2021-11-05:2021-12-06-0&Refer=g',
'x-requested-with': 'XMLHttpRequest'
}
2.通过微博网页版的高级搜索,复制对应的URL

3.通过requests.get(url=url, headers=headers) 来解析网页,并通过正则表达式获取到所有微博的唯一标识符mid,后续都根据mid来获取微博信息

rep1 = requests.get(url=api_url, headers=headers)
# rep1.enconding= rep1.apparent_encoding
try:
rep=rep1.text
comment_ID=re.findall('(?<=mid=")\d{16}', rep)
comments_ID.extend(comment_ID)
print(page,"页id获取成功!",comment_ID)
except:
print(page,"页id获取有误!")
4.通过手机端口来爬取数据,会比电脑端口爬取数据方便。在手机端口里(m.weibo.cn),根据刚刚获取到的mid可以获得每条微博的数据。
article_url = 'https://m.weibo.cn/detail/' + comment_ID
html_text = requests.get(url=article_url, headers=headers).text
发布日期、话题内容、楼主ID、楼主昵称等信息都可以通过正则表达式从html_text中获取到。
# 话题内容
find_title = re.findall('.*?"text": "(.*?)",.*?', html_text)[0]
title_text = re.sub('<(S*?)[^>]*>.*?|<.*? />', '', find_title) #
# print("title_text = ", title_text)
# 楼主ID
title_user_id = re.findall('.*?"id": (.*?),.*?', html_text)[1]
# print("title_user_id = ", title_user_id)
# 楼主昵称
title_user_NicName = re.findall('.*?"screen_name": "(.*?)",.*?', html_text)[0]
# print("title_user_NicName = ", title_user_NicName)
# 楼主性别
title_user_gender = re.findall('.*?"gender": "(.*?)",.*?', html_text)[0]
5.通过一条博文的max_id和max_id_type获取到博文下面的评论信息
def parse_page(jsondata):
if jsondata:
items = jsondata.get('data')
item_max_id = {}
item_max_id['max_id'] = items['max_id']
item_max_id['max_id_type'] = items['max_id_type']
print('评论页面max_id和max_id_type获取成功!')
return item_max_id
def get_page(comment_ID, max_id, id_type):
params = {
'max_id': max_id,
'max_id_type': id_type
}
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id={}&max_id_type={}'.format(comment_ID, comment_ID,max_id,id_type)
try:
time.sleep(2)
r = requests.get(url,headers=headers)
if r.status_code==200:
print('评论页面解析成功!')
return r.json()
except requests.ConnectionError as e:
print('评论页面解析错误!', e.args)
pass
6.根据正则表达式获取评论数据
# 评论者ID
user_id = json['user']['id']
# 评论者昵称
user_name = json['user']['screen_name']
# 评论者性别,m表示男性,表示女性
user_gender = json['user']['gender']
user_statuses_count = json['user']['statuses_count']#评论者发博数量
user_verified = json['user']['verified'] # 评论者是否认证
user_verified_type = json['user']['verified_type'] # 评论者认证类型
if user_verified=='true':
user_verified_type_ext = json['user']['verified_type_ext'] # 评论者是否金v
else:
user_verified_type_ext = 0
user_follow_count = json['user']['follow_count'] # 评论者关注数
user_followers_count = json['user']['followers_count'] # 评论者发博数
user_urank = json['user']['urank'] # 评论者微博等级
# 获取评论
comments_text = json['text']
comment_text = re.sub('<(S*?)[^>]*>.*?|<.*? />', '', comments_text) # 正则匹配掉html标签
# print('评论内容:',comment_text)
# 评论时间
created_times = json['created_at'].split(' ')
comment_total_number=json["total_number"]#评论的回复数量
comment_like_count = json["like_count"] # 评论的点赞数量
其实整个爬取的流程就是获取url,解析网页,根据正则表达式获取需要的信息。
代码有点长,完整代码放在文章最后了。
链接: https://pan.baidu.com/s/1LPCYq3dwBBzPty0FLBp4pA 提取码: 79yu 复制这段内容后打开百度网盘手机App,操作更方便哦
如果有需要的话,原代码需要改动的地方如下:
1.文件存储路径:

- cookie,有时候爬虫太多次了cookie就会失效,这时候可以再换一个cookie

3.还有一个很重要的参数Refer,这里每换一个关键词最好都要改一下
4.搜索的关键词和时间范围:在原代码里year都是2021,如果想找不同年份的,可以设置year1,year2,后面api_url中记得也要改成year1,year2
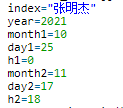
5.每次爬取的页。在高级搜索中最多只能看50页的内容,50页之外的就是实时微博了,而不是想要搜索的微博。所以如果想搜索的微博远不止50页,那就只能再缩短时间范围。比如你想找1.1-1.15期间含有关键词“张明杰”的微博,第50页的最后一条微博是1.5日18:00,那只能再把时间范围改为1.5 18:00-1.15日,然后再去爬取数据。

start_date和end_date是为了防止有时间范围之外的微博被爬取到了,这个可以根据需要改成自己的

版权归原作者 去看海0 所有, 如有侵权,请联系我们删除。