
简单介绍
1.登录到要爬取信息的页面
登录系统(填写账号密码)→进入表格数据所在的网页页面→定位下拉选框并进行选择→定位时间框选择日期→在选择日期时弹出的是另一个网页窗口进行选择,所以要将切换环境到日期所在的窗口地址→选完日期后切回原来窗口
2.循环爬取信息并保存到Excel
想象一下和Excel一样的格式,第一行是标题,第二行开始是所要采集的数据,一共有13个标题,每个标题有11行数据(这里只例举3列数据的采集),按照这个格式完全的copy到Excel。而这个系统在进行翻页时url并不会发生变化,在采集完当页数据后,只好依靠selenium模拟点击下一页再进行循环采集,之后就是不断重复这个采集完再点击再采集的动作。
完整代码
我在看别人的文章的时候就喜欢那种上来就给全码的,后面哪里出错了再回来看解释,所以我自己写也这么写,哈哈哈哈哈哈哈哈
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from time import sleep
from selenium.webdriver.support import select
from selenium.webdriver.support.select import Select
from selenium.webdriver.support.ui import Select
import pandas as pd
from lxml import etree #乱复制一通哪些有用哪些没用已经不知道了
#创建对象
driver = webdriver.Chrome('C:\Program Files\Google\Chrome\Application/chromedriver.exe') #我直接复制绝对路径了
driver.get('http://') #这里放的是我的登录网址
sleep(1) #等待1秒,网页加载得快的可以不用
#进入页面
driver.find_element_by_xpath('//*[@id="UserIdText"]').send_keys('账号')
driver.find_element_by_xpath('//*[@id="PasswordText"]').send_keys('密码')
driver.find_element_by_xpath('//*[@id="LoginButton"]').click() #点击登录按钮
driver.get('http://') #在登录之后还要一直点点点才能到达我要爬的网页,我就直接获取了那个网页的地址
#找到下拉选框
selectTag =Select(driver.find_element_by_name('XXX'))
#根据指来选择
selectTag.select_by_value('XXX')
#找到时间框并点击(筛选日期)
driver.find_element_by_xpath('//*[@id="SHIFTDATEFROM"]').click()
#切换环境到新页面
driver.switch_to_window(driver.window_handles[1])
driver.get('http://') #进入选择时间时弹出的网页,否则就不能在那个网页窗口进行点击动作
#选择日期——8月1日
driver.find_element_by_xpath('//*[@id="divCalendar"]/table[2]/tbody/tr[2]/td[1]/span').click()
#切换环境到原来页面
driver.switch_to_window(driver.window_handles[0])
driver.find_element_by_xpath('//*[@id="cmdQuery"]').click() #点击查询按钮
#建立空列表
SHIF_list =[]
MAN_list =[]
WORK_list =[]
count =1
#获取数据
while count <=50:print('获取第{}页'.format(count))for i inrange(11): #一共有11行数据
#获取网页源码
resp_text = driver.page_source
#数据解析
page_html = etree.HTML(resp_text)
#开始把表格信息写入并做到能够循环
SHIF_list.insert(1,page_html.xpath('//*[@id="grdGrid"]/tbody/tr[{}]/td[1]/text()'.format(i+1)))
MAN_list.insert(1,page_html.xpath('//*[@id="grdGrid"]/tbody/tr[{}]/td[2]/text()'.format(i+1)))
WORK_list.insert(1,page_html.xpath('//*[@id="grdGrid"]/tbody/tr[{}]/td[3]/text()'.format(i+1)))
a ={'SHIFTDATE':SHIF_list,'MANPOWERTYPE':MAN_list,'WORKINGHOURS':WORK_list,}
#点击下一页
driver.find_element_by_xpath('//*[@id="pageREPORT_btnNextPage"]').click()
count = count+1
offline_a = pd.DataFrame(a) #忘了什么意思,但有dataframe应该是转成Excel那样的表格样式吧
offline_a.to_excel('随便叫什么.xlsx',index=False) #保存到Excel
#driver.quit() #关闭webdriver
代码解析
碎碎念开始~~
因为除了是能够给大家提供借鉴之外也是自己的一种记录,经历过的坎坷想都把它记录下来。
from selenium import webdriver
webdriver安装教程,貌似代码里除了这个其他都是pip直接安装的
链接: link.
driver.find_element_by_xpath('//*[@id="UserIdText"]').send_keys('账号')
遇到Xpath不要慌~ Google浏览器复制粘贴就完事儿~
F12→点击左上角的箭头→点击要选择的地方→右键copy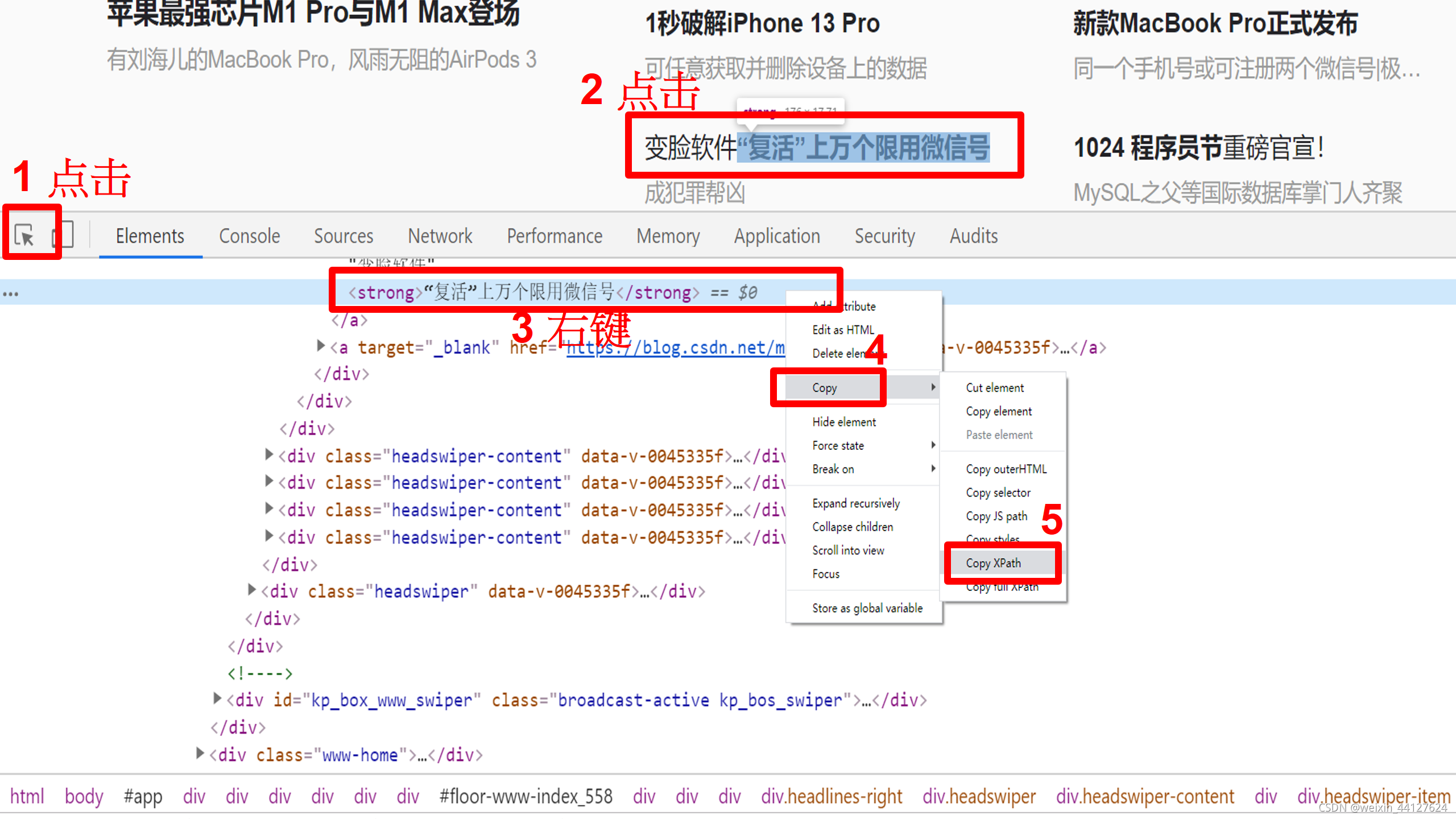
driver.find_element_by_xpath('//*[@id="LoginButton"]').click()
click(),只要是有鼠标点击的动作都要用click,否则只定位到了没用~
selectTag =Select(driver.find_element_by_name('XXX'))
这里就是find_element了,我这里选择的是根据名字进行选择的,在F12里复制,也可以根据id、value等,可以自由选择,具体就看F12的标签中哪个值是唯一的,哪个唯一选哪个。例如如果是by_id的话就把引号里面的值复制进去。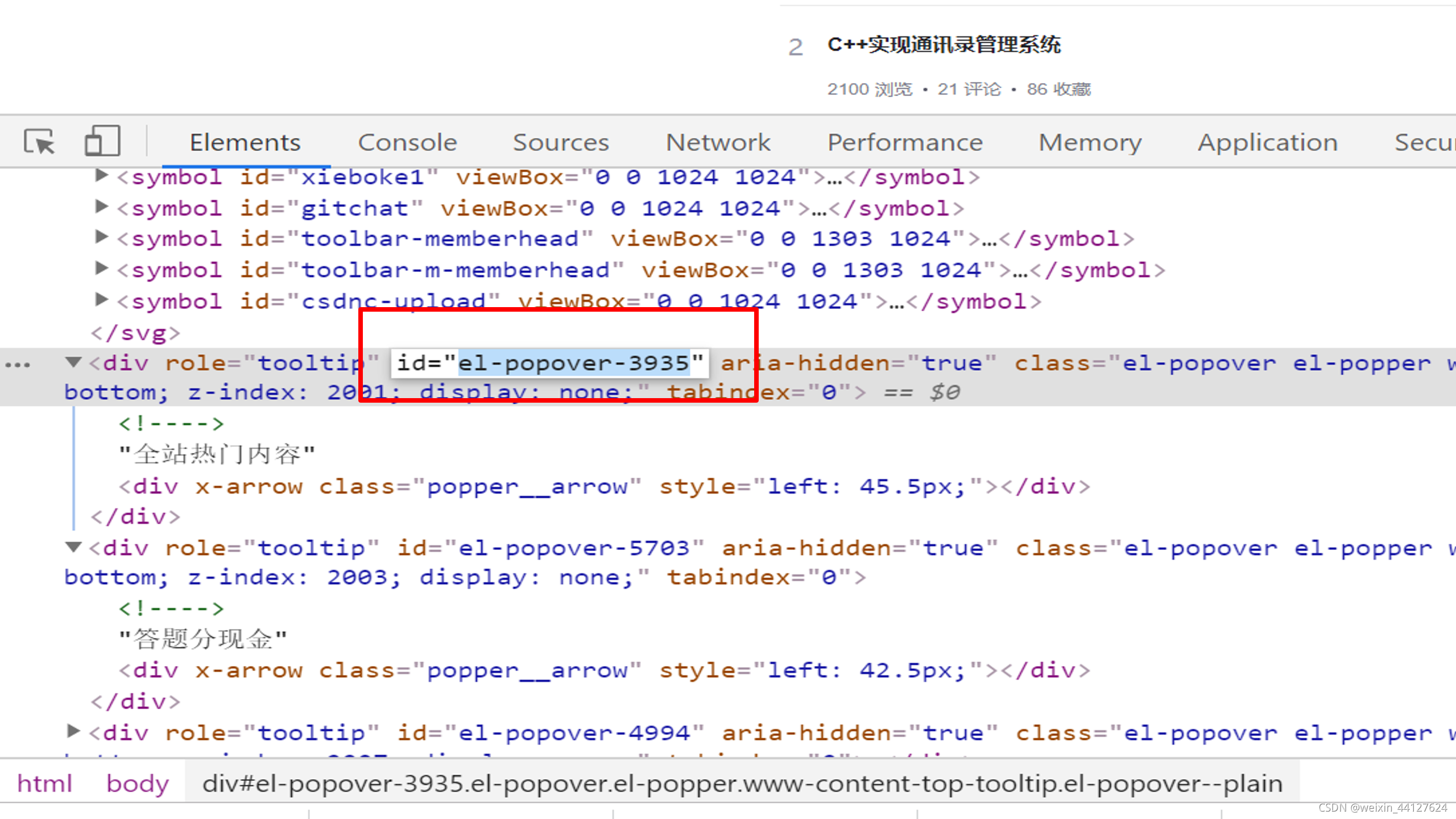
count =1
#获取数据
while count <=50:print('获取第{}页'.format(count))for i inrange(11): #一共有11行数据
迫使它进行循环的简陋方法,这个系统狗的就是登录了之后,不管在页面里面怎么点点点,网页的url就是不会改变,所以只能用点击下一页的方法进行循环。count设定的是页数,从第一页开始获取,获取完11行的数据之后count = count+1,进行第二页的获取,以此类推,直到50页,缺点就是需要手动设定循环的页数。
SHIF_list.insert(1,page_html.xpath('//*[@id="grdGrid"]/tbody/tr[{}]/td[1]/text()'.format(i+1)))
MAN_list.insert(1,page_html.xpath('//*[@id="grdGrid"]/tbody/tr[{}]/td[2]/text()'.format(i+1)))
WORK_list.insert(1,page_html.xpath('//*[@id="grdGrid"]/tbody/tr[{}]/td[3]/text()'.format(i+1)))
不愿再回想,当初就是卡在这里,要怎么把数据按照顺序爬取下来。方法就是把每一列的前3行数据的Xpath复制到txt进行对比,然后找到改变的地方,再循环填充进去。Xpath中 “ td[1],td[2],td[3] ” 表示标题所在的列数,是固定不变的,变的是不同行的数据,“ tr[{}] ” 就是用来接收这些改变的数据,i 循环的是行数,当 i = 1 时是第一行,也就是标题行,所以是从 i+1 也就是第二行开始把数据format到 “ tr[{}] ” 里面的,把它包在while里面,只要count没有停止,就会一直循环点击并爬取。
版权归原作者 都说没逃课了 所有, 如有侵权,请联系我们删除。