
JobMaster 部署 Task
核心入口:
JobMaster.onStart();
部署 Task 链条:JobMaster --> DefaultScheduler --> SchedulingStrategy --> ExecutionVertex --> Execution --> RPC请求 --> TaskExecutor
TaskExecutor 处理 JobMaster 的 submitTask RPC 请求
JobMaster 向 TaskExecutor 发送 submitTask() 的 RPC 请求,用来部署 StreamTask 运行。TaskExecutor 接收到 JobMaster 的部署 Task 运行的 RPC 请求的时候,就封装了一个 Task 抽象,然后通过一个线程来启动这个 Task。
Task 构造方法
在 Task 的构造方法中,也做了一些相应的初始化动作,大致总结一下;
- 封装得到一个 TaskInfo 对象
- 创建得到一个 上下文对象
- 初始化输出组件:ResultPartition + ResultSubPartition
- 初始化输入组件:InputGate + InputChannel
- 初始化一个线程对象,用来执行当前这个 Task
- TaskManagerServices 在 TaskExecutor 启动的时候,被创建好了,它内部创建了 ShuffleEnvironment,具体实现是 NettyShuffleEnvironment - NettyShuffleEnvironment 创建了 ConnectionManager,内部初始化和启动了 NettyClient 和 NettyServer- NettyShuffleEnvironment 内部创建了 ResultPartitionFactory 和 SingleInputGateFactory 用来创建输入输出组件- 当前 Task 初始化时会通过 NettyShuffleEnvironment 创建对应的输入输出组件 - 输入组件:InputGate 和 InputChannel,通过 SingleInputGateFactory 创建- 输出组件:ResultParition 和 ResultSubpartition,肯定是通过 ResultPartitionFactory 创建的
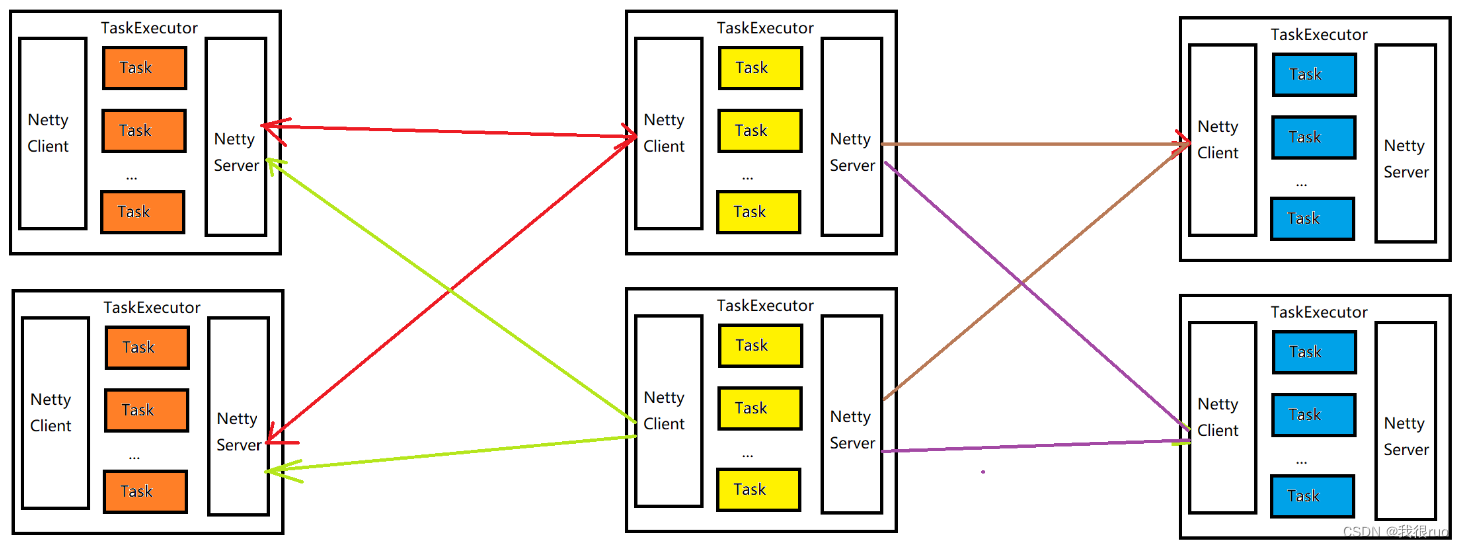
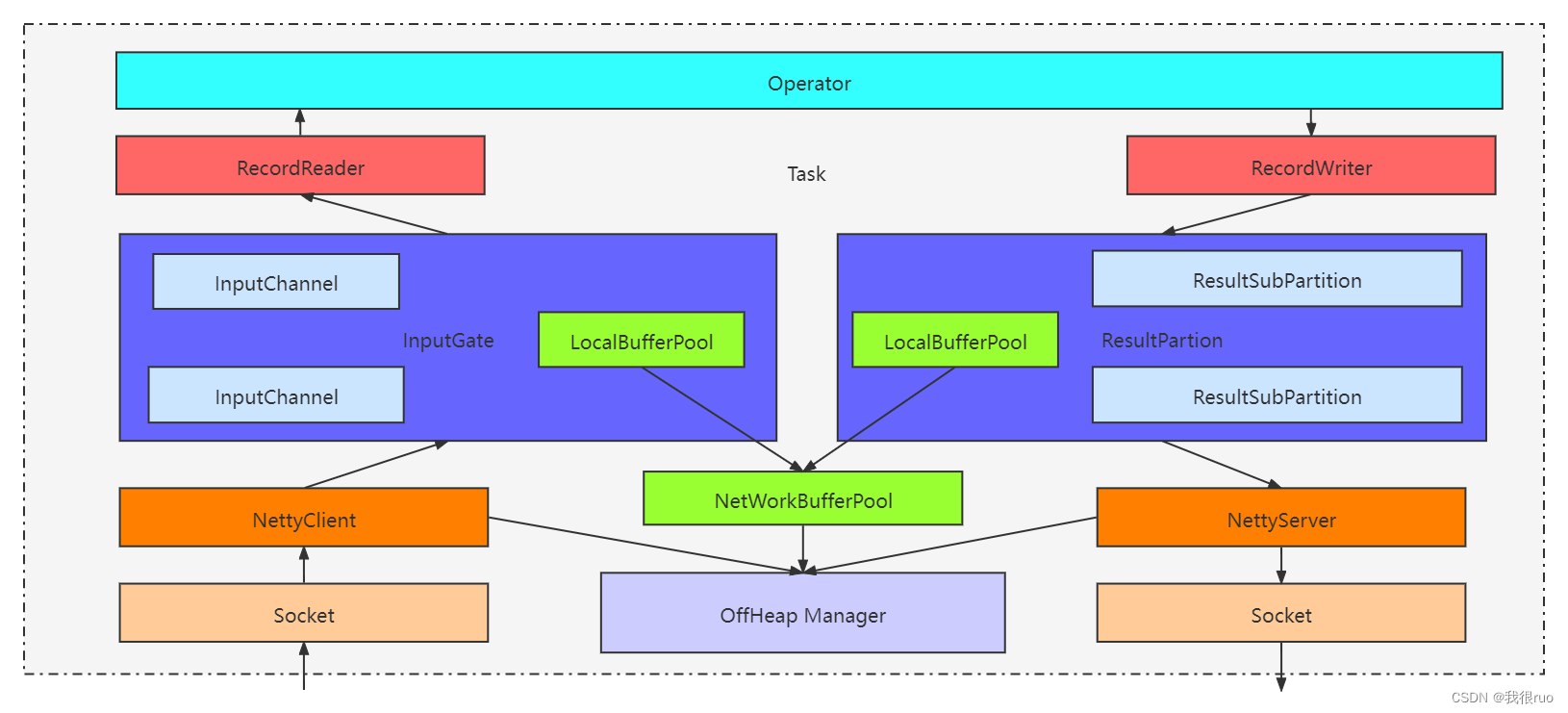
所有 channel 共用同一个 netty 客户端,通过 inputChannelId 区分消息是属于哪个 inputChannel。同理,所有 ResultSubPartition 共用同一个 netty 服务端,通过 channelIndex 区分消息是属于哪个 ResultSubPartition。
Task 执行(线程启动)
Task 的启动,是通过启动 Task 对象的内部 executingThread 来执行 Task 的,具体逻辑在 run 方法中。当 invokable.invoke(); 执行的时候,Task 就真正执行起来了。根据上述代码的执行可知:一个 Task 的状态周期:
CREATED ----> DEPLOYING ----> INITIALIZING ----> RUNNING ----> FINISHED
StreamTask 初始化
这个地方的初始化,指的就是 SourceStreamTask 和 OneInputStreamTask 的实例对象的构建。
Task 这个类,只是一个笼统意义上的 Task,就是一个通用 Task 的抽象,不管是批处理的,还是流式处理的,不管是源 Task, 还是逻辑处理 Task, 都被抽象成 Task 来进行调度执行。
SourceStreamTask 和 OneInputStreamTask 初始化
在 SourceStreamTask 的 processInput() 方法中,主要是启动接收数据的线程 LegacySourceFunctionThread。
StreamTask 执行
Flink 的 MailboxProcessor 详解
在 Flink-1.9 之前,StreamTask 中的多线程互斥通过一个 CheckpointLock 来解决。Flink 从 1.9 版本之后引入基于 Actor 模型的 Mailbox 设计理念来取代 StreamTask 中现有的多线程模型,变为了单线程(MailboxProcessor) + 阻塞队列(Mailbox) 的形式。
Flink StreamTask 对接数据源
SourceStreamTask 与 OneInputStreamTask/TwoInputStreamTask 的不同之处在于 mainOperator 中的 userFunction。
SourceStreamTask
SourceStreamTask 的 processInput() 内部 通过 LegacySourceFunctionThread 来对接数据源,不停的获取一条一条的数据,通过 output 组件交给后面。
OneInputStreamTask 和 TwoInputStreamTask
OneInputStreamTask 或者 TwoInputStreamTask 是通过 StreamInputProcessor 来获取输入数据,然后执行处理。
RecordWriter 的具体实现是什么呢:
- ChainingOutput:一个 OperatorChain 中的前一个 Operator 输出数据到下一个 Operator
- RecordWriterOutput: 负责当前这个 OperatorChain 最后的执行结果,输出到该 Task 的 ResultPartition 内部的某个 ResultSubPartition
Flink OneInputStreamTask 获取输入数据
关于 OneInputStreamTask 获取 Buffer 数据的时候,其实涉及到两部分的逻辑:
- getChannel() 阻塞在 inputChannelsWithData 上获取准备就绪的 InputChannel。
- 当前这个 StreamTask 如果接收到上游 StreamTask 发送过来的数据,则 CreditBasedPartitionRequestClientHandler 的 channelRead() 调用执行数据解析,然后将该数据对应的 InputChannel 加入到 inputChannelsWithData 队列中。
当 StreamTask 接收到某个 InputChannel 发送过来的数据的时候,就会把这个 InputChannel 和 Buffer 数据加入到 inputChannelsWithData 队列中,然后环境 pollNextBuffer 的执行逻辑,就能获取到 Buffer,执行接下来的 processElement 方法了。
Flink Task 的 InputChannel 数据处理就是典型的生产者消费者模式(wait + notifyAll)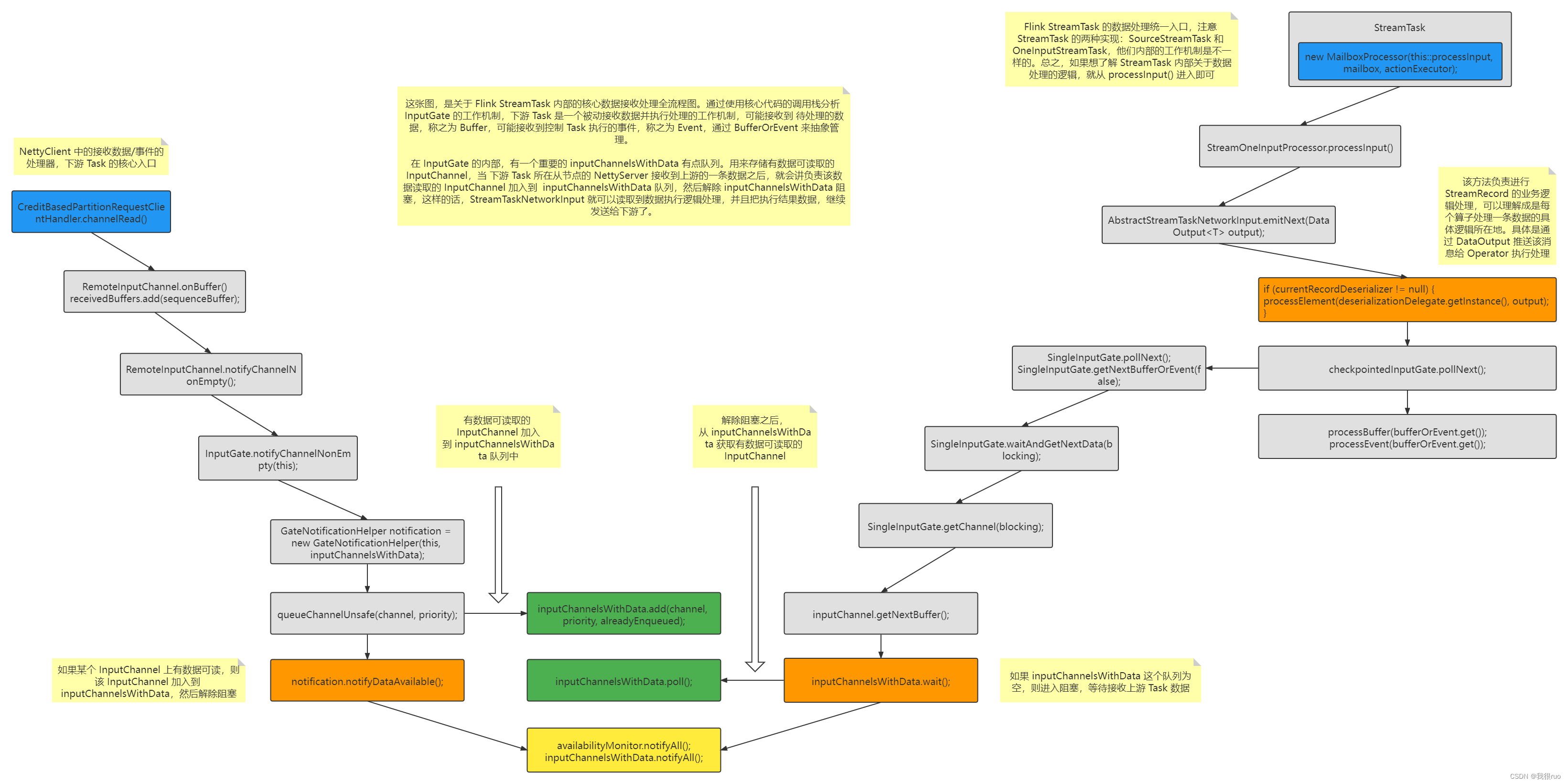
Flink StreamTask 执行 Record 逻辑处理
SourceStreamTask 和 OneInputStreamTask 在接收到数据执行处理之后,都通过一个 output 执行向下输出。
版权归原作者 我很ruo 所有, 如有侵权,请联系我们删除。