
堆排序与TOP-K问题
1. 堆排序的实现
1.1 堆排序的简单实现
堆排序的简单实现(要复用前面的堆的相关函数)
思路:新建一个堆,然后将要排序的数组的每一个元素push到堆中,因为堆顶的元素总是最大或者最小的元素,利用这个性质,每次都能够将当前堆中最小或者最大的元素得到,将其覆盖到原来的数组中,同时将当前堆中的首元素删除掉,依次进行,就能够得到从大到小的数组元素或者从小到大的数组元素。
升序:小堆(每次从堆顶取最小元素)
降序:大堆(每次从堆顶取最大元素)
时间复杂度:O(N*log2N)
void HeapSort(int* a, int size)//堆排序的模拟实现
{
HP hp;//建立一个堆
HeapInit(&hp);//堆的初始化
for (int i = 0; i < size; i++)//将数组的每个元素push到数组中
{
HeapPush(&hp, a[i]);
}
size_t j = 0;//记录数组下标
while (!HeapEmpty(&hp))
{
a[j++] = HeapTop(&hp);//取数组首元素覆盖到数组中
HeapPop(&hp);//将堆的首元素删除,同时使用向下调整的函数将最小或者最大的元素重新调整到了首元素
}
HeapDestory(&hp);//堆的销毁
}
int main()
{
int a[] = { 1,3,5,2,3,7,5,4 };//要进行排序的数组
int size = sizeof(a) / sizeof(int);//数组元素的数目
HeapSort(a, size);
for (int i = 0; i < size; i++)//打印排序后数组的元素
{
printf("%d ", a[i]);
}
return 0;
}
缺点:上面这种方法并不轻松,需要自己实现堆,同时还有O(N)的空间复杂度,所以实际中写堆排序不是这样写的。下面是对堆排序的优化,将空间复杂度优化到O(1)。
1.2 堆排序的优化实现
注意:堆排序的本质就是选择排序。
void HeapSort(int* a, int size)//堆排序的优化
{
//1.建立堆。建立堆有两种方式:一、使用向上调整,插入数据的思想建堆 二、使用向下调整建堆
//方法一:向上调整建堆(向上调整的算法的前提是前面的都是大堆或者都是小堆)
//思路:从第二层节点开始,对每一个节点进行向上调整,始终保持前面的所有节点是一个堆并满足堆的性质
/*for (int i = 1; i < size; i++)
{
AdjustUp(a, i);
}*/
//问:为什么从1开始呢?因为从0开始的时候进行调整并没有任何意义,此时并没有数据
//方法二:向下调整建堆(向下调整的算法的前提是左子树和右子树都是大堆或者都是小堆)
//思路:从倒数第一个非叶子节点开始,对每一个节点进行向下调整,向前进行遍历,始终保持后每一个节点的子树都是一个堆
for (int i = (size - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, size, i);
}
//最后一个节点下标是size-1,再进行-1然后÷2就是它的父亲
//问:为什么从不从最后开始呢?因为最后那一层都是叶子节点,调整没有意义
//2.排序
//问:升序为什么不可以建立小堆?
//答:因为最小的一个数已经在第一个位置了,剩下的数关系已经全部乱了,需要重新建堆,而建堆的时间复杂度最小也要O(N),此时整个函数的时间复杂度就变为O(N^2)了,不满足我们的要求,如果这样,还不如直接遍历选数呢,搞的这么复杂效率却没有提升
//结论:升序要建立大堆,降序要建立小堆
size_t end = size - 1;//记录当前堆最后一个元素的下标
while (end>0)
{
Swap(&a[0],&a[end]);
AdjustDown(a, end, 0);
--end;
}
//思路:将最开始的节点元素和最后一个节点元素进行交换,即a[end]和a[0]此时最后节点存储的元素变成了最大的数,然后将end--
//此时将前面的数进行向下调整,然后a[0]就会变为次大的数,然后将a[0]再与数组倒数第二个数进行交换,然后依次进行前面的操作
}
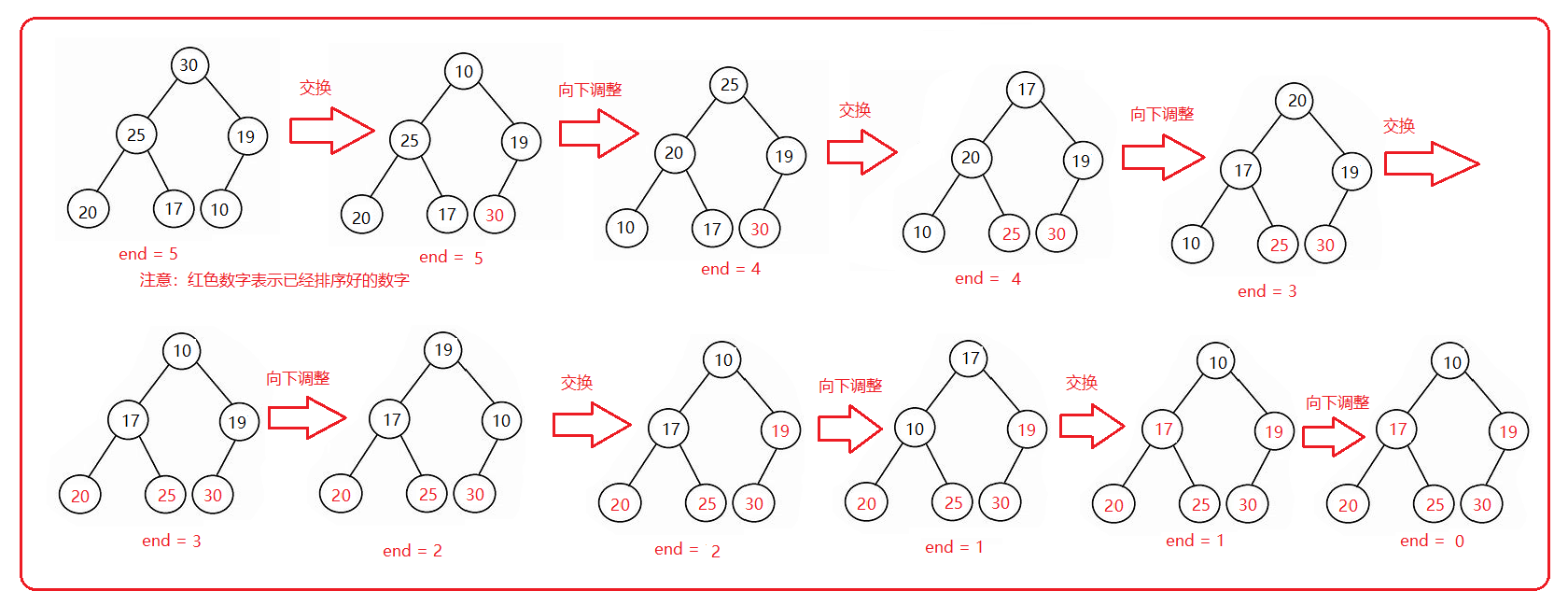
排序图示:
1.3 建堆的时间复杂度
如下图所示,假设总共是有N个节点,共有h层。(以完全二叉树为例)
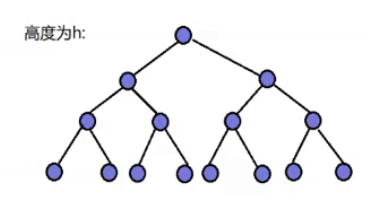
则有关系为log2N+1 = h即2h - 1 = N
1.3.1 向上调整建堆
for (int i = 1; i < size; i++)
{
AdjustUp(a, i);
}
注意:调整就是节点交换的次数,我们考虑最坏的情况,每次都要进行调整交换。
第1层有20个节点,每个节点需要调整0次,总共需要调整20*0次。(值为0,后面不予列出)
第2层有21个节点,每个节点需要调整1次,总共需要调整21*1次
第3层有22个节点,每个节点需要调整2次,总共需要调整22*2次
……
第h-1层有2h-2个节点,每个节点需要调整h-2次,总共需要调整2h-2*(h-2)
第h层有2h-1个节点,每个节点需要调整h-1次,总共需要调整2h-1*(h-1)
记节点交换的总的次数为T(等差数列乘以等比数列的前n项和,运用的解题方法就是错位相减法)
T(h) = 211 + 222 + 233 + ······ + 2h-2(h-2) + 2h-1*(h-1) (1)
2T(h) = 221 + 232 + ······ + 2h-2(h-3) + 2h-1*(h-2) + 2h*(h-1) (2)
(1) - (2)可得
-T(h) = 211 + 222 + 233 + ······ + 2h-2(h-2) + 2h-1*(h-1) - 2h*(h-1)
-T(h) = 201 + 222 + 233 + ······ + 2h-2(h-2) + 2h-1*(h-1) - 2h*(h-1) -1 (此处在最开始的地方加上了20*1,在最后的地方再减去1即可)
-T(h) = 2h - 1 - h*2h + 2h - 1
-T(h) = 2h*(2 - h) - 2
T(h) = 2h(h-2) + 2
T(N) = (N + 1)(log2(N+1) -2) + 2
所以向上调整建堆的时间复杂度:O(N*log2N)
1.3.2 向下调整堆
for (int i = (size - 1 - 1) / 2; i >= 0; --i)
{
AdjustDown(a, size, i);
}
第1层有20个节点,每个节点需要调整h - 1次,总共需要调整20*(h - 1)次。
第2层有21个节点,每个节点需要调整h - 2次,总共需要调整21*(h - 2)次
第3层有22个节点,每个节点需要调整h - 3次,总共需要调整22*(h - 3)次
……
第h-1层有2h-2个节点,每个节点需要调整1次,总共需要调整2h-2*1
第h层有2h-1个节点,每个节点需要调整0次,总共需要调整2h-1*0(值为0,不予列出)
T(h) = 20*(h - 1) + 21*(h - 2) + 22*(h - 3) + ······ + 2h-21 + 2h-10 (1)
2T(h) = 21(h - 1) + 22*(h - 2) + ······ + 2h-22 + 2h-11 + 2h*0 (2)
(2) - (1)可得
T(h) = 1 - h + 21 + 22 + 23 + ······ + 2h-2 + 2h-1
T(h) = 20 + 21 + 22 + 23 + ······ + 2h-2 + 2h-1 - h
T(h) = 2h - 1 - h
T(N) = N - log2(N+1) ≈ N
所以向下调整建堆的时间复杂度:O(N)
2.TOP-K问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能 数据都不能一下子全部加载到内存中)。
- 排序:时间复杂度:O(N&log2N),空间复杂度:O(1)。
- 建立N个数的大堆,pop K次,就可以选出最大的前K个,时间复杂度:O(N + K*log2N),空间复杂度:O(1)。
最佳的方式就是用堆来解决,基本思路如下:
- 用数据集合中前K个元素来建堆- 前k个最大的元素,则建小堆- 前k个最小的元素,则建大堆
- 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
时间复杂度:O(K + (N - K)*log2K)
函数实现:
void PrintTopK(int* a, int n, int k)
{
//1.建堆--用k中前k个元素建堆
int* kminHeap = (int*)malloc(sizeof(int)*k);
assert(kminHeap);
for (int i = 0; i < 10; i++)
{
kminHeap[i] = a[i];
}
//建小堆,这里是采用的
for (int j = (k - 1 - 1)/2; j >=0; --j)
{
AdjustDown(kminHeap, k, j);
}
//2.将剩余n-k个元素依次与堆顶元素进行交换,不满则替换
for (int i = k; i < n; i++)
{
if (a[i] > kminHeap[0])
{
kminHeap[0] = a[i];
AdjustDown(kminHeap, k, 0);
}
}
for(int j = 0;j < k;j++)
{
printf("%d ",kminHeap[i]);
}
}
运用举例:
void PrintTopK(int* a, int n, int k)
{
//1.建堆--用k中前k个元素建堆
int* kminHeap = (int*)malloc(sizeof(int)*k);
assert(kminHeap);
for (int i = 0; i < 10; i++)
{
kminHeap[i] = a[i];
}
//建小堆,这里是采用的
for (int j = (k - 1 - 1)/2; j >=0; --j)
{
AdjustDown(kminHeap, k, j);
}
//2.将剩余n-k个元素依次与堆顶元素进行交换,交换后同时进行向下调整
for (int i = k; i < n; i++)
{
if (a[i] > kminHeap[0])
{
kminHeap[0] = a[i];
AdjustDown(kminHeap, k, 0);
}
}
}
void TestTopk()
{
int n = 10000;
int* a = (int*)malloc(sizeof(int) * n);
assert(a);
srand(time(0));
for (size_t i = 0; i<n;i++)
{
a[i] = rand() % 10000;
}
a[5] = 10001;
a[1231] = 100002;
a[12] = 10003;
a[100] = 10004;
a[107] = 10005;
a[9] = 10006;
a[1087] = 10007;
a[1079] = 10008;
a[17] = 10009;
a[102] = 100010;
PrintTopK(a, 10000, 10);
}
最终kminHeap中存储的值为10001到10010。
版权归原作者 鹿九丸 所有, 如有侵权,请联系我们删除。