
MySQL调优

索引
为数据表添加索引( MySQL 无需进行全表扫描 ),是 MySQL 优化的常用方法之一。下面简单介绍索引:
索引(index) 是帮助 MySQL 高效获取数据的数据结构。本质上,和表一样,都是磁盘中的文件。那么,创建索引是会基于原有的表数据,重新在磁盘中创建新的本地索引文件,同时做好排序并与表数据产生映射关系。
索引优点:
- 提高数据检索效率,降低数据库 IO 成本
- 通过索引列对数据进行分组排序,降低数据分组排序成本,降低 CPU 消耗
- 连表查询时,基于主外键字段上建立索引,性能明显提升
- 从 MySQL 整体架构而言,减少了查询 SQL 的执行时间,提高了数据库整体吞吐量
索引缺点:
- 创建索引需要额外的磁盘空间
- 写入数据时(增、删、改),需要额外维护索引,导致额外的时间开销,执行写 SQL 时效率降低,性能下降
- 需要定期维护索引(重建),增加维护成本
- 不合理的索引设计会导致系统性能下降
注:索引并不是越多越好,合理建立索引才是最佳选择!!!
分类
1.按功能分类:
- 普通索引(Normal Index):可以有多个,最基本的索引,快速定位特定数据
- 主键索引(Primary Index):只能有一个,默认自动创建,针对于表中主键创建的索引
- 唯一索引(Unique Index):可以有多个,避免同一个表某字段的值重复
- 全文索引(Fulltext Index):可以有多个,查找文本中的关键词,而不是比较索引中的值
注:
1.主键索引是自动创建的
2.在创建唯一索引中,若选用字段的值存在相同值时,是无法创建的
2.按数量分类:
- 单列索引(Single-column index):可以有多个,在一个字段上创建的索引
- 组合索引(Concatenated index):可以有多个,在多个字段上创建的索引,使用组合索引时遵循最左前缀集合
3.按存储形式分类:
- 聚集索引(Clustered Index):必须且仅有一个,数据与索引一起存储,索引结构的叶子节点存放整行数据
- 非聚集索引(Nonclustered Index,也称辅助索引或二级索引):可以有多个,数据与索引分开存储,索引结构的叶子节点存放主键值
注:聚集索引选取规则
1.如果存在主键,主键索引就是聚集索引
2.如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
3.如果表没有主键,或没有合适的唯一索引,则 InnoDB 会自动生成一个 _rowid 作为隐藏的聚集索引
结构
MySQL 索引是在存储引擎层实现的,而不同的存储引擎有不同的结构。
- B+树索引(B+Tree):最常见且默认的索引类型,大部分引擎都支持 B+ 树索引。MySQL 索引数据结构对经典的 B+Tree 进行了优化。在原 B+Tree 的基础上,增加了一个指向相邻叶子节点的链表指针,而形成了带有顺序指针的 B+Tree,提高区间访问的性能。 BPlusTree动态可视化网站
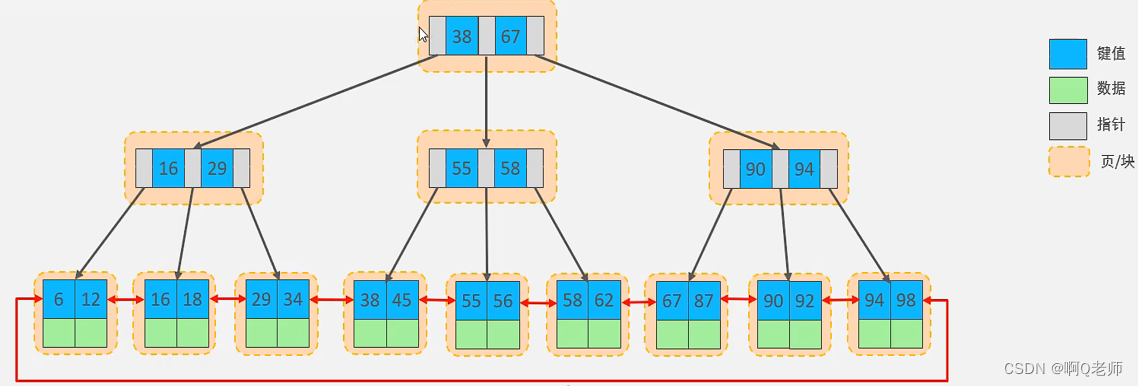 特点: 1.所有数据都存储在叶子结点,中间节点不存放数据 2.叶子结点形成单向链表 3.非叶子节点仅起到索引数据作用
特点: 1.所有数据都存储在叶子结点,中间节点不存放数据 2.叶子结点形成单向链表 3.非叶子节点仅起到索引数据作用 - 哈希索引(Hash):底层数据结构是用哈希表实现的,只有精确匹配索引字段的查询才有效,不支持范围查询。其采用一定的 hash 算法,将键值换算成新的 hash 值,映射到对应的槽位上,然后存储在 hash 表中。如果两个或多个键值,映射到一个相同的槽位上,便会产生 hash 冲突(也称 hash 碰撞),但可以通过链表来解决。MySQL 目前仅有 MEMORY 存储引擎和 HEAP 存储引擎支持这类索引。
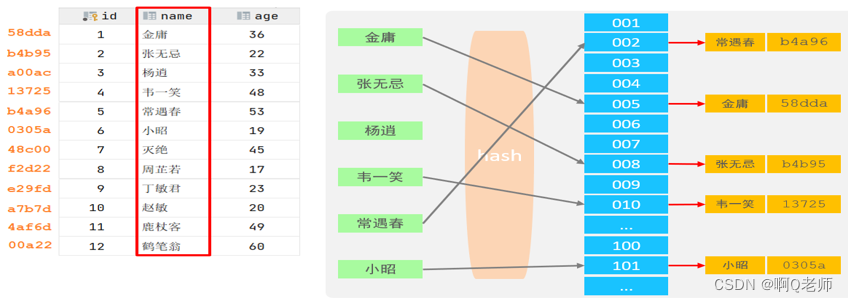 特点: 1.哈希索引只能用于对等比较( = 、in ),不支持范围查询( between 、> 、< ) 2.不能利用索引完成排序操作 3.查询效率高,通常只需一次检索即可,效率通常高于 B+Tree 索引
特点: 1.哈希索引只能用于对等比较( = 、in ),不支持范围查询( between 、> 、< ) 2.不能利用索引完成排序操作 3.查询效率高,通常只需一次检索即可,效率通常高于 B+Tree 索引
语法
下面简单介绍索引的基本语法:
#创建普通索引createindex idx_name on table_name(字段);#创建唯一索引(其字段是非空且唯一的)createuniqueindex idx_name on table_name(字段);#创建组合索引createindex idx_name1_name2_name3 on table_name(字段1,字段2,字段3...);#查看表的索引showindexfrom table_name;#删除某字段的索引dropindex idx_name on table_name;
SQL性能分析
1.SQL执行频率
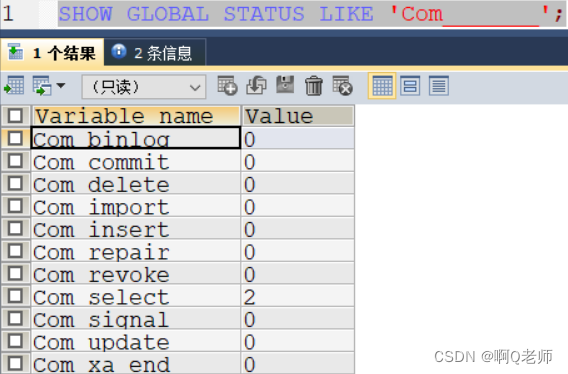
MySQL 客户端连接成功后,通过 show [session | global] status 命令显示服务器状态信息。
- 查看当前数据库 insert、update、delete、select 的访问频次— show global status like ‘Com_______’;
2.慢查询日志
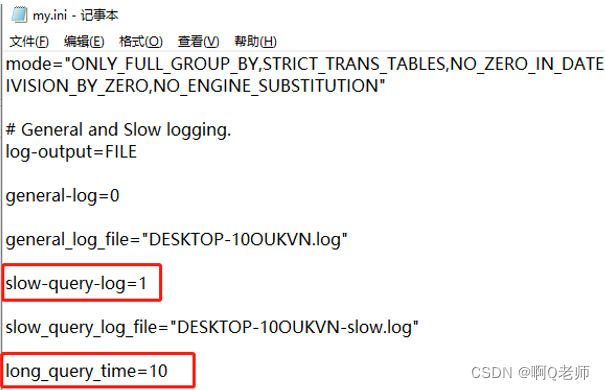
慢查询日志记录执行时间超过指定参数( long_query_time,单位:秒,默认10秒 )的所有 SQL 语句的日志。通过慢查询日志,定位执行效率较低的 SQL 语句,重点关注分析。
- 开启慢查询日志,需要在 MySQL 的配置文件( Linux:/etc/my.cnf、Windows:my.ini )
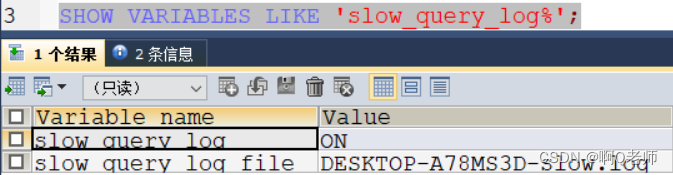
- 查看慢查询日志配置— show variables like ‘slow_query_log%’;
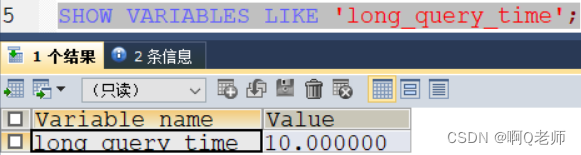
- 查看超过多长时间才记录到慢查询日志— show variables like ‘long_query_time’;
3.分析执行计划
explain 查看分析 SQL 的执行计划— explain + 需要分析的 SQL 语句(一般为查询语句);
explain 各字段解释:
- id:select 查询的序列号。表示查询中执行 select 子句或操作表的顺序(id相同,执行顺序从上到下;id不同,值越大先执行)
- select_type:select 的类型,常见的取值有 simple、primary、union、subquery
- type:查看索引执行情况的一个重要指标—连接类型。性能由高到低:system > const > eq_ref > ref > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
- possible_keys:显示可能应用在这张表上的索引,一个或多个
- key:实际用到的索引。一般配合 possible_keys 列一起查看
- key_len:索引中使用的字节数 。该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好
- rows:MySQL 估算要找到我们需要的记录而需要读取的行数。对于 InnoDB 表,此数字是一个估计值
- filtered:一个百分比的值,表示符合条件的记录数的百分比。即存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例,该值越大越好
- extra:有关 MySQL 如何解析查询的其他信息1. Using filesort:表示按文件排序,一般是在指定的排序和索引排序不一致的情况才会出现2. Using index:表示使用了覆盖索引,查询内容可以直接在索引中获取3. Using temporary: 表示使用了临时表,性能比较差,需要重点优化4. Using where: 表示使用了 where 条件过滤5. Using index condition:MySQL5.6 之后新增的索引下推。在存储引擎层进行数据过滤,而不是在服务层过滤,利用索引现有的数据减少回表的数据
4.分析执行耗时
explain 只能看到 SQL 的预估执行计划,若要了解 SQL 真正的执行线程状态及消耗的时间,需要使用 profiling 。
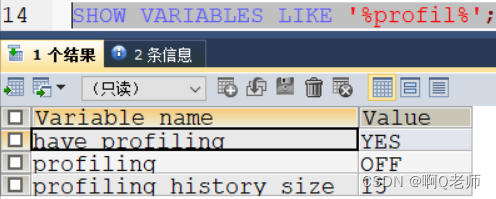
- 查看 profiling 是否开启— show variables like ‘%profil%’;
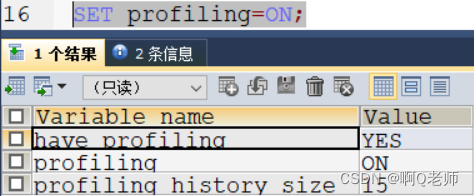
- 开启— set profiling=ON;
- 开启后运行 SQL 语句,使用 show profiles 查看一下
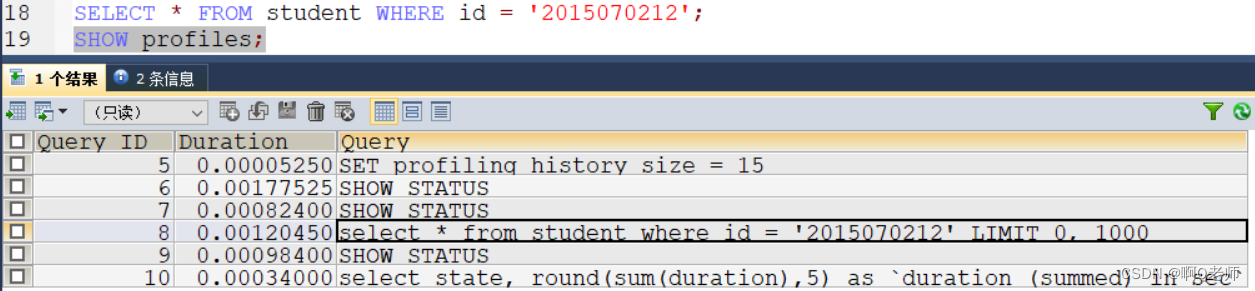
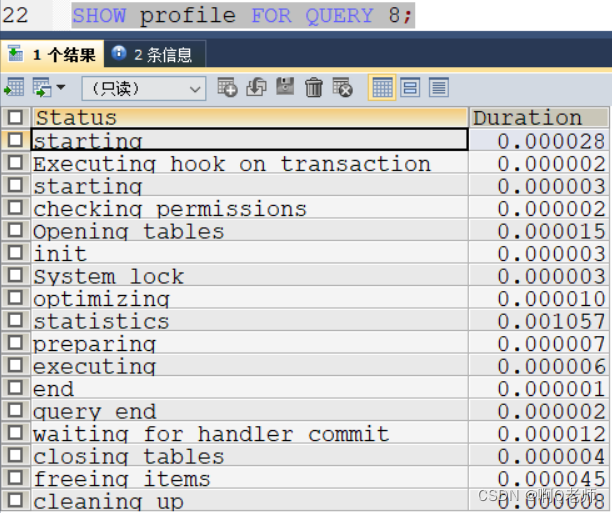
- 查看具体一条的 SQL 语句分析— show profile for query id; ( id为 show profiles 中的 QUERY_ID )
使用
1. 最左前缀法则
索引有多字段(组合索引)是要遵守最左前缀法则的。最左前缀法则指查询从索引的最左列依次开始。若跳跃某字段,后面的字段索引将失效。
如:创建组合索引 create index idx_a_b_c on table_name(a,b,c); 中,相当于创建了(a)、(a,b)、(a,b,c)三个索引。若要索引生效的话,只有 (a)、(a,b)/ (a,c)、(a,b,c)三种组合,而(a,c)只有a生效。
2. 查询索引列
MySQL 在查询带有索引字段比使用 * 或查询没有索引字段的查询效率高。
简单示例:
查看表的索引
使用 * 查询,全表扫描得到 SQL 执行结果
查询索引字段,使用了覆盖索引,直接在索引中得到 SQL 执行结果
3. 覆盖索引
覆盖索引指查询使用了索引,并且需要返回的字段可以直接在索引中获取。尽量使用覆盖索引,目的是减少回表操作。
4. 范围查询
组合索引中,若带有范围查询( > 、< 、!= 、not in ),范围查询右侧的字段索引失效。
简单示例:
查看表的索引
带有范围查询 != ,type 为 ALL ,索引失效
修改后,type 为 ref
5. 索引字段运算
在索引字段上,进行运算操作会导致索引失效。
简单示例:
查看表的索引
使用运算操作查询,type 为 ALL,索引失效
6. 模糊查询
查询数据时,以通配符( % 、_ )为开头的 like 语句会导致索引失效。
简单示例:
通配符 % 为开头,type 为 ALL,索引失效
修改后,type 为 range
7. 隐式类型转换
在使用字符串类型字段中,不加引号会导致数据库存在隐式类型转换,索引失效。
简单示例:
查看表的结构,字段的类型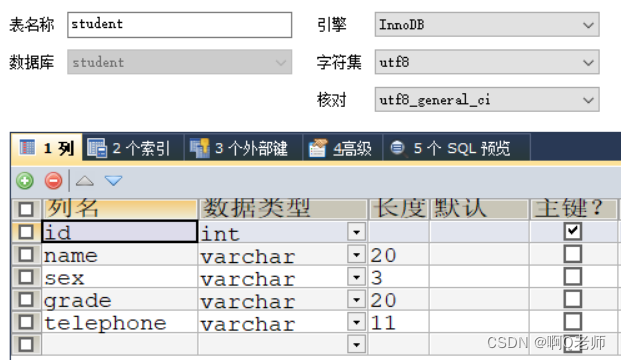
使用字符串字段而不加引号,type 为 ALL,索引失效
修改后,type 为 ref
8. or连接条件
在使用 or 条件中,若存在没有索引的字段会导致 MySQL 不会使用索引。
简单示例:
查看表的索引
使用没有索引的 name 字段,MySQL 没有使用索引
使用都有索引的字段后
9. 索引使用原则
- 数据量较大且查询频繁的表建立索引
- 常常作为查询条件(where)、排序(order by)、分组(group by)操作的字段建立索引
- 尽量选择区分度高的字段作为索引、建立唯一索引和组合索引
- 若字符串类型的字段的长度较长时,可以针对于字段的特点,建立前缀索引
- 合理建立索引,控制好索引的数量
- 若索引字段不能存储NULL值,在创建表时使用 NOT NULL 约束它
注意事项
- 若字段经常需要增删改操作,不合适建立索引。
- 若字段存在大量的重复值时,不适合建立索引 。
- 若字段经常使用函数查询的,不适合建立索引。
- 一张表的索引数量一般控制在3个,最多不能超过5个。
- 建立组合索引一定要考虑优先级,查询频率最高的字段应当放在首位。
- 当表的数据较少时,不应当建立索引
- 当索引的字段值无序时,不推荐建立索引
其他调优
简单介绍完索引后,接下来介绍一下其他调优。
数据插入优化
当一次性插入少量数据时,方案如下:
insertinto student(`id`,`name`,`sex`,`grade`,`telephone`)values('2015070224','赵子龙','男','24计本班','19564872301'),('2015070225','马超','男','24计本班','19568975301'),('2015070226','吕布','男','24计本班','19564872023');
注:
主键顺序插入比乱序插入性能高
当一次性插入大量数据时,方案如下:
#在 Windows 环境下loaddatalocalinfile'D:\\ProgramData\\student.txt'intotable t_user fieldsterminatedby','linesterminatedby'\n';#在 Linux 环境下loaddatalocalinfile'/home/ubuntu/Code/student.txt'intotable t_user fieldsterminatedby','linesterminatedby'\n';
注:
student.txt文件需要严谨规范
不同环境下的路径格式不同
order by 优化
order by 语句用于排序。MySQL 排序方式有 filesort 和 index 两种,对应 Extra 值为:Using filesort 和 Using index 。
简单示例:
查看索引
在 grade 字段没有建立索引时,使用 order by 语句,查看分析 SQL 的执行计划,type 为 ALL ,Extra 为 Using filesort
为 grade 字段建立索引,再次查看分析 SQL 的执行计划,type 为 index ,Extra 为 Using index
另外,创建组合索引时,需要遵循最左前缀原则以及对应字段的升序或降序
注:
若不可避免的出现 filesort 排序方式,且数据量较大时,可以适当增大排序缓冲区大小 sort_buffer_size(默认256k)
group by 优化
group by 语句用于分组,一般与聚合函数一起使用,如:count()、sum()、avg()、max()、min() 等函数。
下面简单了解 group by 与 where / having 的使用。
#grade字段为班级,score字段为成绩,num为count(*)的别名--统计的人数#求各班总人数SELECT grade,COUNT(*)AS num FROM student GROUPBY grade;#求各班成绩大于等于80的总人数SELECT grade,COUNT(*)AS num FROM student WHERE score>='80'GROUPBY grade;#求成绩大于等于80的总人数超过3人的班级SELECT grade,COUNT(*)AS num FROM student WHERE score>='80'GROUPBY grade HAVING num>='3';
注:
where用于分组前的筛选,having用于分组后的筛选
where不用使用聚合函数,having可以使用聚合函数
接下来简单了解索引对于分组操作的影响。
简单示例:
查看索引
在 grade 字段没有建立索引时,使用 group by 语句,查看分析 SQL 的执行计划,type 为 ALL ,Extra 为 Using temproary
为 grade 字段建立索引,再次查看分析 SQL 的执行计划,type 为 index ,Extra 为 Using index
同样,分组操作可以通过建立索引来提高效率,创建组合索引也需要遵循最左前缀原则。
limit 优化
limit 语句用于分页查询。但进行limit分页查询,数据量比较大且越往后,分页查询效率越低。
简单示例:
#查看第100001开始的十条记录,效率较低SELECT*FROM student LIMIT100000,10;
优化:
#1.若主键是顺序的,可以通过条件筛选来指定从某条记录往下扫描SELECT*FROM student WHERE id>100000LIMIT10;#2.通过把条件转移到主键索引树来减少回表SELECT*FROM student s1 INNERJOIN(SELECT id FROM student LIMIT100000,10) s2 ON s1.id = s2.id;
count 优化
count() 是一个聚合函数,用于统计行数。按效率高低排序:count(*)≈count(1)>count(主键)>count(字段)。另外,在数据量很大的情况下,可以考虑新建 MySQL 表存储计数,用事务的原子性和隔离性解决。
update 优化
Update 语句用于更新记录。在 InnoDB 存储引擎下,行锁是通过索引上的索引项来实现;若在无索引或索引失效下会从行锁升级为表锁。
简单示例:
查看索引
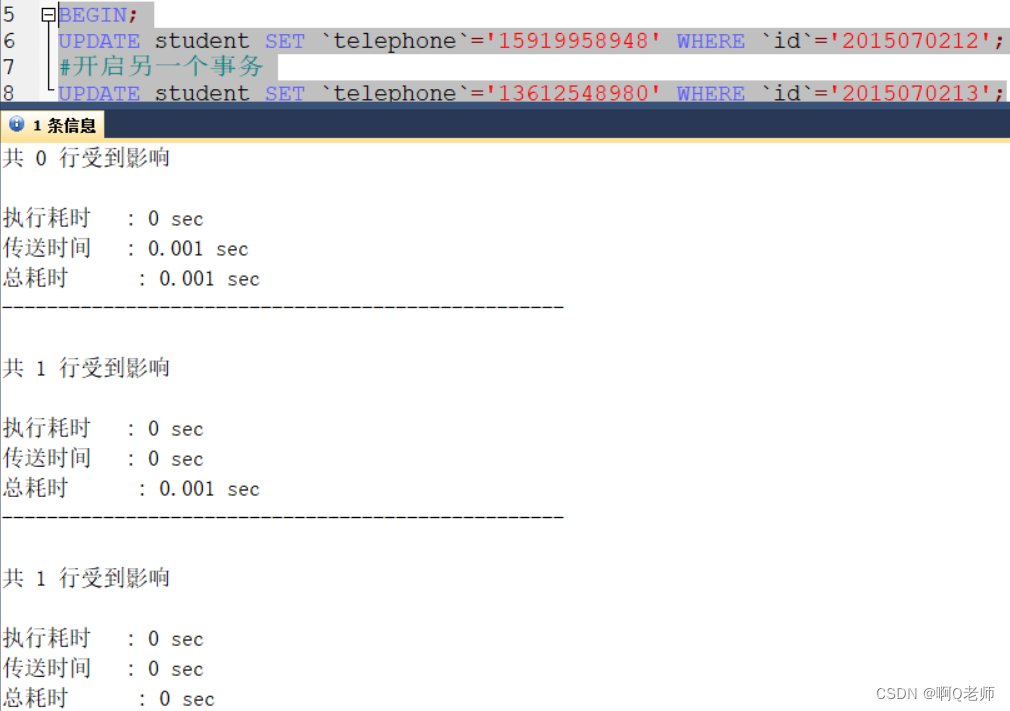
基于条件为主键或索引的更新,是增加了行锁,两个事务不影响,都可以提交
BEGIN;#开启一个事务UPDATE student SET`telephone`='15919958948'WHERE`id`='2015070212';#开启另一个事务UPDATE student SET`telephone`='13612548980'WHERE`id`='2015070213';
基于条件为非索引的更新,是增加了表锁,两个事务互相影响,第二个事务会被阻塞
BEGIN;#开启一个事务UPDATE student SET`telephone`='15919959999'WHERE`telephone`='15919958888';#开启另一个事务UPDATE student SET`telephone`='13612514888'WHERE`telephone`='13612548888';
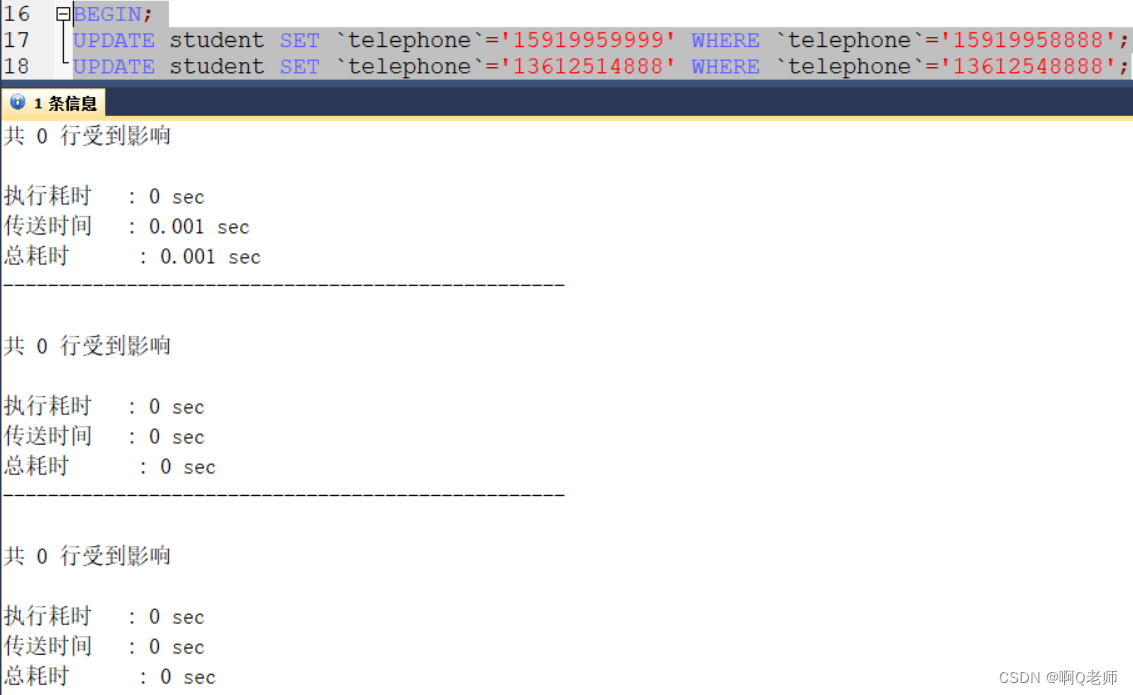
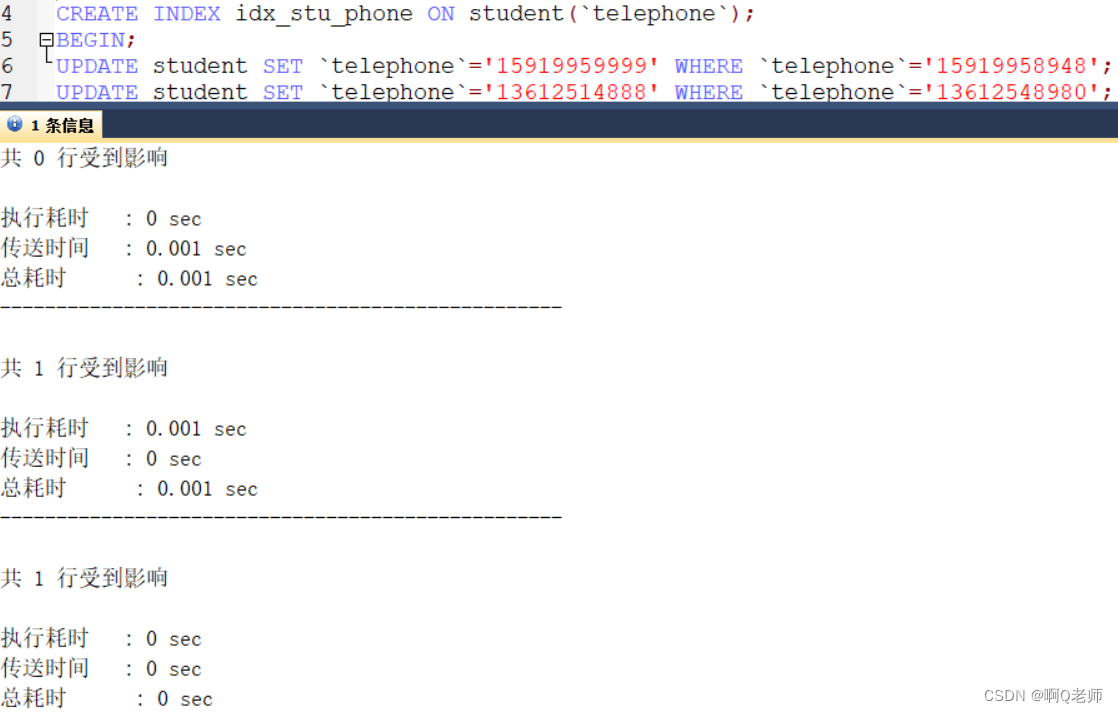
解决:为该字段建立索引
CREATEINDEX idx_stu_phone ON student(`telephone`);
存储过程
存储过程(Stored Procedure),指事先经过编译并存储在数据库中的一段为了完成特定功能的SQL语句集。通过调用存储过程来减少应用开发人员的工作量,提高数据处理的效率。
基本语法
下面简单介绍存储过程的创建、调用和删改查
#创建CREATEPROCEDURE 存储过程名称([参数列表])BEGIN
存储过程体
END;##参数列表由参数模式、参数名、参数类型三部分组成。其中参数模式又分为IN、OUT、INOUT三种#IN:作为输入,即该类参数调用时需要传入值#OUT:作为输出,即该类参数可以作为返回值#INOUT:既可以作为输入参数,也可以作为输出参数#调用CALL 存储过程名称([参数列表]);#删除DROPPROCEDURE 存储过程名称;#修改ALTERPROCEDURE 存储过程名称 存储过程特性;#查看某个存储过程的定义SHOWCREATEPROCEDURE 存储过程名称;#查询指定数据库的存储过程及状态信息SELECT*FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_SCHEMA ='XXX';
变量
下面简单介绍变量的声明和赋值
#局部变量声明DECLARE 变量名 变量类型 DEFAULT 默认值;#赋值SET 变量名=值;SET 变量名:=值;SELECT 字段名 INTO 变量名 FROM 表名 WHERE 条件;
控制语句
1.if 语句
#条件语句IF 条件1THEN
语句1;ELSEIF 条件2THEN
语句2;...ELSE
语句n;ENDIF;
2.case 语句
#条件选择语句
格式一:
CASE 表达式或字段
WHEN'值1'THEN
语句1;WHEN'值2'THEN
语句2;...ELSE
语句n;ENDCASE;
3.while 语句
#有条件的循环控制语句#满足条件则执行循环体中的SQL语句;反之则不执行[标签:]WHILE 条件 DO
循环体
ENDWHILE[标签];
4.repeat 语句
#有条件的循环控制语句#先执行一次循环体中的SQL语句,然后判断UNTIL条件是否满足。如果满足UNTIL声明的条件的时退出循环;反之则继续下一次循环[标签:]REPEAT
循环体
UNTIL 条件
ENDREPEAT[标签];
5.loop 语句
#循环语句,一直重复执行,需要在循环体中添加退出循环的条件才会退出。一般与 LEAVE 或 ITERATE 配合使用#LEAVE:配合循环使用,退出循环#ITERATE:必须用在循环中,作用为跳过当前循环剩下的语句,直接进入下一次循环[标签:]LOOP
循环体
ENDLOOP[标签];
游标
游标(CURSOR) ,指用来存储查询结果集的数据类型 , 在存储过程和函数中可以使用游标对结果集进行循环的处理。其语法如下:
#声明游标DECLARE 游标名称 CURSORFOR 查询语句;#打开游标OPEN 游标名称;#获取游标记录FETCH 游标名称 INTO 变量1,变量2...;#关闭游标CLOSE 游标名称;
版权归原作者 啊Q老师 所有, 如有侵权,请联系我们删除。