
StreamSets简介
Streamsets是一款大数据实时采集和ETL工具,可以实现不写一行代码完成数据的采集和流转。通过拖拽式的可视化界面,实现数据管道(Pipelines)的设计和定时任务调度。最大的特点有:
可视化界面操作,不写代码完成数据的采集和流转
内置监控,可是实时查看数据流传输的基本信息和数据的质量
强大的整合力,对现有常用组件全力支持,包括50种数据源、44种数据操作、46种目的地。
对于Streamsets来说,最重要的概念就是数据源(Origins)、操作(Processors)、目的地(Destinations)、触发执行器(Executor)。创建一个Pipelines管道配置也基本是前三个组件,Executor很少使用。
常见的Origins有Kafka、HTTP、UDP、JDBC、HDFS等;Processors可以实现对每个字段的过滤、更改、编码、聚合等操作;Destinations跟Origins差不多,可以写入Kafka、Flume、JDBC、HDFS、Redis等。
组件详细信息可以查看官方文档:
https://docs.streamsets.com/portal/datacollector/3.14.x/help/index.html
安装部署
Streamsets最新的版本已经更新到5.x,但是由于已经不在开源,目前最新的免费版本官方只能下载3.22.3版本并且移除了历史版本下载的功能。由于3.15.x及其之后的版本,安装之后均需要进行Streamsets的注册认证激活(只需激活一次,激活完成永久免费使用),但是跳转激活的网址在好像在2022年初已经被墙了,无法进行激活数据传输,所以目前使用的是3.14.0版本(注:该版本是all版本,压缩后大小5.4G左右,不要使用core版本,因为已经闭源所以现在添加组件异常困难)。
知道兄弟们资源不好找,在此分享完整版安装包
链接:https://pan.baidu.com/s/1SLyHVPTbV5PLuqBx_k2mmQ
提取码:g4d7
安装部署比较简单,按照如下步骤
1,上传压缩包到服务器并解压
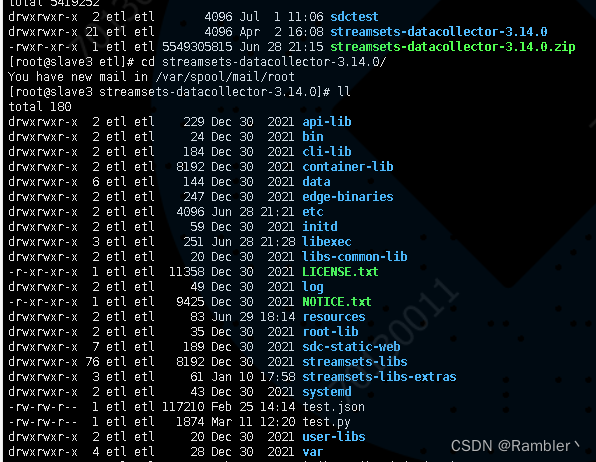
文件目录介绍:
bin目录:是Streamset DC运行脚本目录
etc目录:是Streamset DC默认的配置文件目录,包括系统配置、权限配置、邮件配置、日志配置等;
data目录:是Streamset DC默认的数据目录,用于存储你设计的数据流等;
log目录:是Streamset DC默认的日志目录,包括GC日志和系统日志;
libexec目录:是Streamset DC默认的运行时环境配置目录
treamsets-libs目录:是Streamset DC默认的系统自带组件的目录
user-libs目录:是Streamset DC放置用户自定义开发组件的目录
edge-binaries目录:是Streamset DC存放Streamsets DC Edge的各种类型的安装包
2,配置文件修改
必须修改:修改libexec文件夹下面的sdc-env.sh文件,注释掉以下几行,不然会使用文件中写死的环境导致启动报错

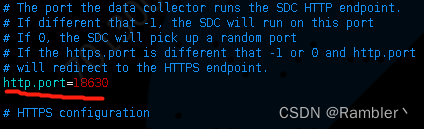
如果想要修改web端口号修改etc文件夹下面的sdc.properties文件
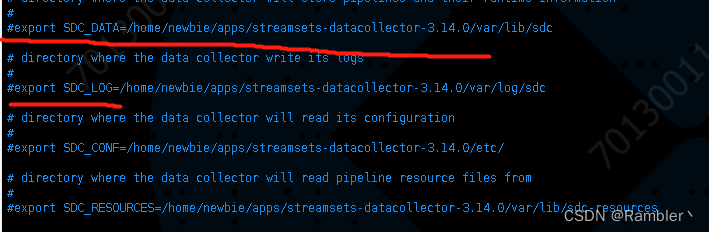
如果不想使用默认的data目录和log目录,修改sdc-env.sh文件
启动服务
streamsets-datacollector/bin路径下面
后台启动:nohup ./streamsets dc &
StreamSet工作平台介绍
1,首页(首次进入)
默认账号密码是admin/admin
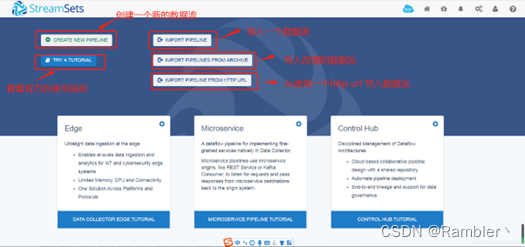
2,数据流创建界面
点击 CREATE NEW PIPELINE可以新建一个数据流

3,数据流设计界面
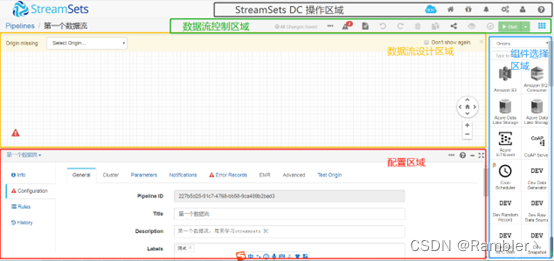
数据流设计界面,根据不同的功能可以分为5大区域:
数据流设计区域:该区域是数据流设计区域,通过拖拽组件选择区域的组件与连接操作设计数据流。
配置区域:该区域在设计阶段:主要配置整个数据流、配置每个组件、设置一个运行时数据规则;在预览阶段:查看对比各个组件的输入输出;在运行阶段,监控整个数据流、各个组件的运行状态、处理效率、出错率等;在快照阶段,可以查看数据流在某一时刻的快照信息。
组件选择区域:该区域放置了很多已经开发好的组件,包括origin类、processor类、destination类等组件,供数据流设计使用。
数据流控制区域:该区域主要用来控制设计好的数据流,比如:启动、校验、预览、分享、复制、删除、停止、导入、导出、数据快照、查看日志等等。
StreamSets DC操作区域:该区域主要是操作Streamsets DC,比如:安装组件、系统启停、消息通知、系统监控、系统日志、权限控制、系统的一些配置(部分)、系统提供的RESTful接口使用等等。
4,数据流管理界面(主界面)

mysql增量到hive实战
1,创建数据流
创建数据流
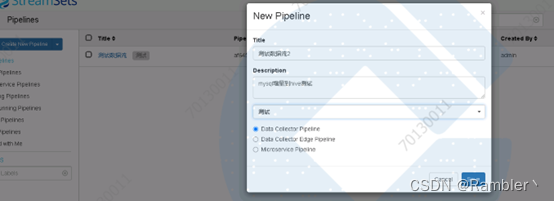
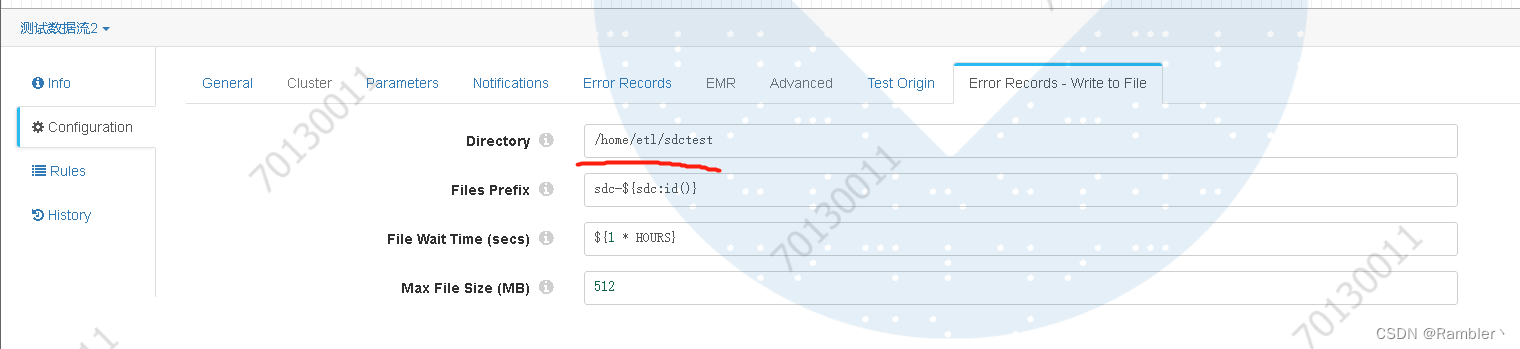
配置错误日志输出路径,我设置的是/home/etl/sdctest

2,添加JDBC query(Origins)
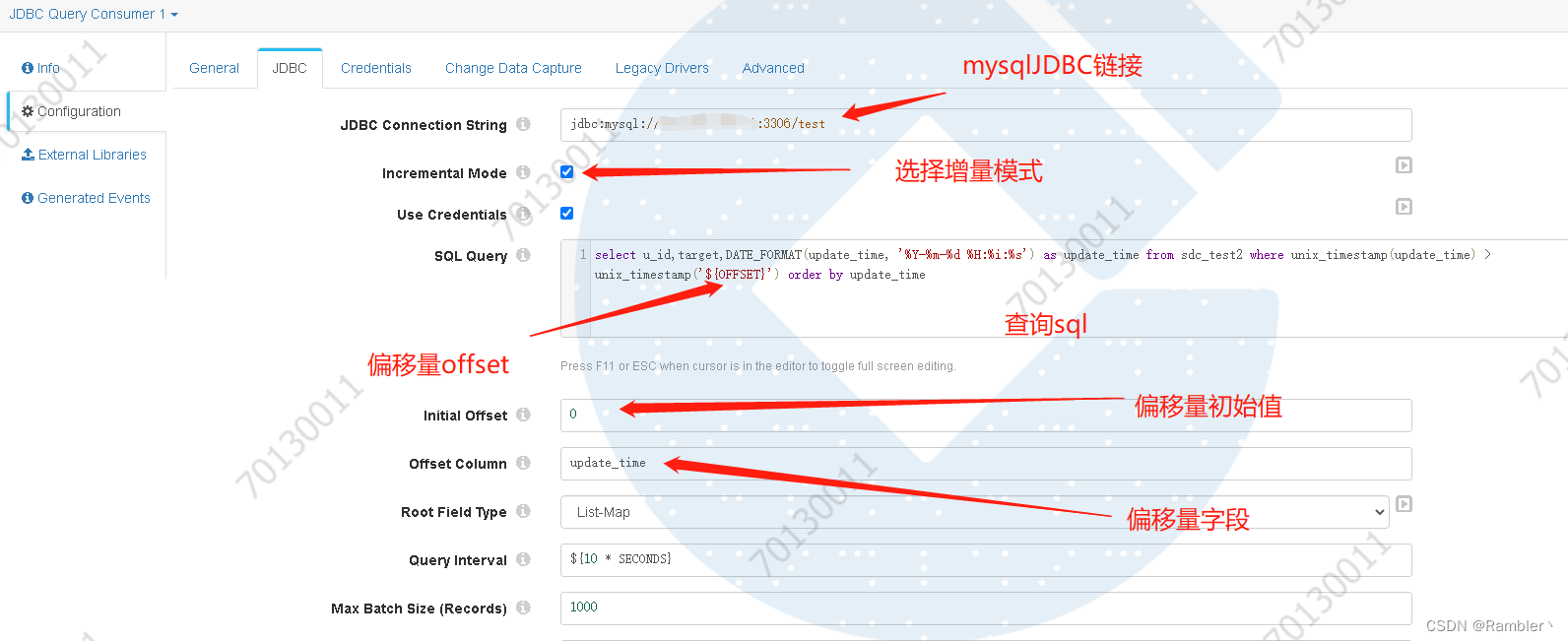
添加驱动
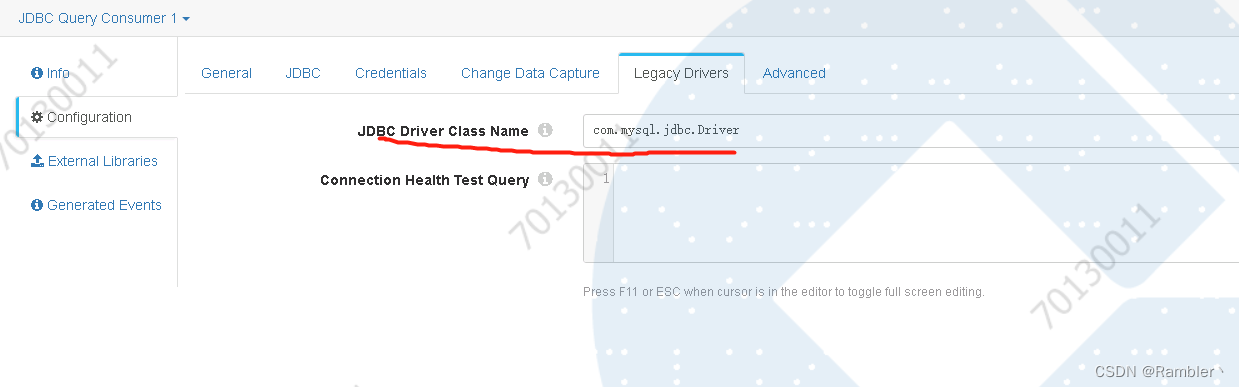
Mysql连接用户

3,执行预览检查
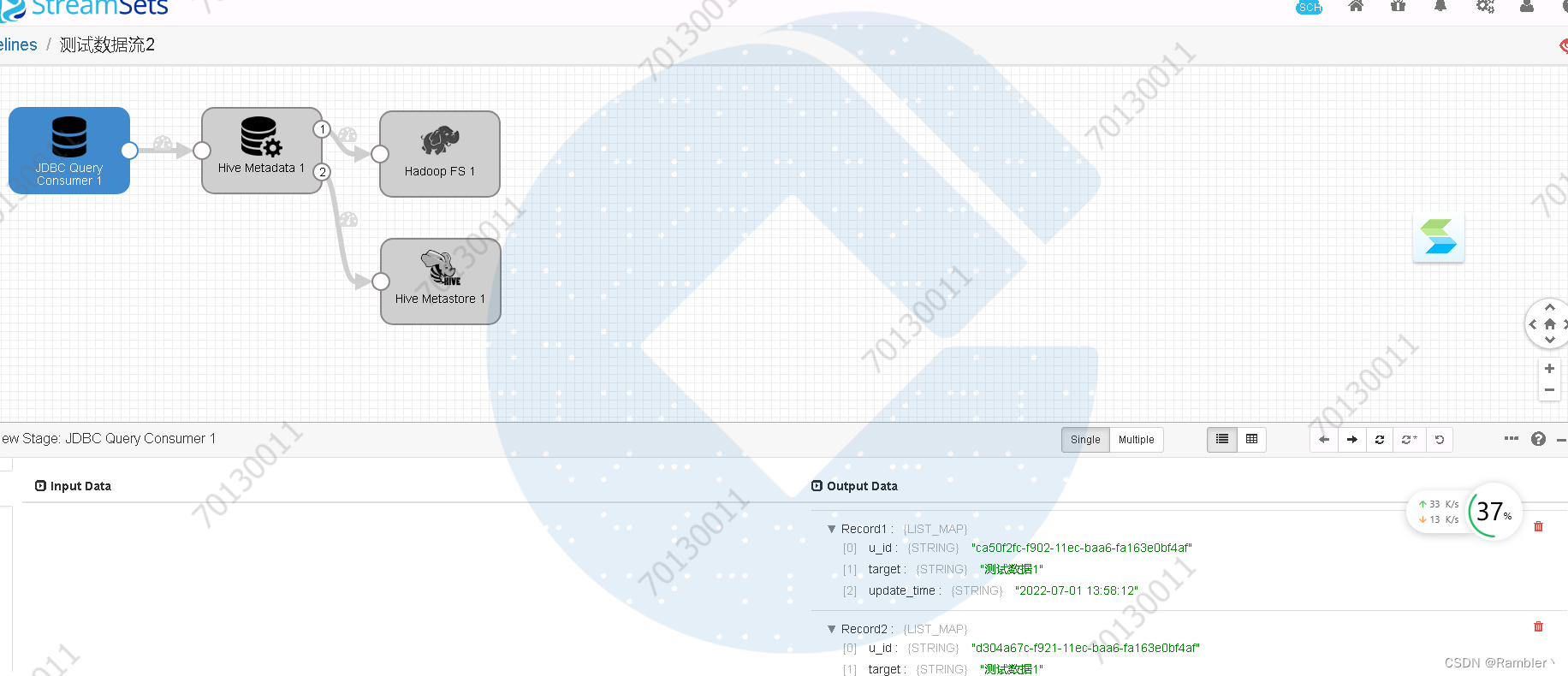
可以看到,mysql表里面的数据
4,添加hive metadata
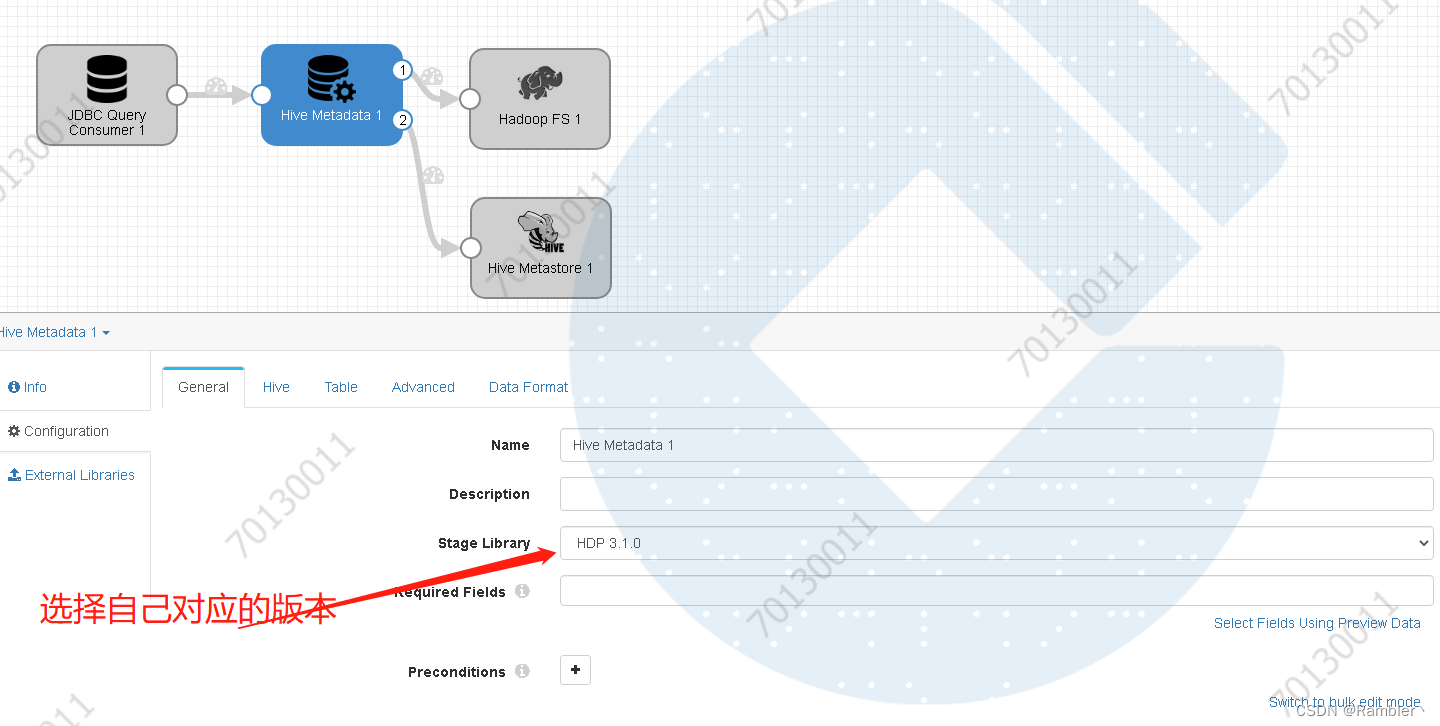
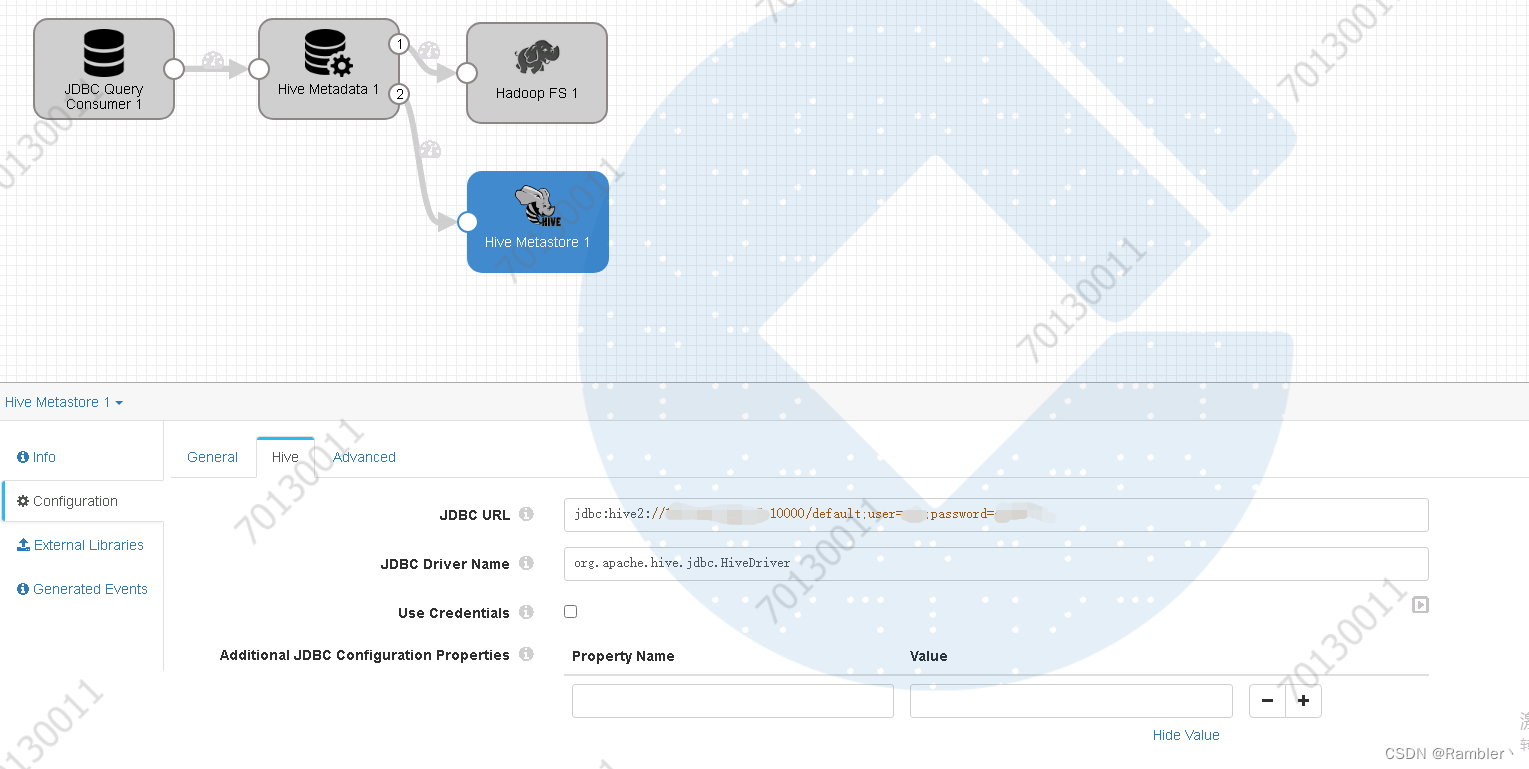
添加hive的jdbc链接
注:如果hive开启了用户认证,一定要在后面加上用户信息。如:jdbc:hive2://xxx.xxx.xxx.xx:10000/default;user=xxx;password=xxx
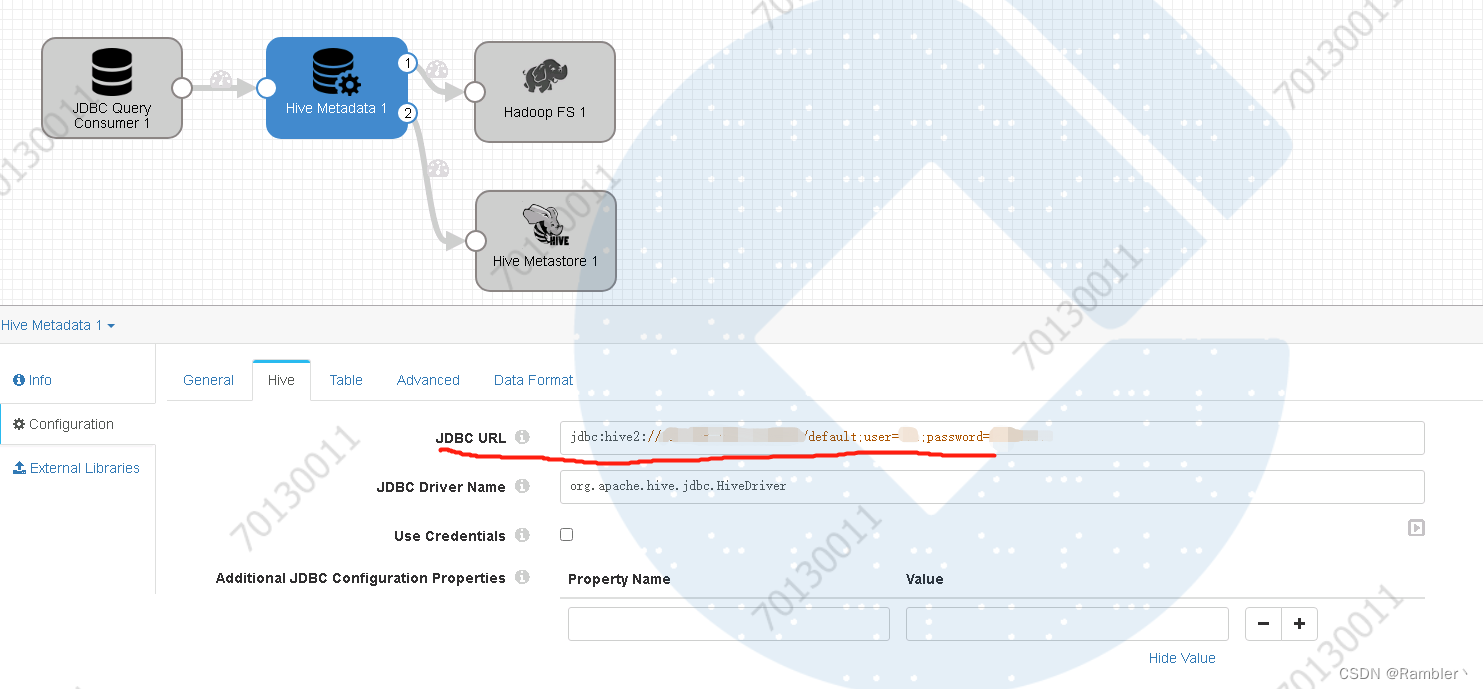
配置hive库和表名,注:hive表提前创建,不然会报错

在这重点说一下分区设置:首先,分区字段和mysql中的字段不能存在名称一样的,不然会报错;
如果查询mysql是三个字段a,b,c;我想使用c映射为分区字段,那么需要在Partition Value Expression选项中设置为${record:value('/c')},而且c字段也会存储在hive的普通字段中,那怕hive创建的表不包含字段c,也会自动创建c字段;上图所示我是使用的日期作为分区,这一块需要注意设置时区问题,避免日期不一致;
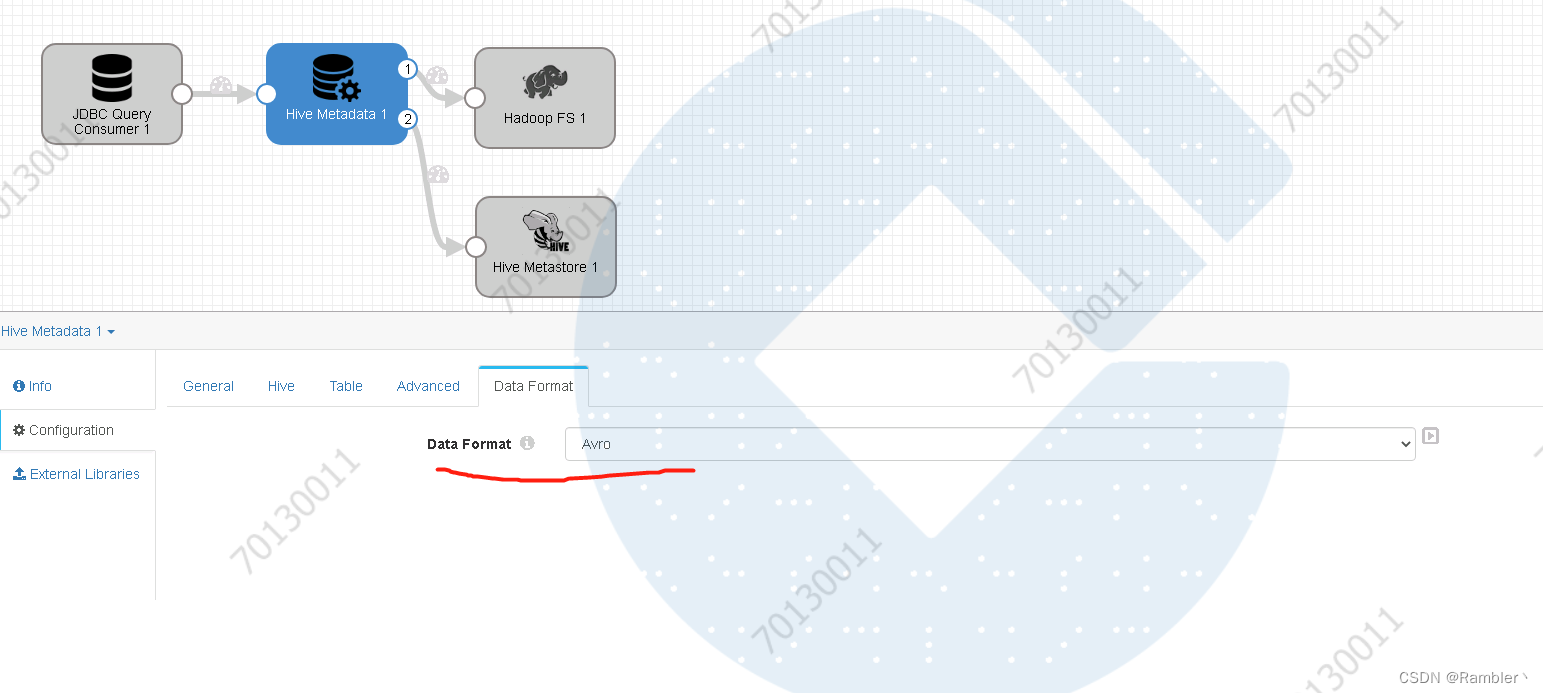
设置数据格式为avro,注:创建的hive数据存储格式也必须得是avro不然报错
注意,如下图,该配置是三个文件的存放位置,分别是core-site.xml,hdfs-site.xml,hive-site.xml,需要拷贝文件到streamsets所在服务器对应的文件夹,不然会报错
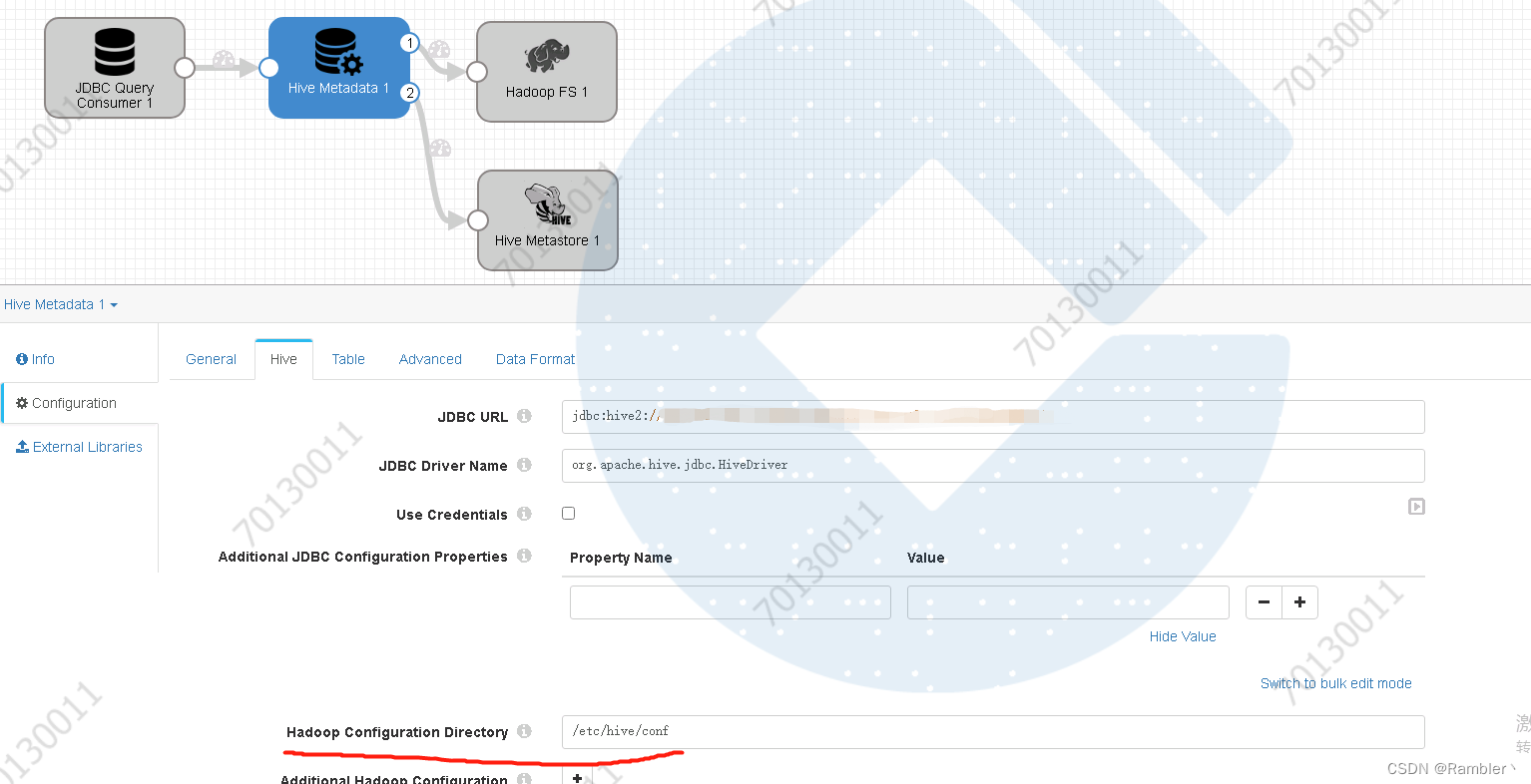
5,添加hadoop FS 1
将hive Metadata的data输出到HDFS上
选择版本
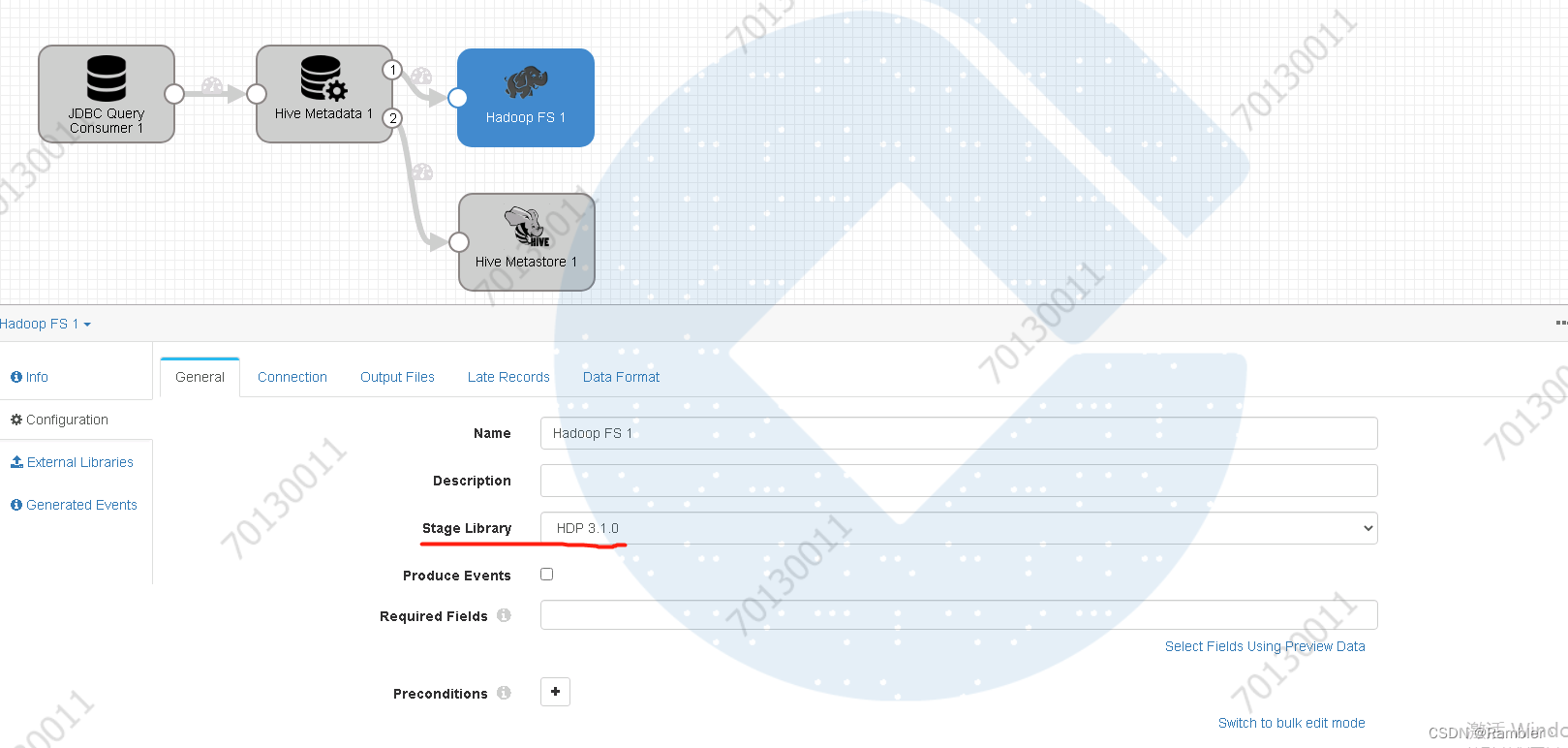
添加文件系统地址

输入配置更改
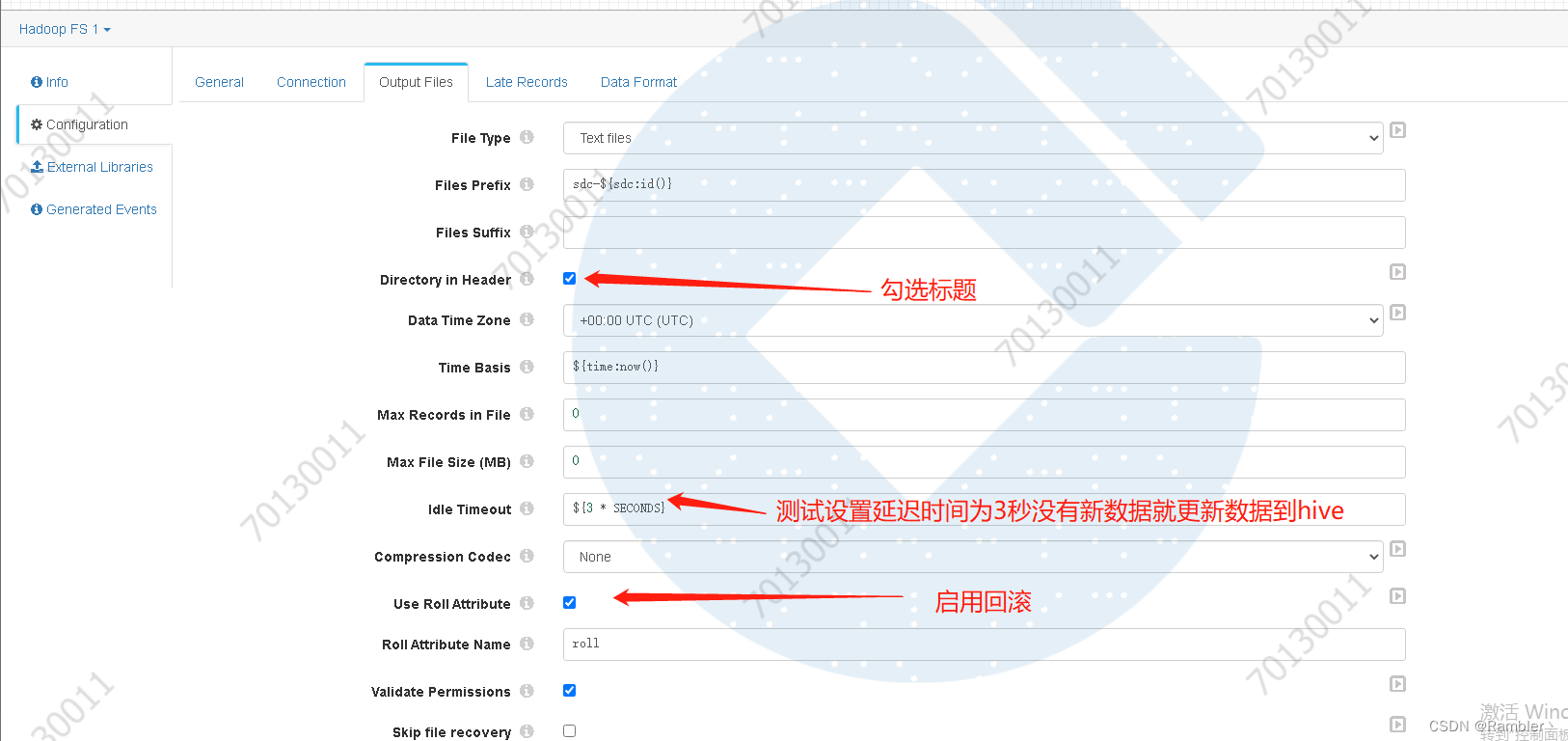
修改存储格式

6,添加hive Metastore 1
将hive的元数据输出到hive Metastore上
选择版本
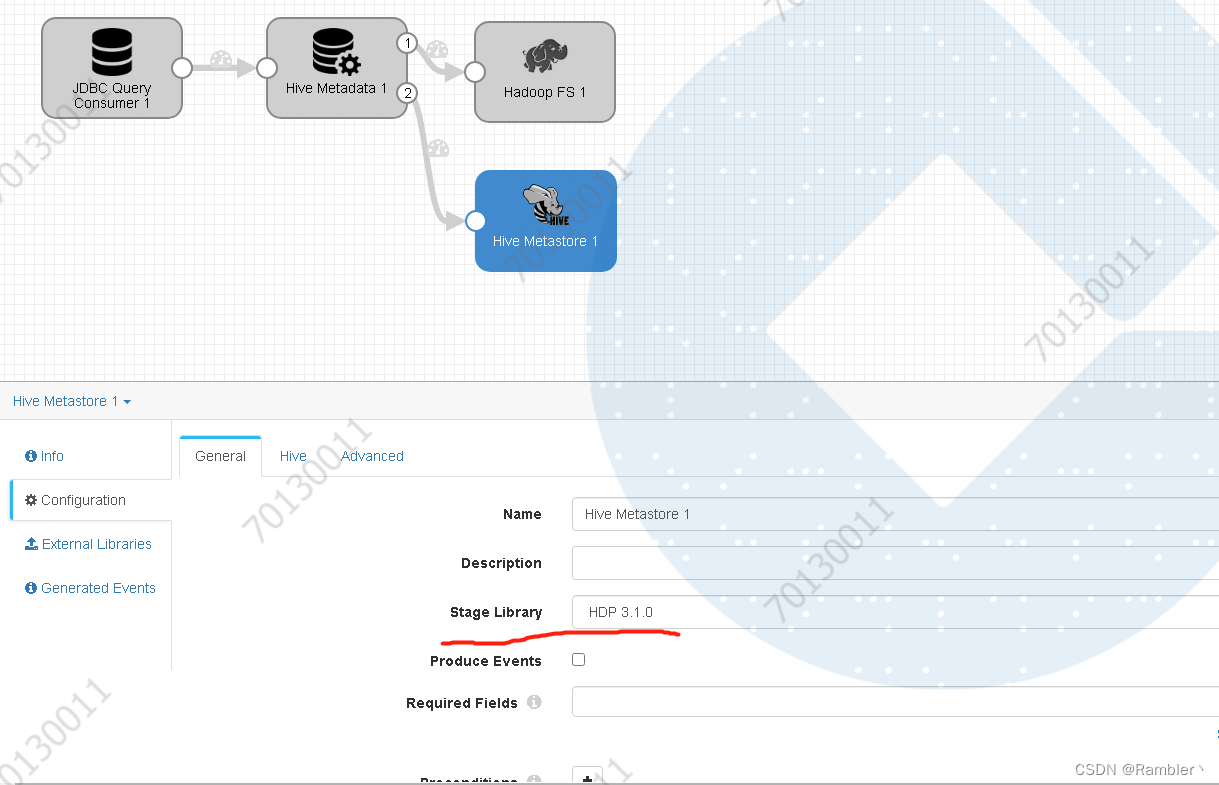
添加hive链接
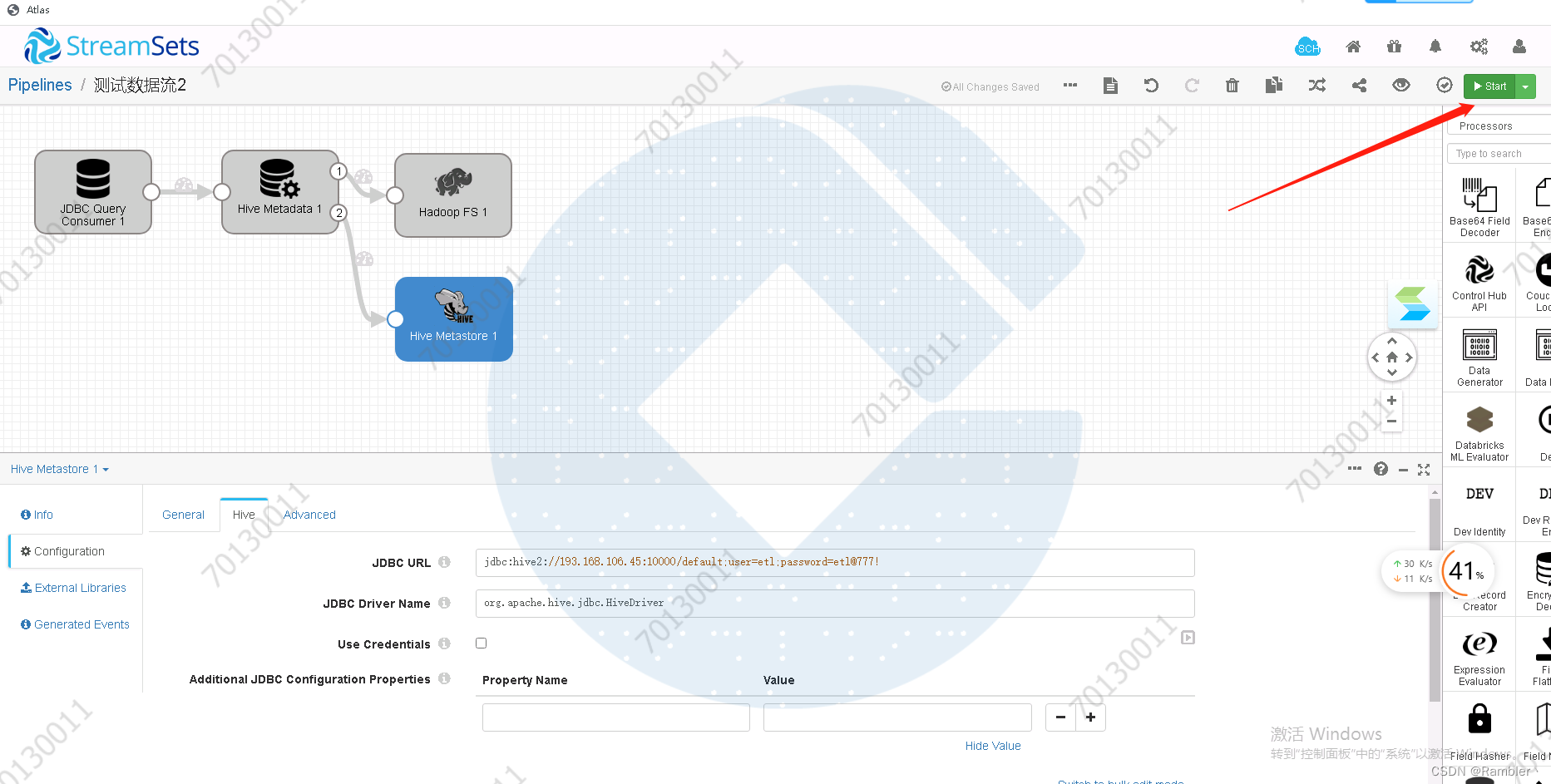
7,执行任务
启动任务流
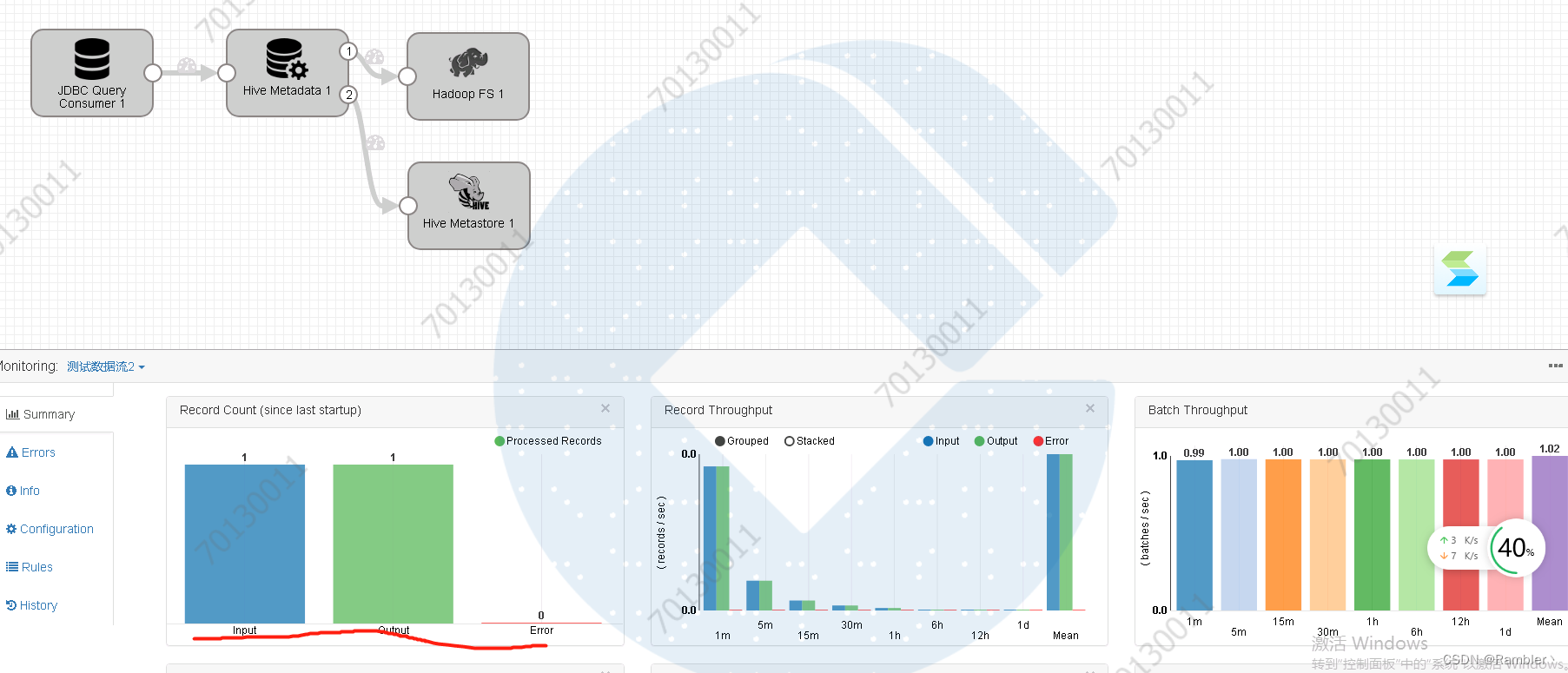
在mysql中新增一条数据

看到输入输出
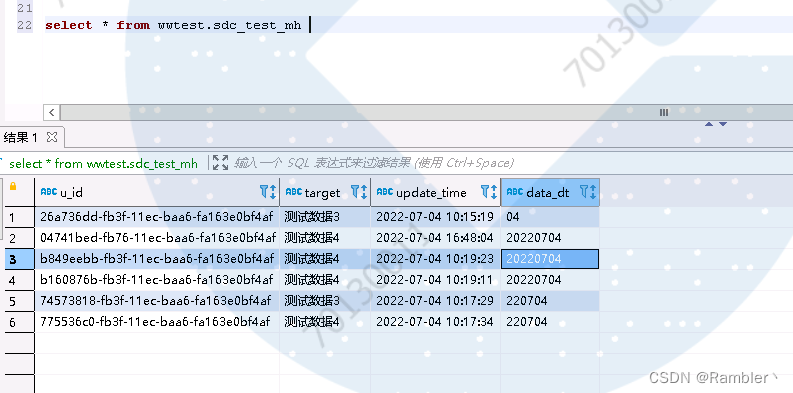
查看hive中出现了数据
引用参考:
【SDC】StreamSets实战之路-4-环境篇- StreamSet工作平台介绍_菜鸟蜀黍的博客-CSDN博客_streamset 专栏
【SDC】StreamSets实战之路-21-实战篇- 如何使用StreamSets从MySQL增量更新数据到Hive_菜鸟蜀黍的博客-CSDN博客_streamsets
版权归原作者 旺旺大数据 所有, 如有侵权,请联系我们删除。