
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
在本文中,我将训练一个模型来使用机器学习预测天气。我们将表现得好像我们无法访问天气预报一样。我们可以获得一个世纪的全球温度历史平均值,包括全球最高温度、全球最低温度以及全球陆地和海洋温度。综上所述,我们知道这是一个监督回归机器学习问题。
用于预测天气的天气数据集
首先,我们需要一些数据,我用来通过机器学习预测天气的数据是从世界上最负盛名的研究型大学之一创建的,我们将假设数据集中的数据是真实的。您可以从此处轻松下载此数据。
现在,让我们开始阅读数据集:
import pandas as pd
global_temp = pd.read_csv("GlobalTemperatures.csv")
print(global_temp.shape)
print(global_temp.columns)
print(global_temp.info())
print(global_temp.isnull().sum())
数据准备
不幸的是,我们还没有达到可以将原始数据输入模型并让它发回响应的地步。我们将需要进行一些小的编辑,以将我们的数据放入机器学习模型中。
数据准备的具体步骤将取决于所使用的模型和收集的数据,但需要进行一定数量的数据处理。首先,我将创建一个名为 wrangle () 的函数,我将在其中调用我们的数据框:
#Data Preparation
def wrangle(df):
df = df.copy()
df = df.drop(columns=["LandAverageTemperatureUncertainty", "LandMaxTemperatureUncertainty",
"LandMinTemperatureUncertainty", "LandAndOceanAverageTemperatureUncertainty"], axis=1)
我们想复制数据帧以免损坏原始数据。之后,我们将删除具有高基数的列。
高基数是指值非常稀有或唯一的列。鉴于大多数时间序列数据集中出现高基数数据的频率,我们将通过从数据集中完全删除这些高基数列来直接解决这个问题,以免将来混淆我们的模型。
现在,我将创建一个函数来转换温度,并将列转换为 DateTime 对象:
def converttemp(x):
x = (x * 1.8) + 32
return float(x)
df["LandAverageTemperature"] = df["LandAverageTemperature"].apply(converttemp)
df["LandMaxTemperature"] = df["LandMaxTemperature"].apply(converttemp)
df["LandMinTemperature"] = df["LandMinTemperature"].apply(converttemp)
df["LandAndOceanAverageTemperature"] = df["LandAndOceanAverageTemperature"].apply(converttemp)
df["dt"] = pd.to_datetime(df["dt"])
df["Month"] = df["dt"].dt.month
df["Year"] = df["dt"].dt.year
df = df.drop("dt", axis=1)
df = df.drop("Month", axis=1)
df = df[df.Year >= 1850]
df = df.set_index(["Year"])
df = df.dropna()
return df
global_temp = wrangle(global_temp)
print(global_temp.head())
在将我们的 wrangle 函数调用到我们的 global_temp 数据帧之后,我们现在可以看到我们的 global_temp 数据帧的一个新的清理版本,没有缺失值。
可视化
现在,在继续训练模型以使用机器学习预测天气之前,让我们可视化这些数据以找到数据之间的相关性:
import seaborn as sns
import matplotlib.pyplot as plt
corrMatrix = global_temp.corr()
sns.heatmap(corrMatrix, annot=True)
plt.show()
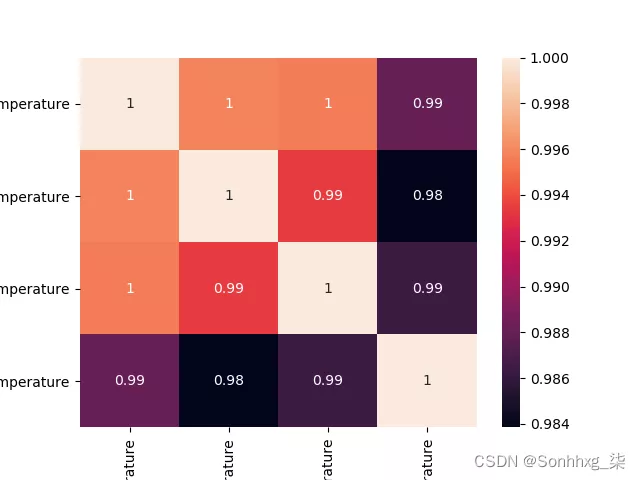
正如我们所看到的,并且你们中的一些人可能已经猜到了,我们选择继续前进的专栏彼此高度相关。
分离我们的目标以预测天气
现在我们需要将数据分成特征和目标。目标,也称为 Y,是我们要预测的值,在这种情况下,实际的平均陆地和海洋温度和特征是模型用于进行预测的所有列:
target = "LandAndOceanAverageTemperature"
y = global_temp[target]
x = global_temp[["LandAverageTemperature", "LandMaxTemperature", "LandMinTemperature"]]
训练测试拆分
现在,要创建一个使用机器学习预测天气的模型,我们需要使用 scikit-learn 提供的 train_test_split 方法来拆分数据:
from sklearn.model_selection import train_test_split
xtrain, xval, ytrain, yval = train_test_split(x, y, test_size=0.25, random_state=42)
print(xtrain.shape)
print(xval.shape)
print(ytrain.shape)
print(yval.shape)
(1494, 3)
(498, 3)
(1494,)
(498,)
基线平均绝对误差
在我们可以对我们的机器学习模型做出和评估任何预测以预测天气之前,我们需要建立一个基线,一个我们希望用我们的模型击败的合理指标。如果我们的模型不能从基线改进那么它就会失败,我们应该尝试不同的模型或者承认机器学习不适合我们的问题:
from sklearn.metrics import mean_squared_error
ypred = [ytrain.mean()] * len(ytrain)
print("Baseline MAE: ", round(mean_squared_error(ytrain, ypred), 5))
训练模型预测天气
现在为了用机器学习预测天气,我将训练一个随机森林算法,它能够执行分类和回归任务:
from sklearn.feature_selection import SelectKBest
from sklearn.ensemble import RandomForestRegressor
forest = make_pipeline(
SelectKBest(k="all"),
StandardScaler(),
RandomForestRegressor(
n_estimators=100,
max_depth=50,
random_state=77,
n_jobs=-1
)
)
forest.fit(xtrain, ytrain)
预测天气的机器学习模型的模型评估
为了正确看待我们的预测,我们可以使用从 100% 中减去的平均百分比误差来计算精度:
import numpy as np
errors = abs(ypred - yval)
mape = 100 * (errors/ytrain)
accuracy = 100 - np.mean(mape)
print("Random Forest Model: ", round(accuracy, 2), "%")
Random Forest Model: 99.52 %
另外,阅读——为什么 Python 比 R 更好。
我们的模型已经学会通过机器学习预测明年的天气状况,准确率为 99%。我希望您喜欢这篇关于如何使用机器学习构建模型来预测天气的文章。请随时在下面的评论部分向您提出有价值的问题。
版权归原作者 Sonhhxg_柒 所有, 如有侵权,请联系我们删除。