

Spark SQL的基础知识🎈🎈
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个叫作DataFrame的编程模型(带有Schema信息的RDD)。SparkSQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrameAPI和DatasetAPI三种方法实现对结构化数据的处理。
一、Spark SQL的简介
Spurk SQL****的前身是Shark,Shark最初是美国加州大学伯克利分校的实验室开发的Spark生态系统的组件之一。
Shark过于依赖Hive,因此在版本这代时很难添加新的优化策略。
Spark SQL主要提供三个功能
1.Spark SQL可以从各个结构数字化数据源(如JSON,Hive,Parquet等)中读取数据,进行缝隙
2.SparkSQL包含行业标准JDBC和ODBC连接方式,因此他不限于在Spark程序中使用SQL语句进行查询。
3.Spark SQL可以无缝的将SQL查询与Spark程序进行结合,他能将结构化数据作为Spark中的分布式数据集(RDD)进行查询,再Python,Scala和Java中均继承了相关的API。
总结:SparkSQL支持多种数据源的查询和加载,兼容Hive,可以使用JDBC/ODBC的连接方式来执行SQL语句,它为Spark框架在结构化数据分析方面提供重要的技术支持。
二.Spark SQL 架构
1 .Spark SQL****兼容Hive,Spark SQL 架构与Hive底层结构相似,Spark SQL复用Hive提供的元数据仓库(Metastore)、HiveQL、用户自定义函数(UDF)以及序列化和反序列工具(SerDes)。
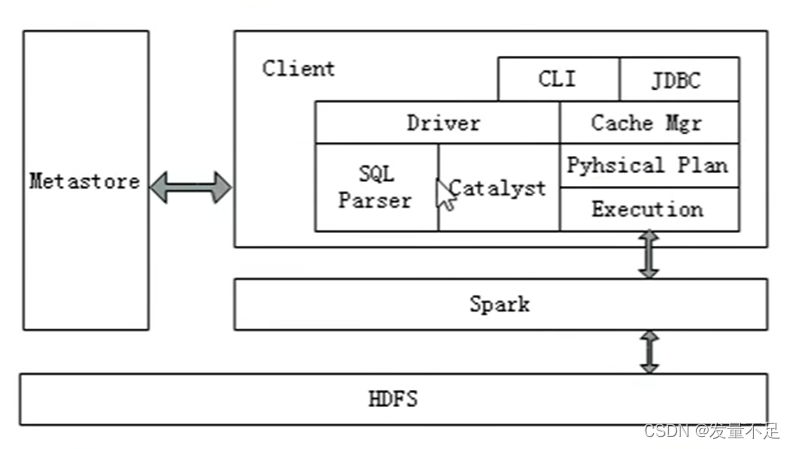
Spark SQL****快速的计算效率得益于 Catalyst优化器。(HiveQL 被解析成语法抽象树起,执行计划生成和优化的工作全部交 给(Spark sQD的Catalyst优化器负责和管理。
Spark的三大过程:解析(Parser)、优化(optimizer)、执行(execution)
Catalyst优化器执行生产和优化的五大组件:
*Parse***组件:**该组件根据一定的语义规则(即第三方类库ANTLR)将SparkSql字符串解析为一个抽象语法树AST。
*Analyze***组件:**该组件会遍历整个AST,并对AST上的每个节点进行数据类型的绑定以及函数绑定,然后根据元数据信息Catalog对数据表中的字段进行解析。
*Optimizer***组件:**该组件是Catalyst的核心,主要分为RBO和CBO两种优化策略,其中RBO是基于规则优化,CBO是基于代价优化。
SparkPlanner****组件:优化后的逻辑执行计划OptimizedLogicalPlan依然是逻辑的, 并不能被Spark系统理解,此时需要将OptimizedLogicalPlan转换成physical plan(物理计划)。
CostModel****组件:主要根据过去的性能统计数据,选择最佳的物理执行计划。
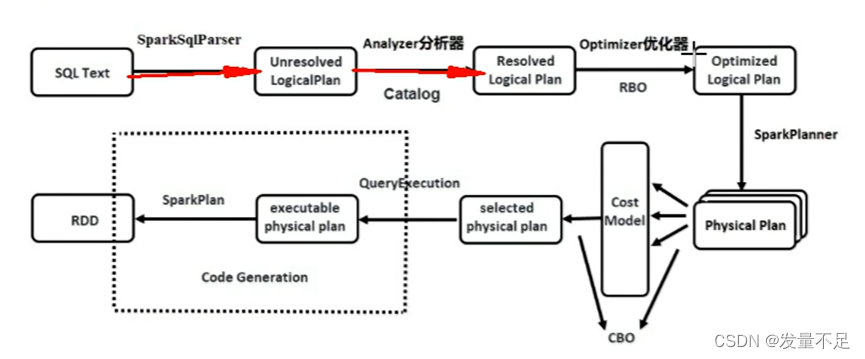
Spark SQL工作流程:
(1)在解析SQL语句之前会创建SparSession,涉及表名、字段名称和字段类型的元数据都将保存在Catalog中;
(2)当调用SparkSession的sq|(O方法时就会使用SparkSqlParser进行解析SQL语 句,解析过程中使用的ANTLR进行词法解析和语法解析:
(3)使用Analyzer分析器绑定逻辑计划,在该阶段Analyer会使用Analyzer Rules,并结合Catalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划;
(4) Optimizer根据预先定义好的规则(RBO)对Resolved Logical Plan 进行优化并生 成Optimized Logical Plan(最优逻辑计划);
(5)使用SparkPlanner对优化后的逻辑计划进行转换,生成多个可以执行的物理计划 Physical Plan;
(6) CBO优化策略会根据Cost Model算出每个Physical Plan的代价,并选取代价最 小的Physical Plan作为最终的Physical Plan;
(7)使用QueryExecuion执行物理计划,此时则调用SparkPlan的execute()方法,返回RDD.
版权归原作者 发量不足 所有, 如有侵权,请联系我们删除。