
原文链接:KIP-500: Replace ZooKeeper with a Self-Managed Metadata Quorum - Apache Kafka - Apache Software Foundation
译者:关于Kafka3.x版本最大的一个变化即是解除了对ZooKeeper的依赖,而本文的作者是大神Colin,他高屋建瓴地阐述去ZK的整个过程,更多的是偏整体设计,了解它有助于我们从一个较高的高度,更好的掌握KRaft
背景(Motivation)
Currently, Kafka uses ZooKeeper to store its metadata about partitions and brokers, and to elect a broker to be the Kafka Controller. We would like to remove this dependency on ZooKeeper. This will enable us to manage metadata in a more scalable and robust way, enabling support for more partitions. It will also simplify the deployment and configuration of Kafka.
当前,Kafka使用ZooKeeper来存储partitions、brokers这样的元数据,同时Kafka Controller的选主操作也是依赖ZooKeeper,因此我们想删除对ZooKeeper的依赖。这样我们可以以更具扩展性及鲁棒性的方式来管理元数据,并能够支持更多的分区,同时也可简化Kafka的部署及相关配置
元数据->事件日志(Metadata as an Event Log)
We often talk about the benefits of managing state as a stream of events. A single number, the offset, describes a consumer's position in the stream. Multiple consumers can quickly catch up to the latest state simply by replaying all the events newer than their current offset. The log establishes a clear ordering between events, and ensures that the consumers always move along a single timeline.
我们常常谈论将状态作为一系列事件来管理的好处。位点,只是一个单纯的数字,它描述出了一个consumer在流中的位置。所有的consumer都可以简单的重放那些比自己当前位点大的消息事件,从而快速追赶上来。日志在事件之间建立了清晰的顺序,并确保消费者始终沿着单一的时间线移动
However, although our users enjoy these benefits, Kafka itself has been left out. We treat changes to metadata as isolated changes with no relationship to each other. When the controller pushes out state change notifications (such as LeaderAndIsrRequest) to other brokers in the cluster, it is possible for brokers to get some of the changes, but not all. Although the controller retries several times, it eventually give up. This can leave brokers in a divergent state.
然而,我们Kafka的用户享受着这些好处,但Kafka自己却没有好好利用它。我们将元数据的更改视为彼此无关的孤立更改,当controller向集群中的其他broker推送状态变更时(例如LeaderAndIsrRequest),broker可能会收到一些更改请求,但并不是全部。虽然controller重试了几次,但最终还是放弃了。这会导致broker处于一个分裂状态
Worse still, although ZooKeeper is the store of record, the state in ZooKeeper often doesn't match the state that is held in memory in the controller. For example, when a partition leader changes its ISR in ZK, the controller will typically not learn about these changes for many seconds. There is no generic way for the controller to follow the ZooKeeper event log. Although the controller can set one-shot watches, the number of watches is limited for performance reasons. When a watch triggers, it doesn't tell the controller the current state-- only that the state has changed. By the time the controller re-reads the znode and sets up a new watch, the state may have changed from what it was when the watch originally fired. If there is no watch set, the controller may not learn about the change at all. In some cases, restarting the controller is the only way to resolve the discrepancy.
更糟糕的是,虽然ZooKeeper存储了元数据,但很多时候ZooKeeper存储的数据与controller内存中的元数据不一致。例如,当一个partition leader修改了其ISR列表,controller通常在很多秒后才能收到通知(译者:这里简单说明一下,partition leader会直接将ISR写入ZooKeeper,而不是controller,这样就导致了controller存储的并不是最新的元数据)。controller并没有一种通用的方法来跟踪ZooKeeper的事件日志。尽管controller可以设置一次性监视器,但出于性能考虑,监视器的数量是有限的。当一个ZooKeeper的监视器被触发,它并不会告诉controller只有某个partition的ISR变更了,只会告诉controller有变更了。当controller重新读取znode并重新设置watch时,状态可能相对比最初触发时已经发生了变更。而如果不设置watch,controller可能完全感知不到元数据的变更。有些时候,重启controller变成了唯一解决数据不一致的方法 (译者:本节通篇说的是ZooKeeper带来的一些不一致问题)
Rather than being stored in a separate system, metadata should be stored in Kafka itself. This will avoid all the problems associated with discrepancies between the controller state and the Zookeeper state. Rather than pushing out notifications to brokers, brokers should simply consume metadata events from the event log. This ensures that metadata changes will always arrive in the same order. Brokers will be able to store metadata locally in a file. When they start up, they will only need to read what has changed from the controller, not the full state. This will let us support more partitions with less CPU consumption.
比起将元数据存储在另外一个系统,Kafka更应该自己来管理它。这样可以避免所有因为controller及ZooKeeper状态不一致带来的问题。比起controller向broker推送数据,broker更应该从event日志中消费元数据变更事件。这样可以保证broker收到元数据的变更总是有序的。同时broker也可以将元数据存储在本地文件中,当它重启时,它不需要从controller处读取全量元数据,而只读取增量部分即可,这样就可以花费较少的cpu处理更多的partition
简化部署及配置(Simpler Deployment and Configuration)
ZooKeeper is a separate system, with its own configuration file syntax, management tools, and deployment patterns. This means that system administrators need to learn how to manage and deploy two separate distributed systems in order to deploy Kafka. This can be a daunting task for administrators, especially if they are not very familiar with deploying Java services. Unifying the system would greatly improve the "day one" experience of running Kafka, and help broaden its adoption.
ZooKeeper是一个独立的系统,有自己的配置文件、管理工具和部署模式。这意味着,系统管理员需要同时掌握管理及部署两个分布式系统,对于管理员来说,这可能是一项艰巨的任务,特别是如果他们不太熟悉如何部署Java服务的话。统一该系统将大大改善运行Kafka的“第一天”(译者:这里是老外用词的习惯,所谓“第一天”就是初次使用kafka的感受将会变好)体验,并有助于扩大其采用范围
Because the Kafka and ZooKeeper configurations are separate, it is easy to make mistakes. For example, administrators may set up SASL on Kafka, and incorrectly think that they have secured all of the data travelling over the network. In fact, it is also necessary to configure security in the separate, external ZooKeeper system in order to do this. Unifying the two systems would give a uniform security configuration model.
因为Kafka跟ZooKeeper的配置是分离的,因此这很容易犯错。例如,管理员可能会在Kafka上设置SASL,并错误地认为他们已经保护了通过网络传输的所有数据。事实上,为了做到这一点,还需要在单独的外部ZooKeeper系统中配置SASL。将这两个系统统一起来才能得到一个统一的安全配置模型
Finally, in the future we may want to support a single-node Kafka mode. This would be useful for people who wanted to quickly test out Kafka without starting multiple daemons. Removing the ZooKeeper dependency makes this possible.
最后,在将来,我们可能想支持一个单节点模式的Kafka集群,这对于运行不需要多节点的测试来说是非常有用的,而删除对ZooKeeper的依赖让其变得可能
架构(Architecture)
简介(Introduction)
This KIP presents an overall vision for a scalable post-ZooKeeper Kafka. In order to present the big picture, I have mostly left out details like RPC formats, on-disk formats, and so on. We will want to have follow-on KIPs to describe each step in greater detail. This is similar to KIP-4, which presented an overall vision which subsequent KIPs enlarged upon.
这个KIP为可扩展的、去ZooKeeper的Kafka提供了一个总体愿景。为了从大局分析及宏观叙事,我基本上省略了RPC格式、磁盘格式等细节。我们希望有后续的KIP来更详细地描述每个步骤。这类似于KIP-4,它提出了一个总体愿景,随后的KIP对此进行详细阐述
概述(Overview)
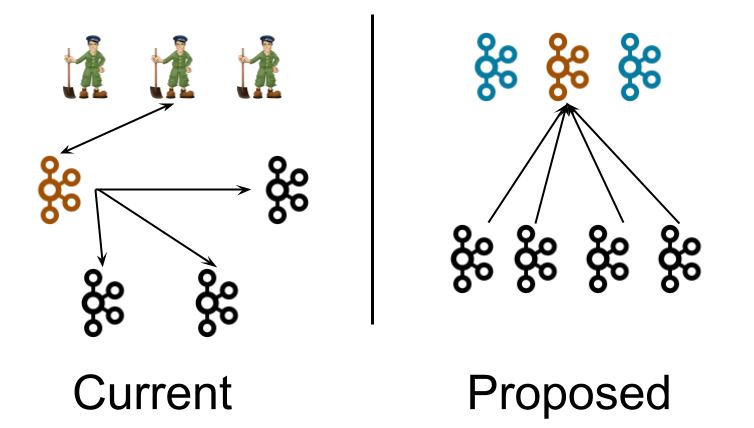
Currently, a Kafka cluster contains several broker nodes, and an external quorum of ZooKeeper nodes. We have pictured 4 broker nodes and 3 ZooKeeper nodes in this diagram. This is a typical size for a small cluster. The controller (depicted in orange) loads its state from the ZooKeeper quorum after it is elected. The lines extending from the controller to the other nodes in the broker represent the updates which the controller pushes, such as LeaderAndIsr and UpdateMetadata messages.
目前,Kafka集群包含多个broker节点和ZooKeeper的外部仲裁节点。上图中描绘了4个broker节点和3个ZooKeeper节点。这通常是一个小集群的规模。controller(以橙色显示)在被选中后从ZooKeeper中加载元数据等状态信息。从controller到其他broker的连线表示控制器推送的更新,如LeaderAndIsr和UpdateMetadata消息(译者:这里需要注意,ZooKeeper模式下,controller是向其他broker推送元数据的)
Note that this diagram is slightly misleading. Other brokers besides the controller can and do communicate with ZooKeeper. So really, a line should be drawn from each broker to ZK. However, drawing that many lines would make the diagram difficult to read. Another issue which this diagram leaves out is that external command line tools and utilities can modify the state in ZooKeeper, without the involvement of the controller. As discussed earlier, these issues make it difficult to know whether the state in memory on the controller truly reflects the persistent state in ZooKeeper.
请注意,此图多少有点误导。除了controller之外的其他broker也会与ZooKeeper通信。所以,实际上,应该从每个broker到ZK画一条线。然而,画那么多线会使此图难以阅读。此图遗漏的另一个问题是,外部的命令行工具和程序可以在不涉及controller的情况下修改ZooKeeper中的状态。如前所述,这些问题使得很难知道controller上内存中的状态是否真实反映了ZooKeeper中的持久状态
In the proposed architecture, three controller nodes substitute for the three ZooKeeper nodes. The controller nodes and the broker nodes run in separate JVMs. The controller nodes elect a single leader for the metadata partition, shown in orange. Instead of the controller pushing out updates to the brokers, the brokers pull metadata updates from this leader. That is why the arrows point towards the controller rather than away.
在“proposed”模式的架构中,三个controller节点代替了三个ZooKeeper节点。controller节点和broker节点在独立的JVM中运行。三个准controller节点会根据元数据分区选出一个leader,从而成为真正的集群controller(译者:这里说明一下,元数据分区指的是内部topic '__cluster_metadata'的0号分区,当然这个topic也只有一个分区),如橙色所示。broker从该leader那里获取元数据更新,而不是由controller向broker推送更新。这就是为什么箭头指向控制器而不是远离控制器的原因
Note that although the controller processes are logically separate from the broker processes, they need not be physically separate. In some cases, it may make sense to deploy some or all of the controller processes on the same node as the broker processes. This is similar to how ZooKeeper processes may be deployed on the same nodes as Kafka brokers today in smaller clusters. As per usual, all sorts of deployment options are possible, including running in the same JVM.
注意,尽管controller进程在逻辑上与broker进程是分开的,但它们不需要在物理上分开。在某些情况下,将部分或全部controller进程部署在与broker进程相同的节点上也是有意义的。这类似于小集群中,ZooKeeper进程也可能会与broker进程部署在同一个节点。与之前一样,各种部署模式都是可能的,包括在同一JVM中运行
Controller仲裁(The Controller Quorum)
The controller nodes comprise a Raft quorum which manages the metadata log. This log contains information about each change to the cluster metadata. Everything that is currently stored in ZooKeeper, such as topics, partitions, ISRs, configurations, and so on, will be stored in this log.
这些controller节点由管理元数据日志的Raft仲裁组成,这个元数据日志包含了所有元数据变更的信息。每一个当初存储在ZooKeeper的元数据,例如topics、partitions、ISR、configurations等,现在均存储在这个日志中
Using the Raft algorithm, the controller nodes will elect a leader from amongst themselves, without relying on any external system. The leader of the metadata log is called the active controller. The active controller handles all RPCs made from the brokers. The follower controllers replicate the data which is written to the active controller, and serve as hot standbys if the active controller should fail. Because the controllers will now all track the latest state, controller failover will not require a lengthy reloading period where we transfer all the state to the new controller.
利用Raft共识算法,这些个准controller节点将会在他们当中选举出一个leader,而不依赖任何外部系统。这个管理了元数据日志的leader被称为active controller。这个active controller将会处理所有来自broker的RPC请求,而所有的follower controllers会从active controller同步数据,并且作为热备随时等待active controller宕机后接管工作。因为这些follower controllers全部跟踪最新状态,因此将所有的状态转移至新controller不需要长时间的重新加载。
Just like ZooKeeper, Raft requires a majority of nodes to be running in order to continue running. Therefore, a three-node controller cluster can survive one failure. A five-node controller cluster can survive two failures, and so on.
就像ZooKeeper,Raft也是需要大多数节点存活才能持续提供服务的。因此,一个3节点的controller集群能够容忍1个节点宕机,一个5节点的集群能够容忍2个节点宕机,等等。。。
Periodically, the controllers will write out a snapshot of the metadata to disk. While this is conceptually similar to compaction, the code path will be a bit different because we can simply read the state from memory rather than re-reading the log from disk.
这些个controller会将元数据信息写入本地磁盘中,虽然这在概念上有点类似于“压实”,但代码实现上是稍有不同的,因为我们只是简单地直接从内存中读取数据,而不是从磁盘上读取 (译者:这里表达稍微有点绕,其实本质意思是说controller节点会将内存中的元数据压实后存入磁盘,但程序真正使用这些数据的时候,其实肯定是直接从内存中获取的。这里的压实-compaction是什么意思呢?其实对应的是kafka压实类型的topic,概念对其到这里。比如一个topic的partition数量,刚开始的时候是3,后来变成5,再后来最终变成10,那么在日志条数上一共有3条,但真正压实后,只会保留最近一条日志即可)
Broker元数据管理(Broker Metadata Management)
Instead of the controller pushing out updates to the other brokers, those brokers will fetch updates from the active controller via the new MetadataFetch API.
Broker将会使用新定义的API从active controller处拉取元数据,而不是ZooKeeper时代的由controller向broker推送数据
A MetadataFetch is similar to a fetch request. Just like with a fetch request, the broker will track the offset of the last updates it fetched, and only request newer updates from the active controller.
元数据的拉取很像是fetch请求的拉取。就像是fetch请求那样,broker将会使用本地存储的最新的offset向active controller发送元数据拉取请求(译者:这里注意一下,所谓fetch请求,就是consumer消费消息的时候调用的API,follower从leader处拉取消息也是使用的该API)
The broker will persist the metadata it fetched to disk. This will allow the broker to start up very quickly, even if there are hundreds of thousands or even millions of partitions. (Note that since this persistence is an optimization, we can leave it out of the first version, if it makes development easier.)
而broker会将拉取到元数据持久化到磁盘中。因此即便是有成千上万,甚至百万级别的partition,broker也能保证快速启动。(不过需要注意一点,持久化操作是一个优化项,在第一个版本中我们可以先不去实现它)
Most of the time, the broker should only need to fetch the deltas, not the full state. However, if the broker is too far behind the active controller, or if the broker has no cached metadata at all, the controller will send a full metadata image rather than a series of deltas.
在大多数的情况下,broker只需要拉取元数据的增量更新部分即可,而不需要拉取全量数据。然而,如果broker中的元数据落后active controller太多,或者当前的broker压根就没有存储任何元数据信息,active controller会直接发送全量的元数据信息
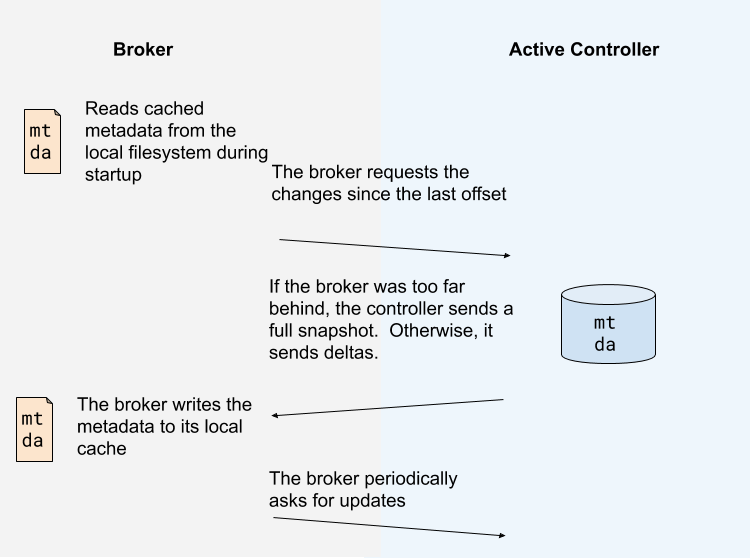
The broker will periodically ask for metadata updates from the active controller. This request will double as a heartbeat, letting the controller know that the broker is alive.
broker会周期性地向active controller发送元数据拉取请求,这个请求可以同时作为心跳,让controller知道这个broker还活着
Note that while this KIP only discusses broker metadata management, client metadata management is important for scalability as well. Once the infrastructure for sending incremental metadata updates exists, we will want to use it for clients as well as for brokers. After all, there are typically a lot more clients than brokers. As the number of partitions grows, it will become more and more important to deliver metadata updates incrementally to clients that are interested in many partitions. We will discuss this further in follow-on KIPs.
注意,本KIP只讨论broker对于元数据的管理,客户端的元数据管理对于可扩展性也非常重要。一旦这种增量更新元数据的架构实现了,我们同样也想将这种机制移植到客户端,毕竟通常情况下,客户端数量会比broker数量多很多。随着partition数量的增长,客户端增量更新元数据的方式变得越来越重要。我们会在将来其他的KIP中来讨论它
Broker状态机(The Broker State Machine)
Currently, brokers register themselves with ZooKeeper right after they start up. This registration accomplishes two things: it lets the broker know whether it has been elected as the controller, and it lets other nodes know how to contact it.
当前,broker一启动便会向ZooKeeper发起注册,注册会完成两件事:它让broker知道它自己是否已被选为controller,并让其他节点知道如何联系它
In the post-ZooKeeper world, brokers will register themselves with the controller quorum, rather than with ZooKeeper.
而在去ZooKeeper的模式下(译者:这里注意,后文原作者多次提到了“post-ZooKeeper”,直译过来就是去ZooKeeper,其实也就是KRaft,读者留意一下即可),broker会直接向controller发起注册,而不是ZooKeeper
Currently, if a broker loses its ZooKeeper session, the controller removes it from the cluster metadata. In the post-ZooKeeper world, the active controller removes a broker from the cluster metadata if it has not sent a MetadataFetch heartbeat in a long enough time.
当前,如果一个broke的ZooKeeper session过期了,controller会将其从元数据中移除。而在去ZooKeeper的模式下,当broker在指定时间内没有向controller发送MetadataFetch的心跳请求,此时其会被active controller从元数据中移除
In the current world, a broker which can contact ZooKeeper but which is partitioned from the controller will continue serving user requests, but will not receive any metadata updates. This can lead to some confusing and difficult situations. For example, a producer using acks=1 might continue to produce to a leader that actually was not the leader any more, but which failed to receive the controller's LeaderAndIsrRequest moving the leadership.
在当前ZooKeeper的模式下,如果一个broker能连接上ZooKeeper,但连接不上controller时,它不能再收到元数据更新了,它可以继续处理用户发过来的请求。这将会导致一些让人困惑以及复杂的场景。例如,当producer设置参数acks=1时,目标broker可能已经不是leader了,但producer还会一直向其发送数据,因为它已经收不到controller发送的LeaderAndIsrRequest切换leader的请求了
In the post-ZK world, cluster membership is integrated with metadata updates. Brokers cannot continue to be members of the cluster if they cannot receive metadata updates. While it is still possible for a broker to be partitioned from a particular client, the broker will be removed from the cluster if it is partitioned from the controller.
在去ZooKeeper的模式下,集群broker的成员资格是与元数据集成在一起的。当一个broker无法收到元数据变更时,它将不再是集群的成员。虽然有可能将一个broker与特定的client隔离,但如果broker与controller无法建联,则将从集群中删除该broker
Broker状态(Broker States)
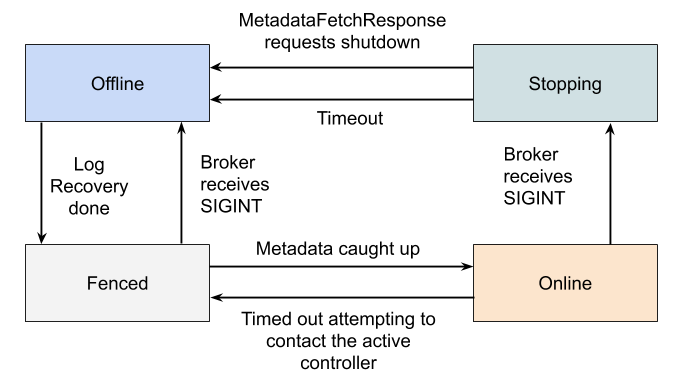
离线(Offline)
When the broker process is in the Offline state, it is either not running at all, or in the process of performing single-node tasks needed to starting up such as initializing the JVM or performing log recovery.
当一个broker变为了离线状态,要么它压根就没有运行,要么就是处于刚刚启动阶段,正在执行一些单节点的启动任务,例如JVM的初始化或者日志恢复等
隔离(Fenced)
When the broker is in the Fenced state, it will not respond to RPCs from clients. The broker will be in the fenced state when starting up and attempting to fetch the newest metadata. It will re-enter the fenced state if it can't contact the active controller. Fenced brokers should be omitted from the metadata sent to clients.
当一个broker处于隔离状态,它不会响应client发送的RPC请求。broker启动时准备去拉取元数据时,它将会处于隔离状态。如果它发现自己与controller无法建联,同样也会再次进入隔离状态。隔离状态的broker不会再向client发送元数据
在线(Online)
When a broker is online, it is ready to respond to requests from clients.
当一个broker处于在线状态,它会响应从client发送过来的请求
离线(Stopping)
Brokers enter the stopping state when they receive a SIGINT. This indicates that the system administrator wants to shut down the broker.
当broker收到指定信号时,broker将会进入离线状态,这表明系统管理员想要让这个broker宕机
When a broker is stopping, it is still running, but we are trying to migrate the partition leaders off of the broker.
当一个broker正在停止时,它其实仍在运行,我们正在尝试将leader迁移至其他broker
Eventually, the active controller will ask the broker to finally go offline, by returning a special result code in the MetadataFetchResponse. Alternately, the broker will shut down if the leaders can't be moved in a predetermined amount of time.
最后,active controller将会在MetadataFetchResponse请求时,通过返回一个特定的result code,来告诉这个broker可以真正下机了。或者leader转移的操作在指定的时间内无法完成,broker也会强制下线
转发已有API请求至Controller(Transitioning some existing APIs to Controller-Only)
Many operations that were formerly performed by a direct write to ZooKeeper will become controller operations instead. For example, changing configurations, altering ACLs that are stored with the default Authorizer, and so on.
之前许多同学需要写入ZooKeeper的操作将会变为controller的操作。例如,修改配置、更改默认权限的ACL,等等
New versions of the clients should send these operations directly to the active controller. This is a backwards compatible change: it will work with both old and new clusters. In order to preserve compatibility with old clients that sent these operations to a random broker, the brokers will forward these requests to the active controller.
新的客户端版本应该直接向active controller发送这些操作请求,这是一个向前兼容的操作:它将适用于旧集群及新集群。之前旧的client会将请求随机发送给一个broker,为了做到向前兼容,broker将会向controller转发这些请求
新Controller API(New Controller APIs)
In some cases, we will need to create a new API to replace an operation that was formerly done via ZooKeeper. One example of this is that when the leader of a partition wants to modify the in-sync replica set, it currently modifies ZooKeeper directly In the post-ZK world, the leader will make an RPC to the active controller instead.
在某些情况下,我们需要新建一些API用来替换那些以前通过ZooKeeper完成的操作。一个典型的例子,比如leader需要修改ISR列表,当前的现状是,leader会直接修改ZooKeeper。而在去ZooKeeper的模式下,leader将会向active controller发送RPC请求
删除直接操作ZooKeeper的工具(Removing Direct ZooKeeper Access from Tools)
Currently, some tools and scripts directly contact ZooKeeper. In a post-ZooKeeper world, these tools must use Kafka APIs instead. Fortunately, "KIP-4: Command line and centralized administrative operations" began the task of removing direct ZooKeeper access several years ago, and it is nearly complete.
当前,一些工具及脚本会直接与ZooKeeper建联。在去ZooKeeper的模式下,这些工具必须被Kafka API所替代。幸运的是,"KIP-4: Command line and centralized administrative operations" 这支KIP在几年前就已经开始了移除直接操作ZooKeeper的工作,而且它几乎已经都做完了
兼容性、过时及迁移计划(Compatibility, Deprecation, and Migration Plan)
客户端兼容性(Client Compatibility)
We will preserve compatibility with the existing Kafka clients. In some cases, the existing clients will take a less efficient code path. For example, the brokers may need to forward their requests to the active controller.
我们会为当前已经存在的kafka客户端版本提供兼容性。在一些场景下,现存的客户端在代码上可能不会有太大影响,比如broker会将某些请求转发给active controller(译者:确实,这种情况下,client压根就不用动,只需要broker后端做一些转发即可)
桥接版本(Bridge Release)
The overall plan for compatibility is to create a "bridge release" of Kafka where the ZooKeeper dependency is well-isolated.
兼容性的整体规划是创建一个“桥接版本”,在这个桥接版本中,对ZooKeeper的依赖能够被很好的隔离(译者:其实Kafka3.x版本同时支持了KRaft及ZooKeeper两种版本,用的就是这个所谓的桥接版本,而到了kafka4.x,将会彻底删除对ZooKeeper的依赖)
滚动更新(Rolling Upgrade)
The rolling upgrade from the bridge release will take several steps.
桥接版本的滚动更新将会经历多个步骤
升级至桥接版本(Upgrade to the Bridge Release)
The cluster must be upgraded to the bridge release, if it isn't already.
如果集群还没有升级到桥接版本,那它必须先升级
启动Controller仲裁节点(Start the Controller Quorum Nodes)
We will configure the controller quorum nodes with the address of the ZooKeeper quorum. Once the controller quorum is established, the active controller will enter its node information into /brokers/ids and overwrite the /controller node with its ID. This will prevent any of the un-upgraded broker nodes from becoming the controller at any future point during the rolling upgrade.
我们将会在controller节点上配置ZooKeeper的接入点。一旦controller仲裁完成,也就是选出了active controller,active controller会将它的broker ID加入至ZooKeeper的/brokers/ids路径下,并强制替换/controller路径的内容为自己的ID,这个操作将会防止所有还未升级至KRaft的broker节点在将来的滚动升级过程中,成为controller节点
Once it has taken over the /controller node, the active controller will proceed to load the full state of ZooKeeper. It will write out this information to the quorum's metadata storage. After this point, the metadata quorum will be the metadata store of record, rather than the data in ZooKeeper.
一旦它接管了/controller节点,active controller将会加载ZooKeeper的全部状态,而后它将这些数据写入至KRfat的元数据存储中(译者:其实就是将这些元数据信息写入内置topic:__cluster_metadata),在这之后,元数据的存储将会由ZooKeeper转移至KRfat模式下
We do not need to worry about the ZooKeeper state getting concurrently modified during this loading process. In the bridge release, neither the tools nor the non-controller brokers will modify ZooKeeper.
我们不需要担心ZooKeeper状态在这个加载过程中被其他broker或client并发修改。在桥接版本中,工具和非controller的broker都不会修改ZooKeeper
The new active controller will monitor ZooKeeper for legacy broker node registrations. It will know how to send the legacy "push" metadata requests to those nodes, during the transition period.
在这个集群模式变更的过渡时期,这个新的active controller将会监控ZooKeeper上的broker延时注册,它会将这些发生在ZooKeeper上的变化同步至KRfat模式下
滚动更新Broker节点(Roll the Broker Nodes)
We will roll the broker nodes as usual. The new broker nodes will not contact ZooKeeper. If the configuration for the zookeeper server addresses is left in the configuration, it will be ignored.
我们正常滚动更新这些broker节点即可。新的broker不会再与ZooKeeper建联,这些broker发现ZooKeeper的连接串没有配置,它们也不会在意,直接将其忽略
滚动更新Controller (Roll the Controller Quorum)
Once the last broker node has been rolled, there will be no more need for ZooKeeper. We will remove it from the configuration of the controller quorum nodes, and then roll the controller quorum to fully remove it.
一旦最后一个broker节点更新完毕,就再没有节点需要ZooKeeper了。我们还需要将其从Controller的配置中删除,滚动升级完毕后,整个集群中会移除对ZooKeeper的依赖
拒绝的备选方案(Rejected Alternatives)
可插拔共识(Pluggable Consensus)
Rather than managing metadata ourselves, we could make the metadata storage layer pluggable so that it could work with systems other than ZooKeeper. For example, we could make it possible to store metadata in etcd, Consul, or similar systems.
我们可以不用自己管理元数据,而是抽象一个元数据存储层,继而我们可以对接其他系统,而不仅仅是ZooKeeper。例如我们可以很容易地将数据存储在etcd、consul或其他详细的系统
Unfortunately, this strategy would not address either of the two main goals of ZooKeeper removal. Because they have ZooKeeper-like APIs and design goals, these external systems would not let us treat metadata as an event log. Because they are still external systems that are not integrated with the project, deployment and configuration would still remain more complex than they needed to be.
不幸的是,这个方案解决不了删除ZooKeeper这个目标。因为这个方案会拥有类似操作ZooKeeper的API及设计目标,而这些外部的系统也不能让我们管理元数据像event日志这样。因为它们仍然是一个外部系统而跟Kafka不是一个整体,部署、配置的复杂性依然很高
Supporting multiple metadata storage options would inevitably decrease the amount of testing we could give to each configuration. Our system tests would have to either run with every possible configuration storage mechanism, which would greatly increase the resources needed, or choose to leave some user under-tested. Increasing the size of test matrix in this fashion would really hurt the project.
支持多个元数据存储选项将不可避免地增加(译者:这里估计是原作者打错字了,原文写的减少decrease)对每个配置的测试量。我们的系统测试要么使用每种可能存在的配置存储机制运行,这将大大增加所需的资源;要么选择让一些用户处于测试中状态。以这种方式增加测试矩阵的大小,实际上会损害项目
Additionally, if we supported multiple metadata storage options, we would have to use "least common denominator" APIs. In other words, we could not use any API unless all possible metadata storage options supported it. In practice, this would make it difficult to optimize the system.
此外,如果我们支持多个元数据的存储选项,我们将不得不使用“最小公分母”API。换句话说,除非所有可能的元数据存储选项都支持某个API,否则我们无法使用该API。在实际操作中,这将使系统的优化变得困难
后续工作(Follow-on Work)
This KIP expresses a vision of how we would like to evolve Kafka in the future. We will create follow-on KIPs to hash out the concrete details of each change.
这个KIP表达了我们希望未来如何发展Kafka的愿景。我们将创建后续的KIP,以详细讨论每个变更的具体细节
- KIP-455: Create an Administrative API for Replica Reassignment
- KIP-497: Add inter-broker API to alter ISR
- KIP-543: Expand ConfigCommand's non-ZK functionality
- KIP-555: Deprecate Direct Zookeeper access in Kafka Administrative Tools
- KIP-589 Add API to update Replica state in Controller
- KIP-590: Redirect Zookeeper Mutation Protocols to The Controller
- KIP-595: A Raft Protocol for the Metadata Quorum
- KIP-631: The Quorum-based Kafka Controller
参考(References)
The Raft consensus algorithm
- Ongaro, D., Ousterhout, J. In Search of an Understandable Consensus Algorithm
Handling Metadata via Write-Ahead Logging
- Shvachko, K., Kuang, H., Radia, S. Chansler, R. The Hadoop Distributed Filesystem
- Balakrishnan, M., Malkhi, D., Wobber, T. Tango: Distributed Data Structures over a Shared Log
版权归原作者 昔久 所有, 如有侵权,请联系我们删除。