
6、Flink SQl 语法
1、查询语句
1、hint
在对表进行查询的是偶动态修改表的属性
-- 创建表
CREATE TABLE word (
lines STRING
)
WITH (
'connector' = 'kafka',
'topic' = 'word',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',-- 读取所有的数据
'format' = 'csv',
'csv.field-delimiter'='\t'
)
-- 加载hive函数
LOAD MODULE hive WITH ('hive-version' = '1.2.1');
--统计单词的数量
--不动态指定开始读取的参数
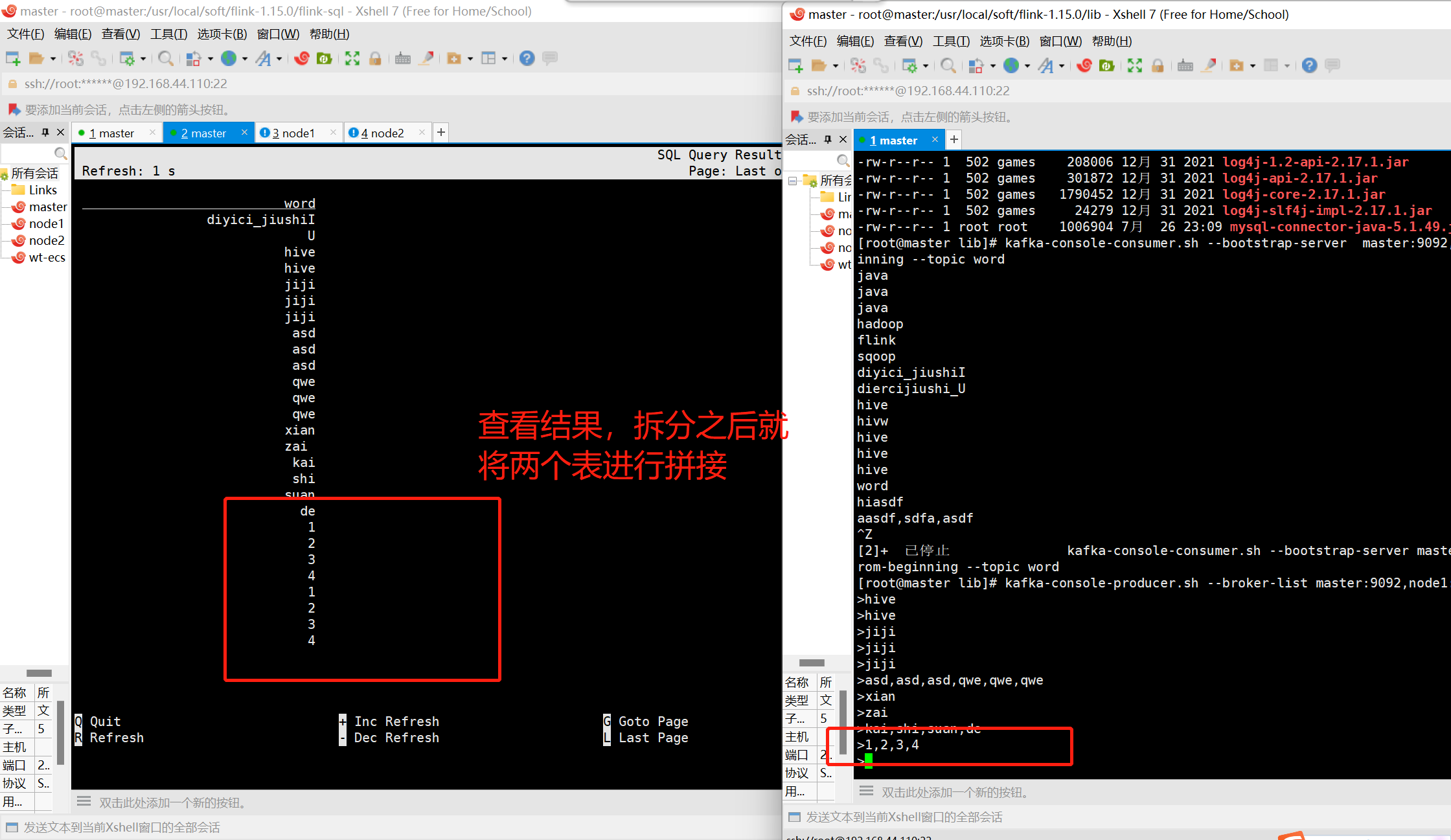
select word,count(1) from
word,
lateral table(explode(split(lines,','))) as t(word)
group by word
-- OPTIONS 动态指定参数
select word,count(1) from
word /*+ OPTIONS('scan.startup.mode'='latest-offset') */ ,
lateral table(explode(split(lines,','))) as t(word)
group by word

3、WITH
-- temp可以在后面的sql中使用多次
with temp as (
select word from word,
lateral table(explode(split(lines,','))) as t(word)
)
select * from temp
union all
select * from temp
4、SELECT
SELECT order_id, price
FROM
(VALUES (1, 2.0), (2, 3.1)) AS t (order_id, price)

5、分组窗口聚合
老版本语法,新版本中不推荐使用
-- PROCTIME(): 获取处理时间的函数
CREATE TABLE words_window (
lines STRING,
proc_time as PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'words',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',-- 读取所有的数据
'format' = 'csv',
'csv.field-delimiter'='\t'
)
-- TUMBLE:滚动窗口
-- HOP": 滑动黄口
-- SESSION: 会话窗口
--TUMBLE:处理时间的滑动窗口
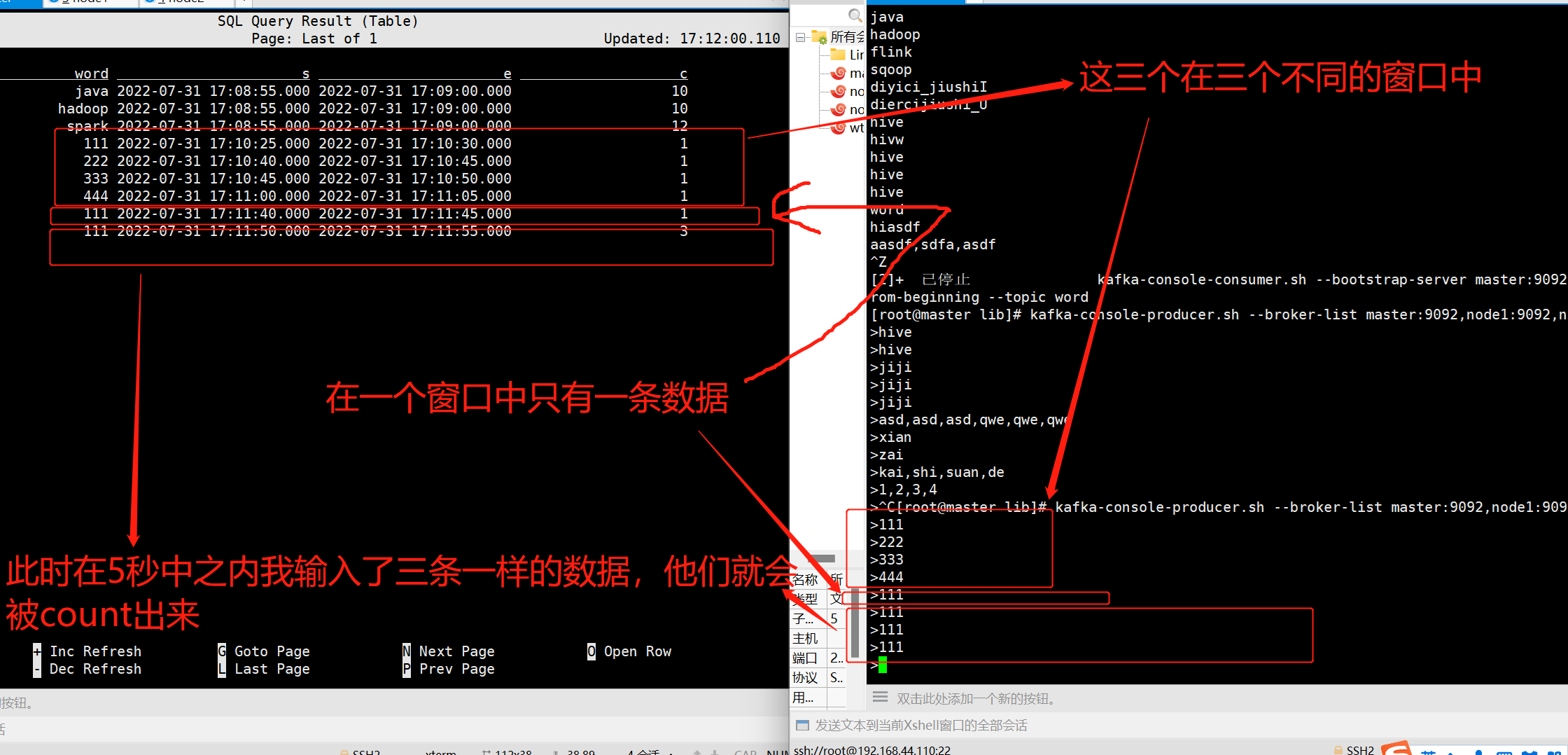
select
word,
TUMBLE_START(proc_time, INTERVAL '5' SECOND) as s, -- 窗口开始时间
TUMBLE_END(proc_time, INTERVAL '5' SECOND) as e, -- 窗口开始使时间
count(1) as c
from
words_window,
lateral table(explode(split(lines,','))) as t(word)
group by
word,
TUMBLE(proc_time, INTERVAL '5' SECOND) -- 每5秒计算一次
- 会话窗口> 一段时间没有数据开始计算> > 暂时只能在老板本api中使用
CREATE TABLE words_window (
lines STRING,
proc_time as PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'words',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',-- 读取所有的数据
'format' = 'csv',
'csv.field-delimiter'='\t'
)
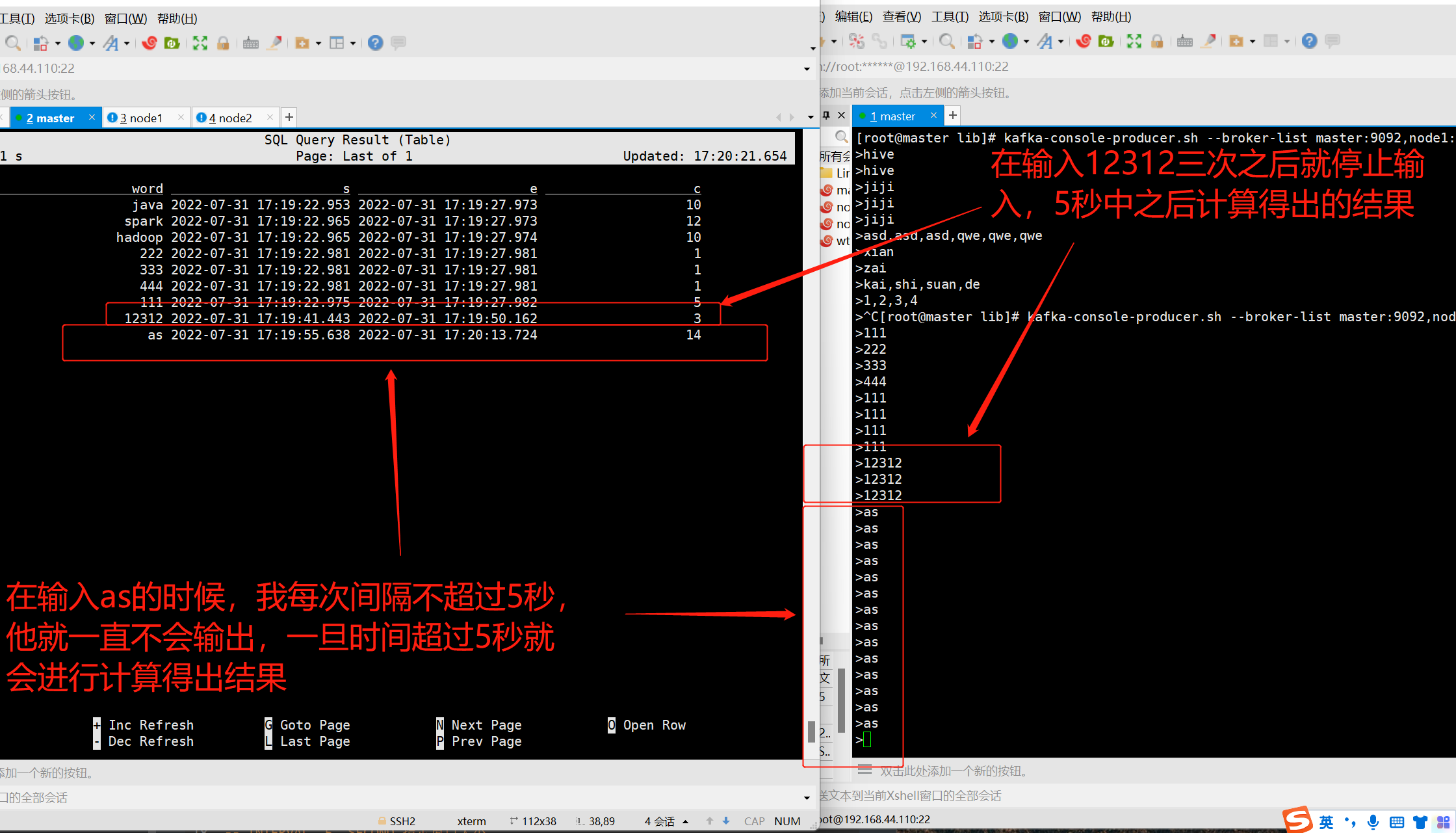
select
word,
SESSION_START(proc_time, INTERVAL '5' SECOND) as s, -- 窗口开始时间
SESSION_END(proc_time, INTERVAL '5' SECOND) as e, -- 窗口结束使时间
count(1) as c
from
words_window,
lateral table(explode(split(lines,','))) as t(word)
group by
word,
SESSION(proc_time, INTERVAL '5' SECOND) -- 会话超过5秒中没有发送消息,就开始进行计算
6、TVFs(重点)
- 滚动窗口函数
CREATE TABLE words_window (
lines STRING,
proc_time as PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'words',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',-- 读取所有的数据
'format' = 'csv',
'csv.field-delimiter'='\t'
)
-- TUMBLE(TABLE words_window, DESCRIPTOR(proc_time), INTERVAL '5' SECOND)
-- TUMBLE: 窗口函数,可以给原表增加床i偶开始时间,窗口的结束时间,窗口时间
-- TABLE words_window : 指定原表
-- DESCRIPTOR(proc_time) 指定时间字段,可以处理时间,也可以是事件时间
-- INTERVAL '5' SECOND 指定窗口大小
SELECT lines,proc_time,window_start,window_end,window_time FROM TABLE(
TUMBLE(TABLE words_window, DESCRIPTOR(proc_time), INTERVAL '5' SECOND)
);
-- 在划分和窗口之后进行聚合计算
SELECT word,window_start,count(1) as c FROM
TABLE(
TUMBLE(TABLE words_window, DESCRIPTOR(proc_time), INTERVAL '5' SECOND)
),
lateral table(explode(split(lines,','))) as t(word)
group by word,window_start
- 滑动窗口函数> 一条数据会出现在多个窗口中,所以输入一条数据,会输出多条数据
CREATE TABLE words_window (
lines STRING,
proc_time as PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'words',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',-- 读取所有的数据
'format' = 'csv',
'csv.field-delimiter'='\t'
)
-- HOP: 滑动窗口函数,需要指定窗口大小和滑动时间
-- 输入一条数据会输出多条数据
with temp as (
select * from words_window /*+ OPTIONS('scan.startup.mode'='latest-offset') */
)
SELECT * FROM
TABLE(
HOP(TABLE temp , DESCRIPTOR(proc_time), INTERVAL '5' SECOND, INTERVAL '15' SECOND)
)
;
-- 窗口止呕进行聚合
with temp as (
select * from words_window /*+ OPTIONS('scan.startup.mode'='latest-offset') */
)
SELECT word ,window_start,count(1) as c FROM
TABLE(
HOP(TABLE temp, DESCRIPTOR(proc_time), INTERVAL '5' SECOND, INTERVAL '15' SECOND)),
lateral table(explode(split(lines,','))) as t(word)
group by word,window_start
;
7、时间属性
1、处理时间
使用PROCTIME()函数给表增加一个时间字段
CREATE TABLE student_kafka_proc_time (
id STRING,
name STRING,
age INT,
gender STRING,
clazz STRING,
proc as PROCTIME() -- 处理时间字段
) WITH (
'connector' = 'kafka',
'topic' = 'student',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv',
'csv.field-delimiter'=',', -- csv格式数据的分隔符
'csv.ignore-parse-errors'='true', -- 如果出现脏数据据,补null
'csv.allow-comments'='true'--跳过#注释行
)
-- 使用处理时间可以做窗口统计
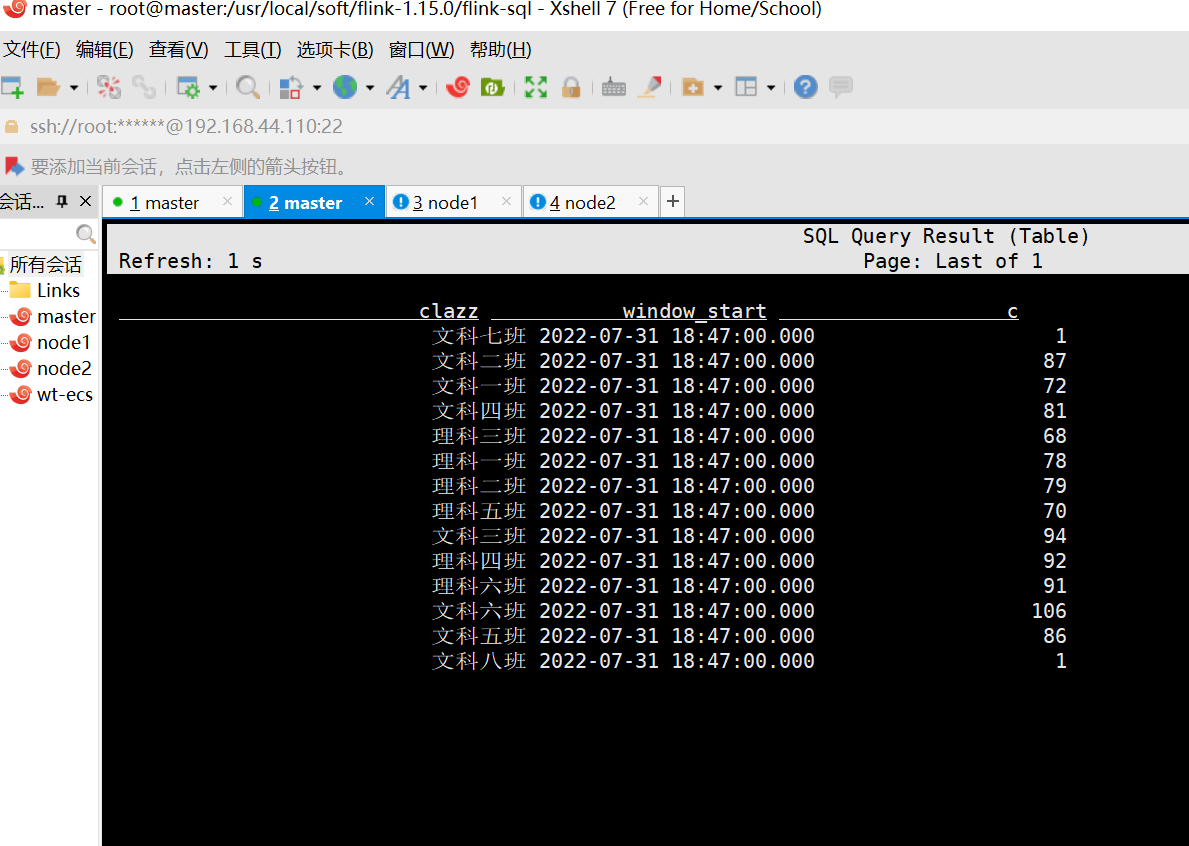
SELECT clazz,window_start,count(1) as c FROM
TABLE(
TUMBLE(TABLE student_kafka_proc_time, DESCRIPTOR(proc), INTERVAL '5' SECOND)
)
group by clazz,window_start
2、事件时间
- 测试数据
1500100001,施笑槐,22,女,文科六班,2022-07-20 16:44:101500100001,施笑槐,22,女,文科六班,2022-07-20 16:44:111500100001,施笑槐,22,女,文科六班,2022-07-20 16:44:121500100001,施笑槐,22,女,文科六班,2022-07-20 16:44:201500100001,施笑槐,22,女,文科六班,2022-07-20 16:44:151500100001,施笑槐,22,女,文科六班,2022-07-20 16:44:25 - 创建表指定时间字段和水位线
-- TIMESTAMP(3) flink的时间戳类型-- ts - INTERVAL '5' SECOND 水位线前移5秒CREATE TABLE student_kafka_event_time ( id STRING, name STRING, age INT, gender STRING, clazz STRING, ts TIMESTAMP(3), WATERMARK FOR ts AS ts - INTERVAL '5' SECOND -- 指定时间字段和水位线) WITH ( 'connector' = 'kafka', 'topic' = 'student_event_time', 'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv')-- 使用事件时间 做窗口函数统计-- 每一条数据都会计算出一个结果,会取更新之前已经输出的结果-- 不存在数据丢失问题-- 需要将统计结果保存在状态中 SELECT clazz,window_start,count(1) as c FROM TABLE( TUMBLE(TABLE student_kafka_event_time, DESCRIPTOR(ts), INTERVAL '5' SECOND) ) group by clazz,window_start -- 分钟窗口统计-- 如果数据乱序可能会丢失数据-- 不需要将统计的结果保存在状态中select clazz,TUMBLE_START(ts, INTERVAL '5' SECOND) as s, -- 窗口开始时间TUMBLE_END(ts, INTERVAL '5' SECOND) as e, -- 窗口开始使时间count(1) as cfrom student_kafka_event_timegroup by clazz,TUMBLE(ts, INTERVAL '5' SECOND) -- 没4秒计算一次 -- 生产数据 kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic student_event_time

练习
统计单词的数量,
每隔5秒统计一次
每个窗口中取单词数量最多个两个单词
CREATE TABLE words_window_demo (
lines STRING,
proc_time as PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'words',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',-- 读取所有的数据
'format' = 'csv',
'csv.field-delimiter'='\t'
)
-- 在夫林卡 sql 流处理中row_number()必须要取topN
select * from (
select
word,
window_start,
c,
row_number() over(partition by window_start order by c desc) as r
from (
select word,window_start,count(1) as c from
TABLE(
TUMBLE(TABLE words_window_demo, DESCRIPTOR(proc_time), INTERVAL '5' SECOND)
),
lateral table(explode(split(lines,','))) as t(word)
group by word,window_start
) as a
) as b
where r <= 2
- 统计每个城市中每个区县的车流量
- 每隔5分钟统计一次,统计最近15分钟的数据
- 每个城市中取车流量最大的前2个区县
- 将统计好的结果保存到数据库中
-- 数据
{
"car": "皖AK0H90",
"city_code": "340100",
"county_code": "340111",
"card": 117303031813010,
"camera_id": "00004",
"orientation": "北",
"road_id": 34130440,
"time": 1614799929,
"speed": 84.51
}
-- TIMESTAMP(3) flink的时间戳类型
-- ts - INTERVAL '5' SECOND 水位线前移5秒
-- 创建表读取kafka中的json数据
CREATE TABLE cars_kafka_event_time (
car STRING,
city_code STRING,
county_code STRING,
card BIGINT,
camera_id STRING,
orientation STRING,
road_id BIGINT,
`time` BIGINT,
speed DOUBLE,
ts_ltz AS TO_TIMESTAMP_LTZ(`time`, 3),
WATERMARK FOR ts_ltz AS ts_ltz - INTERVAL '5' SECOND -- 指定时间字段和水位线
) WITH (
'connector' = 'kafka',
'topic' = 'car_test',
'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092',
'properties.group.id' = 'carGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
)
-- 测试一下是否存在数据
select * from cars_kafka_event_time
-- 统计每个城市中每个区县的车流量,每隔5分钟统计一次,统计最近15分钟的数据,每个城市中取车流量最大的前2个区县
select *
from (
select
county_code
,city_code
,window_start
, c
,row_number() over(partition by window_start order by c desc) as r
from
(
with temp as (
select * from cars_kafka_event_time /*+ OPTIONS('scan.startup.mode'='latest-offset') */
)
SELECT
county_code
,city_code
,window_start
,count(1) as c
FROM
TABLE(
HOP(TABLE temp, DESCRIPTOR(ts_ltz), INTERVAL '5' SECOND, INTERVAL '15' SECOND))
group by county_code,city_code,window_start
) as b ) as h
where r <= 2;
-- 创建mysql的sink表
CREATE TABLE clazz_num_mysql (
country_city_r_count STRING,
window_start STRING,
PRIMARY KEY (country_city_r_count) NOT ENFORCED -- 按照主键更新数据
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata17?useUnicode=true&characterEncoding=UTF-8',
'table-name' = 'city_top_2', -- 需要手动到数据库中创建表
'username' = 'root',
'password' = '123456'
);
-- 发送到mysql中
insert into clazz_num_mysql
select concat_ws('_',county_code,city_code,r,c) country_city_r_count ,window_start
from (
select
cast(county_code as STRING) county_code
,cast(city_code as STRING) city_code
,cast(window_start as STRING) window_start
,cast(c as STRING) c
,cast(row_number() over(partition by window_start order by c desc) as STRING) as r
from
(
with temp as (
select * from cars_kafka_event_time
)
SELECT
county_code
,city_code
,window_start
,count(1) as c
FROM
TABLE(
HOP(TABLE temp, DESCRIPTOR(ts_ltz), INTERVAL '5' SECOND, INTERVAL '15' SECOND))
group by county_code,city_code,window_start
) as b ) as h
where r <= 2;
-- mysql 中的查询方法如下(笨方法)
select SUBSTRING_INDEX(country_city_r_count,'_',1) as country ,SUBSTRING_INDEX(SUBSTRING_INDEX(country_city_r_count,'_',2),'_',1)as city,SUBSTRING_INDEX(SUBSTRING_INDEX(country_city_r_count,'_',3) ,'_',-1) as topn , SUBSTRING_INDEX(country_city_r_count,'_',-1) as count_car ,window_start from city_top_2

本文转载自: https://blog.csdn.net/weixin_48370579/article/details/126091927
版权归原作者 a-tao必须奥利给 所有, 如有侵权,请联系我们删除。
版权归原作者 a-tao必须奥利给 所有, 如有侵权,请联系我们删除。