
本文还有配套的精品资源,点击获取 
简介:Spark-LP是一款利用Apache Spark分布式计算能力解决大规模线性规划问题的工具,旨在提升优化效率。线性规划在多个领域有广泛应用,而Spark-LP通过将问题分解并并行求解,大幅提高处理速度。该求解器支持Scala编写,并可利用Spark生态系统。文章将深入介绍Spark-LP的关键组件、概念和实际应用案例,帮助开发者和数据科学家提高处理分布式优化问题的能力。 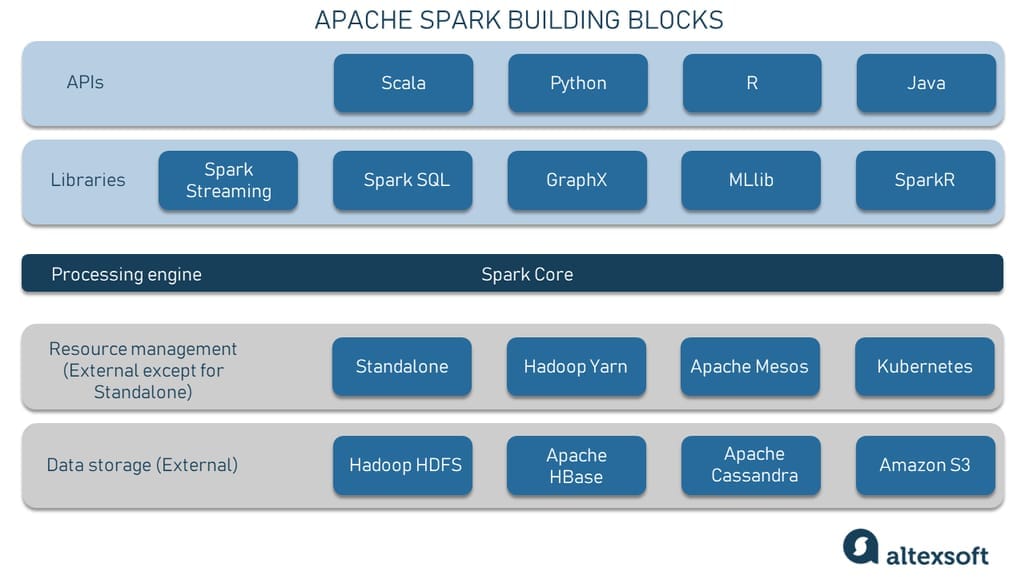
1. Apache Spark分布式计算框架
随着大数据时代的到来,Apache Spark作为一个开源的分布式计算系统,在处理大规模数据集方面表现卓越。Spark的分布式特性使得它能够在多个节点上并行处理数据,显著提高了数据处理速度和效率。本章节将介绍Spark的背景、核心组件以及它在现代数据处理中的重要性。
Apache Spark通过提供一套丰富的API来支持多种编程语言,如Scala、Java、Python和R等,同时它的集群管理能力是基于Hadoop YARN、Apache Mesos或自带的简单集群管理器来实现的。Spark通过其弹性分布式数据集(RDDs)提供了一个容错的并行数据处理模型,使得开发者可以轻松编写分布式应用。
在第一章的后续部分,我们将深入了解Spark的核心组件,如Spark Core、Spark SQL、Spark Streaming和MLlib等,并将探讨如何利用这些组件解决复杂的业务问题。通过本章的学习,读者将对Apache Spark有一个全面的认识,并为深入理解第二章中将要介绍的分布式线性规划求解器Spark-LP打下坚实的基础。
2. 分布式线性规划求解器Spark-LP的理论基础
分布式线性规划求解器Spark-LP利用Apache Spark的分布式计算能力,为大规模线性规划问题提供了一个高效的解决方案。本章节将深入探讨Spark-LP的理论基础,包括分布式线性规划的概述,以及Spark-LP的核心架构与组件。
2.1 分布式线性规划概述
2.1.1 线性规划模型的定义和重要性
线性规划(Linear Programming,LP)是一种在给定一组线性不等式约束条件下,求解线性目标函数最大值或最小值的问题。线性规划模型通常用于资源优化、投资决策、生产调度等场景,因其在解决现实世界中的优化问题时具有强大的实用性。
线性规划问题一般可以用以下形式表示:
minimize (or maximize) c^T x
subject to A x <= b
x >= 0
其中,c和x是向量,A是矩阵,b是向量,目标是最小化(或最大化)目标函数c^T x的值,同时满足线性不等式约束条件。
线性规划在工业和学术领域都有广泛的应用,例如在制造业中优化生产计划,在金融领域制定投资组合策略,在运输行业中规划物流路线等。
2.1.2 分布式计算对线性规划的优化作用
随着数据规模的日益增大,传统的线性规划求解方法已不能有效地处理大规模问题。分布式计算提供了一个有效的解决方案,通过将问题拆分成更小的部分,并在多个计算节点上并行处理,可以显著减少求解大型线性规划问题所需的时间。
分布式线性规划框架如Spark-LP,可以利用其内存计算能力,快速加载和处理大规模数据集,同时通过并行化算法在不同的节点上分散计算任务,减少了数据传输和等待时间,从而在保持求解精度的同时,显著提高了求解速度。
2.2 Spark-LP的核心架构与组件
2.2.1 Spark-LP的系统架构设计
Spark-LP采用模块化的设计,核心架构包括数据处理层、优化算法层、用户接口层和集群管理层。数据处理层利用Spark的RDD进行数据的加载和初步处理,优化算法层则运行分布式优化算法处理线性规划问题。用户接口层提供了简洁的API和用户界面,让开发者和用户可以方便地提交和管理任务。集群管理层负责监控和分配计算资源,保证系统的稳定运行。
2.2.2 关键组件的功能和作用
关键组件包括数据输入输出模块、问题转换模块、求解引擎、容错机制等。数据输入输出模块负责读取数据和输出求解结果,问题转换模块将线性规划问题转换成Spark-LP可以处理的形式,求解引擎运行分布式线性规划算法,容错机制则确保了即使在部分节点故障的情况下也能正确求解问题。
每个组件都是Spark-LP不可或缺的部分,它们相互协作,共同保证了Spark-LP在分布式环境下高效的线性规划求解能力。
2.2.3 Spark-LP架构的优化实践
在分布式环境中,数据倾斜、任务调度、资源分配等问题可能影响Spark-LP的性能。因此,Spark-LP架构设计中需要考虑优化实践,比如采用数据分区策略、动态资源管理、负载均衡技术等来提升计算效率。
在数据分区策略方面,Spark-LP通过优化RDD分区策略,减少数据倾斜,实现更均匀的任务分配,从而提升整体计算性能。在动态资源管理上,Spark-LP根据任务执行情况动态调整资源分配,保证了系统的高效和稳定运行。
通过这些优化实践,Spark-LP能够在处理大规模线性规划问题时提供一个鲁棒、灵活且高效的计算框架。
2.2.4 Spark-LP架构的扩展性和维护性
随着业务的扩展和计算需求的增加,系统的可扩展性和维护性变得尤为重要。Spark-LP在设计上注重模块化和解耦,这样可以很容易地添加新的功能或优化现有组件,而不需要对整个系统进行大规模重构。
系统的维护性通过提供详细的日志记录、监控工具和文档来实现。这使得开发者和系统管理员可以快速定位问题,并进行必要的维护和升级。
2.2.5 Spark-LP与其他分布式计算框架的比较
Spark-LP与其他分布式计算框架相比,如Hadoop的MapReduce,拥有更丰富的优化功能和更高效的内存计算能力。Spark-LP利用RDD的特性来提供更快的数据访问速度,而其支持的高级API则简化了分布式优化问题的实现。
此外,Spark-LP的设计目标是为了处理大规模数据集上的复杂优化问题,而不是像其他框架那样只侧重于通用的数据处理任务。这种针对性使得Spark-LP在特定的应用场景中,比如线性规划、二次规划等,具备更专业的处理能力。
2.2.6 Spark-LP的性能评估和案例分析
评估Spark-LP的性能需要考虑多个方面,包括计算速度、资源利用率、可伸缩性等。通过与其他线性规划求解器,如Gurobi、CPLEX等的比较,可以评估Spark-LP在不同条件下的性能表现。
案例分析可以帮助我们更好地理解Spark-LP在实际应用中的优势。例如,在处理一个大规模的物流优化问题时,Spark-LP通过并行化优化算法,能够有效地缩短求解时间,并提供接近最优解的结果。
以上是对分布式线性规划求解器Spark-LP的理论基础的介绍,下一章节将会详细探讨其在分布式环境下的实践应用。
3. Spark-LP在分布式环境下的实践应用
3.1 RDD在分布式线性规划中的应用
3.1.1 RDD数据结构的优势及其对优化问题的影响
弹性分布式数据集(RDD)是Apache Spark中的核心抽象,它允许用户在容错的文件系统上执行并行操作。RDD提供了一种高效、容错的方式来处理大量数据,并且是实现复杂优化问题时的重要工具。对于分布式线性规划求解器Spark-LP而言,RDD的应用带来了一些关键优势:
- ** 容错性 ** :RDD的容错机制基于数据副本的创建,使得在计算过程中出现节点故障时,系统可以自动重新计算丢失的数据分区,而无需从头开始整个计算过程。
- ** 高效的并行操作 ** :通过Spark的RDD操作,可以自动优化数据在节点间的传输,减少网络瓶颈,提升计算效率。
- ** 内存计算 ** :RDD的计算模型允许在内存中处理数据,这对于需要大量迭代的线性规划问题来说,可以显著提高求解速度。
- ** 延迟执行 ** :RDD的操作具有惰性,仅在需要结果的时候才会执行,这使得Spark-LP可以优化执行计划,减少不必要的计算。
在实际应用中,Spark-LP可以利用RDD的这些特性,设计出更加高效的分布式线性规划算法,从而在大数据环境下提供更加快速和准确的解决方案。
3.1.2 具体案例:RDD在大规模数据处理中的应用实例
作为具体案例,考虑一个典型的物流路线优化问题,在这个问题中,需要根据不同的运输成本和时间约束来计算最优的货物配送路线。使用Spark-LP和RDD,这个问题可以通过以下步骤解决:
- ** 数据加载和准备 ** :首先,使用RDD加载大量的订单数据、运输成本和时间限制等信息。
- ** 转换和过滤 ** :然后,利用RDD提供的转换操作(如
map和filter)来处理和清洗数据,为模型构建准备合适的数据格式。 - ** 模型构建 ** :基于准备好的数据,构建线性规划模型。在这个阶段,可以将复杂的业务逻辑和约束条件通过RDD操作转换为数学模型。
- ** 求解过程 ** :模型构建完毕后,Spark-LP利用RDD的并行处理能力进行求解。求解过程涉及到迭代计算,RDD能够通过分区操作和缓存机制显著提高运算效率。
- ** 结果分析 ** :求解完成后,将结果映射回RDD,并以适当格式输出。这可能涉及到数据的进一步转换,以便更好地呈现和理解。
通过上述步骤,Spark-LP可以利用RDD的特性,在大规模数据集上求解复杂的线性规划问题。接下来,我们将探讨MapReduce模型在Spark-LP中的运用。
3.2 MapReduce模型在Spark-LP中的运用
3.2.1 MapReduce模型的原理及其在Spark-LP中的适应性
MapReduce是一种编程模型,用于大规模数据集的并行运算。它由两部分组成:Map和Reduce。在Map阶段,原始数据被分割成独立的块,然后并行处理;在Reduce阶段,中间结果被汇总和合并,最终产生整个问题的解决方案。
MapReduce模型在Spark-LP中的适应性体现在以下几个方面:
- ** 分布式处理 ** :MapReduce允许数据被分割并在多个节点上并行处理,这与Spark-LP处理大规模数据集的需求高度一致。
- ** 容错机制 ** :MapReduce操作通常在节点出现故障时能够重新执行,为分布式线性规划的稳定运行提供了保障。
- ** 可扩展性 ** :MapReduce设计为易于扩展,随着数据量和计算资源的增加,它能够适应更大的计算规模。
在分布式线性规划中,MapReduce模型可以帮助有效地组织大规模数据的处理流程,实现高效率的并行计算。
3.2.2 优化实践:如何在Spark-LP中实现高效MapReduce
为了在Spark-LP中实现高效MapReduce,我们需要关注以下几个关键实践:
- ** 数据分区策略 ** :合理的数据分区可以显著提高并行处理的效率。通过分析数据的特征,选择合适的键值进行分区,确保数据均匀分配。
scala val data = sc.textFile("hdfs://path/to/large/input") val keyData = data.map(line => { val parts = line.split(",") // 假设我们按照逗号分隔数据 (parts(0), line) }).partitionBy(new HashPartitioner(10)) // 将数据分区成10个部分 - ** Map操作的优化 ** :在Map阶段,需要尽可能减少计算和资源消耗,同时确保中间结果的准确性。
scala val mappedData = keyData.map { case (key, value) => // 处理每个分区的数据 ... } - ** Reduce操作的并行化 ** :在Reduce阶段,应该设计高效的合并逻辑,确保能够并行化地对数据进行归约。
scala val reducedData = mappedData.reduceByKey { (a, b) => // 归约逻辑 ... } - ** 作业链的优化 ** :通过优化作业链,减少不必要的数据序列化和网络传输,可以进一步提升Spark-LP的性能。
scala // 示例:将多个操作链式连接,以减少中间数据的创建 val result = originalData.map(...) .filter(...) .reduceByKey(...) .join(...)
通过以上优化实践,Spark-LP能够更加有效地利用MapReduce模型处理大规模分布式线性规划问题。这不仅提升了问题求解的效率,而且提高了系统的可靠性和稳定性。在下一节中,我们将探讨如何利用Spark-LP的高级功能和应用场景来解决实际问题。
4. Spark-LP中的关键技术和算法
4.1 分布式优化算法概述
4.1.1 Simplex方法的基本原理及其分布式版本
Simplex方法是由George Dantzig在1947年提出的一种用于求解线性规划问题的算法。它通过在多面体的顶点上进行搜索,逐步移动到最优解。其基本思想是寻找一个可以改进的基解,通过迭代的方式达到最优解或证明问题无界。
在分布式环境下,传统的Simplex方法需要进行改造以适应大规模数据的处理和多节点计算环境。分布式Simplex算法通常采用如下策略: - ** 任务划分 ** :将大型的线性规划问题分解为小任务,分配到多个节点上。 - ** 局部优化 ** :各个节点首先在本地进行优化迭代。 - ** 全局同步 ** :定期在所有节点间进行信息同步,更新全局状态。 - ** 负载平衡 ** :监控计算负载,动态调整任务分配以平衡节点负载。
分布式Simplex算法的一个关键挑战是如何设计高效的消息传递和状态同步机制,以减少通信开销,并确保算法的收敛性。由于每个节点的计算资源可能不同,算法还需要能够适应不同的计算环境。
4.1.2 Interior Point Method的分布式实现及其优势
Interior Point Method (IPM) 是另一种求解线性规划问题的算法,尤其适合解决大规模问题。IPM的核心思想是在解空间内部找到最优解,而不是像Simplex方法那样沿着边界搜索。这种方法的优点是具有多项式时间复杂度,通常比Simplex方法更快速。
在Spark-LP中,IPM的分布式实现可能涉及以下步骤: - ** 初始解生成 ** :使用线性规划的松弛形式生成一个可行的初始解。 - ** 迭代求解 ** :在满足可行性条件的前提下,沿着一个特定的方向迭代求解。 - ** 预处理和调整 ** :通过线性代数运算如LU分解进行预处理,以提高求解效率。 - ** 并行加速 ** :利用Spark分布式数据处理能力,将线性代数运算并行化。
IPM在分布式环境中的一个显著优势是其内部迭代通常可以独立进行,易于并行化处理。而且,由于IPM的收敛速度较快,特别适合处理那些在数据规模大到难以被Simplex方法高效处理的情况。
4.2 Scala的并发特性与Spark并行模型
4.2.1 Scala并发编程的基础知识
Scala是一种多范式编程语言,设计用于扩展Java语言,它集成了面向对象和函数式编程特性。Scala中的并发编程主要依赖于
Actor
模型,这与传统线程模型相比,可以更安全地管理并发和状态。
Actor
是一个并发模型的基本构建块,每个
Actor
有自己的私有状态,可以接收和发送消息,但不能直接共享状态。这大大简化了并发程序的设计,因为开发者不需要担心线程安全问题。
除了
Actor
模型,Scala还提供了其他并发工具,如
Future
和
Promise
。
Future
代表一个可能还没有完成的计算过程,允许开发者继续执行后续代码,而计算结果会在未来某个时刻准备好。
Promise
则是一个可以被
Future
消费的可写容器,表示一个还未完成的结果。
4.2.2 Spark并行模型与Scala并发特性的结合
Apache Spark作为分布式计算系统,其并行模型与Scala的并发特性相结合,为处理大数据问题提供了强大的支持。在Spark中,数据以分布式集合的形式存储和操作,称为RDD(弹性分布式数据集)。RDD的每个数据分区可以分布在不同的节点上,每个分区可以并行地进行操作。
在Spark-LP中,算法的每一步骤可以在多个分区上并行执行。利用Scala的并发特性,开发者可以编写出高效的数据处理和算法实现逻辑。比如,在使用
mapPartitions
操作时,可以利用
Future
来并行执行每个分区的计算任务,并最终收集结果。
这种结合使得Spark-LP可以在Spark集群上实现高效率的并行计算,尤其是对于复杂的优化算法,可以有效地利用集群的计算资源,加速求解过程。同时,借助Scala的函数式特性,代码更简洁且易于维护,大大提高了开发效率。
在接下来的章节中,我们将深入探讨Spark-LP中的关键技术和算法的应用实例,以具体案例来展示其在分布式环境下的强大性能和优化能力。
5. Spark-LP的高级功能和应用场景
在上一章中,我们探讨了Spark-LP的关键技术和算法,深入理解了其在分布式计算中的作用和实现方式。现在,我们转向Spark-LP的高级功能和应用场景,这将帮助读者更深入地了解Spark-LP的实用性和强大能力。
5.1 错误处理和容错机制
在分布式计算环境中,错误处理和容错是确保系统稳定性和可靠性的重要因素。Spark-LP在设计时充分考虑了这些因素,并提供了相应的策略和机制。
5.1.1 Spark-LP中的错误处理策略
分布式系统面临的主要挑战之一是节点故障,这些故障可能会导致任务失败或者数据丢失。在Spark-LP中,错误处理策略依赖于以下几个关键方面:
- ** 任务重试机制 ** :当检测到任务失败时,Spark-LP会自动尝试重新执行该任务。
- ** 数据持久化 ** :RDD的数据持久化机制可以确保在节点故障时数据不丢失,因为数据会被存储在多个节点上。
- ** 备份任务 ** :对于长时间运行的任务,Spark-LP会创建备份任务来防止数据处理进度的丢失。
5.1.2 容错机制的实现原理及其对系统稳定性的影响
为了支持这些错误处理策略,Spark-LP采用了基于RDD的容错机制:
- ** 不变性 ** :RDD是不可变的,这意味着一旦创建,其内容不会改变。如果任务失败,Spark-LP只需要重新计算丢失的RDD分区即可恢复。
- ** 血统依赖 ** :每个RDD记录了创建它的操作和父RDD,这样Spark-LP可以重新计算丢失的数据分区。
- ** 分区 ** :数据被分割成小的分区,并分布在整个集群中,使得单点故障不会影响整个计算过程。
5.2 用户界面和API设计
为了使Spark-LP易于使用,用户界面和API的设计至关重要。以下是如何实现易用性的关键点:
5.2.1 Spark-LP的用户界面设计原则和用户体验
- ** 直观性 ** :用户界面直观,让用户能够轻松地了解如何操作Spark-LP,并监控作业进度。
- ** 功能模块化 ** :不同功能被合理划分,用户可以根据需要启用或禁用特定模块。
- ** 实时反馈 ** :实时显示计算状态和结果,便于用户及时作出调整。
5.2.2 API设计的关键要素及其在开发者中的应用
- ** 简洁性 ** :API接口设计简洁明了,易于理解和使用。
- ** 灵活性 ** :提供可扩展的接口,允许开发者根据需求定制自己的线性规划模型。
- ** 文档完备性 ** :API文档详尽,提供足够的示例代码,帮助开发者快速上手。
5.3 Spark生态系统的集成
Spark-LP不仅仅是一个独立的工具,它可以轻松集成到整个Spark生态系统中,这为开发者带来了极大的便利。
5.3.1 Spark-LP与Spark生态组件的集成策略
- ** 数据集成 ** :Spark-LP能够读取HDFS、HBase等多种数据源,实现与Spark SQL的无缝对接。
- ** 操作集成 ** :支持DataFrame、Dataset等Spark SQL的数据结构,便于用户在Spark-LP中进行复杂的数据处理。
- ** 工作流集成 ** :可以作为Spark Streaming的一部分,用于实时数据的线性规划处理。
5.3.2 集成实践:如何在现有Spark应用中部署Spark-LP
部署Spark-LP通常涉及以下步骤:
- ** 环境准备 ** :确保Spark环境已经搭建好,并且Spark版本与Spark-LP兼容。
- ** 依赖引入 ** :在项目中引入Spark-LP的依赖。
- ** 配置调整 ** :根据需要调整Spark配置,优化Spark-LP的性能。
- ** API调用 ** :在应用程序中使用Spark-LP提供的API进行线性规划求解。
5.4 Spark-LP在实际场景中的应用
Spark-LP在多个实际场景中的应用证明了其强大的适用性和价值。
5.4.1 物流优化:如何利用Spark-LP进行高效的物流规划
物流领域中,路径优化是一个常见的线性规划问题。利用Spark-LP,可以实现以下功能:
- ** 运输成本优化 ** :最小化运输成本,同时满足货物需求。
- ** 运输时间优化 ** :计算最快运输路径,缩短货物到达时间。
- ** 资源分配 ** :优化车辆、人员等资源的分配,提高物流效率。
5.4.2 资源分配:Spark-LP在资源分配优化中的作用
资源分配问题在各种行业都十分常见,Spark-LP可以通过以下方式优化资源分配:
- ** 资金分配 ** :合理分配有限资金,最大化投资回报。
- ** 人力资源 ** :优化人员分配,提高工作效率。
- ** 计算资源 ** :动态分配计算资源,平衡负载,提高计算效率。
5.5 开发者和数据科学家的技能提升
最后,Spark-LP不仅仅是一个工具,它还是一个帮助开发者和数据科学家提升技能的平台。
5.5.1 分布式优化知识框架和学习路径
为了更好地使用Spark-LP,开发者需要构建以下知识框架:
- ** 分布式系统基础 ** :了解分布式系统的工作原理和特点。
- ** 线性规划理论 ** :掌握线性规划模型的构建和求解方法。
- ** Spark框架学习 ** :熟悉Spark的基础架构和操作。
5.5.2 Spark-LP在提升分布式优化能力方面的价值
通过使用Spark-LP,开发者和数据科学家可以:
** 实践技能提升 ** :在实际项目中使用Spark-LP,提高解决复杂问题的能力。
** 理论与实践结合 ** :将理论知识应用于实际场景中,加深对分布式优化的理解。
** 创新解决方案 ** :开发新的算法和方法,推动分布式优化领域的进步。
本文还有配套的精品资源,点击获取
简介:Spark-LP是一款利用Apache Spark分布式计算能力解决大规模线性规划问题的工具,旨在提升优化效率。线性规划在多个领域有广泛应用,而Spark-LP通过将问题分解并并行求解,大幅提高处理速度。该求解器支持Scala编写,并可利用Spark生态系统。文章将深入介绍Spark-LP的关键组件、概念和实际应用案例,帮助开发者和数据科学家提高处理分布式优化问题的能力。
本文还有配套的精品资源,点击获取
版权归原作者 Ready-Player 所有, 如有侵权,请联系我们删除。