
网络爬虫—字体反爬
前言:
🏘️🏘️个人简介:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证
📝📝第一篇文章《1.认识网络爬虫》获得全站热榜第一,python领域热榜第一。
🧾 🧾第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
🧾 🧾第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
🧾 🧾第十篇文章《10.网络爬虫—MongoDB详讲与实战》全站热榜第八,领域热榜第二🧾 🧾第十三篇文章《13.网络爬虫—多进程详讲(实战演示)》
全站热榜第十二。
🧾 🧾第十四篇文章《14.网络爬虫—selenium详讲》测试领域热榜第二十。
🎁🎁《Python网络爬虫》专栏累计发表十五篇文章,上榜六篇。欢迎免费订阅!欢迎大家一起学习,一起成长!!
💕💕悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
一·字体反爬原理
🧾 🧾 Python字体反爬原理是指爬虫在爬取网站数据时,遇到了基于字体反爬的防护措施。这种反爬措施是通过将网站的文字转换成特定的字体文件,然后在页面上引用该字体文件来显示文字,使得爬虫无法直接获取文字内容。
🧾 具体原理如下:
- 网站将需要显示的文字转换成特定的字体文件,通常是
TrueType或OpenType格式的字体文件。 - 网站在页面上引用该字体文件,并使用CSS样式将需要显示的文字的字体设置为该字体文件。
- 爬虫在获取页面源代码时,无法直接获取到需要显示的文字内容,只能获取到字体文件的引用地址。
- 爬虫可以通过下载字体文件并解析其中的映射关系,将字体文件中的编码与对应的文字内容进行匹配,从而获取到需要显示的文字内容。
- 为了增加反爬难度,网站通常会对字体文件进行加密或混淆,使得爬虫无法直接解析。
🧾 为了应对这种反爬措施,爬虫可以采用以下方法:
- 下载字体文件并解析映射关系,从而获取需要显示的文字内容。
- 使用OCR技术对图片中的文字进行识别,从而获取需要显示的文字内容。
- 使用第三方库或工具对字体文件进行解密或混淆,从而获取需要显示的文字内容。
🔔🔔需要注意的是,字体反爬技术是一种比较高级的反爬措施,需要爬虫具备一定的技术水平才能应对。此外,爬虫在使用字体反爬技术时也需要注意遵守相关法律法规和网站的使用规定。
二·字体反爬模块Fonttools
安装Fonttools
pip install fonttools
如图所示,表示安装完成!
FontTools是一个开源的Python库,用于处理和转换字体文件。它可以读取和写入
OpenType(OTF)
和
TrueType(TTF)
字体文件,以及其他各种字体格式。FontTools可以用于许多用途。
例如:
字体编辑:可以使用FontTools来修改字体文件中的字形、轮廓、度量等属性。字体转换:可以将字体文件从一种格式转换为另一种格式,例如将TTF文件转换为OTF文件。字体分析:可以使用FontTools来分析字体文件中的元数据、字符集、度量等属性,以便于字体设计和排版。
TTF文件
🧾 🧾TTF文件是TrueType字体文件,是一种字体文件格式,通常用于在计算机和打印机上显示文本。它是一种可缩放的字体,可以在不失真的情况下进行缩放。TTF文件通常具有.ttf文件扩展名,可以在Windows、Mac和Linux等操作系统中使用。
三·FontCreator 14.0.0.2790
🧾 🧾 FontCreator 14.0.0.2790是一款专业的字体设计软件,由高级字体编辑器、字形插值器、字体转换器等多个工具组成。
- 它可以帮助用户创建自定义的字体,包括TrueType、OpenType、Web字体等多种格式。
- FontCreator14.0.0.2790提供了一个友好的用户界面,使得用户能够轻松地创建、编辑和修复字形、设置字符间距、调整字体度量等。
- 还支持多语言字体设计,用户可以添加和修改各种字符集。
- FontCreator 14.0.0.2790还可以进行字体转换,将不同格式的字体文件相互转换,方便用户在不同场景下使用。
FontCreatorPortable下载与安装

🎁🎁点击FontCreator 14.0.0.2790进入即可下载
提取码:a3e8
下载完成后是这样的:
打开需要查看的ttf文件
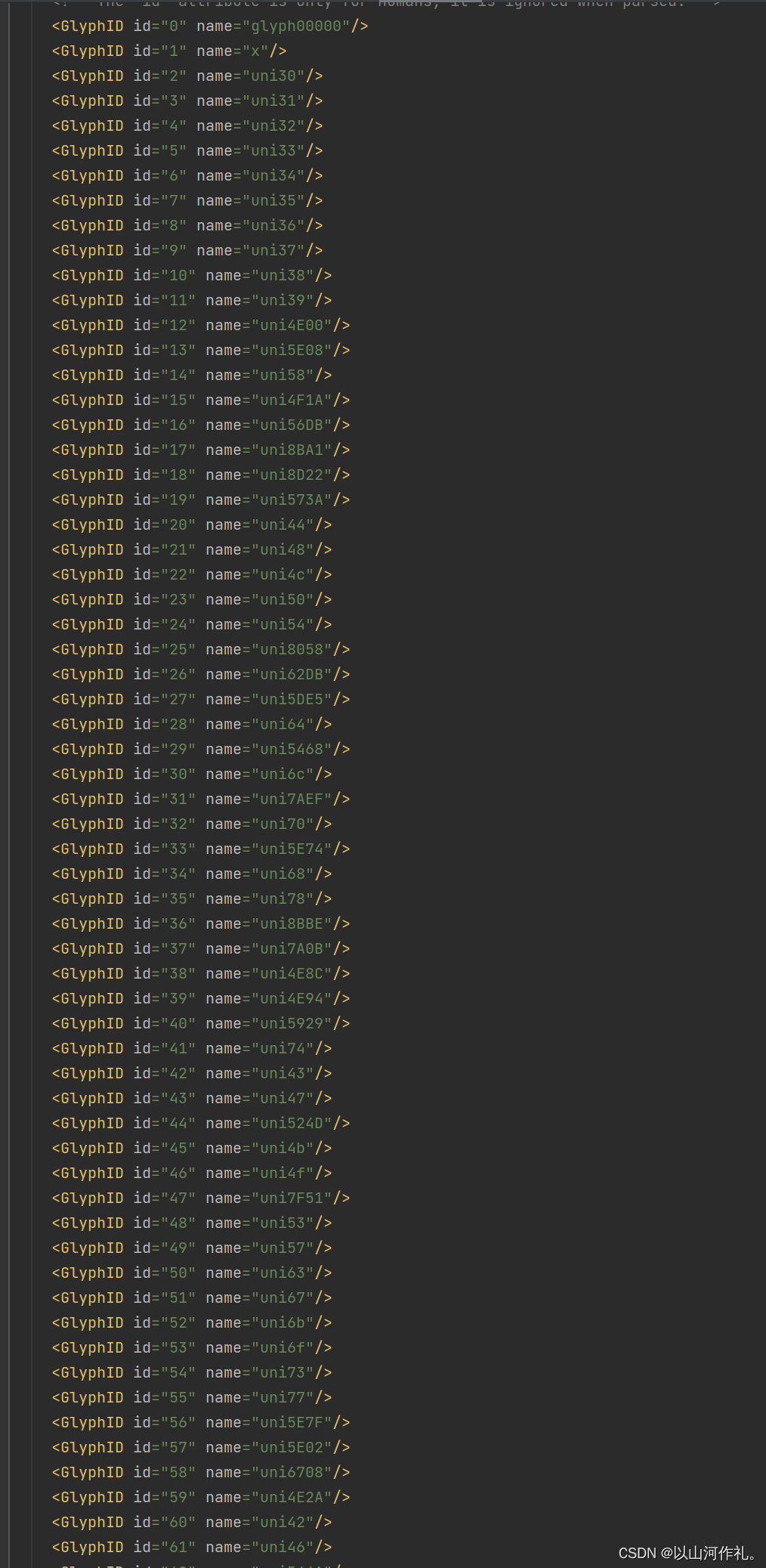
如图所示,被编码的文字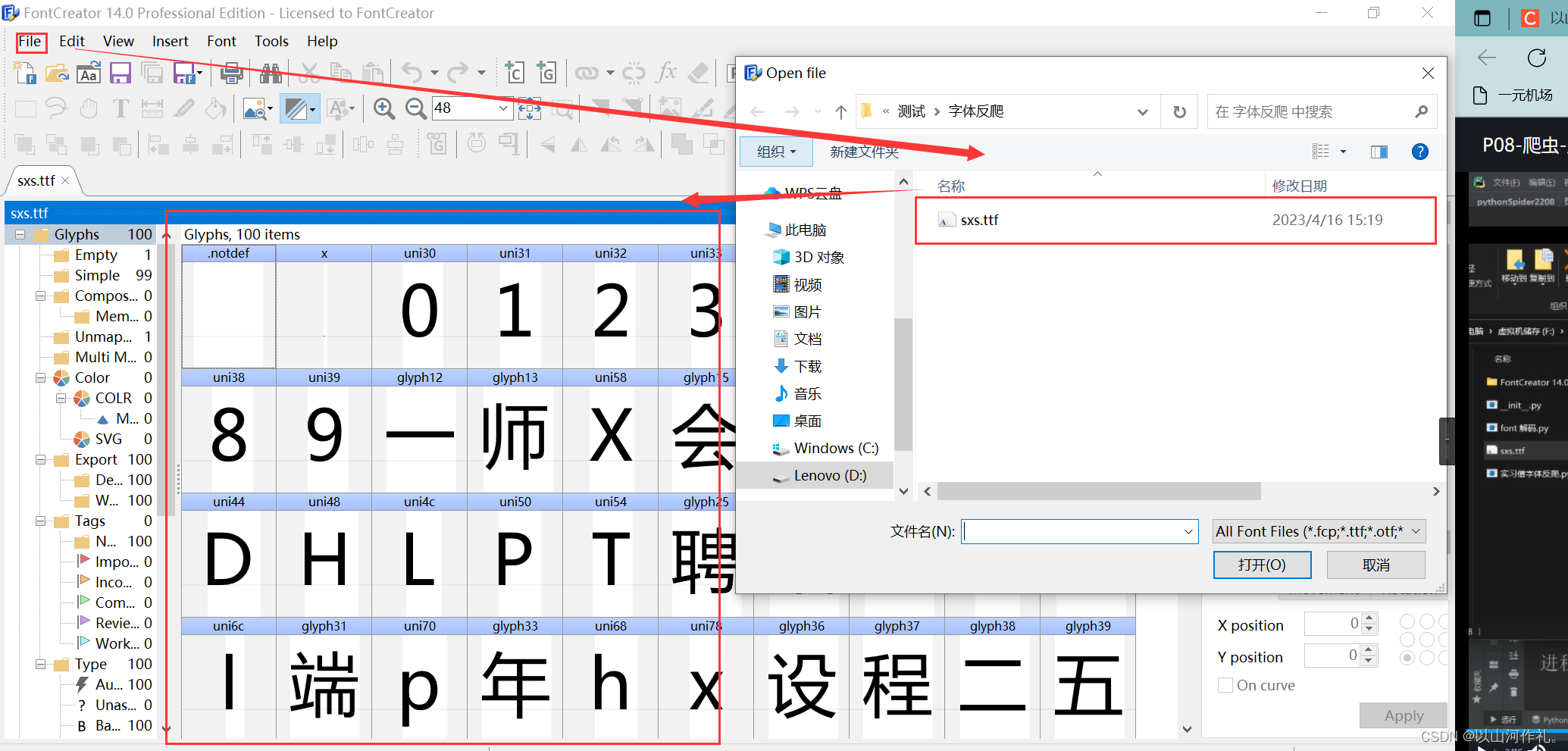
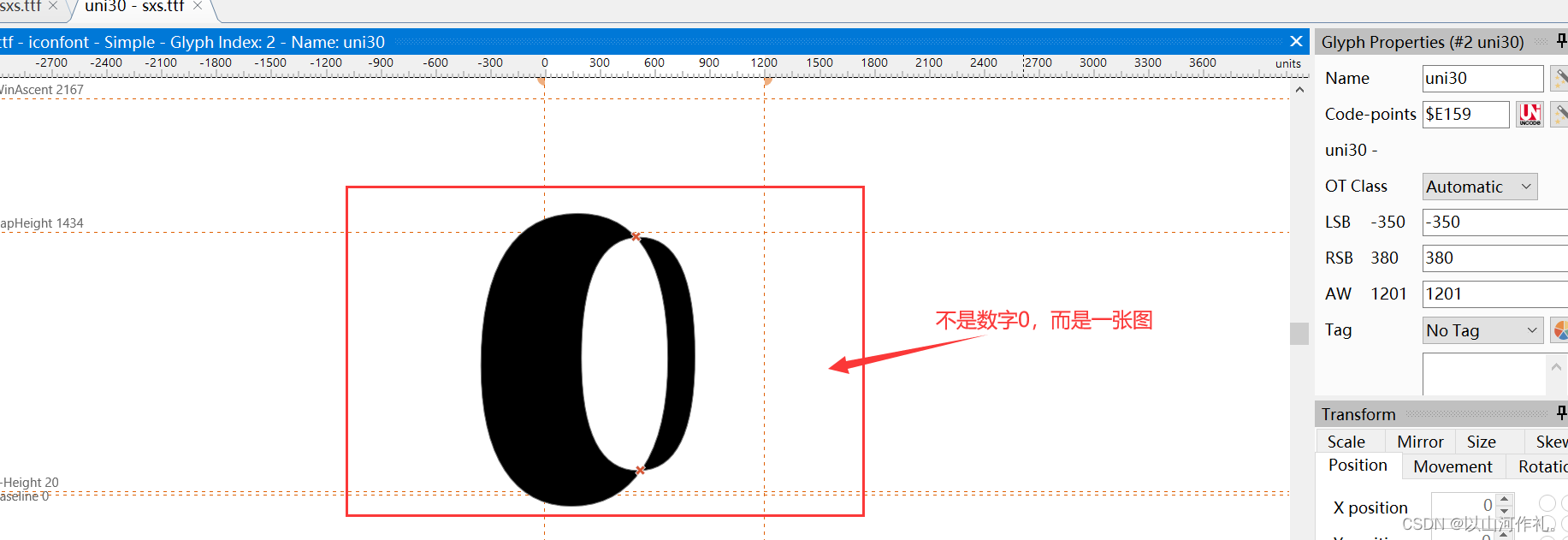
每一个编码对应一个图,对,下面这些0,1,2,3,4,5,6,7,这些对不是字体,而是一张图,所以在后续解码操作中,我们需要手动输入这些数据。
四·实战演示
🎯🎯本次实战以某招聘网站为目标,获取其中数据,并对字体加密进行破解操作
如图所示: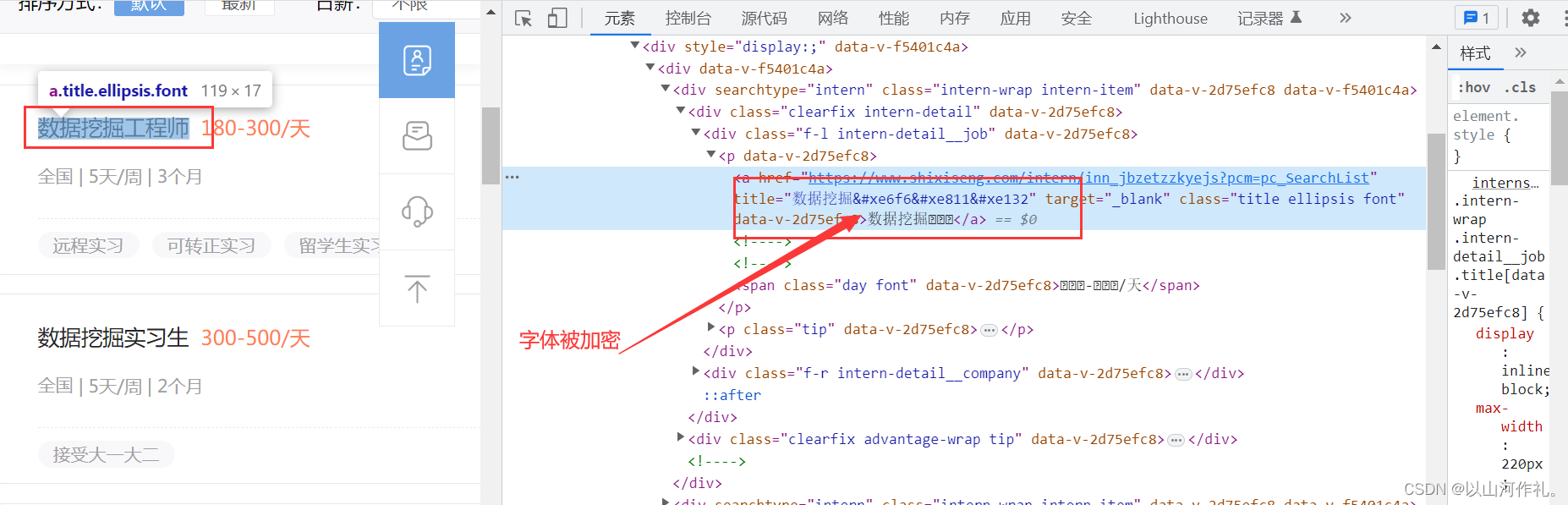
🎯我们想要爬取的数据被加密,我们来一步一步对其进行破解。
先按正常方式将数据获取到本地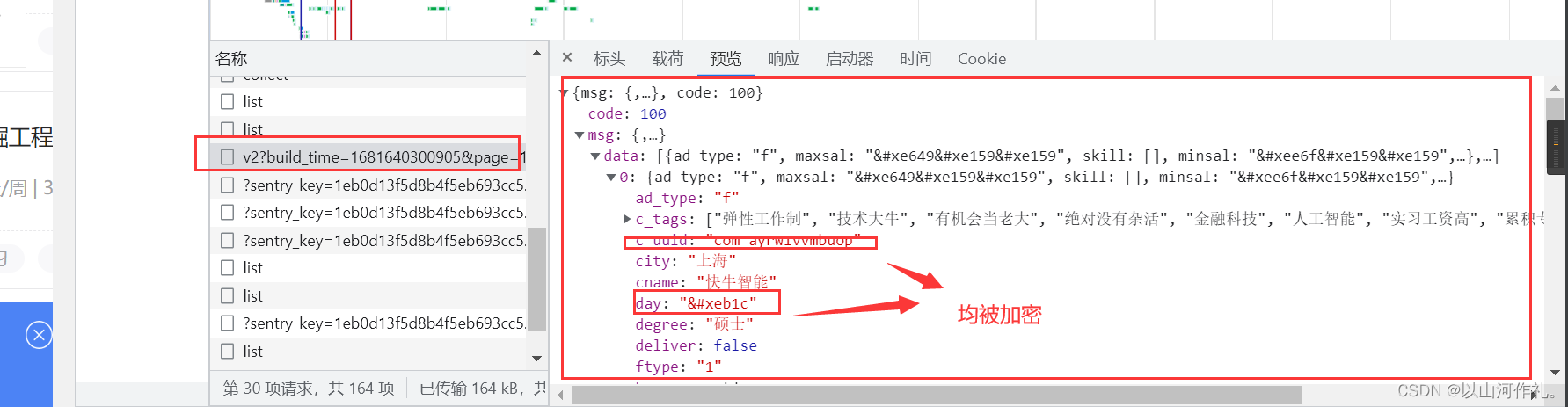
# coding = utf-8import crawles
url ='https://www.shixiseng.com/app/interns/search/v2'
cookies ={'RANGERS_WEB_ID':'7222273943993026082','RANGERS_SAMPLE':'0.797004667731563','adCloseOpen':'true','utm_source_first':'PC','Hm_lvt_03465902f492a43ee3eb3543d81eba55':'1681566719,1681626579','adClose':'true','SXS_XSESSION_ID':'\"2|1:0|10:1681626608|15:SXS_XSESSION_ID|48:ZmIzNDc2MDgtM2MxOS00ZGMzLTg1OWYtZjZmZjliODI3ODBm|e0c74e6e5b304e78720e68feddc1ebc596b09b541b03cab0ad8f542aa7782cf4\"','SXS_XSESSION_ID_EXP':'\"2|1:0|10:1681626608|19:SXS_XSESSION_ID_EXP|16:MTY4MTcxMzAwOA==|f0de0b3a4d7235bb497a86fab85289c792654792ec9114ede5cd4e213074f3ab\"','position':'pc_search_syss','utm_source':'PC','utm_campaign':'PC','Hm_lpvt_03465902f492a43ee3eb3543d81eba55':'1681640297',}
headers ={'authority':'www.shixiseng.com','accept':'application/json, text/plain, */*','accept-language':'zh-CN,zh;q=0.9','cache-control':'no-cache','content-type':'application/x-www-form-urlencoded','pragma':'no-cache','referer':'https://www.shixiseng.com/interns?page=2&type=intern&keyword=%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98&area&months&days°ree&official&enterprise&salary=-0&publishTime&sortType&city=%E5%85%A8%E5%9B%BD&internExtend','sec-ch-ua':'\"Chromium\";v=\"112\", \"Google Chrome\";v=\"112\", \"Not:A-Brand\";v=\"99\"','sec-ch-ua-mobile':'?0','sec-ch-ua-platform':'\"Windows\"','sec-fetch-dest':'empty','sec-fetch-mode':'cors','sec-fetch-site':'same-origin','user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',}
params ={'build_time':'1681640300905','page':'1','type':'intern','keyword':'数据挖掘','area':'','months':'','days':'','degree':'','official':'','enterprise':'','salary':'-0','publishTime':'','sortType':'','city':'全国','internExtend':'',}
response = crawles.get(url, headers=headers, params=params, cookies=cookies)
response = crawles.get(url, headers=headers, params=params, cookies=cookies)print(response.text)for i in response.json['msg']['data']:print(i)
🎯这是我们通过代码获取到本地的数据: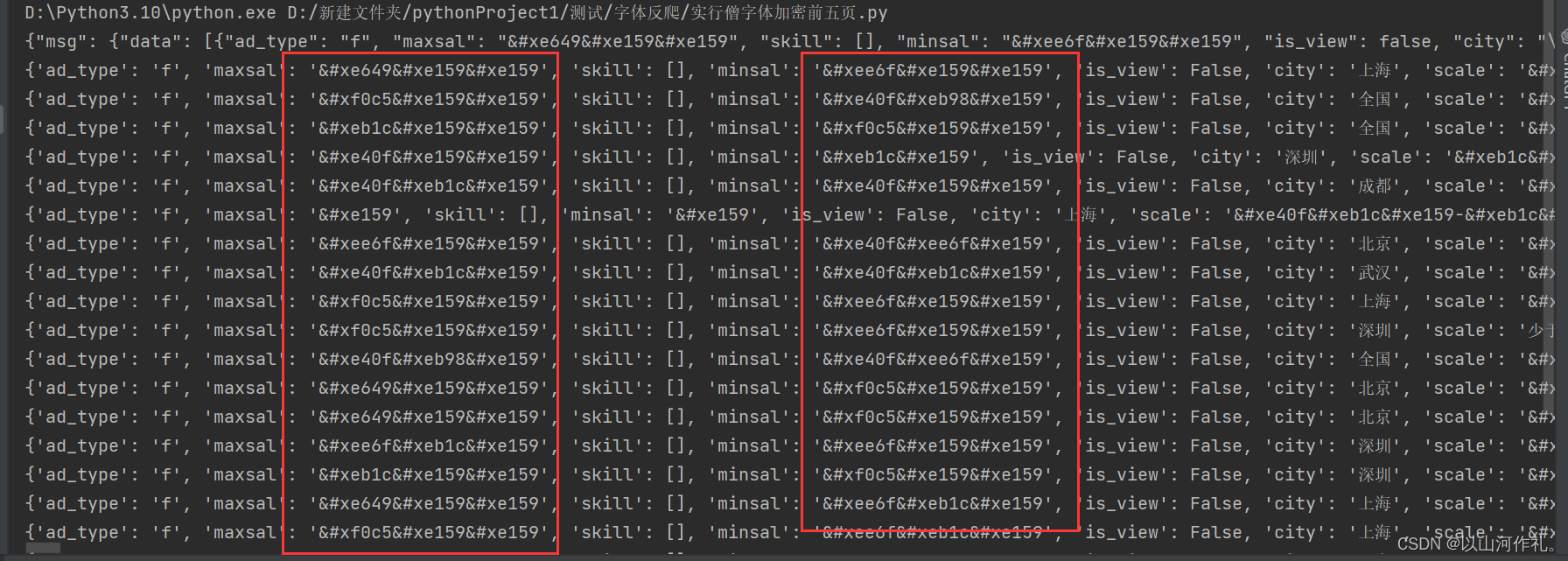
🎯接下来我们需要找到解密用的文件,在这里面找关于font的文件: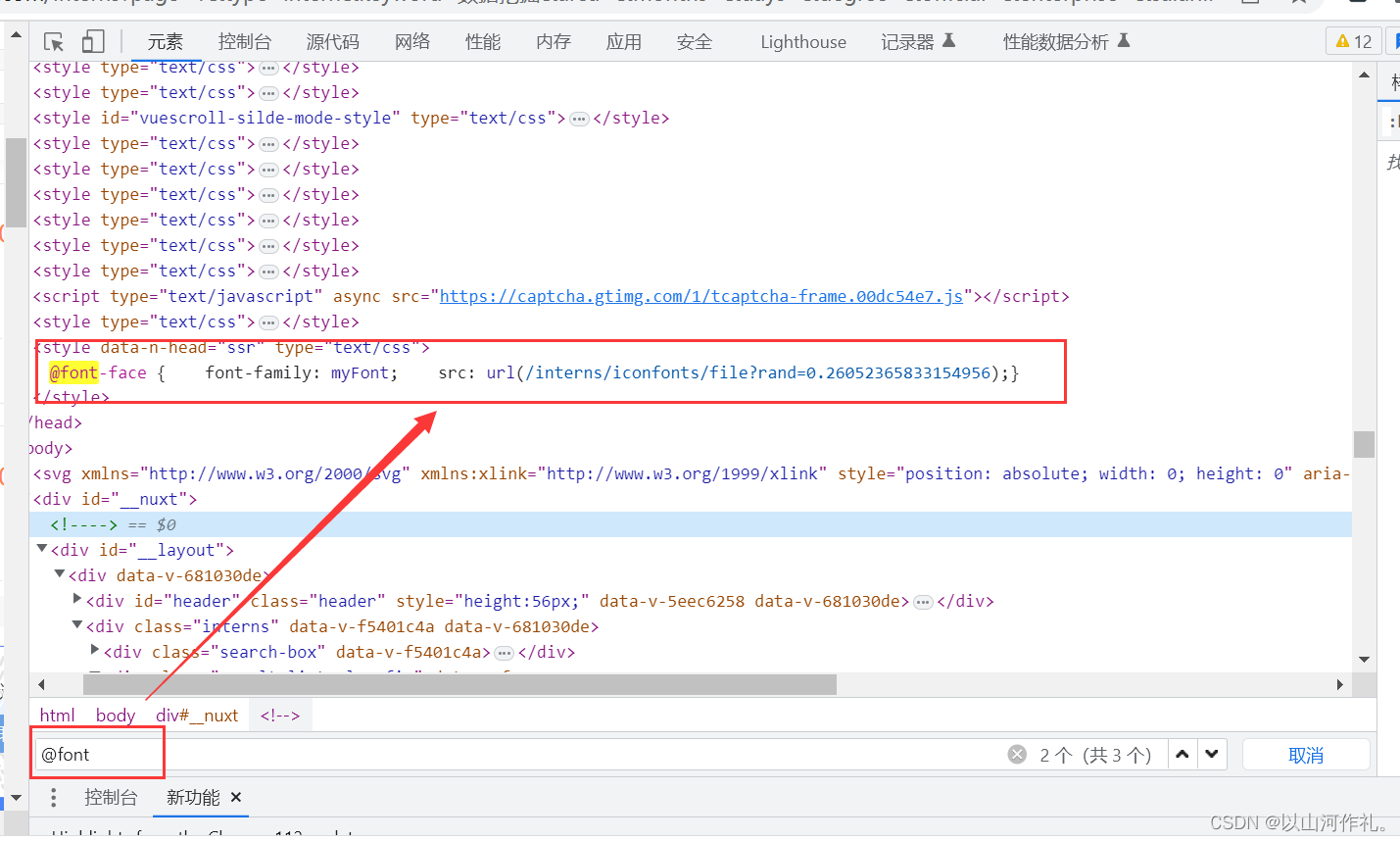
@font-face { font-family: myFont; src: url(/interns/iconfonts/file?rand=0.7027418610803815);}
🎯对获取的链接发起请求(获取字体文件,帮助我们对加密文件进行解码)
# font字体文件# 1,查找相关链接,或者文本# 2.获取文件(url) @font-face { font-family: myFont; src: url(/interns/iconfonts/file?rand=0.7027418610803815);}# 3.对获取的链接发起请求(获取字体文件,帮助我们对加密文件进行解码)# import requests
# 将请求到的数据存放到内存中,以便其他地方直接使用import io
from fontTools.ttLib import TTFont
font_file_uel ='https://www.shixiseng.com/interns/iconfonts/file'# 将请求到的数据存放到内存中,以便其他地方直接使用
ttf = TTFont(io.BytesIO(requests.get(font_file_uel).content))# 将获取的数据保存到ttf文件中
ttf.save('sxs.ttf')
🎯然后我们得到一个ttf文件,我们使用上面安装的软件对该文件进行查看。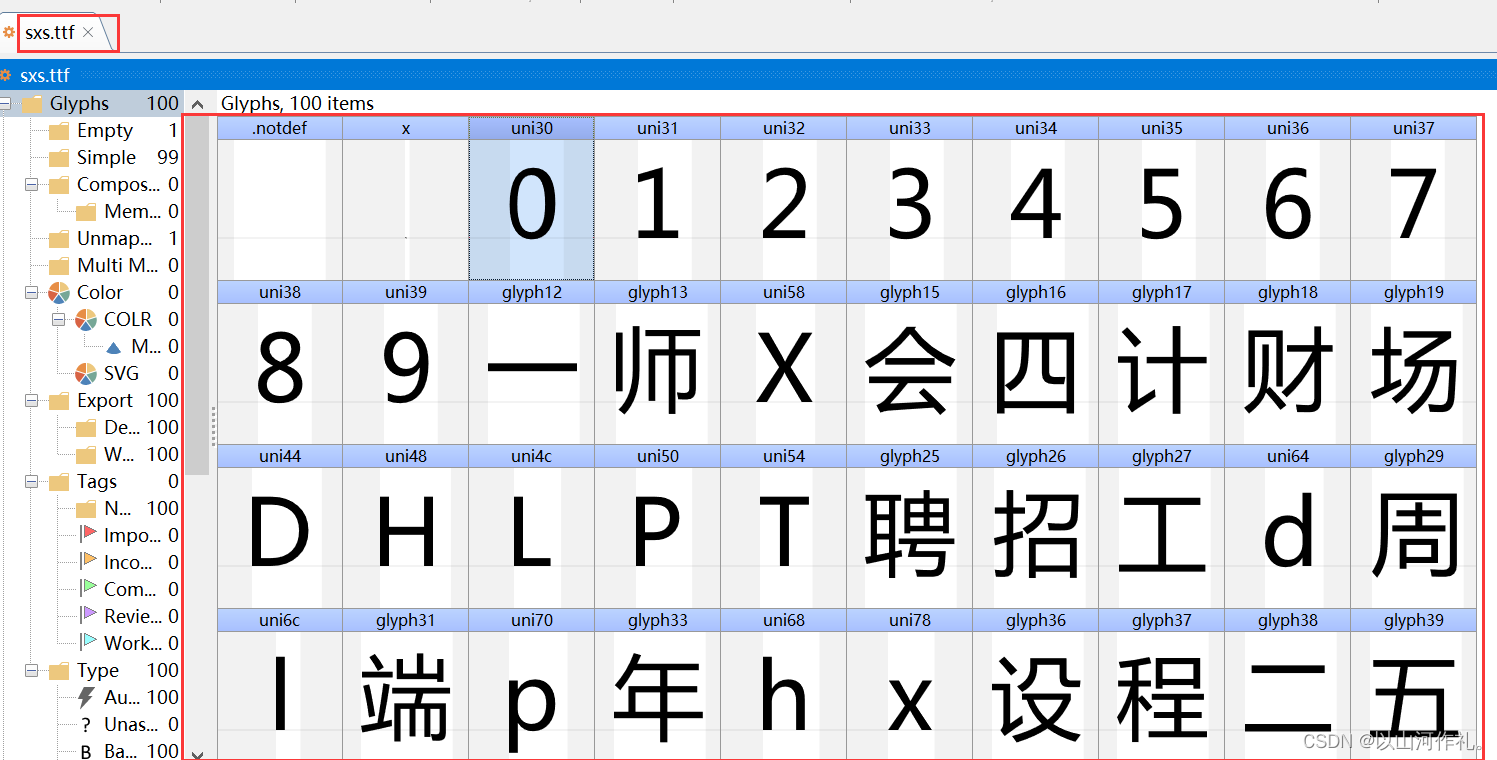
🎯我们将上述数据换成xml来查看,方便我们对其解码操作:
# font字体文件# 1,查找相关链接,或者文本# 2.获取文件(url) @font-face { font-family: myFont; src: url(/interns/iconfonts/file?rand=0.7027418610803815);}# 3.对获取的链接发起请求(获取字体文件,帮助我们对加密文件进行解码)# import requests
# 将请求到的数据存放到内存中,以便其他地方直接使用import io
from fontTools.ttLib import TTFont
font_file_uel ='https://www.shixiseng.com/interns/iconfonts/file'# 将请求到的数据存放到内存中,以便其他地方直接使用
ttf = TTFont(io.BytesIO(requests.get(font_file_uel).content))# 将获取的数据保存到ttf文件中# ttf.save('sxs.ttf')
ttf.saveXML('sxs.xml')
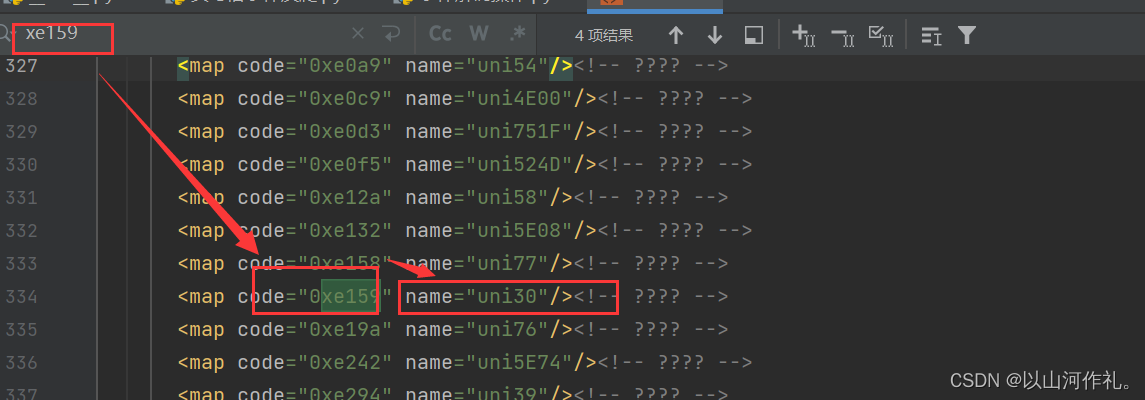
🎯我们的思路如下,将加密字体一步一步转成我们需要的字体,然后再获取出来:
 -> 0xe283 -> uni30 -> 数据索引 -> 文字
 -> 0xe714 -> uni35 -> 7 -> 5
import re
f =open('sxs.xml','r', encoding='utf-8')# 将数据读取出来
file_data = f.read()
f.close()
x = re.findall('<map code="0x(.*?)" name="(.*?)"/>', file_data)
glyph = re.findall('<GlyphID id="(.*?)" name="(.*?)"/>', file_data)
glyph_dict ={k: v for v, k in glyph}
str_data ='0123456789一师x会四计财场DHLPT聘招工d周L端p年hx设程二五天tXG前KO网SWcgkosw广市月个BF告NRVZ作bfjnrvz三互生人政AJEI件M行QUYaeim软qu银y联'
str_list =[' ','']+[i for i in str_data]
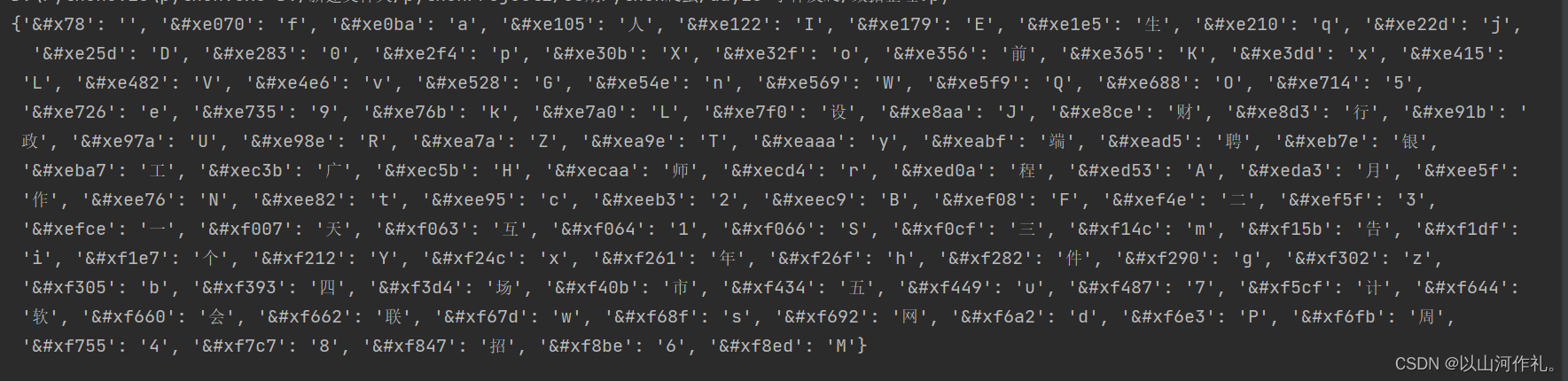
x_dict ={f'&#x{k}': str_list[int(glyph_dict[v])]for k, v in x}print(x_dict)
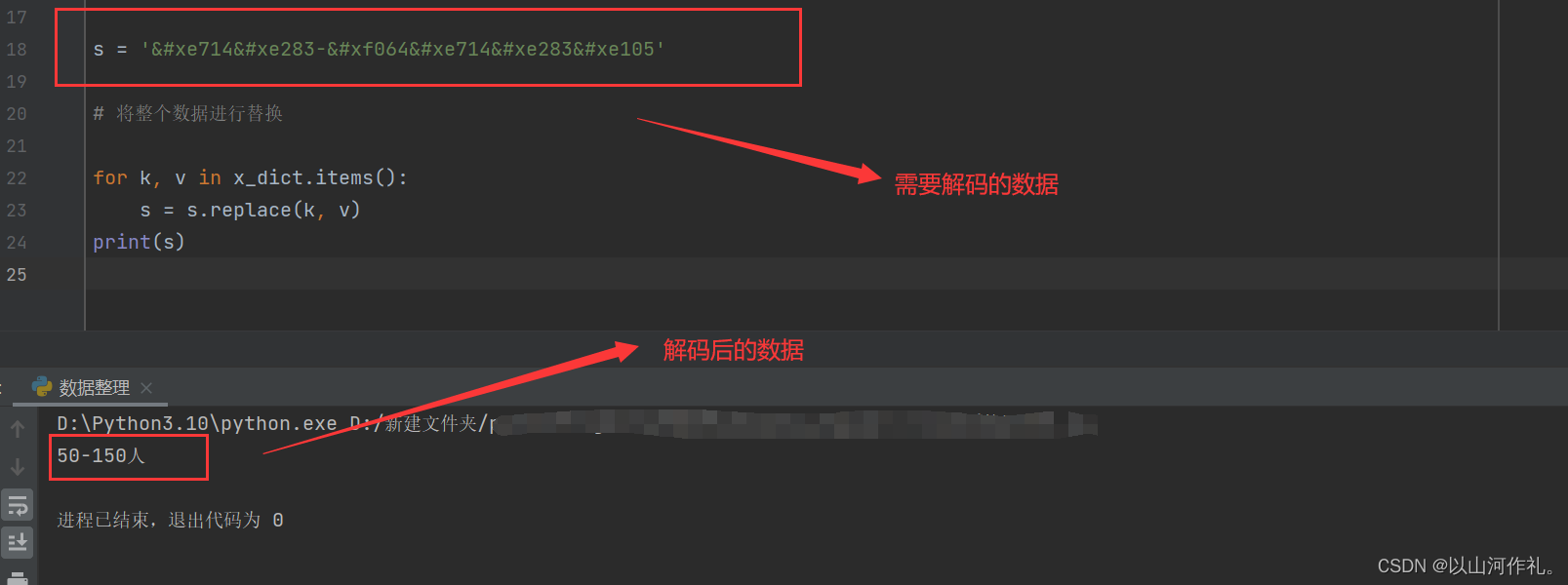
🎯如上图所示,我们解密了一部分字体来展示如何操作,现在对整个网页的加密数据进行字体解密操作,解密后的数据如图所示,我们对有用的数据进行整理: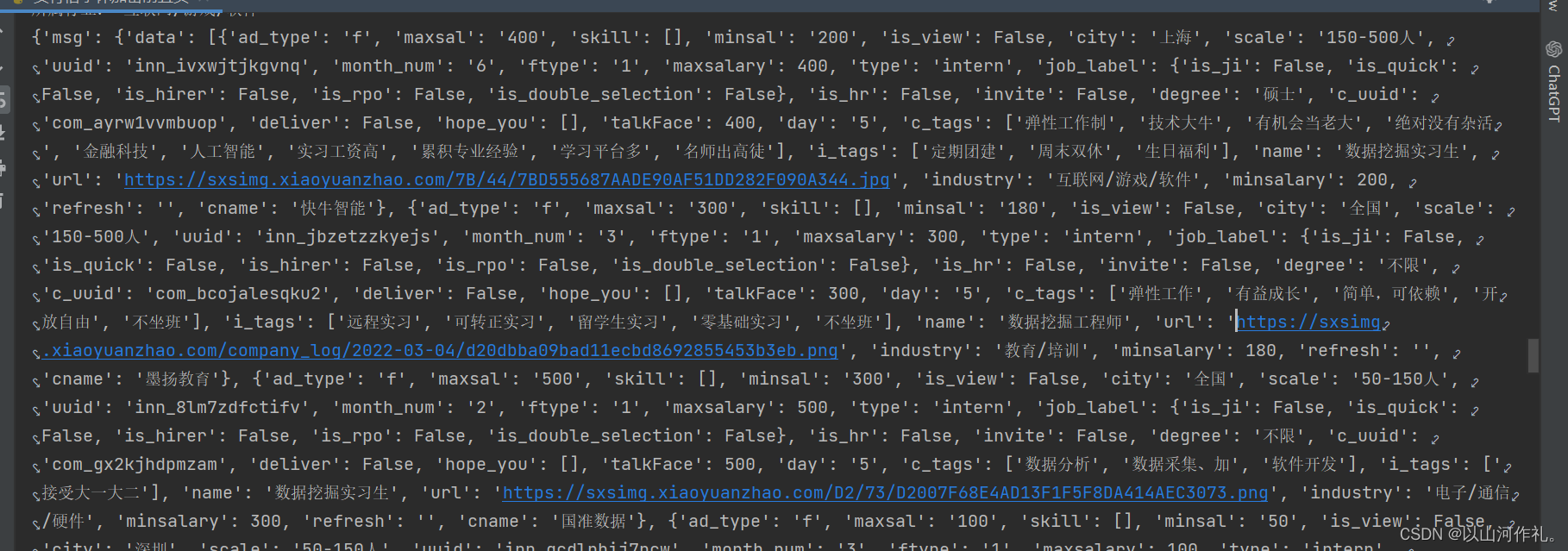
🎯整理后的数据如下: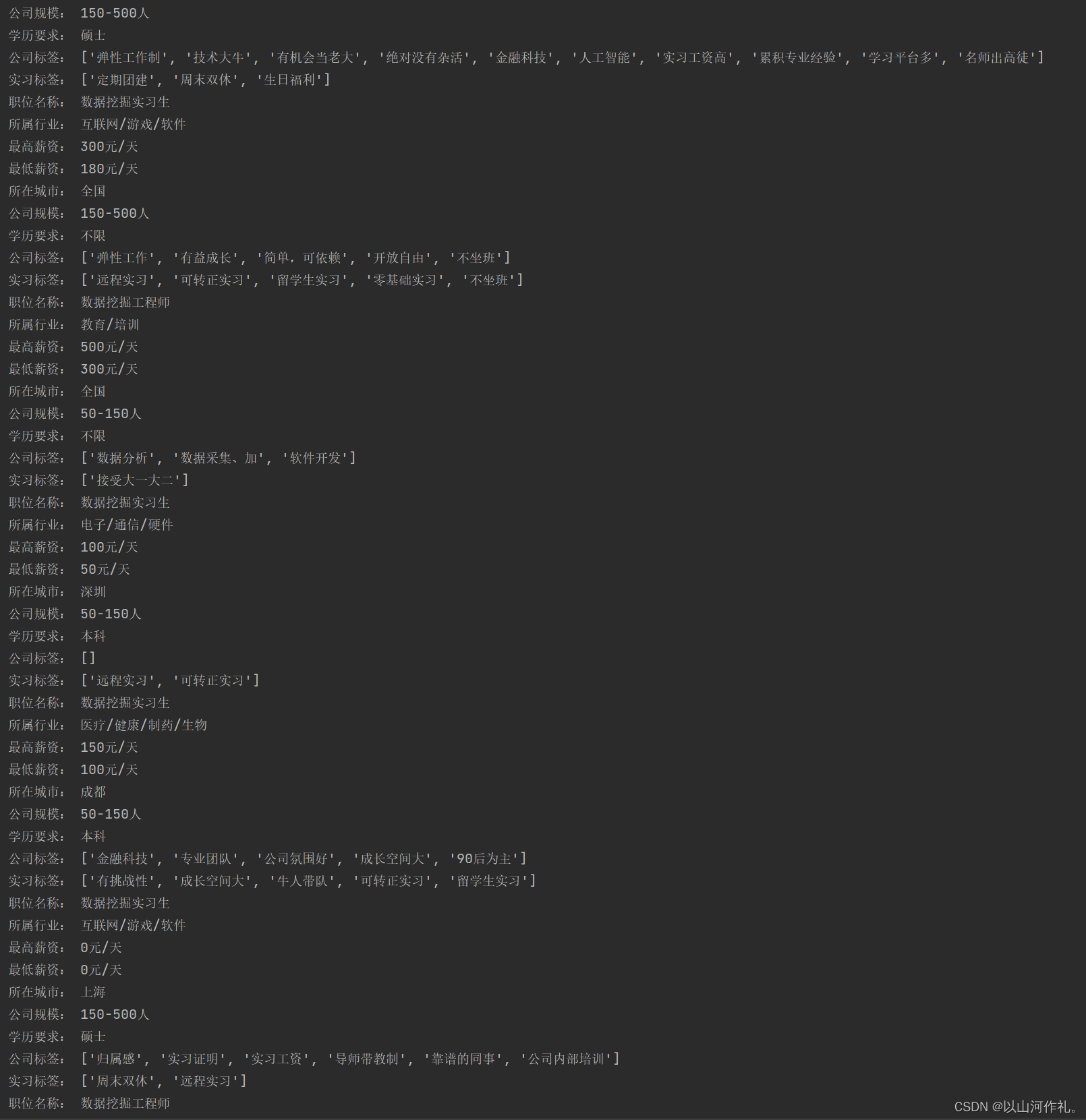
🎁🎁完整代码:
import crawles
import json
import re
import requests
import io
from fontTools.ttLib import TTFont # pip install fonttools
url ='https://www.shixiseng.com/app/interns/search/v2'
cookies ={'RANGERS_WEB_ID':'7222273943993026082','RANGERS_SAMPLE':'0.797004667731563','adCloseOpen':'true','utm_source_first':'PC','Hm_lvt_03465902f492a43ee3eb3543d81eba55':'1681566719,1681626579','adClose':'true','SXS_XSESSION_ID':'\"2|1:0|10:1681626608|15:SXS_XSESSION_ID|48:ZmIzNDc2MDgtM2MxOS00ZGMzLTg1OWYtZjZmZjliODI3ODBm|e0c74e6e5b304e78720e68feddc1ebc596b09b541b03cab0ad8f542aa7782cf4\"','SXS_XSESSION_ID_EXP':'\"2|1:0|10:1681626608|19:SXS_XSESSION_ID_EXP|16:MTY4MTcxMzAwOA==|f0de0b3a4d7235bb497a86fab85289c792654792ec9114ede5cd4e213074f3ab\"','position':'pc_search_syss','utm_source':'PC','utm_campaign':'PC','Hm_lpvt_03465902f492a43ee3eb3543d81eba55':'1681640297',}
headers ={'authority':'www.shixiseng.com','accept':'application/json, text/plain, */*','accept-language':'zh-CN,zh;q=0.9','cache-control':'no-cache','content-type':'application/x-www-form-urlencoded','pragma':'no-cache','referer':'https://www.shixiseng.com/interns?page=2&type=intern&keyword=%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98&area&months&days°ree&official&enterprise&salary=-0&publishTime&sortType&city=%E5%85%A8%E5%9B%BD&internExtend','sec-ch-ua':'\"Chromium\";v=\"112\", \"Google Chrome\";v=\"112\", \"Not:A-Brand\";v=\"99\"','sec-ch-ua-mobile':'?0','sec-ch-ua-platform':'\"Windows\"','sec-fetch-dest':'empty','sec-fetch-mode':'cors','sec-fetch-site':'same-origin','user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',}
params ={'build_time':'1681640300905','page':'1','type':'intern','keyword':'数据挖掘','area':'','months':'','days':'','degree':'','official':'','enterprise':'','salary':'-0','publishTime':'','sortType':'','city':'全国','internExtend':'',}
response = crawles.get(url, headers=headers, params=params, cookies=cookies)
text = response.text
# 存储ttf文件 用于分析和后续操作
font_file_uel ='https://www.shixiseng.com/interns/iconfonts/file'# 将请求到的数据存放到内存中,以便其他地方直接使用
ttf = TTFont(io.BytesIO(requests.get(font_file_uel).content))# ttf.save('sxs.ttf')
ttf.saveXML('sxs.xml')# 读取xml文件
f =open('sxs.xml','r', encoding='utf-8')
file_data = f.read()
f.close()
x = re.findall('<map code="0x(.*?)" name="(.*?)"/>', file_data)
glyph = re.findall('<GlyphID id="(.*?)" name="(.*?)"/>', file_data)
glyph_dict ={k: v for v, k in glyph}
str_data ='0123456789一师x会四计财场DHLPT聘招工d周L端p年hx设程二五天tXG前KO网SWcgkosw广市月个BF告NRVZ作bfjnrvz三互生人政AJEI件M行QUYaeim软qu银y联'
str_list =[' ','']+[i for i in str_data]
x_dict ={f'&#x{k}': str_list[int(glyph_dict[v])]for k, v in x}# print(x_dict)# 对整个文本数据进行替换解码操作for k, v in x_dict.items():
text = text.replace(k, v)# 将数据转化回方便使用的格式
text_1 = json.loads(text)for item in text_1['msg']['data']:
max_salary = item['maxsal']+'元/天'# 最高薪资
min_salary = item['minsal']+'元/天'# 最低薪资
city = item['city']# 所在城市
scale = item['scale']# 公司规模
degree = item['degree']# 学历要求
c_tags = item['c_tags']# 公司标签
i_tags = item['i_tags']# 实习标签
name = item['name']# 职位名称
industry = item['industry']# 所属行业print('最高薪资:', max_salary)print('最低薪资:', min_salary)print('所在城市:', city)print('公司规模:', scale)print('学历要求:', degree)print('公司标签:', c_tags)print('实习标签:', i_tags)print('职位名称:', name)print('所属行业:', industry)print(text_1)
五·后记
👉👉本专栏所有文章是博主学习笔记,仅供学习使用,爬虫只是一种技术,希望学习过的人能正确使用它。
博主也会定时一周三更爬虫相关技术更大家系统学习,如有问题,可以私信我,没有回,那我可能在上课或者睡觉,写作不易,感谢大家的支持!!🌹🌹🌹
版权归原作者 以山河作礼。 所有, 如有侵权,请联系我们删除。