
背景:目前国内有大量的公司都在使用 Elasticsearch,包括阿里、京东、滴滴、今日头条、小米、vivo等诸多知名公司。除了搜索功能之外,Elasticsearch还结合Kibana、Logstash、Elastic Stack还被广泛运用在大数据近实时分析领域,包括日志分析、指标监控等多个领域。
欢迎加入老王的成长社区,我们一起进步
本节内容:一张图让你读懂ElasticSearch强大的搜索能力。
说明:以下源码及流程图基于Elasticsearch 7.X, 其它版本类似。
1、 ElasticSearch搜索操作(Java版)
为了更好地说明Elasticsearch搜索的原理,我们先来看下客户端查询操作代码及搜索流程。具体实战案例参考老王前面的文章 Elasticsearch 7.X增删改查实战
/**
* 搜索
* @param indexName
* @throws IOException
*/
public static void search(String indexName) throws IOException {
SearchRequest request = new SearchRequest(indexName);
//构建搜索条件
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.termQuery("name", "test")); // term
builder.sort("createTime", SortOrder.DESC);
builder.timeout(new TimeValue(60, TimeUnit.SECONDS));
request.source(builder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT); //搜索
System.out.println(JSON.toJSONString(response.getHits()));
for (SearchHit hit : response.getHits().getHits()) {
System.out.println(hit.getSourceAsMap());
}
}
在发起查询请求时,我们通常会传入一些查询过滤参数,这些参数可能需要:精确匹配、前缀匹配或后缀匹配。那这些不同的搜索条件Elasticsearch是如何快速搜索的呢?
2、ElasticSearch分布式搜索流程
如果对ES整体架构不太了解的朋友,可以先看下前面的两篇文章,能有助于大家理解本篇内容。
Elasticsearch架构及模块功能介绍
ElasticSearch写操作—原理及近实时性分析(完整版)
2.1 搜索源码概览
2.1.1 定位有效节点
/**
* 查找可用节点
*/
private NodeTuple<Iterator<Node>> nextNodes() throws IOException {
NodeTuple<List<Node>> tuple = this.nodeTuple;
Iterable<Node> hosts = selectNodes(tuple, blacklist, lastNodeIndex, nodeSelector);
return new NodeTuple<>(hosts.iterator(), tuple.authCache);
}
主要查询当前集群有哪些可用节点,过滤掉黑名单和无权限的节点,便于搜索时能直接根据有效节点进行数据搜索。
2.1.2 遍历节点及并行搜索
/**
* @param tuple 遍历节点
* @param request 请求参数
* @param previousException
* @return
* @throws IOException
*/
private Response performRequest(final NodeTuple<Iterator<Node>> tuple,
final InternalRequest request,
Exception previousException)
throws IOException {
RequestContext context = request.createContextForNextAttempt(tuple.nodes.next(), tuple.authCache);
HttpResponse httpResponse;
try {
// 真正执行搜索操作的位置- asyncResponseConsumer为异步查询
httpResponse = client.execute(context.requestProducer,
context.asyncResponseConsumer,
context.context, null)
.get();// 异步获取结果
} catch (Exception e) {
//... 忽略多余代码
}
ResponseOrResponseException responseOrResponseException = convertResponse(request, context.node, httpResponse);
if (responseOrResponseException.responseException == null) {
return responseOrResponseException.response;
}
addSuppressedException(previousException, responseOrResponseException.responseException);
if (tuple.nodes.hasNext()) { //循环迭代node
// 递归调用 performRequest 函数
return performRequest(tuple,
request,
responseOrResponseException.responseException);
}
throw responseOrResponseException.responseException;
}
该步骤主要针对可用节点进行依次循环,循环内部为异步从服务端获取数据。
public <T> Future<T> execute(HttpAsyncRequestProducer requestProducer,
HttpAsyncResponseConsumer<T> responseConsumer,
HttpContext context,
FutureCallback<T> callback) {
this.ensureRunning();
BasicFuture<T> future = new BasicFuture(callback);
HttpClientContext localcontext = HttpClientContext.adapt
((HttpContext)(context != null ? context : new BasicHttpContext()));
// DefaultClientExchangeHandlerImpl
// MinimalClientExchangeHandlerImpl
try {
handler.start();
} catch (Exception var9) {
handler.failed(var9);
}
return new FutureWrapper(future, handler);//异步获取结果
}
通过异步方式,对Quesry Response结果进行排序合并后,将最终结果返回到客户端。
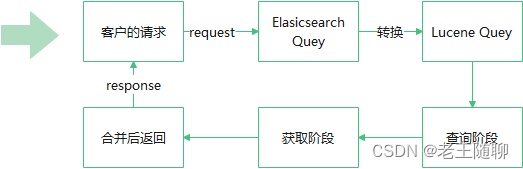
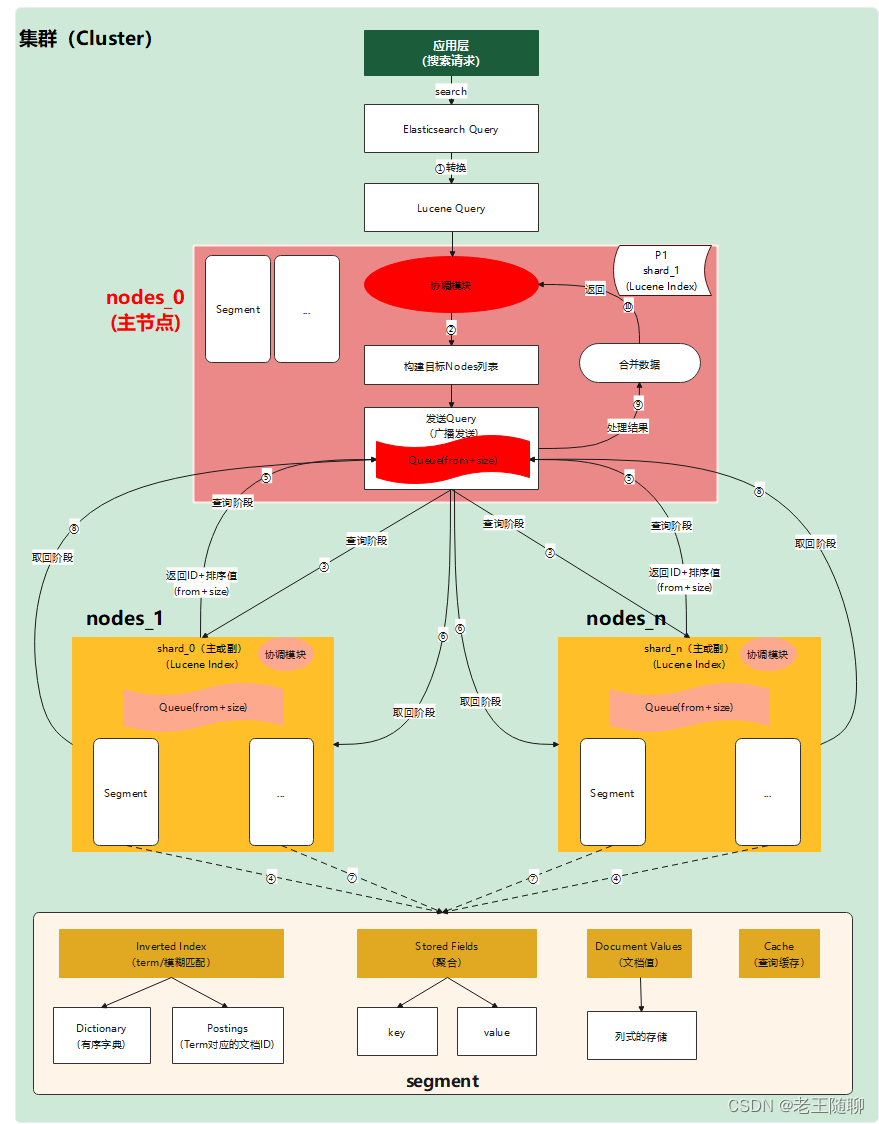
2.2 搜索核心流程全景图
2.3 核心模块执行流程
2.3.1 Elasticsearch转Lucene操作 ①
我们知道, Elasticsearch是基于Lucene底座基础之上做了很多封装,老王在前面文章ElasticSearch—解答最近网友提问的四个问题 提到过关于Elasticsearch和Lucene的区别。由于Lucene底层操作比较复杂,对于很多人来说上手难。因此Elasticsearch专门为我们抽象出了一套基于JSON的RESTFulAPI 来便捷的调用Lucene功能, 可以理解为是对Lucene更进一层的封装。
因此,在实际搜索之前,需要将用户传入的ES 查询API 转换为Lucene的查询API。即Elasticsearch Query转 Lucene Query。(具体API会在后面的文章会讲到)
2.3.2 构建目标Nodes列表 ②
首先,我们需要知道为什么要构建Nodes列表?
在发起请求之前,需要知道哪些节点是可用的,哪些节点是有权限。因为在实际生产当中,节点可能会出现异常或者权限控制。所以需要对可用节点进行过滤。
其次,为什么不直接找主节点呢?
我们知道Node是由多个Shard组成的,而Shard存在主分片和副本分片。一版生产环境中主副分片是不在同一台机器上,这样做是解决单台机器出现故障的情况下数据不丢失问题。所以,我们需要的数据在其他节点上也会存在它的副本。因此,只需要找到其中一个主搜索节点A(不一定是主节点)做协调节点,其余节点做分查询即可。
最后,主搜索节点A查询完可用节点后,接着会构建出一个长度为from+size的优先队列,这个队列用于存储各节点返回数据列表。然后,通过广播模式将请求信息分发到所有可用节点,等待数据返回。
2.3.3 查询阶段文档ID和排序值获取 ③ ④
各节点接收到主搜索节点A发送过来的请求,在自己内部的segment中进行搜索。其中,每个节点内部也会维护一个from+size大小的优先队列,用于存放本身查询的结果数据集。关于Segment的各个组成要素及作用可以看看前面的文章 Lucene Segment的作用是什么 这里需要重点说一下Segment为什么只获取查询文档ID和排序值以及如何生成这个排序值。
1)为什么只获取查询文档ID和排序值
这里面主要考虑数据传输过大的性能问题,如果是已知搜索文档ID,即可以通过Elasticsearch的路由机制快速定位到存储该数据的任一分片副本;如果是非已知搜索文档,则需要根据过滤条件搜索所有节点。这就会导致整个查询数据量会比较庞大,特别是在from+size比较大的情况下更为明显。
2)如何生成这个排序值
其中sort值为数组,支持多字段排序。比如时间维度递减或地递增排序,sort会记录每个ID的日期值。
3)单分片如何提升查询性能
当词条数量较少时,可以顺序遍历词条获取结果,但如果词条有成千上万个时,Elasticsearch为了能快速找到某个词条,它对所有的词条都进行了排序,随后使用二分法查找词条,其查找效率为log(N)。此处排序词条的集合也称为Term Dictionary。
为了提高查询性能,Elasticsearch直接通过内存查找词条,而并不是从磁盘中直接读取。如果词条太多,显然Term Dictionary也会很大,此时全部放在内存有些不现实,于是引入了Term Index。
Term Index就像字典中的索引页,其中的内容如字母A开头的有哪些词条,以及这些词条分别在哪个页。通过Term Index,Elasticsearch也可以快速定位到Term Dictionary的某个OffSet(位置偏移),然后从这个位置再往后顺序查找。
2.3.4 查询Query阶段返回处理 ⑤
每个分片返回本地优先级序列中所记录的ID与sort值,并发送给节点A。节点A将这些值合并到自己的本地优先级队列中,并做出全局的排序。
2.3.5 取回Fetch阶段请求 ⑥
根据⑤最终的排序结果,再次发起Featch请求。比如此时找出最终排序的from起的size条数据,此时请求参数胡会携带ID值。
2.3.6 根据索引ID查询对应文档数据 ⑦
根据文档ID, 通过Elasticsearch的路由机制可快速定位到存储该数据的任一分片,从而达到快速查询的效果。
2.3.7 对整体结果集处理 ⑧ ⑨ ⑩
请求节点将来自所有分片的数据做合并处理,并在请求节点上进行排序,文档被按照查询要求进行选择。最终,实际文档从它们各自所在的独立的分片上被检索出来,最终将结果返回给客户端。
3、分布式搜索性能高的原因总结
从以上流程中,我们可以大致推断出影响Elasticsearch搜索性能的一些因素。
3.1 写入对读的影响比较小
数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中。只要buffer中的数据被refresh到os cache中,数据就可以被检索到了。因此,存储和实际查询的区域互不影响。而且是基于内存检索,加速查询效率。
3.2 广播式查询提升并发性能
主搜索节点通过广播模式向各节点发起请求,这样会让多核节点并行执行,大大提升了查询性能。
3.3 Query阶段数据量传输相对较少
从前面的查询阶段了解到,该步骤仅返回查询文档ID和排序值,而没有把所有文档数据返回,这样避免了因数据量过大而导致查询性能下降。更为重要的是,这个过程当中会用到倒排索引,必然进一步加速了查询性能。
3.4 Fetch阶段请求前逻辑优化
这一步主要是对各节点返回的数据进行重新排序,比如分页,只查询当前页需要的数据即可,这样也进一步减少了无效数据量的传输。
3.5 Fetch阶段索引快
fetch阶段传入,请求参数文档ID根据路由规则直接计算出对应数据存储的分片,从而避免了全节点检索的效率问题。
版权归原作者 老王随聊 所有, 如有侵权,请联系我们删除。