
软件对国家的全球竞争力、创新和国家安全至关重要。它还确保了我们的现代生活水平,并使国防、基础设施、医疗保健、商业、教育和娱乐不断进步。卡内基梅隆大学软件工程研究所领导社区创建了这样一个多年研发愿景和路线图,用于设计下一代软件系统。
基于软件的性质,它在能力、复杂性和互连方面在持续无限制的增长。软件的发展似乎没有停滞不前。为了使未来的软件系统安全、可预测和可进化,软件工程界必须共同努力,从战略上推进软件工程的理论和实践,以实现下一代软件依赖系统。

1. 介绍
我们生活在一个由软件驱动的变革时代。在过去的半个世纪里,软件已经深深地与我们的个人生活交织在一起,对国家的全球竞争力、创新和国家安全是至关重要的。随着社会赋予了软件越来越复杂和关键的功能,我们对未来软件系统的依赖将持续增加,但系统的构建和维护会变得更加复杂,而软件工程是负责构建和维护这些普及软件系统的学科。
软件工程应用了必要的理论、工具和实践,从而能够交付和维护功能强大、可靠、及时且价格合理的软件系统。随着系统不断发展,几乎可以肯定,新类型的系统将超越当前软件工程的界限。我们将无法充分地开发和维护未来的软件系统,除非进行适当的研究,以克服新趋势和软件技术中固有的工程问题。软件提供了无限的潜力,但只有通过软件工程的进步才能实现。
1.1 软件赋能与创新
软件为现代生活中的许多重要活动提供了能力。它使我们的手机、汽车、医疗设备等功能更加强大。软件也有助于创新。例如,在如今的汽车中,几乎每一个部件都连接到了一台中央计算机,数百万行代码实现了我们期望的所有功能。
软件是一切,一切皆为软件。软件将决策者与数据联系起来,改善了货物对客户的流向,并实现了全球通信。我们可以通过软件支持的社交网络与远隔重洋的朋友和家人联系。我们可以很容易地获得石油、天然气和电力,因为软件可以管理这些资源通过管道和电网的流量。多亏了软件,使我们认为这些和其他重要商品一样出现在日常生活中是理所当然的。
1.2 软件是阿喀琉斯之踵
虽然软件是一个社会日益依赖的使能器,但也使我们容易受到其弱点的影响。例如,最近的软件质量问题的一个漏洞,导致黑客访问了数十亿个人、公司和政府办公室的数据[Tunggal,2021]。软件漏洞还导致了美国历史上最大规模的一条输油管道关闭,攻击导致了多个州数百家企业[Satter 2021]的瘫痪。软件质量问题已经导致了飞机上的旅客丧生、空间飞行行业中的事故、车祸等昂贵的故障[Rhee 2020;CBS 2010]。事实上,根据信息和软件质量联合会(CISQ)[Krasner,2021]的数据,2020年在美国,由于软件质量问题导致的总成本为2.08万亿美元。
1.3 软件是关键安全系统的脊梁
许多跨国公司正在面对软件工程工作未达到其系统所要求的质量水平时出现的严重故障。例如,一项重大太空计划一直受到设计错误、软件错误和质量保证实践问题的困扰[Pasztor,2021]。这些问题的根本原因,是缺乏软件工程领导力和纪律[McFall-Johnsen 2020]。在这些挑战中,并非只有物理空间上的举措。例如,过去十年中,与几种不同汽车软件相关的非预期加速被认为与许多人的死亡有关,汽车制动控制的其他问题可追溯到有问题和质量差的软件[Mitchell 2010]。
1.4 软件通常依赖于复杂的供应链
现代软件供应链通常包括大量的利益相关者,他们对软件产品的内容做出贡献或有机会进行修改。因此,整个供应链是生态系统的重要组成部分,在考虑软件质量时必须考虑到这一点。(参见图1,了解美国国防部系统供应链中可能存在的复杂关系示例。)
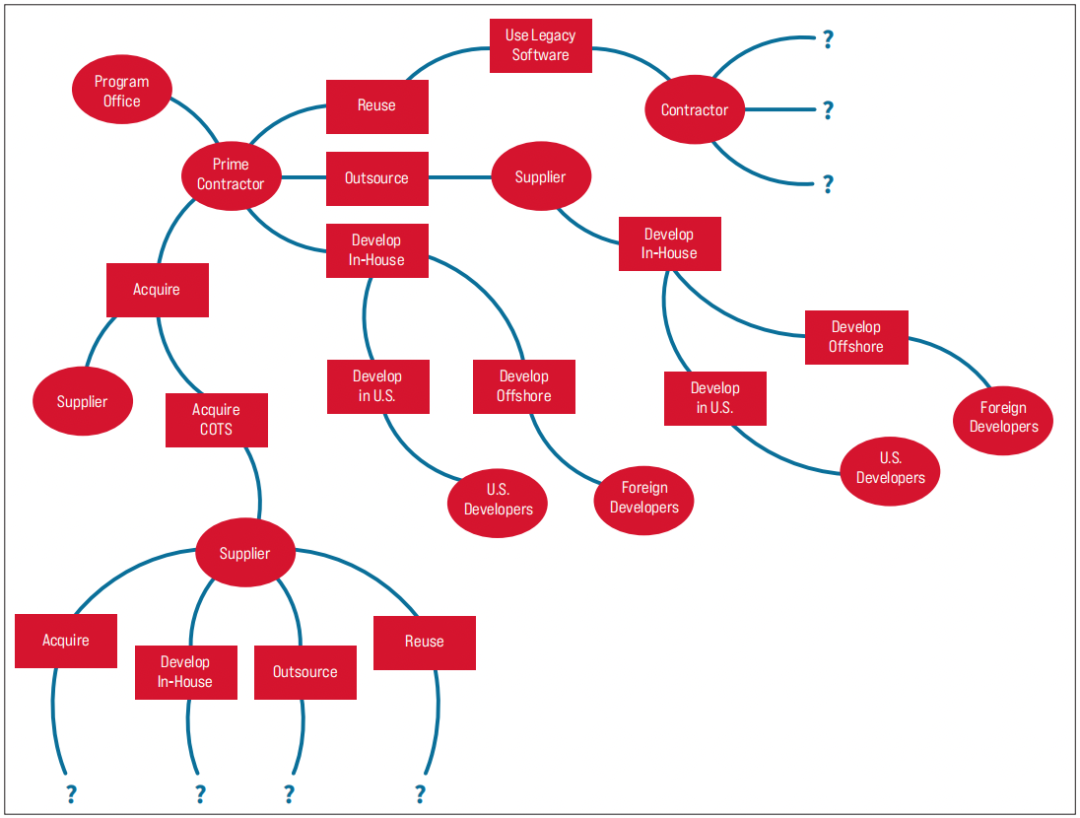
软件开发日益全球化,这一特点引起了对供应链攻击的关注。这些类型的攻击在数量和规模上都在迅速增长,并且由于系统之间的互联性越来越强以及软件代码库和库缺乏透明度,它们变得更加犀利。
例如,2020年,一家以帮助企业管理其网络和信息技术基础设施的美国开发软件公司被证明是迄今为止已知最大规模供应链攻击的理想目标。通过在例行软件更新中插入恶意代码,黑客能够破坏五分之四的财富500强公司(包括微软、英特尔、FireEye和德勤等)和许多美国政府机构(包括国土安全部、国务院和国防部)使用的第三方软件。总共约有30000个公共和私有组织在使用可能被感染的软件,这导致了一个数据、系统和网络受损的情景[Turton 2020]。
理解所用代码的功能和质量,并记录和验证供应链,这一点很重要。供应链完整性是至关重要的,但重用低质量或未知质量的代码是司空见惯的。跟踪软件的来源是解决这个问题的一种方法,开发这样的技术和工具将有助于提高软件质量。
1.5 软件是关键基础设施的组成部分
低质量软件的开发或重用可能会引入漏洞,使网络犯罪分子能够访问控制关键基础设施的软件并造成严重破坏。2021 5月,Colonial Pipeline发生了一起引人注目的袭击事件,该管道每天运输约1亿加仑汽油、柴油和航空燃料,为东海岸提供约45%燃料【伊顿2021】。黑客组织DarkSide对管道系统发起了勒索软件攻击,导致该公司关闭所有业务以遏制攻击。这起事件被认为是历史上对关键基础设施最重大的袭击之一。勒索软件攻击在2020年增加了715%,目前是增长最快的网络攻击类型[Bitdefender 2020]。每周约有1000家公司受到勒索软件攻击,公用事业公司是第二大最常见的攻击目标,仅次于医疗机构[Lanowitz,2021]。
虽然在关键基础设施中开发和部署安全软件的许多长期挑战是已知的,但问题仍然存在,低质量的软件代码继续在整个基础设施中传播着漏洞。
1.6 软件工程决定软件质量
软件故障直接反映了软件开发和维护方式的不足【van Genuchten 2019;Shaw 2002】。也就是说,低质量的软件是当前软件工程技术和实践的直接结果。一些影响是非常明显的,例如,由于失去对物理实体的控制而造成的生命损失。其他影响不太明显,例如当车辆排放系统性能不佳或手机应用程序未经用户许可收集和共享数据。如果没有对软件工程投资的催化剂,由于对越来越多和复杂软件系统的依赖性越来越大,情况将更加恶化。本报告旨在成为使软件工程成为战略优势的催化剂。
1.7 行动呼吁
尽管软件的进步是从许多部门逐步实践中有机出现的,并实现了20年前无法想象的进步,但它们并没有提供未来系统所需的能力、安全性、质量和可进化性水平。在对软件工程进行合理研究的同时,需要集中精力、持续投资和改进关键的软件工程技术;否则,可以肯定的是,下一代应用 程序根本不可能实现。
本研究报告确定了对实现未来系统中至关重要的研究领域,并提供了指导软件工程研究的路线图。在制定本路线图时,确保将未来软件系统的安全性、可预测性和可进化性所需的工作放在首位。
本报告是一份行动呼吁,强调了持续投资软件工程研究的必要性,以实现研究路线图中所描述的愿景。研究投资必须与软件工程对国家安全和竞争力的重要性相称,激励行业和政府投资伙伴关系将是成功的关键要素。
1.8 范围
本研究解决了以下问题:
- 如何快速开发、保证、分析和部署未来的软件系统?
- 哪些重大的开放性问题和“重大挑战”是重要的?
- 需要哪些软件工程研究来发明面对这些挑战的解决方案?
- 如何促进政府、学术界和行业之间的战略伙伴关系和合作?
需要强调的是,软件工程不能孤立地考虑,它需要系统视角,包括软件、硬件和人。在报告中包含了这种思想的元素,但主要集中在软件工程研究的议程上。本研究旨在适用于所有类型的软件系统,如军事安全和商业系统;商业和物流系统;以及支持所有研究类型的系统。
虽然软件工程支持的解决方案可能对社会和经济的所有部门产生变革性影响,但也有人担心这些系统的安全性和脆弱性。这项研究没有直接深入探讨网络安全,因为其重要性已经得到充分肯定,SEI和其他机构也在继续开展这方面的研究。
随着人工智能革命的推进,这些技术的开发和部署将加速。我们已经将人工智能定位为一种能力增强剂以及工程不确定性的来源,但没有提出人工智能的研究议程。SEI和其他机构也都有专门研究机器学习和人工智能的重要项目。
1.9 受众
本研究的一些预期受众如下所述:
- 工业研究人员、学术研究人员、技术人员和研究实验室可能会感兴趣的是,确定重要的开放问题领域,在这些领域中,研究解决方案可能特别有效,跨行业/学术界的新工作模式可能产生红利。
- 研究资助者、决策者和立法代表可能会理解这样一种观点,即在所确定领域的投资有可能广泛支持多个领域的研究和实践的重要发展。
- 软件开发人员、从业者和项目经理可能会发现当今领域中的关键挑战是有用的,并可能会受到启发与研究人员合作,帮助更广泛地解决这些问题。
- 政府资助的研究与开发中心可能会受到启发,共同致力于一些基本软件问题,这些问题将有助于解决各个许多特定重点领域的国家优先事项。
- 教育工作者可能会欣赏该领域当前实践状态的快照(及其限制的阐述),以便在课堂和课程中使用。
- 行业领导者可能会发现研究方向和劳动力的改进领域,以补充他们的需求,并确定与研究人员合作解决商业领域关键问题的方法。
1.10 方法
软件工程作为一个全球生态系统存在,包括许多具有不同观点的利益相关者,包括软件开发人员、软件工具供应商、将软件集成到其产品中的公司、软件研究人员和软件的政府赞助者。在这项研究中,CMU SEI与软件工程社区合作,组建了一个由商业、学术界和政府部门的远见者和思想领袖组成的咨询委员会。在他们的投入下,研究团队致力于创建下一代软件依赖系统工程的多年研发愿景和路线图。
这些社区之间的协调对于制定议程至关重要,也将是落实成果的必要条件。了解不同的软件工程生态系统、确定未来需求和确定实现变更的方法需要一系列活动,如图2所示。
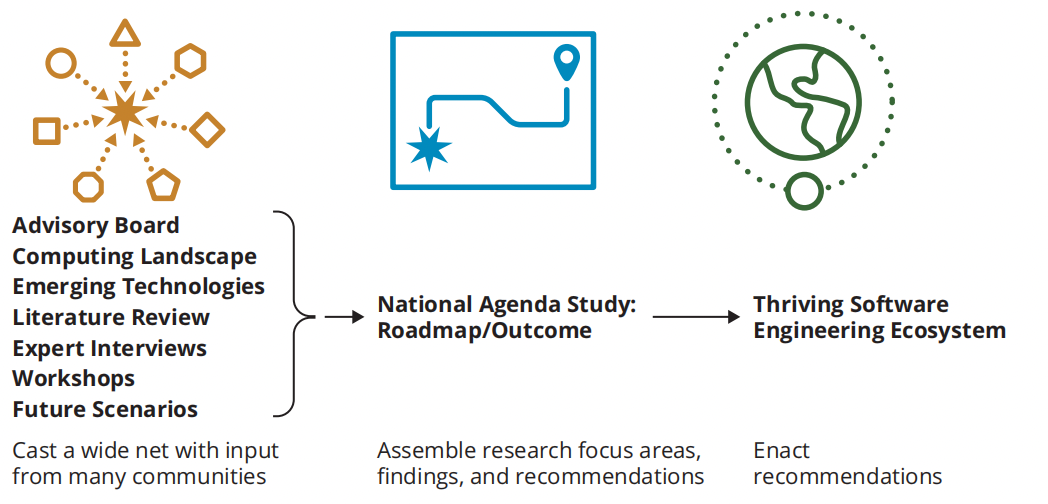
在开展这项研究时,团队进行了背景研究和文献调查,举办了研讨会,进行了专家访谈,评估了计算和软件趋势和新兴技术,开发了未来场景,与咨询委员会合作,检查了与软件相关的经济和商业数据。附录A提供了与软件工程界合作举办的研讨会的更多信息,包括与国防高级研究计划局(DARPA)合办的研讨会。
2. 探索新兴技术与趋势
计算技术的进步仍然是美国在科学技术、国家安全和经济竞争力方面保持领先地位的关键驱动因素[DIB 2019]。为了预测未来支持软件工程所需的研究和开发,必须密切关注有助于了解新挑战和机遇的新兴趋势和技术。
虽然不可能在一个文档中对它们进行全面探讨,但本节中包含的内容有助于描绘影响软件工程研究的技术前景。
2.1 新兴趋势
在当今快速发展的世界中,趋势在不断变化。以下重点介绍了我们认为对于预测软件系统未来的发展非常重要的几个当前趋势。
软件工程的流水线正在发生变化,加快了软件代码的生产和高速部署的能力。如今,私营企业和公共部门面临着快速变化的竞争环境、不断变化的安全需求和性能可扩展性的挑战。企业正在努力以创新和信心来快速开发和部署,弥合运营稳定性和快速功能开发之间的差距。在大型航空航天组织或产品组织(如亚马逊)的规模上,这通常意味着数千个独立软件团队必须能够并行工作,以快速、安全、可靠地交付软件,并且对中断或错误零容忍。快速开发实践,如持续集成/持续开发(CI/CD)和DevSecOps,正被用于快速、可靠地交付软件功能。随着这一快速开发/部署连续体的进一步发展,软件工程流水线的概念正在演变为一个动态过程,通过这个过程,新的能力被引入不断演进的系统中。
新型系统将持续超越当前软件工程理论、工具和实践所能支持的范围[Kim 2019;Murphy 2020;NITRD 2011;Weyuker 2021;Wing 2021]。例如,趋势已经指向这些系统类型的开发和使用:
- 高适应性的防御系统。软件越来越多地支持结合智能、武器、人机协同和其他能力的新型异构计算系统。
- 执行大规模数据融合的系统。无论是新闻还是情报,这些系统都利用了大量的数据流,包括开源数据。这些数据流还将推动构建未来软件系统的新方法。
- 智能城市、智能建筑、智能道路、智能汽车和其他智能交通工具。软件系统现在是这些领域中关键基础设施的组成部分,它们需要处理大规模集成,并适当处理安全和隐私问题。
- 真正有帮助的个人数字助理。软件系统必须能够学习和自适应,作为其在家庭、商业和国家安全工作流程以及我们个人生活中集成的一部分。
- 医疗保健的动态集成。家庭、医生和医院的设备将越来越多地集成到功能和数据的使用中。这种整合将导致更好的疾病预防、治疗和恢复护理。
- 社会规模的系统。这些平台在连接性、人工智能和数据科学的推动下,变得越来越大,影响力也越来越大。随着这些系统的发展,它们影响着社会行为,并在社会层面产生影响。在过去十年中,这类系统的发展趋势已经爆发,全世界有39.6亿人使用社交媒体[Dean,2021]。

规模激发了对安全和弹性软件组合的需求。 依赖软件的系统范围和规模在不断变化和增长[NRC 2010]。随着计算机硬件的改进,可以开发更复杂、更高级的软件,随着更多设备通过传感器和网络连接到物联网(IoT)中,规模的增加显然是一种趋势,没有减缓的迹象。在这些大型复杂系统中从头开始开发和维护软件组件已不再现实。因此,一个共同的趋势是从模块化组件中集成(并不断重新集成)软件系统,其中许多组件是从现有元素中重用的。
人工智能(AI)系统的开发和维护与构建、部署和维护软件系统有许多相似之处。人工智能吸引了公众的想象力,以及大量的投资和研究资金[Gil 2019]。随着人工智能越来越多地应用于各个行业,人工智能的使用呈扩大趋势。而人工智能是一个领域,它本身有许多子领域和应用,在软件开发中具有巨大的潜力。人工智能增强的软件开发有望自动化常见或繁琐的任务,并使流程更高效、更有效、更令人愉快。软件工程需要关注AI元素给软件分析、设计、构建、部署、维护和演化带来的挑战。
数据隐私和可信是软件系统越来越重要的设计考虑因素。数据现在是一种战略资产,在全球范围内捆绑、共享、出售和分发。适当地使用这些数据,同时保护数据并防止其被滥用,会带来与隐私、信任和道德相关的严重架构挑战和软件工程挑战,例如差分隐私的技术。这些技术对于人口普查、医学分析和其他涉及收集个人信息的数据分析工作非常重要。信任与用户对系统数据或输出的信心有关,包括社会上特别关注人工智能的系统中。其他技术也有建立信任的潜力,例如区块链,一种分布式账本技术。它为软件工程带来了新的机遇,在软件测试、质量、配置管理和维护方面都有应用[Demi,2021]。
2.2 新兴技术
我们今天拥有的强大技术生态系统意味着不断引入新技术,而且还有更多的技术即将出现。了解这些技术可以带来的能力,以及如何快速、安全、可预测地将它们集成到系统中,是确保它们成为软件系统的关键资产,而不是弱点或不稳定的来源。在以下段落中,简要介绍了一些直接影响软件工程的技术[Holland 2020]
高级计算在组成和开放系统方面带来了新的工程挑战。高级计算通常是指台式计算机和普通公众无法获得的一组功能。这通常意味着使用专门的软件或硬件来提供支持大规模数据密集型项目的先进技术能力。高级计算的一些例子包括高性能计算(通常用于模拟和建模)、大型云计算实现以及量子计算和信息理论的使用。
在过去的十年中,在新硬件的支持下,高级计算有了许多发展,如多核芯片、图形处理单元、现场可编程门阵列和芯片级的专用集成电路,还存在一个长期的技术机会来开发一个能够实现可扩展量子计算的软件生态系统。高级计算强调了一个事实,即未来的计算环境将越来越异构,这将在跨计算基础来构建和发展系统方面带来新的挑战。
由于规模的原因,智能边缘带来了新的挑战。“智能边缘”是一个概括术语,指将异构计算能力、应用程序和数据推向互联网的边缘。它超越了传统的计算机网络,融合了网络边缘的设备,如传感器、物联网设备和移动电话。尽管普适计算的概念已经存在了几十年,但最近出现了智能边缘的加速,包括硬件改进和5G网络的广泛部署。由于无处不在的传感器和物联网,边缘数据正在快速增长,分析领域正在创造新的新方法,利用边缘设备和中央处理的组合进行分布式数据分析。未来更智能的边缘甚至可能包括更多非传统设备,如卫星,以实现下一代的连接。
数字孪生为可信体系创造了新的机遇和挑战。数字孪生是物理对象的高保真数字或计算机表示,具有一定的推理能力。这些类型的模型使我们能够了解现实世界中的对象在许多不同条件或要求下的行为。数字孪生已经开始将现实世界物体感测到的实时数据结合起来。这种新的、更高分辨率的传感器数据允许数字孪生对未来的行为进行推理,然后将反馈传输到物理对象。数字孪生为软件工程师利用数据开发和可信软件系统创造了新的机会,但随着物理世界中越来越多的系统产生了数字孪生,他们也在规模上带来了新的挑战。

量子使能系统在组合不同的计算模型方面带来了新的挑战。软件工程是量子使能系统的挑战:许多领域都需要进步,包括量子算法、开发工具、语言、计算平台和测试平台。如果我们设想实现了允许量子计算扩展的硬件,那么软件和软件工程也将需要更多的进步。
扩展现实为人类交互和可视化复杂数据和系统提供了新的机会。扩展现实是指增强现实(AR)、虚拟现实(VR)以及两者的组合。AR包括使用设备,如辅助显示的专用眼镜,允许个人看到真实世界,但具有增强的信息。相反,虚拟现实指的是使用专用设备,使人只能看到虚拟世界。扩展现实的一个本质特征是它能够从根本上重塑人类对信息的推理。这些技术可以为软件工程师提供新的界面,以可视化复杂的数据或系统,并使新的用户交互界面具有更高的生产率。
3. 调查结果
在本研究的调查结果中,软件工程是一个高度动态、快速发展的领域,技术可以迅速崛起并发展成为现代生活基础设施的组成部分。虽然这也许并不令人惊讶,但近期技术趋势的融合程度以及高质量能力的迅速涌现是惊人的。
以下发现总结了软件工程未来所需的关键知识、关键挑战和新研究。
3.1 保持国家软件工程能力是一项战略优势
软件工程影响一切,因为软件无处不在,包括国家的基础设施、国防、金融、教育和医疗系统。我们对软件系统日益增长的依赖使得我们必须保持我们国家在软件工程领域的领导地位和战略优势。我们需要提高软件工程的知名度,使其获得与其对国家安全和竞争力的重要性相称的持续认可和投资。
软件越来越多地以越来越大的规模在影响着人类的互动。随着我们对软件依赖的增加,需要改进软件工程的技术来处理未来更大、更复杂的系统。
3.2 保持国家软件工程能力需要持续的研究
新型系统将继续超越当前软件工程理论、工具和实践所能支持的范围。未来的系统和软件工程中的根本性转变需要在智能自动化、不断发展的可信系统和理解组合系统等领域进行新的研究重点。新的系统类型,如人工智能系统、社会规模系统和量子系统,也推动了这项新的研究。
人工智能的可预测性和普遍使用也将导致新的软件工程原理。将人工智能纳入软件系统需要对人工智能工程进行研究,以增强必要的软件工程环境和工具。引入人工智能还需要理解人工智能和非人工智能组件如何协同工作,以实现整体可预测的系统行为。软件工程工具是一种特殊的系统,将人工智能纳入这些工具将使软件工程更加有效。一旦我们了解了如何以可预测的方式做到这一点,它将允许更多的责任转移到人工智能,人工智能和人类之间的合作将继续加强软件工程。
3.3 保持国家软件工程能力需要促进战略伙伴关系
我们需要促成战略伙伴关系和协作,以推动行业、研究实验室、学术界和政府之间的软件工程研究创新。将人工智能引入这些工具将使软件工程更加有效。
3.4 保持国家软件工程能力需要持续的投资
我们必须确保决策者认识到软件工程的好处,并使其成为一项重要的国家能力。这种承认将意味着持续的投资战略。
3.5 软件工程的愿景需要改变
当前基于程序员意图的软件开发流水线的概念将被人工智能和人类合作并不断进化的系统所取代。
3.6 将重点放在可信系统上,使新能力能够持续、快速地整合
由于软件无处不在,因此对软件的需求不断增加,不断发展,并整合新的功能。因此,我们需要了解如何在不损害现有能力的情况下,持续有效地保证软件系统是可信的,提高可信证据和论据的重要性将是关键。
3.7 社会规模的系统需要新的设计原则
对软件影响的加深认知正在产生新的质量属性需求,软件工程师需要开发更好的设计方法。除传统属性(如可修改性、可靠性、性能等)外,还需要添加新的质量属性,如透明度和影响力。
社会规模的系统涉及微妙的判断(例如,软件系统和言论自由原则之间的适当交互)。社会规模系统的一个共同特征是人类成为系统的组成部分。这些系统应提供信息或通信渠道,可预测地从用户那里获得期望的结果(如参与度、准确性等)。随着这些系统的激增,需要更多的研究来实现对系统行为的预测和控制。
3.8 需要重新设想并构建软件工程的人员队伍
依赖于软件的系统是由一群拥有完全不同技能的人为许多不同目的而构建的,其中许多人没有受过正式的软件工程培训。我们需要更好地了解所需劳动力的性质以及如何促进其增长。
社会普遍对软件工程人才的充足性和可用性表示关注。人们似乎越来越关注一些话题,包括不断变化的技术技能、软件工程人才的全球竞争以及软件教育的作用。似乎很清楚的是,无论提供了什么工具,或者我们使用什么抽象级别来构建系统,人在不断发展的软件工程中始终扮演着最重要的角色。
4. 展望软件工程的未来
假设现在是2035年,软件工程会是什么样子?也许我们可以把它想象成人类和计算机之间的技术对话,而不是手动细化规范和编写代码的过程。
4.1 未来情景
考虑一下这个场景:无休止的需求和设计审查的日子已经过去了。一个由航空工程师、飞行员和软件工程师组成的联合团队通过提出想法,共同设计下一个具有太空能力的飞行器,这些想法在获得关于物理系统的广泛知识以及物理局限性的基础上,变为可行的设计。这些设计是实时显示的,团队通过实时模拟典型任务,在飞行中比较防御和机动能力。最终设计是根据成本、能力和时间的最理想平衡来选择的。与这种流动的迭代过程相比,今天的软件开发生命周期的概念似乎过时了。

未来的软件开发可能更多是表达所需的能力,而不是编写代码或拥有算法的思想仓库。软件工程师必须熟练地表达意图,使计算机能够从经验中学习。“优雅的软件”不再指聪明的代码,而是人类与自动化和人工智能系统合作,以最及时、经济、符合道德和安全的方式实现人类所能想象的最佳想法的结果。
能够“编程”和创建复杂系统的人自然也会扩展。我们与计算机的对话将以领域语言进行,例如,计算生物学家通过谈论测序和基因来开发软件能力,而不是学习Python。所有类型的专家都需要适当地通知计算机,他们的交互方式将与今天有很大不同。
仿真的使用可以将今天的整个测试和评估方式转变为一种沉浸式体验。设想为一系列空间资产规划了新的硬件配置和软件功能。在完全沉浸式虚拟现实环境中,通过对当前资产的全面遥测来模拟环境变化。工程师可以从任何有利位置查看新的空间配置,而不仅仅是在可视范围内。来自当前环境的所有可用数据和元数据也实时呈现。如果期望的效果不是预期的,工程师会做出改变,并立即看到对整体空间环境的影响。此外,数十名或更多的工程师正在共享体验中观察和操作相同的环境。工程师之间的沟通,通过多种类型的媒体和共享的决策过程,确保系统作为一个整体没有意外或不期望行为。一旦做出更改,将使用相同的环境来支持操作员培训和实时任务演练。
软件一旦被部署,系统的适应性和可集成性也将大大提高。考虑一个涉及特种部队部署的场景,想象一场交火。小队措手不及,通讯中断,他们不确定用什么武器对付他们。幸运的是,他们正在与一组微型无人驾驶飞机系统合作,利用备用通信渠道主动建立网状网络,以重新建立与总部的联系。一旦该网络建立,该小队将指挥设备秘密观察和分析战场上的武器,并在掩护时提供缓解选项。因此,他们不仅能够在当地克服新的威胁,而且能够将他们的实时经验提供给处于战场边缘可能处于风险中的其他部队。为了使这一场景成为现实,软件工程师将需要设计灵活的架构,并允许根据来自传感器的数据和来自现场用户的其他输入对系统进行调整。
随着自适应用户界面的扩展,设计一部电影的工作方式可能会有所不同。人们不再期望他们知道编码和脚本,他们可以在开发完全沉浸式电影的过程中进一步提高他们的创造性设计技能。在“全息甲板时代”,他们能够融入新颖的视觉故事情节,为下一代触觉反馈设计服装,并创造对观众输入做出反应的事件。随着时间的推移,随着情景可能性的探索,互动体验不断发展和改进,以适应参与者的偏好,并以艺术家的意图为基础。

软件工程的学生也将学习不同的知识。帮助他们编写代码的人工智能和自动化工具可能在很大程度上是不可见的,因为他们专注于主要工作:学习如何最好地理解和表达软件应该(和不应该)做什么。他们的计划意图是什么?他们如何能确保这一意图得到实现呢?最终结果是否不仅是功能性的,而且是可进化的、对用户直观的、值得信赖的?一个示例项目可能涉及一个个性化的web“浏览器”,它可以根据个人的需要定制,同时还可以自我更新安全层,以保护关键数据。同样的系统仍然可以建立并实时匿名分享适当的信息,以帮助其他从事类似项目的学生。
随着软件工程师进入劳动力市场,他们将不再需要试图理解日益复杂的系统变化带来的连锁反应。由于系统是由人类和人工智能助手共同进化的,因此在实施之前,问题已经被识别和纠正。通过分析变更可能对系统的基础和保证参数产生的影响,确保变更不会破坏系统,这是由熟练的软件工程师设计的。设计也将保证符合质量的标准,作为由专家工程师实施的复杂软件开发框架的一部分,但对不需要关注这些方面的程序员隐藏。
尽管软件工程取得了这些进步,但任何类型的复杂系统都不可能是完美的。未来,可能会出现专门的学科,如检测潜在系统问题、在故障发生时恢复能力、发现并消除原因的学科。例如,安全软件工程师可能会参加与世界各地同事的虚拟会议,分析客户安全代码中的漏洞,并确定其可能产生的影响。另一个与社会技术生态系统合作的工程师可能会被系统本身要求:如果它注意到情绪的总体表达正朝着不受欢迎的极端发展,请介入。当检测到这些问题时,专业软件工程师的工作就是找出根本原因。它是一个训练不足的机器学习算法,表达了不好的意图,亦或一个因为没有考虑特定变量而违反了架构的组件,还是其他什么?
在所有这些场景中,软件工程无处不在,尽管它的外观和行为与今天不同。它实现了所描述的所有功能,而且安全、可预测且经济。未来的研究进步将使不同群体的人有更广泛的机会进行创造性开发,但软件工程将确保系统具有卓越的能力,在很大程度上没有我们今天看到的问题和失败。
4.2 软件工程的未来展望
虽然智能算法和人工智能的确切角色仍有待确定,但软件工程对我们愿景的重要性是显而易见的:人类和人工智能将是值得信赖的合作者,能够根据程序的意图快速进化系统。
随着软件工程师不断与智能软件助理互动,计算机和人类将能够做他们都做得最好的事情。以这种方式工作,我们甚至无法想象的可能性将成为现实。本报告中的研究为推进软件工程学科提供了必要的基础,以确保必要的框架到位,以最大化这些未来的优势。
软件工程的新愿景需要新的开发和架构范例,这也激励了第5节中描述的重点研究领域。
先进的发展模式,将在规模上带来效率和信任:
- 人类利用可信人工智能作为软件创建各个方面的劳动力乘数。
- 形成正式的保证论据,以确保并有效地保证软件的不断发展。
- 先进的软件组合机制能够在越来越大的规模上实现系统的可预测构建。
先进的架构范式将使新计算模型的可预测使用成为可能,如下所述:
- 来自行为科学的理论和技术用于设计大规模社会技术系统,导致可预测的社会结果。
- 人工智能和非人工智能组件以可预测的方式相互作用,以实现增强的任务、社会和业务目标。
- 新的分析和设计方法促进了量子使能系统的开发。

5 研究的重点领域
本报告中描述的软件工程的基本转变和进步需要新的研究领域。我们与顾问委员会和软件工程研究社区的其他领导者密切合作,制定了一个包含六个重点领域的研究路线图。
本节描述这六个领域的动机,它们与上一节的发现密切相关。在本节中,还提供了一个完整的路线图,然后深入讨论了每个研究的重点领域。
5.1 先进的开发范式
使用DevSecOps和数字孪生的趋势表明,现场系统和开发环境之间的边界开始模糊。例如,通过成熟的人工智能技术,软件正在增强人类的决策,并成为从数据中学习来提高性能的有用工具。操作数据与仿真相结合,可以实时了解系统的行为。不断变化的任务需求正在推动系统的连续演化,需要有效的系统保证和系统开发的组合方法。这些趋势推动了前三个研究重点领域,我们认为这三个领域是先进开发范式的基础:
1.人工智能增强软件开发:使用成熟的人工智能技术增强软件工程中的人类决策,并从大量软件工程数据中学习。
2.确保持续发展的软件系统:认识到快速变化系统有效保证的重要性,同时考虑到未来软件系统推理所需的许多科学领域和证据。
3.通过组成的正确性进行软件构建:认识到开发和进化系统的唯一可行方法是通过实现组合开发的技术。
5.2 高级架构范式
未来系统的一些特性为软件工程提出了新的和有趣的问题。特别是,将人工智能组件引入系统,将人类视为系统的元素,并有效利用量子计算,对未来系统提出了特别重要的挑战。在我们的软件工程愿景中,高级
架构范例将使系统的这些新方面的可预测使用成为可能。这些挑战激发了以下三个研究重点领域,我们认为这三个领域是高级架构范例的基础:
4.工程社会规模软件系统:讨论建模人类行为的挑战
5.人工智能工程化支持的软件系统:关注处理人工智能组件给系统带来的不确定性的挑战
6.量子计算工程化的软件系统:考虑量子计算的哪些方面应隐藏于或暴露于软件堆栈的更高层
5.3 研究路线图
我们确定的研究领域是相互协同。例如,人工智能增强软件开发需要考虑不断发展的系统,最终,人工智能工具在提供软件开发建议时需要使用可保证的论据。通过组合正确性进行的软件构建与确保持续发展的软件系统之间的关系也很强,因为随着系统的发展,组合技术和推理将是增量确保的关键因素。同样,所有高级开发范式都适用于高级架构范式中讨论的每种新系统类型。
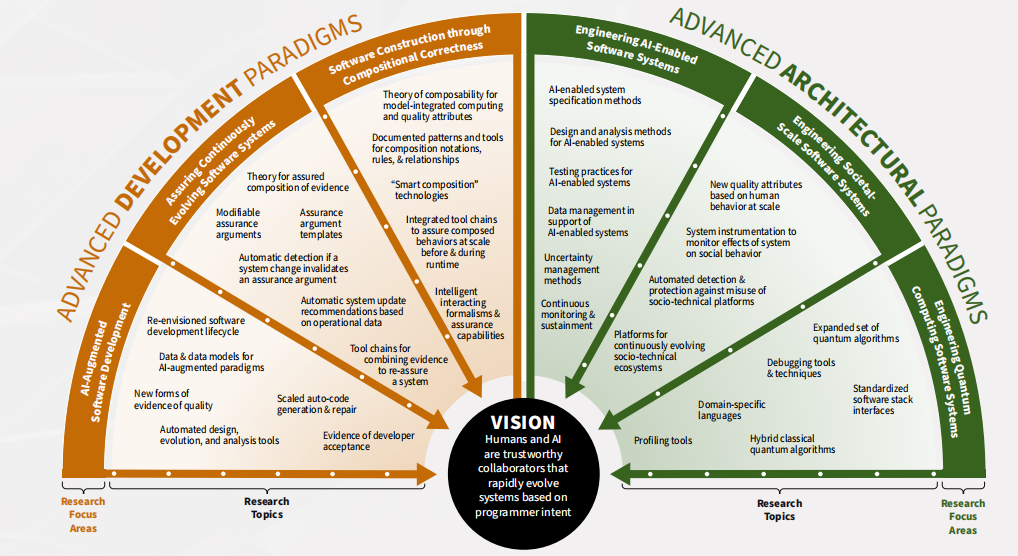
5.4 AI增强软件开发研究重点领域
5.4.1目标
提高软件工程师效率和减少其认知负荷已经推动改进了自动化和形式化的趋势,以支持软件开发任务。使用人工智能增强方法的软件工程师也将能够专注于需要批判性思维和创造力的任务。该研究领域侧重于开发自动化AI相关的软件工程任务方法,并加速可靠性工程自动化的发展。这一研究领域的成果将进一步将人类的注意力转移到计算机不擅长的概念性任务上,并消除计算机可以帮助任务中的人为错误,从而使可靠软件的设计、开发和部署成为可能。
在过去十年中开发的许多自动化方法,包括基于模型的软件工程、DevSecOps工具、缺陷和漏洞分析、自动错误修复、现代代码审查和价值流管理工具,都旨在提高软件开发效率和质量[Lago 2015;Rahman 2017;Morrison 2018;Le Goeus 2019;Sadowski 2018;Murphy 2019]。尽管在自动化方面取得了这些进步,但故障、软件安全和质量问题以及超支仍然是常态。考虑到问题的规模,仅美国政府就在2019年花费了900多亿美元用于系统维护和运营[GAO 2019]。
我们需要创建工具,使软件工程师能够轻松表达他们关心的更改,包括需求和设计权衡以及不同的解决方案选项,然后相信自动化将在编程语言级别正确解决大部分(如果不是全部)细节。例如,许多系统将受益于开发工具,以帮助开发人员在开发软件时避免、检测和修复缺陷。一系列技术,包括更安全的编程语言、设计更好的框架、廉价且简单的自动生成测试,以及提供修复建议的工具,将共同提供比单独依赖任何一种技术更好的结果。在未来十年,人工智能方法将提供一个重新思考我们如何实现编程目标的机会,特别是通过提供改进的能力来消除后来难以发现和修复的琐碎错误。
这些进步将不可避免地推动对软件开发过程的重新设计,增加对开发人员的智能支持。利用通过软件开发生命周期生成的数据将是该过程的有益和自然的副产品。因此,这一研究领域提出了一个问题:人工智能增强软件开发在未来会是什么样子?
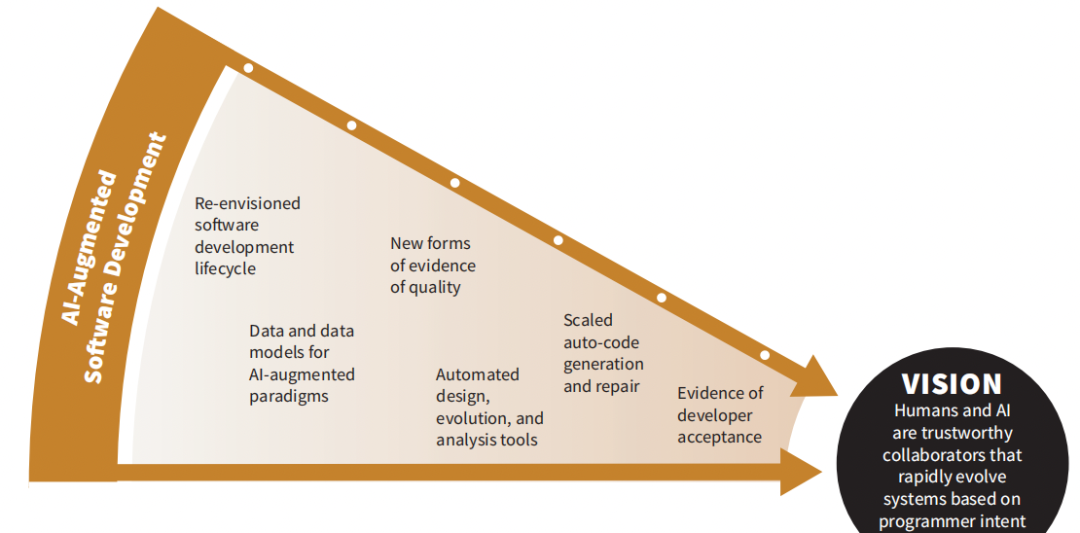
5.4.2当前实践的局限性
当前,软件开发是人力和测试密集型的,而且容易出错。特别是,软件开发的实践方法受到了以下的限制:
- 开发人员需要成为许多主题(需求、架构、设计、编程语言、分析模型、令人眼花缭乱的技术和框架、质量属性、测试方法、平台等)的专家。软件工程师通常依赖于没有正确遵循的软件开发过程来协调这些活动以及创建的工件。
- 从开始到部署,需求规范生成了大量工件,如设计文档、分析工件、测试用例和部署脚本。精简这些工件以实现成功的系统交付仍然是一项资源密集型的挑战。
- 在没有有效工具的情况下,开发人员需要理解复杂系统中的连锁反应(在规模、分布、并发性等方面)。
- 正式方法和基于模型的方法已经创建,并承诺可靠地生成代码和演化系统,但即使在关键的安全系统中,它们也不能突破系统的局限。
- 当进度的挑战来临时,用于设计和测试系统的时间继续缩短,进一步危及所开发系统的质量。
- 系统的可持续性和演化,特别是遗留系统,继续着手动驱动的高风险工作。
- 作为软件开发框架或工具链的一部分,不能保证符合质量标准和预期架构。
5.4.3研究主题
在软件开发的每一个阶段,人工智能可以帮助人类,并使过程更加高效、有效和愉快。每一代新的工具和朝着这一目标的进步都会被开发人员接受:
- 执行开发人员已经完成的任务,但效率更高(例如,测试速度更快)。
- 执行开发人员已经完成的任务,但做得更好(例如,捕捉更多错误)。
- 执行开发人员目前无法完成的任务(例如,利用新数据集成新的一致性检查或生成新的测试)。
- 减少移交并集成当前断开连接的元素(例如,提供需求可追溯性)。
- 教导开发人员如何更好地完成任务(例如,建议和/或指导实施错误的实时反馈)。
- 帮助扩展开发人员已经可以做的事情(例如,允许他们考虑更多的替代设计选项)。
为了最好地评估这种新的自动化工具和方法在实践中的有效性,还需要无缝地扩展和集成开发人员的环境,即使在研究阶段也是如此。人工智能增强软件工程进一步利用了数据收集、迭代反馈循环和测试开发人员的持续集成和部署环境。

5.4.3.1人工智能支持的重新设想开发工作流
敏捷和精益软件开发流程通过帮助开发人员关注最优先事项并了解库存中的任务,鼓励消除浪费[Reinertson 2019]。例如,测试驱动的开发工作流可能提倡在软件完全开发之前将软件需求转换为测试用例。然后,可以通过针对所有测试用例重复测试软件来跟踪软件开发,这将显著提高软件开发的效率并提高系统质量。类似地,人工智能支持的开发工作流将针对数据密集和繁琐的活动,这可能导致软件开发生命周期中不同的任务依赖性。例如,当人工智能增强bug修复成为现实时,开发人员可能不需要测试某些类型的bug。
结合基于AI支持的工具也将触发为开发人员设想更有效工作流的需求。例如,在代码质量一致性方面改进的实时帮助可以减少在测试和部署期间对添加的静态代码分析的依赖,提高本地一致性分析与系统范围、跨领域、架构质量和运行时问题分析之间的平衡。今天,系统范围的分析通常是手动工作,很少得到自动化的支持。
在AI增强的开发生命周期中,开发人员和人工智能助手都将发挥监督作用。开发人员将指导并改进人工智能助手。人工智能助手将通过提供实时反馈,并及时向开发人员演示重复错误,发挥监督作用。在开发人员团队中,总是有一些开发人员比其他人更值得您信任(可能是由于经验、技能或表现)。人工智能辅助开发工作流程将触发以同样方式思考人工智能“合作伙伴”的需求。作为生产高质量软件的整体团队的一部分,人类和人工智能在哪些方面最有效?
5.4.3.2自动代码修复
自动代码修复是自动代码生成的一种特殊应用。代码生成包括完成不同任务的方法和技术的广泛集合,其确切含义在很大程度上取决于代码库的哪一部分。几十年来,代码生成已经可以用来生成部分代码,例如类声明,以匹配统一建模语言(UML)。这类工作通常被用作起点,开发人员希望在这个代码框架中来管理实现细节。对于驱动代码生成的几种形式,已经有了一些零散的研究。类似地,现有的计算机辅助软件工程工具具有有限的代码生成能力。
人工智能为代码生成提供的机会是搜索现有代码并识别与预期新代码具有相似模式的能力。现有的代码可以用作输入,并进行转换,以解决特定类型的问题,而不是从规范(如UML模型)开始。基于ML的技术可以帮助生成与现有代码类似的代码。这意味着可以从小型开始,使用基于人工智能的代码生成方法来利用通常重复的应用程序。
自动代码修复同样可以使用现有代码作为输入,然后对其进行转换,以解决特定类型的修复问题[Oliveira 2018;Klieber 2016]。需要填补的研究空白包括找出用户需要为程序指定哪些部分才能大规模生成可用的解决方案,以及如何生成部分可接受的解决方案以取得增量进展。其他差距包括确定代码库是否提供相关数据来标记和创建复杂代码生成任务的ML模型,以及确定开发人员如何确定生成的内容是否合适。
随着生成的代码和其他软件工件的数据量指数增长,人为错误的机会增加;被忽略的错误数量也在同时增加。AI,特别是ML,擅长识别大量数据中的模式。成功将取决于识别自动代码生成和修复问题中小型可扩展部分的能力[Kirbas,2021]。
5.4.3.3消除设计/规范一致性差距
调整系统的设计和实现可以提高产品质量并简化产品开发。特别是对于国防部的系统,符合特定体系结构方法(如开放式体系结构)的能力不仅支持技术目标,而且支持任务目标,如跨领域集成的能力。同样的挑战也存在于工业系统中,如智能城市。今天,这种一致性目标是通过定性技术实现的。虽然开发人员获得了人工智能增强的工具和技术,这些工具和技术越来越多地帮助他们完成实现任务,但代码和设计之间的抽象差距限制了一致性和设计任务的自动化。代码经常偏离系统的预期设计,系统中设计的质量无法实现,增加了维护工作。如果开发人员能够确认每个代码提交是否符合预期的设计和质量,则可以防止这种情况。为了以可扩展的方式实现这一点,需要自动化,以将实现的设计与预期的设计作为持续集成流水线的一部分进行比较。ML和基于搜索的算法提供了重新审视这个棘手问题的机会。
5.4.3.4 多工件系统分析
依赖人工智能助手帮助开发人员找到工件、代码库、缺陷和漏洞记录或文档建议中的相关示例,既有机会也有危险。例如,许多开发人员复制了不安全的代码,传播了不良的实践方式。然而,人工智能助手在主动设计以防范此类错误时,可有助于降低此类做法带来的风险。例如,建议可以包含来自多个工件的特征,以及提高相关性的置信度。例如,当项目可以利用来自需求、分析和技术选择的输入来改进来自其他项目的重用代码时,支持多工件分析的人工智能助手就可以在规划阶段支持工程任务。
结合来自多个软件工程工件的信息,在ML方法(如自然语言处理算法和数据增强算法)的支持下,将弱学习者转化为强学习者,将为软件开发生命周期中的可追溯性开辟更好的途径。例如,如果开发人员正在描述他们不太确定的东西,系统可以基于人工智能的干预不断地重建自身的各个方面,直到描述变得更清晰。通过这样做,它可以利用不同软件工程工件潜在的共同特性,这些特性驱动这些学习者的发展。
挖掘软件仓库的工作在过去几十年中取得了进展[Hassan 2008;MSR 2021],特别是在缺陷分析和预测、开发人员情绪分析以及代码审查等实践领域。这部分工作为改进工件内共享信息的可追溯性提供了基础,从而为开发人员提供更及时和正确的决策支持。

5.4.3.5 自动化演进和重构
软件设计、开发和部署是基于权衡的活动。基于搜索的软件工程技术[Harman 2015]显示了适应软件设计的帕累托最优,事实上,代表了设计权衡空间的多种可行解决方案。尽管在为软件工程师提供自动化开发工具方面取得了进展,但诸如重新设计和重构现有软件等复杂活动仍然是资源密集型的。
大规模自动化演化和重构的愿景要求自动化,以设计语言来帮助开发人员,并自动化实现这些更改所需的代码更改[Ivers 2020]。需要解决的问题包括流程的哪些部分可以和应该自动化,以及人工智能方法如何可靠地生成解决方案。对繁琐、重复和容易出错的活动进行自动化是一个明确的起点。工具是否应该最低限度的改变以实现重构目标,还是应该创造机会,沿着总体质量改进目标在改进系统的过程中“清理”一切?我们可以将数据与代码一起重构吗?工具应该重构测试套件和代码。还可以创建单元测试作为大规模重构的副产品吗?解决这些问题将使人工智能增强软件开发能够支持更多高速变化的未来。
5.4.4 研究问题
研究主题产生的问题包括:
- 我们如何将程序应该做什么的高级规范转化为实现它的低级程序(即,使用抽象逻辑推理创建满足给定规范的程序)?
- 人工智能可以用何种方式使规范更加精确并解决歧义,符合系统受众的需求?开发人员在编写规范时是否比在编写代码时更容易出错,AI在哪里可以弥补编写代码和规范的差距?
- 在人工智能辅助的范式中,是否有新的阶段或活动成为软件开发生命周期的一部分?我们是否需要重新思考生命周期的各个方面,以纳入意图的激发?人工智能助手的反馈是否可以用于培养开发人员的技能?
- 人工智能助手能否帮助开发人员协调持续的系统进化,软件将不再像现在的这样静态和硬编码,而是动态调整以不断实现其目的?
- 人工智能支持的工具将扮演什么角色,人类开发人员将保留什么角色?
- 人工智能增强的软件开发工具如何生成有效验证或验证代码所需的元数据?
- 人工智能能力是否可以通过检测开发环境来支持调试代码(例如,自动化分析是否可以查看关键系统中的问题日志,并了解解决特定类型问题需要多长时间,然后将其反馈给决策制定)?
- 什么是正确的抽象级别?我们使用了更高级的编程语言、架构模式等。需要哪些新的抽象级别来支持不同的开发人员任务?
- 需要收集哪些新的软件开发数据(符合道德规范,并确保安全和隐私)以支持此类未来研究?如果我们收集这些数据,哪些活动缺乏可追溯性?
对基于人工智能的解决方案的信任,无论其形式如何,都归结为风险评估。结果正确的概率是多少?如果它是错误的,会有什么影响?如果人工智能提出错误的建议,相关的风险将如何显著降低?开发人员最初将不得不坐在驾驶座上,初期进展缓慢;然而,在回答这些问题方面取得进展将加速。因此,人工智能增强的软件开发将为开发人员创造可靠的自动化支持,提高他们开发的系统的效率、有效性和质量。
5.4.5研究课题
为了在这些领域取得进展,每个领域都必须能够通知其他领域,特别是通过生成数据并使用这些数据确定下一个相关研究步骤。进展将是迭代和增量的,指导成功的里程碑如下:
- 重新设想软件开发生命周期。需要考虑软件开发生命周期在人工智能增强范式中的变化方式。随着研究的进展,重要的是澄清人类和人工智能增强工具的不同角色,从人工智能作为可信赖的助手到人工智能完全取代某些任务。
- 获取数据并为人工智能增强范式开发数据模型。需要为人工智能增强范式的每个阶段或工作流建模提供数据,需要进行评估,以确定哪些额外的数据将有帮助,如何以最少的干预收集缺失的数据,以及如何以合乎道德的方式收集这些数据。
- 确定质量证据的新形式。需要自动累积和携带质量证据,并验证结果是否正确。AI生成元数据以有效地验证代码,并使用代码生成可跟踪证据。
- 自动化设计、演进和分析工具。需要可靠的自动化工具与开发人员使用他们的词汇表进行交互,以帮助开发和重构任务。
- 自动代码生成和修复的规模化。基于模型的技术和形式化方法需要用人工智能技术加以扩充,以扩大其适用范围和规模。
- 收集证据,证明开发人员接受AI的援助并有效。开发人员必须自信地接受新的交互形式;经验数据表明,开发人员在设计任务上花费的时间最多,而不是在软件复杂性和提高质量的挑战上。
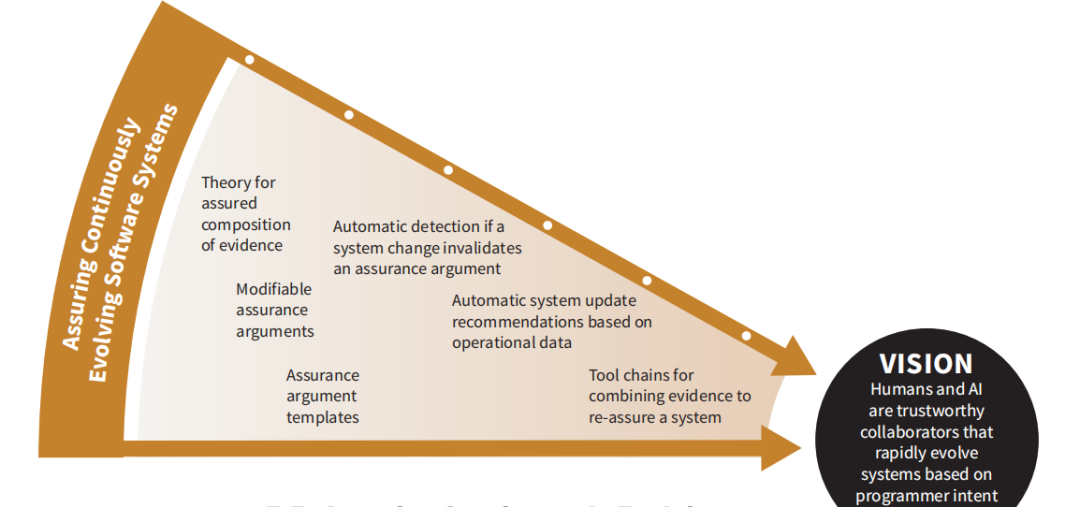
5.5 确保软件系统持续演进的重点研究领域
5.5.1目标
该研究领域的重点是如何创建一个可演化的确保方式,该确保方式只需要在对系统进行增量变更时进行增量修改。对系统增量修改所需的保证也应少于完整的从头开始的保证工作。此外,确保的方式应足够充分(即,确保方式中不确定性的唯一来源应是证据中的缺陷。推理结构应完全演绎,在证据和论证推断完全正确的情况下能够提供正确的结论)。
5.5.2当前实践的局限性
软件系统的范围、规模和普遍性在不断增长和变化。增量保证是及时部署和更新系统的唯一可行方法,对其运行行为有足够的信心。对于软件缺陷可能对生命或财产造成灾难性影响的安全和任务关键型系统,提供这种信心尤为重要。
今天的系统在不断地递增变化。有必要从“构建和保证”(即一次性事件)的心态转变为“重建和重新保证”(即持续事件)。此外,当前软件系统在一定程度上是通过在不一定考虑的环境中重用不同来源的组件而发展的,第三方会负责进行更新。因此,解决组件的有保证组成和进化系统有效再保证的限制非常重要。
5.5.2.1确定成分的限制
如今,软件系统通常通过合并第三方组件来构建,主要以平台(例如,操作系统、中间件和图形用户界面)、库和框架(将平台和库结合起来)的形式来实现。为了允许开发人员使用第三方组件,组件开发人员提供描述信息的应用程序编程接口(API),例如
- 如何调用组件的函数(例如,函数名称和要给出的参数)
- 预期返回的结果(例如,具体输出值类型和计算的高级描述)
- 哪些限制控制了不同功能的顺序(例如,在读取文件之前打开文件)
不幸的是,虽然API通常足以执行代码组合,但它们不足以执行有保证的组合。API不足以实现这一目的的原因是,它们被设计为供程序员使用,而不是集成到确保系统的参数中。
5.5.2.2 系统演进确保方式的局限性
如今,软件系统的确保方法主要集中在测试、仿真和有限集的形式化方法应用上。实践中的大多数保证是通过测试(例如,自动回归测试、压力测试和渗透测试)和检查(例如,设计和代码审查)完成的。对于一些企业和任务关键型系统,敏捷开发和DevSecOps流水线越来越多地为增量演进提供了基础。在这些类型的系统中,通常使用提供关于错误可能性快速反馈的技术。使用了各种非正式的保证技术,包括
- 测试驱动开发,确保新功能和修改功能的测试
- 持续集成,提供了进行和测试频繁小变更的机会,从而增加了满足系统需求的信心
- 持续交付,确保快速反馈增量变更是否满足实际用户需求(即需求是否需要变更)
在所有这些方法中,质量保证工程师利用回归测试来获得证据,证明尽管新版本中包含了更改,但仍保持了先前承诺的系统行为。

越来越多的保证用例来保证关键的系统【Maksimov 2019;Denney 2018】。然而,保证用例概念侧重于在特定时间点论证系统的属性。即使在大型研究项目(如DARPA的ARCoS项目)中,也不经常讨论与系统演进活动并行演进保证论证的概念(该项目专注于通过自动化过程的某些部分更快地开发保证案例)[Richards 2019]。
5.5.3研究主题
5.5.3.1 开发有保证的软件演化理论
软件系统既不是静态的,也不是不经常更新的工程工件,而是流动的工程工件(即,预期将持续更新和改进的工件)。因此,重新保证和重新验证整个系统所需的努力必须通过限制更改单个组件和组成组件子集的后果而最小化。
因此,本研究主题的总体目标是,在大多数(如果不是全部)再保证工作仅限于系统发生变化的部分情况下,实现持续发展系统的有效性和有界性进行再保证。实现这一目标需要开发一个有保证的软件演化理论和实践,包括如何适当地构建系统及其保证论证。该理论的核心是我们将称之为“保证论”的人工制品,其应具有以下属性:
- 精度。该表示法适用于自动和形式化推理。
- 可靠性。一个可行的保证论据必须基于明确和精确的假设,并且相对于系统必须表现出的行为声明而言是可证明的,而且是充分的。
- 多领域适用性。可行的保证论据由大量相互作用的子论据组成(例如,关于逻辑正确性、时序正确性和安全性),每个子论据都必须准确可靠,同时考虑与其他子论据的相互作用。
- 模块化。支持有效重新保证的保证论据必须限制变更的影响,以避免每次系统变更时必须重新保证所有的行为。但除此之外,模块间依赖关系必须明确且可追溯。
接下来的两个部分讨论的主题集中在克服与不断发展系统可靠组成和有效保证相关的限制。
5.5.3.2 面向生态系统架构和论证充分性的证明系统
如今很难解释不同类型证据(如测试、正式验证、模拟和数字孪生)的组合在多大程度上增加和证明了系统满足其要求(即按预期行为)的信心。同样,很难解释何时不需要某些类型的证据来获得对系统行为的足够信心。合理的信心取决于发展和维持一个结构良好的保证论证,该论证严格地编纂了如何从证据收集中推断系统行为。为了应对这一挑战,我们建议研究如何创建或完善理论、方法和工具,以将不同的证据类型组合成合理的保证论证。
虽然,动机是保证论证实际上是证明系统的概念,但我们也意识到,实际系统中没有无可辩驳的论证。特别是,假设没有被忽略,或者从每种证据类型推断出的结论总是正确的,这并不是绝对确定的。然而,我们认为,寻求合理的论据,同时考虑到重要的实际考量,将导致严格而实用的技术。

5.5.3.3 结合不同的证据
保证参数使用不同类型的证据。考虑确保自动系统(如无人驾驶汽车或无人机)永远不会伤害人类的需要,一类证据可能来自实时分析,可用于确保时间关键型任务的最后期限永远不会错过。可能需要另一种类型的证据来估计视觉系统正确识别人类的概率。除其他证据外,这些不同类型的证据必须以能够就人身安全提出正式保证论证的方式进行组合。使用来自不同领域的证据进行形式保证还需要结合来自不同领域中的证明系统。这导致了两个挑战:(1)确定证明系统之间是否存在依赖关系,如果存在依赖关系,(2)确定原始证明系统的哪些部分仍然有效,哪些部分需要更改。
即使经验证据是论据的一部分,保证论据仍然必须提供适当的保证。例如,在气囊系统中,我们可能确定不可能保证成人检测模块始终检测是否存在成人乘客。在这种情况下,可以确定不检测人的概率应保持在0.001%以下。达到这一精度水平的充分理由需要设计基于概率理论的适当采样机制的实验,以证明可以达到所需失效概率的阈值。充分的论证还需要考虑在同一保证论证中使用概率和确定性推理可能产生的相互影响。
5.5.3.4 保证的组成
保证的组成将是组合不同证据和产生严格保证论据的关键。实现有保证的组合需要将注意力从代码组合扩展到保证参数组合,讨论编程和保证问题需要使用更通用的组件和接口定义。
我们将组件定义为行为的封装,该封装提供了接口中此类行为的摘要。该接口足以组合组件并创建新行为。行为封装的细节及其摘要取决于组合的类型。例如,代码组合将使用代码封装(例如,库)和API,而有保证的组合可能使用例如值转换公式和前后条件。相关考虑包括:
- 在当前实践中,软件组合主要集中在代码组合上,这意味着组件接口侧重于向程序员提供信息,而很少直接关注保证。一些工作已经超越了这种传统方法,纳入了某种形式的假设和/或担保推理,如合约设计方案[Myer 1992]。
- 通常为特定领域开发形式参数,而不考虑跨领域效应。这种趋势导致组件和接口描述只支持价值转换声明,而忽略了其他方面,如时间、安全性和错误行为的影响。例如,其他社区关注时间行为,而忽略价值转换。此类特定领域的接口描述仅捕获组件的完整行为的一部分。这些特定领域的声明实际上是特定领域内可扩展保证的关键。例如,速率单调分析中的实时任务抽象(这是一种特定类型的实时分析,仅在最简单的情况下使用任务执行时间、周期和优先级)可能导致实时任务数量的线性复杂性分析。添加额外信息,如计算状态,可导致指数分析的复杂性(例如,对于时间自动机)[Alur 1992]。
- 跨域依赖性。当在特定领域中提出声明时(例如,验证值转换属性),对该声明的修改可能会影响不同域中的声明(例如,关于任务的最坏执行时间、处理器的散热或容错复制结构中故障独立性的声明)。这些影响源于跨域依赖,通常被忽略或非正式处理。
- 可扩展的多域组合。为了处理跨域依赖关系,一些研究工作合并了多个域,以同时解决不同的跨域问题[Alur 1992,1993]。不幸的是,这些努力往往导致不可扩展的保证程序。因此,挑战在于保持独立域的可伸缩性,同时以合理的方式考虑跨域依赖性。Chaki等人的工作在两个领域实现了并发实时系统的可扩展保证:并发系统和实时可调度性[Chaki 2011]。利用实时可调度性分析(特别是作业到达的周期性)的假设,大大减少了周期性并发系统中需要检查的可能进程交织的数量。
5.5.3.5 论证的充分性
一个健全的保证论证系统应能够自动证明所提供的论据足以证明系统的行为符合预期,前提是在支持证据方面没有缺陷。然而,今天从业者使用的大多数方法使用替代标准(如分支覆盖或范围覆盖),这些标准为保证充分性提供了不充分的证据,并依赖于人的判断。这可能是不可避免的,因为对行为进行详尽的推理(例如,软件变量的所有可能值和线程执行的所有交织)可能是不可能的或不实际的。然而,一个合理的保证论据应提供一种方法,以确定证据不足对索赔信心的影响。
不幸的是,依赖于软件的系统(尤其是安全和关键任务的系统)的复杂性不断增加,长期以来,人类无法判断论证是否充分。此外,这种判断不仅必须在每个行为领域内进行,而且必须跨领域进行。显然,论证系统必须是实用的、可扩展的,并且在很大程度上是可自动匹配的,以支持日益复杂的软件系统。
这样的论证系统应该允许我们证明是否缺少论证。例如,考虑一个简化的安全气囊系统,它需要证明三个逻辑行为的声明:(1)存在成人乘客,(2)发生碰撞,(3)当且仅当(1)和(2)时触发充气。对保证论据的分析应能够推断不足(例如,应能够识别缺少定时行为声明和相应的物理行为声明)。在这种情况下,丢失的声明来自其他行为域,但这也可能发生在单个域中。推断不足将需要域和跨域的证明模板;典型系统的规范参数,可以为特定系统实例化,并帮助识别参数中缺少的元素。
5.5.3.6 保证论点的表达
一个通用和完善的论证框架需要(1)向人类解释为什么我们对论证有信心,以及(2)允许对构成案例的所有论证进行全面、正式和自动的整合。
正如上面的气囊示例所示,不同的技术领域使用形式化的演绎推理来抽象(或删除)某些信息。例如,逻辑验证(例如,模型检查)为计算的值转换性质建模。但是,它的模型不包含有关运行时间或执行时间的信息。因此,它可以推理值转换,但不能推理计算时间。
类似地,用于时间验证的实时调度模型考虑运行时间和执行时间,但忽略了计算产生的值。因此,这些模型无法对值转换进行推理。最后,使用微分方程的物理模型完全忽略了计算需要时间或算法以不同格式或位数表示数字。因此,这些模型不能充分考虑值转换的正确性或计算时间。
多年来,已经开发了一些多学科的组合(如嵌入式系统),以在组合模型中模拟计算值的转换和物理变量的演变[Alur 1993]。然而,这些组合往往会增加了质量保证系统的复杂性,并偏离了实用性。
Benveniste等人提出了另一个方向,他开发了一个框架,以指定行为集合的假设/保证合同【Benveniste 2015】。在这种情况下,用于捕获行为的特定形式没有定义。然而,该框架可以定义基于集合论的契约代数,这是关于可组合验证的原因。例如,框架可以定义如何组合模块的保证以验证全局属性,以及如何验证对模块的修改不会修改其做出的假设或提供的保证。
一旦契约代数的集合运算得到正确实现(例如集合交集、包含和并集),定义支持模块低层描述的行为形式可以来自不同的科学学科。此外,可以仔细设计这些操作,以最小化跨形式的交互,避免复杂性爆炸。Benveniste等人在这方面开展了一些初步工作【Benveniste2015】。这些属性允许更改保证参数的一部分,而无需重新验证与此模块交互参数的任何其他部分。这种方法支持通过组合推理来确保软件的演化,这对于在系统演化过程中确保系统的可靠性非常重要。Ruchkin介绍了结合不同类型分析对架构模型进行的其他研究[Ruchkin2014]。
5.5.3.7 生态系统架构
证据组合依赖于系统的结构,而系统的结构又赋予了系统的保证论据结构。论证的结构应该影响开发保证流水线。因此,需要的是一个证据系统和支持性基础设施,其中包括需要什么证据、如何收集证据、如何确保证据的可接受程度、在哪里存储、何时更新、存在哪些依赖关系等概念[Richards 2019]。特别是,系统中组件的假设和保证之间的依赖关系以及保证论据中不同类型证据的依赖关系必须精确。
这些关系提出了一个架构概念,其中包括上述关系,我们称之为“生态系统架构”。在这种情况下,生态系统架构被定义为软件依赖系统、保证论据、DevSecOps流水线和开发组织的聚合结构。这些结构相互关联和相互作用,众所周知,质量属性会影响软件架构[Bass,2012年]。
5.5.3.8 确保系统的演化
对于一个不断发展的系统,部署新功能和修复的速度与保证的全面性之间存在着天然的紧张关系。特别地,很难在有保证的情况下快速部署,需要决定如何修改现有测试,使其满足整个测试套件的一些充分性标准,需要花费大量时间。同样,很难理解变更的后果如何在系统中传播,特别是如果系统由独立开发和演化的模块组成的(尤其是这些模块仅由第三方供应商以二进制形式提供的)。
然而,减少变更系统的再保证工作很重要。对于今天的一些关键安全的系统,在通过认证后,很少或根本不允许更改原因是,确保变更不会引入关键缺陷的唯一公认方法是重新认证整个系统(例如,重新运行所有运行测试,可能需要数月时间)。由于这种重新认证的挑战,一些系统多年没有升级,这显然与其他要求不符,例如升级以满足快速发展的需求,或应用安全补丁修复漏洞。

5.5.3.9 边界传播
软件进化理论将为(1)确定(和限定)变更传播,以及(2)建议或预测基于系统行为、需求变化、操作环境变化等的变更需求提供基础。随着系统的发展,对系统的更改显然不是孤立地进行的,需要在现有系统的上下文中执行。对于任何系统,尤其是大型系统和系统体系,很难完全理解任何给定更改的未来后果。
例如,更改是否无意中引入了新的故障模式或漏洞?复杂的特征空间对于人类来说太难记住了。当从变更到出现错误的“距离”很大时,人类几乎不可能预测到由此产生的问题。此外,当变更的结果跨不同“技术领域”传播时(例如从安全性到实时性能再到数据分析),发现新引入的这些问题可能非常困难。系统中支持AI和ML的组件加剧了这个问题,不可能总是预测或检测到影响系统的环境变化(例如最初用于训练的数据分布的变化)。
5.5.3.10 确保紧急的属性
在进行更改后,很难重新获得对系统非功能性需求或紧急属性的信心,因为这些属性通常取决于系统功能独立部分之间的相互作用。例如,除非仔细设计系统,否则变更可能会无意中损害系统的安全性或定时属性。同样,系统外部环境的变化可能会使关于功能性和非功能性行为的保证索赔的假设无效或减弱。同样,使用模式的变化(例如,对系统请求组合的变化)可能会给设计带来压力,导致出现在变化的环境中无法接受的行为。一般来说,当评估变更可能影响期望质量属性的时候,当前的再保证实践方法并不稳健。
5.5.3.11 确保多行为的组合
更多的软件系统使用基于组件的技术和平台(其中许多是由第三方提供的)开发,我们需要可组合性理论以及相关的方法和自动化工具,以实现组合规则的规范和实施,这些规则都允许(1)在系统所需的所有行为域(即功能性和非功能性)中创建所需的行为(逻辑、定时、控制、安全、安全等),以及(2)在初始部署期间和后续演进期间,这些行为得到保证。这些理论、方法和工具,特别是当它们的结构和功能随时间动态发展时,必须能够推理在每个行为领域内和跨领域集成组件的后果。
5.5.3.12 使用可复用组件的安全系统
当系统主要由可重用组件(如产品线系统)组成时,保证实践的方法需关注保证的效率。例如,清楚与此类组件相关联的参数片段如何能够可靠、高效地组合和重用,以减少组合系统的保证工作。
5.5.3.13从运行经验中学习
如果一个不断演进的系统已经运行,那么可能存在关于其可靠性、安全性等方面的数据。AI和ML至少可以通过两种方式利用这些数据。首先,它可以用于检测与正常值的偏差;此类技术已用于分析网络流量以确保网络安全(使用宏观统计指标),但也可用于监测其他指标,例如电子商务系统(如Amazon.com)的订单队列长度。其次,本着Netflix混沌工程的精神,可以对系统进行假设性更改,AI或ML工具可以确定不同类型更改的传播模式。该分析可用于描述潜在问题的变化类别。
一般来说,我们认为,从观察运行中的系统、对其进行试验以及检查使充分性论证无效的变更模式中获得的经验,可以用于触发再保证或约束再保证。运行经验也证明了对系统保证论据充分性的信心。
5.5.4 研究中的问题
- 保证论据的合适表述是什么?
必须开发一种形式化和自动化的保证参数表示,它可以处理许多保证领域(例如逻辑正确性、定时正确性和安全正确性)及其相互作用。必须设计一种全面的论证机制,使用所有相关领域的证明系统来证明感兴趣的属性,并证明可用证据支持论点的程度。
更具体地说,这个整体机制应该表明(1)参数集合足以证明所有相关域的属性,以及(2)已经考虑了一个域对其他域可能产生的所有可能影响。一个全面的论证机制还必须支持发现缺失假设和无意中忽略的领域。论证模板或模式可能对此有所帮助。
为了使这一点具体化,可以从形式上对保证论据本身进行推理(例如,它是否合理?它的假设是否一致?它是否适当地解释了系统的所有方面?)。提供能够解决这些问题的陈述是一项基本挑战,只有如此才能确保系统不断发展。
- 保证论据演化的模式是什么?
考虑到关于系统的广义保证论据以及随后的系统变更,确定保证论据需要在多大程度上进行变更以解释系统变更,同时保持合理,这是另一个挑战。对于不断发展的系统,限制了再保证成本尤为重要。正如软件架构一样,改变的影响范围取决于参数的结构。构造参数将需要开发接口概念和保证参数的封装。
- 是否有机会使用ML自动检测保证论据中所需的更改?
自动从运行经验中学习可以通过发现运行行为模式来预测改变系统的需要,这些模式表明,新的、可能是意料之外的运行条件违反了保证假设,或者发现可能有缺陷的论证模式。
5.5.5 研究课题
这些研究主题对于确保软件系统不断演化非常重要,并将有助于开发有保证的软件演化理论。以下里程碑是发展这一理论的进展指标:
- 有保证的证据构成理论。开发一种总体方法或理论,用于确定证据系统的组成,允许组合来自不同领域的不同证据,以确保关键软件依赖性的系统属性。
- 保证参数模版。通过使用保证论据模板识别缺失的假设、域或域之间的交互,并适当地表示保证论据,开发一种确保论据充分性的方法。
- 可修改的保证论据。开发一种方法,通过生态系统架构的概念创建可修改的保证论据,并更好地理解使用可重用组件的保证系统。
- 如果系统变更使保证论据无效,则自动检测。开发一种技术,自动确定系统变更是否引入了新的故障模式和漏洞,或者通过确定如何约束变更传播和重新确保紧急属性。
- 基于操作数据的自动系统更新建议。基于使用从系统收集的数据学习操作经验,开发自动提出系统更新建议的技术。
- 用于组合证据以重新保证系统的工具链。开发集成工具链,包括AI和/或ML技术,以支持将多种类型的证据与操作数据相结合,从而重新保证系统的可靠性。
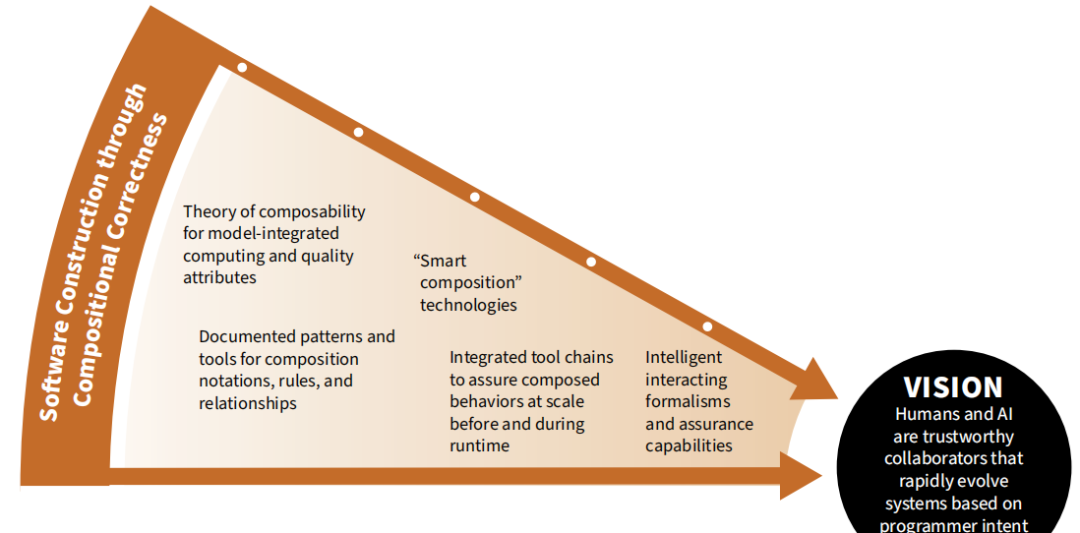
5.6 构建软件中组成正确性的重点研究领域
5.6.1 目标
为了应对与规模、复杂性及上市时间相关的挑战,软件系统越来越多地使用基于组件的技术进行开发。为了确保基于组件的系统满足其业务、技术和财务需求和约束,需要研究可组合性理论以及相关的方法、平台和自动化工具,以实现组合规则的规范和实施,从而允许(1)创建所需的行为(功能和质量属性),以及(2)在初始部署期间和整个生命周期中对这些行为的保证。因此,该研究领域的主要目标是开发和/或完善理论、方法、平台和工具,通过正确组合组件和推理各种组合的后果,特别是随着基于组件的系统结构、功能和起源的不断发展,增强我们构建软件的能力。
5.6.2当前实践的局限性
软件系统的范围和规模在不断增长和变化,包括关键任务和关键安全的网络物理系统,在这些系统中,正确的答案发布得太晚就会变成错误的答案,从头开始开发和维护软件对于大多数生产系统来说不再现实。此外,这些系统的规模和复杂性使得任何一个人或团体都无法理解整个系统。因此,使用模块化组件集成(并不断重新集成)的软件系统已成为常见且必要的。然而,这些组件中的许多都是从现有元素中重用的,这些元素最初可能不是为组合、集成或演化而设计的。这种情况在异构计算环境中尤其有问题,在这种环境中,组件是在质量和来源都有问题的平台技术之上,用一系列编程语言编写的。
自20世纪50年代以来,软件研究人员和开发人员一直在创建抽象,帮助他们根据自己的设计意图进行编程,而不是根据CPU、内存和网络设备等底层计算环境的反复无常进行编程,并使他们免受这些环境的复杂性影响。从计算的早期开始,这些抽象包括语言和平台技术。例如,早期的编程语言,如汇编和Fortran,使开发人员不必直接使用机器代码进行复杂的编程。同样,早期的操作系统平台,如OS/360和Unix,也为开发人员直接从硬件编程的复杂性中屏蔽了出来。
尽管这些早期的语言和平台提高了抽象级别,但它们仍然有一个明显的“面向计算”的重点。特别地,他们关注的是解决方案空间的抽象(即计算技术本身的领域),而不是问题空间(即应用领域,如电信、航空航天、医疗保健、保险和生物学)的抽象。此外,在这些低层次抽象之上从头开始创建或重新创建应用程序需要付出太多的努力,而不是根据应用程序的域概念表达设计,然后使用可集成到应用框架和软件产品线中的可重用组件组合应用程序。
然而,尽管取得了这些进展,仍存在一些棘手的问题。这些问题的核心是平台复杂性的增长,它的发展速度超过了通用编程语言掩盖复杂性的能力。例如,流行的中间件平台,如Spark、Data Distribution Service(DDS)和Android包含数千个类和方法,这些类和方法具有许多复杂的依赖关系和微妙的副作用,需要付出相当大的努力才能正确组合、调整和调优。此外,这些平台通常发展迅速,因此开发人员需要花费大量精力手动将其应用软件移植到不同平台或同一平台的更新版本。
一个相关的问题是,大多数应用程序和平台软件仍然是使用第三代语言手动编写和维护的,这需要花费过多的时间和精力,特别是对于与集成相关的关键活动,如系统部署、配置和质量保证。例如,很难编写Python或C++代码来正确、优化地部署具有数百或数千个互联组件的大型分布式系统,而这样的系统在社会规模的软件系统中越来越常见(见第5.7节)。
即使使用更新的符号化方法,例如在Android等中间件平台上流行的基于可扩展标记语言(XML)的部署描述符,也充满了复杂性。这种复杂性很大程度上源于抽象级别之间的语义鸿沟。例如:
- 设计意图(例如,根据系统资源要求和可用性,将组件1-50部署到节点A-g上,将组件51-100部署到节点H-N上)
- 用数千行手工编制的XML来表达这一意图,这些XML的视觉密集语法既不传达领域语义,也不能完整传达设计意图
面对这些类型的问题,软件行业正在达到复杂性的极限,现代的平台技术,如云部署中的反应式微服务[Gillberg 2020],变得如此复杂,以至于开发人员花费数年时间掌握和努力处理平台API和使用模式,但通常只熟悉他们经常使用平台的一个子集。此外,第三代语言要求开发人员密切关注许多命令式编程细节,例如正确终止循环;正确检测和处理错误和异常情况;以及避免缓冲区溢出、空指针和动态分配内存的双重删除[Seacord 2005]。
这些类型的策略问题使得开发人员很难集中精力解决战略性的架构问题,例如系统范围的正确性和由可重用组件组成的应用性能。尽管现代交互开发环境(IDE)有助于解决其中一些战术问题(例如正确管理动态内存管理),但IDE检测和帮助纠正常见编程错误的能力有限。同样,IDE为指导架构模式的正确应用提供了有限的支持,这仍然需要大量的手动设计和实现工作。
当今分布式的工具和方法也使得软件开发人员很难知道其应用程序的哪些组件和子系统容易受到用户需求、语言和平台环境变化所产生的副作用的影响。缺乏集成视图,再加上由质量和来源有问题的软件组件所产生的不可预见的副作用危险,常常迫使开发人员实施次优解决方案,这些解决方案不必要地重复代码,违反关键架构原则,并使系统演化和质量保证复杂化。在开发和确保持续发展的关键任务和安全网络物理系统时,次优解决方案尤其有问题(见第5.5节)。

5.6.3研究课题
5.6.3.1通过模型驱动工程(MDE)工具实现成分正确性
为了解决平台复杂性以及第三代语言无法缓解组合复杂性,并可靠、安全地表达领域概念的问题,一个有希望的方法是开发和应用模型驱动工程(MDE)技术[Schmidt 2006],例如MATLAB、Simulink、Rhapsody和架构分析与设计语言(AADL)[SEI 2019]。与使用第三代语言(如Java、Java Script和C++)编程不同,这些模型驱动方法使软件开发人员能够通过结合以下内容进行更高级别的编程:
- 特定领域建模语言(DSML),其类型系统将特定领域内的应用程序结构、行为和需求形式化,例如软件定义无线电、航空电子任务计算、在线金融服务、仓库管理,甚至中间件平台领域【Voelter 2013年】。DSML使用元模型进行描述,元模型定义域中概念之间的关系,并精确指定与这些域概念相关联的关键语义和约束。开发人员使用DSML构建使用元模型捕获的类型系统元素的应用程序,并以声明方式而非强制方式表达设计意图。
- 转换引擎和生成器,用于分析模型的某些方面,然后合成各种类型的工件,例如源代码、模拟输入、XML部署描述或替代模型表示。从模型合成工件的能力有助于确保应用程序实现与模型捕获的功能和服务质量(QoS)需求相关的分析信息之间的一致性。这种自动转换过程通常被称为“通过构造进行纠正”[Ge 2018],与传统的手工“通过纠正进行构建”的软件开发过程相反,这些软件开发过程冗长、容易出错且难以保证。
基于早期通过更高级别的平台和语言抽象开发以及组合软件的工作,产生了现有和新兴的MDE技术。与很少表达应用程序域的概念和设计意图的通用符号不同,DSML可以通过元建模进行定制,以精确匹配域的语义和语法。类似于最终用户操作的特定应用程序域的方式,DSML来表达行为或计算。
例如,金融系统可以用账户和分类账来表示行为或计算。另一个例子是,航空电子系统可以表达速度、速度和高度方面的行为和计算。从本质上讲,MDE技术使编程软件能够使用DSML在更高的抽象级别上进行编程,DSML扩展了第三代语言的语法和语义,以在流行的平台和框架之上开发应用程序。因此,MDE方法和工具可以通过组合的正确性来简化软件的构建,使软件开发人员能够关注通过使用DSML创建的模型表示的以域为中心的业务逻辑。然后,他们的大部分应用程序可以从这些更高级别的模型中合成和/或集成,这些模型可以可靠、安全、高效地映射到底层软件框架和平台上。
DSML通常以图方式表示域中的元素,而不是纯粹以文本方式表示(就像第三代语言一样)。拥有与熟悉领域直接相关的图不仅有助于拉平学习曲线,而且有助于更多领域的专家,如系统工程师和经验丰富的软件架构师,确保软件系统满足用户需求。此外,MDE工具会施加特定领域的约束,并执行模型检查,以在软件和系统生命周期的早期检测和防止许多错误。
此外,由于如今的平台比20世纪80年代和90年代的平台具有更丰富的功能和QoS,因此MDE工具生成器不需要那么复杂,因为它们可以合成映射到更高级别、通常是标准化的中间件平台API和框架,而不是更低级别的OS API的工件。特别地,MDE方法和工具可以采用DSML中的表达式,并自动生成大量代码,然后这些代码与通过现代中间件平台(如Spring或React.js等)创建的组件相连接。因此,开发、调试和使用这些工具和相关模型驱动中间框架创建的MDE工具和应用程序通常更容易[Costa 2017]。
集成MDE工具和中间件平台以端到端部署应用程序服务,可以进一步帮助开发人员以正确的方式将正确的服务集配置到应用程序的正确部分。MDE分析工具可以帮助确定应该在整个网络中部署到各种组件服务器中的功能的适当分区。例如,MATLAB、Simulink、TimeWiz和RapidRMA等工具允许应用程序开发人员对其应用程序端到端(及其QoS要求)进行建模和可视化。特别是,Simulink允许应用程序开发人员为关键任务和安全网络物理系统建模、分析、模拟、验证和快速原型的应用程序。

5.6.3.2 通过依赖注入框架来实现成分正确性
过去十年见证了另一种方法的发展,该方法用于解决繁琐且容易出错的代码问题,而这些代码通常是由于仅依赖第三代语言来创建系统而导致的。不是以MDE构造的形式表示软件行为(例如许多程序员可能不熟悉的定制的领域特定建模语言),软件开发人员可以用他们选择的编程语言编写大部分业务逻辑,然后用各种标记来声明性地注释此代码,这些标记提供注释处理工具使用的信息。反过来,这些工具可以通过依赖注入(dependency injection)自动生成和组合软件,这是一种高级的关注点分离形式,用于通过“自动连接在一起”来构造和组合组件,从而提高可读性、代码重用和自动化。
依赖注入框架,如Spring和Dagger,允许程序员通过注释声明性地指定某些属性[Patel 2018]。然后,这些注释由生成并连接大量“粘合代码”的工具自动处理,从而最大限度地减少持久性、远程通信和安全性以及数据访问和操作等方面的软件开发。这些注释处理工具检查、生成和组合合成工作应用程序所需的各个方面。
基于注释的依赖注入框架通过组合正确性简化了软件构建[Bojkic 2020年]。特别是,软件开发人员主要关注用熟悉的编程语言编写的业务逻辑,然后将注解放在某些类中。最后,注解处理工具检查并生成创建和组成工作应用程序所需的许多“粘合代码”。
例如,要将特定类指定为提供数据的类,可以使用@data注解指示注解处理工具生成具有某些附加功能的代码,例如setter/getter方法更新/读取特定对象中的字段。@Value等注解还可以指示实体(如对象)将永久存储在数据库中。还可以对某些字段进行注解(例如,通过@Id注解),以表明它们打算用作数据库中的主键。
这些声明性注解使软件开发人员能够表达关于类中字段和元素的元数据,这样程序员就不需要自己编写所有这些代码。注解工具基础设施反而会生成粘合代码和其他重要任务,例如确定不同定义组件之间的依赖关系。这些工具还可以自动组合依赖项,而无需进行显式组合。例如,软件开发人员可以确定某个特定类依赖于另一个类,然后用另一个注解(例如@Autowired)对其进行注释。这样的注解对工具基础结构表明,它需要检索该实体的实现并安排将各个部分连接在一起。
注解处理工具与依赖注入框架一起工作,以实例化其他依赖组件并将它们连接在一起,因此软件开发人员无需手动建立所有连接、集成和组合。相反,软件开发人员声明这些依赖项,框架识别实现并自动组合它们。这种松散耦合使软件开发人员能够以更模块化的方式编写组件,然后利用工具基础设施代表他们执行正确的组合。
基于注解的依赖注入框架不仅是构建新软件系统的一种更高效、更不容易出错的方法,而且由于广泛用于互联网编程,因此它已经变得流行起来。特别是,像Spring这样的框架封装了流行的低级协议和符号,如超文本传输协议(HTTP)、JavaScript对象符号(JSON)和可扩展标记语言(XML),它们在客户端和服务器之间编码和交换数据类型。反过来,这些低级通信和数据传输机制可以通过注释(如@GetMapping和@PostMapping)进行封装,这些注释可以自动将通过传输控制协议(TCP)连接发送的HTTP GET和POST请求转换为使用流行的第三代语言编写业务逻辑的对象上的常规方法调用。
Spring等依赖注入框架使软件开发人员能够注释(例如,通过@RestController标记)一个常规类,以指定传入的HTTP GET和POST请求应路由到其端点方法,并使用常规方法调用进行处理。特别是,诸如@PostMapping或@GetMapping之类的注释可以在HTTP级别指导传入的请求,将它们路由到适当的端点方法,然后调度此方法来处理HTTP消息中包含的内容。这种基于注释的方法使软件开发人员能够专注于业务逻辑,而不是将消息从客户端发送到服务器所涉及的复杂问题,所有这些都是通过声明性注释和自动生成完成的,而不是开发人员手动编写必要的代码。
通过使软件开发人员能够定义其组件和应用程序,而不必担心用于在它们之间操作的通信机制,就不再需要创建所有组件都驻留在单个地址空间中的不灵活的单片应用程序。相反,微服务架构已经出现,它通过组合许多较小的元素(即微服务)来构建软件,这些元素的配置可以定制并部署到底层计算基础设施上,例如Amazon Web Services(AWS)、本地私有云或物联网传感器网络[Lira 2019]。这种松散耦合的体系结构通过利用多核进程和分布式核心集群实现了系统的可扩展性,因为系统由位置可以相对灵活和透明地改变的小组件组成。
依赖注入框架还使用软件构建管理器,如Gradle和Maven,允许应用程序开发人员以高度灵活、可编程和后期绑定的方式指定他们所依赖的库。反过来,这些功能支持从万维网提供的许多库和包中动态组装和演化组件实现。特别是,这些组件不需要驻留在本地构建计算机上,而是可以从远程存储库自动下载并在开发过程中安装。

这种软件依赖关系解决的后期绑定方法允许开发人员从组件中组合软件,其中一些组件是他们编写(和注解)的,但大多数组件是由其他开发人员编写的。依赖注入框架和构建工具跟踪所有这些依赖项,组合所有内容,并连接所有组件,而无需软件开发人员进行大量的手动工作。
5.6.4 研究问题
基于前一节描述的方法、工具和平台,通过组合正确性实现软件构建有许多研究问题,包括:
- 我们如何确保通过松耦合组件开发的系统?
虽然软件开发人员可以从MDE工具和依赖注入框架中获益,以生成和组成其软件系统的大部分,但挑战依然存在,因为模型和注解通常很难在“源”级别进行调试,因此很难静态保证。这种困难的一个原因是这种松散耦合系统中存在的隐式依赖关系。特别是,在检查源代码本身时,很难静态地确定在合成和连接各种组件后将提供哪些实现。
这一挑战促使人们需要对注释浏览器和静态依赖关系分析器进行深入研究,以了解组成松耦合的基于组件的系统的各个层和工具链的语义。同样,还需要研究“智能组合”方法、工具和平台,通过自动生成适配器来提供高效且类型安全的语义集成,从而智能且正确地组合最初未设计为协同工作的组件。
- 我们如何确保系统在运行之前能够正常、安全地运行?
由于缺乏高级可视化或测试工具,例如基于DevSecOps方法和工具的质量保证管道,以及理解注解语义和依赖注入框架的后期绑定的工具,软件工程师和操作人员通常不知道松耦合的基于组件的系统在开始运行之前是否能够正常工作。虽然单元测试或集成测试是确保传统软件系统的一种久经考验的方法,但对于某些类型的安全关键或任务关键的系统(即航空电子设备、医疗设备或核反应堆),这些方法通常是站不住脚的,在这些系统中,系统操作人员必须确信他们在运行之前能够正常、安全地运行。
使用基于注解的依赖注入框架,软件开发人员需要更好地保证系统在软件生命周期的早期能够正常工作。这一需求为研究人员提供了一个开发更好的工具的机会,可以进行更深入的分析,并提供更大的信心,使系统在运行时执行之前能够按预期工作。
- 我们如何调试使用模型驱动或依赖注入方法开发的软件?
如果使用模型驱动或依赖注入方法,则通常缺少允许开发人员在编写软件的级别(与生成软件的级别相反)逐步调试软件的调试器。这个问题应该为前几代软件开发人员所熟悉。在编译器和其他语言处理工具出现的早期,程序可以用高级语言编写,如Fortran或C,但允许在高级语言级别进行程序调试的源代码级调试器最初并不可用。相反,软件开发人员必须在汇编代码级别进行调试,这很繁琐而且容易出错。
这些类型的限制使得调试高级代码变得很困难,因为开发人员不得不继续依赖于编译器生成的低级代码,而不是他们编写的代码以及编译器用作输入的代码。有了模型驱动的工程和基于注解的依赖注入框架,抽象级别已经提高了许多层。这种不断增长的抽象级别堆栈促使研究开发可以在模型级别或注释级别调试代码的工具,而不是这些自动处理工具生成的代码级别。
5.6.5研究课题
如前几节所示,软件社区需要关注不断发展的形式主义和工具,以解决所描述的问题。
我们邀请研究人员和从业人员提高使用这些方法开发的任务和关键安全系统的安全保障水平。研究主题将逐步增加,总结如下:
- 模型集成计算和质量属性的可组合性理论。开发一种新的可组合性理论,该理论使用建模和质量属性概念来集成根据基于组件的技术(包括但不限于模型驱动的工程和/或基于注释的依赖注入框架)开发的组件,并确保“烘焙”到完整的组合中。
- 用于合成符号、规则和关系的文档化模式和工具。开发组合工具、符号和规则,以确保组合系统的质量属性,并减少纯运行时测试的需要(即,能够在软件生命周期的早期阶段检测缺陷)。
- “智能合成”技术。通过自动生成提供高效且类型安全的语义集成的适配器,创建能够智能且正确地组合最初未设计为协同工作的组件的方法、工具和平台。
- 集成工具链,确保在运行之前和运行期间按比例组合行为。开发工具,为质量属性工程权衡空间决策提供信息,以实现大规模系统组合并确保组合行为。
- 智能交互形式和质量保证的能力。建立一种方法,使开发人员能够使用多种形式(例如,结合模型驱动和基于注释的方法)来组成系统并衡量对保证的影响。
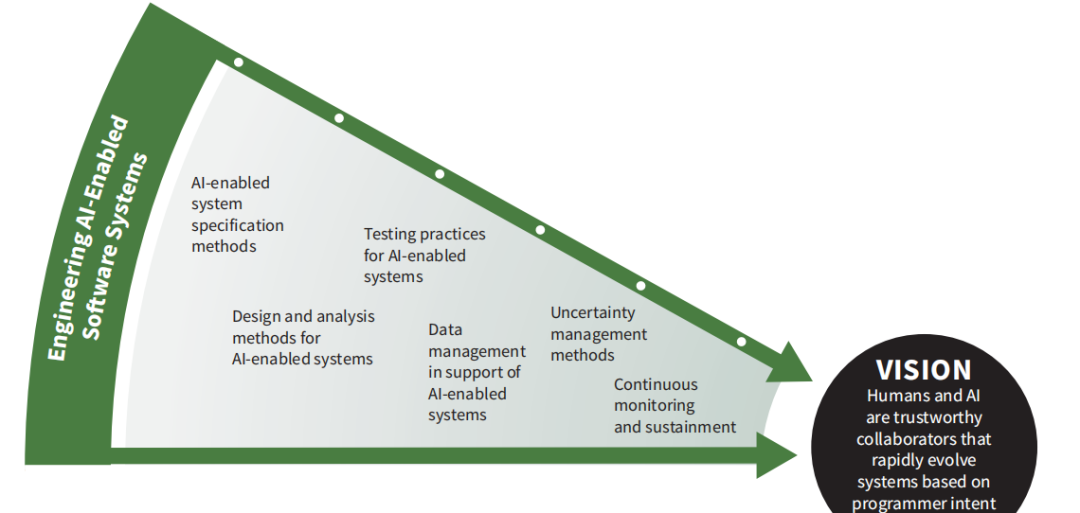
5.7 AI赋能工程化的软件系统重点研究领域
5.7.1目标
未来的系统,从智能城市和建筑到国防和交通系统,再到医疗保健,都可能包含人工智能元素。特别是对于国防应用,人工智能软件系统承诺能够通过开发自适应系统提高对不断变化的任务的响应速度,并促进信息优势。
ML算法的进步和计算能力的增加已经导致了对渴望利用人工智能的系统的巨大投资。人工智能系统是一种依赖软件的系统,它包括实现模拟学习和问题解决的人工智能算法的数据和组件,与不使用人工智能组件的软件系统相比,具有本质上不同的特征。这些差异正在推动学术界、工业界和政府探索创建一门名为AI工程的新工程学科【Horneman 2019;Bosch 2020;Santhanam 2019】。开发和采用安全、合乎道德和安全的变革性人工智能解决方案需要培育人工智能的工程领域。CMU定义了一个称为AI堆栈的抽象技术模型,以推动对AI支持系统的开发和部署的清晰理解【Moore 2018】。SEI进一步确定了可扩展AI(重点是如何扩展算法、数据和基础设施)、健壮和安全AI(着重于了解保护AI系统免受新的对抗威胁的挑战),人机合作(重点关注决策与人工智能元素驱动的交互挑战)是推动人工智能工程实践定义的三个重要支柱[SEI,2021]。
然而,人工智能系统首先是软件系统。这些系统的开发和维护与软件系统的构建、部署和维护有许多相似之处。软件工程的研究项目需要关注人工智能元素给软件分析、设计、构建、部署、维护和演化带来的挑战。因此,本研究领域的目标是探索哪些现有软件工程的实践能够可靠地支持人工智能系统的开发,以及为了可靠地构建人工智能软件系统,需要解决哪些新的软件工程研究挑战。
5.7.2当前实践的局限性
在未来十年,人工智能系统可能会继续被ML算法的进步所主导,特别是由于研究的激增和正在出现的快速进步,与深度学习的进步有关。将AI和ML组件整合到软件系统中,加剧了工程软件所涉及的许多现有挑战,无论是否有AI元素:例如,如何对系统有信心,如何预测和控制紧急行为,如何在数据中存在不确定性时正式规定需求,以及从数据中提取的模式,以及如何控制和管理变化。将ML组件开发引入系统开发的尝试突出了模型开发、软件开发、基础设施开发以及操作过程和工件之间的瓶颈和不匹配[Amershi 2019;Lewis 2021]。
将当前的软件工程实践应用于人工智能系统的开发面临以下限制:
- 当将传统软件开发活动与ML模型和其他AI组件开发中固有的实验性、迭代性和增量性质结合起来时,软件开发过程(包括敏捷过程)可能会带来挑战[Amershi 2019;Rahman 2019]。ML模型开发依赖于生成和测试方法,这些方法使得很难与sprint边界和大多数软件开发过程中常见的已完成标准的识别保持一致。
- 为训练ML模型而开发的系统可能很昂贵。解决这一挑战的一种方法是开发不需要提前培训模型的自我监督系统,并转移标记工作[Hendrycks 2019]。在这些系统中,工程师专注于监控模型并对变化做出反应。这种向自我监督系统的根本转变将继续下去。然而,需要开发新技术来解决系统的哪些元素可以自我监督,自我监督元素如何与自适应元素(尤其是自适应软件系统)协同工作,以及系统监控和可观察性的挑战(除其他外)。
- 支持系统集成和模型开发的平台假设现有软件平台将按现成规模扩展,以支持AI组件与系统其余部分的集成。缺乏确保部署后成功部署和维持人工智能系统的技术。尽管基于现有软件工程技术的方法已经出现,例如MLOps(将DevSecOps原则应用于ML组件开发),但它们仍然依赖于没有适当度量和分析的现有工具来向开发人员提供及时和相关的信息。
- 包含AI组件的系统无法进行可靠测试、验证和认证。随着人工智能等新计算范式的引入,无法保证安全性和安全性。虽然人工智能工程的新兴领域侧重于算法信任等技术,但迫切需要软件测试和分析技术来支持人工智能组件和人工智能系统的测试。
5.7.3 研究课题
为了克服这些局限性,研究将需要集中在使用人工智能组件及其设计、架构、分析、部署和维持的系统规范中,增强软件工程技术。特别是,需要在下述领域取得进展。
5.7.3.1 人工智能、系统特定质量属性和架构关注点
质量属性,或用于评估系统质量和适合其任务目标的属性,推动架构(architecture)方法的选择,进而推动软件系统的结构和行为【Bass,2012】。业务和任务目标驱动领域和相关类型的系统,它们在确定高优先级质量属性方面都至关重要。识别人工智能系统的驾驶质量属性,具体说明这些属性,并了解如何对其进行分析,需要进一步研究。虽然特定的使命和业务目标将塑造预期的质量属性,但其他目标也可能成为首要任务。这些属性至少包括可解释性、数据中心性、可验证性、可监控性、可观察性和容错性[Pons 2019]。需要开发分析技术,以确保其正确设计和实施。这些属性还将推动解决公平、偏见和道德问题的技术发展。伦理学是一门复杂的学科,需要在政策、社会科学和技术领域取得进展。然而,道德的某些方面将落在我们将其设计成人工智能系统的能力的保护伞下[Ozkaya 2019]。
5.7.3.2 规定不确定性和AI激活系统行为的方法
有些系统的需求我们可以并且确实预先知道,或者我们可以通过迭代轻松发现。这些系统往往是可管理的系统。实际上,许多软件系统,即使没有人工智能组件,也需要在整个开发过程中对不确定性和“未知的未知”进行建模。不确定性是人工智能系统的主要特征。特别是,ML建模活动引入的数据学习和发现过程引入了许多不确定性。需要扩展现有的软件需求工程和可追溯性技术,以将AI问题和模型规范(驱动ML组件开发)与系统规范(驱动最终系统的测试和评估,包括AI、数据和其他软件元素)分离开来。
5.7.3.3 分析和管理变更的技术
难以跟踪的依赖项,特别是由数据依赖引起的依赖项成为ML系统中的一个重要故障源。这些隐藏且不稳定的数据依赖性使得应用已知的体系结构模式来管理系统演化和分离关注点具有挑战性(例如,当输入来自另一个随时间更新的ML模型)。谷歌工程师引入了“Changing Anything Changes Everything”(CACE)原则,使用ML组件的系统不仅高度耦合,而且更加复杂【Sculley,2015年】。然而,现实情况是,隐藏的依赖关系一直是管理的挑战,尤其是运行时的依赖关系,因为软件工程师缺乏工具来分析、建模和可视化这些依赖关系。人工智能系统固有的数据依赖性表明,我们需要更快地使用那些缺乏的工具。CACE原则意味着迫切需要更好地管理变更传播,以减少预期结果的不确定性,并提高工程师对系统调试的能力。改进软件工程工具和技术,并分析和保护变更传播的系统将是一个重要的优先事项。

5.7.3.4 人工智能系统的可靠性
人工智能系统可靠性分析和设计所面临的挑战与嵌入式实时系统类似。两者通常都是通过集成许多不同的软件和硬件组件来开发的,其中一些组件可能由不同的方开发和拥有。人工智能组件也将日益独立开发;因此,我们需要技术来分析它们的属性,以预测它们的行为,并将它们可靠地集成到系统的其余部分。软件系统未来的实际情况是,此类不同组件的数量将越来越多,它们将引入系统设计和操作的异构性。这些不同和异构的系统将需要软件工程师和人工智能工程师承担正常故障,并开发安全技术,以确保可靠的系统设计、开发和操作。
5.7.3.5 监测和自适应
随着人们对数据在人工智能系统成功中作用的认识不断加深,将推动人们在克服数据缺乏、数据噪声以及数据标签技术带来的挑战方面取得快速进展。它还将推动强大数据工程流水线的开发。因此,挑战将转向高效部署和维持人工智能系统。当前的监控方法主要依赖于收集通用系统指标,例如系统的吞吐量和资源消耗。需要进一步研究监测技术,以提供漂移检测信息和最佳再训练时间。需要考虑监测和自适应的不同方面,包括监测数据和数据变化、监测模型(以及模型是否继续按预期运行)以及监测带有人工智能组件的系统。关于自适应和自愈系统的现有软件工程需要考虑人工智能组件带来的挑战,特别是对数据的依赖性,以及这些数据依赖性如何影响系统的其余部分及其自适应响应。考虑到意外后果和不正确模型行为的影响,需要开发新的监测和适应技术。
5.7.3.6 人工智能系统的测试、部署和维持
人工智能系统的开发和部署,尤其是支持ML的系统,涉及三个不同的视角(以及各自的工作流程和角色):数据科学、软件工程和操作。当这三个不同的视角由于不正确的假设而错位时,可能会导致不匹配,从而导致系统失败。需要改进指定和检测这些不匹配的自动化和形式主义,将这些工具纳入部署工作流和MLOps管道,并开发测试技术,扩展现有软件测试方法,以有效测试AI组件。目前,AI组件的测试依赖于临时或手动测试实践。ML组件的测试技术与传统软件组件和系统的测试技术类似,是一个需要解决的缺口。
5.7.4 研究问题
通过软件工程研究支持人工智能系统的需要已经达到了一个类似于安全性、可用性和隐私性必须被视为软件系统的主要质量问题的阶段:如果我们不为系统用户和可用性架构师设计,系统就会失败。今天,安全性、可用性和隐私是许多其他主流系统关注的问题之一,我们有常用的词汇表和分析方法来设计和检查这些属性。在识别和理解人工智能系统的特定特性方面也需要取得类似的进展。现有的设计、测试、评估和数据管理技术将帮助我们了解如何设计、部署和维持人工智能系统的结构和行为,它们还将为未来5至10年解决以下关键研究问题提供一个垫脚石:
- 支持可解释和可信的人工智能系统的关键质量属性和架构模式是什么?哪些设计策略和分析技术支持实施这些属性?
- 如何对不确定性建模,以帮助管理和监控AI启用的系统行为?
- 哪些指标能够对人工智能和非人工智能组件进行细粒度监控,以获得及时的维持决策,如再训练、停用、新数据收集和任务驱动的决策?
- 启用AI的系统在部署后如何自我修复和纠正错误?
- 如何将操作分析无缝地纳入AI支持的系统开发和部署,以及如何由MLOps框架中的工具支持?
- 哪些现有软件测试技术可以支持测试AI组件?带有AI组件的系统的单元、集成和回归测试是什么样的?
5.7.5研究课题
在这些领域取得进展的能力将依赖于其他领域,所有这些领域的工作都需要立即开始。进展将是迭代和增量的,以下里程碑将为成功提供引导:
- 支持AI系统的规范方法,开发来明确AI启用系统行为的方法。
- 人工智能系统的测试实践。需要很好地理解人工智能系统的单元、集成和回归测试实践。
- 人工智能系统的设计和分析方法。关键的人工智能系统质量属性关注点,包括可解释性、可监控性、可靠性和信任,将需要架构模式、策略和分析方法的支持。
- 支持人工智能系统的数据管理。分析和一致性工具需要很好地支持理解数据对系统行为、数据架构和变更管理的影响。
- 不确定性管理方法。需要有针对不确定性建模、分析和设计的技术。
- 持续监测和维持。人工智能系统需要得到有效监控、自我修复、进化和维持。
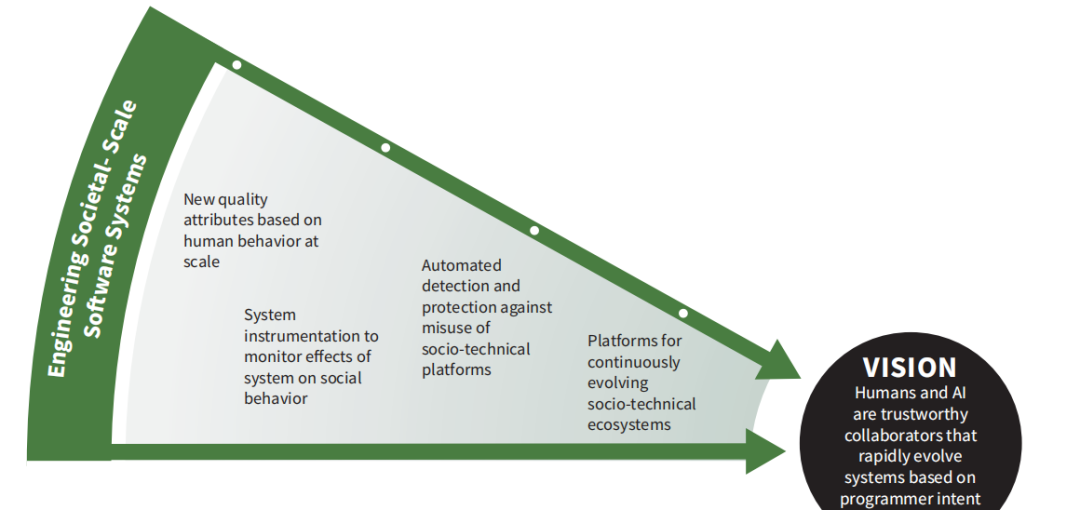
5.8 社会规模系统工程化的重点研究领域
许多社会规模的软件系统,例如今天的商业社交媒体系统,旨在影响人们并让他们参与其中。开发和部署此类系统的公司通常通过销售有针对性的广告来促进产品和服务,或者通过其他方式施加影响,例如倡导特定的政治观点。避免偏见和确保信息的准确性并不总是这些系统的目标或结果。
5.8.1目标
社会规模系统的软件工程侧重于预测当人类是系统的组成部分时产生的全方位影响,包括意外后果和误用和操纵的可能性(我们称之为社会启发质量属性)。目标是利用社会科学的见解来构建和发展社会规模的软件系统,以实现其预期目的,并将不良或意外后果的风险降至最低。研究将有助于更好地预测系统行为,以构建和发展社会规模的社会技术软件系统,构建和发展以人为组成部分的系统,并持续降低意外偏见、错位信任、违反隐私预期、隐蔽影响或无限制社会操纵的风险[Feiler 2006]。
社会规模的系统比传统的社会媒体系统包含更多的内容。这些系统的基本特征是,它们是信息和通信渠道,可将期望的结果(如参与和行动)作为主要收入来源。以下是一些示例:
- 社交媒体平台,如Facebook、Twitter和Instagram
- 搜索平台,如谷歌搜索和YouTube,帮助人们在互联网上或由该服务托管的网站上查找所需内容,并根据数据提供个性化建议
- 检测软件开发人员知识并调整其经验以指导或培训开发人员的系统
- 试图根据搜索或其他数据预测事件(如校园枪击、流感爆发和超级传播者)的系统
- 游戏化,增加个人健康或金融活动等领域的参与度
5.8.2当前实践的局限性
社会规模的软件系统将人们联系在一起,并提供了新的通信机制,使人们能够从寻找久违的朋友到家庭成员的即时更新等方面受益匪浅。然而,今天的系统旨在最大限度地参与和影响人们。对于这些系统如何随着时间的推移影响个人行为或如何预测数百万人的总体行为,人们的理解非常有限。工程社会规模系统在现有实践状态下的局限性,缺乏缓解这些问题所需的理解和保障,对个人和整个社会都造成了严重风险,因为偏见和错误信息会产生不可预见和无限制的后果。
尽管社会规模系统在世界各地都很流行,并且是最常用的软件系统之一,但这些系统的当前工程实践存在很大的局限性,包括以下方面:
- 社会规模的软件系统整合了人工智能,创造了新的信息流,并重塑了社会知识,但人们对社会技术系统的行为方式知之甚少。人们对这些信息源的反应是改变他们的行为,而这些行为并不总是可以预测的,甚至是不可见的【Centola,2018年】。由于信息流频繁变化,而且信息并不总是经过真实性、偏见或操纵的审查,因此理解影响和响应变得更加复杂。
- 当前,社会规模系统的开发主要是为了通过个人互动最大限度地参与,共同创建社会网络。社交网络可以用来影响社会行为或感知。这些技术使用高度针对性的个性化来影响个人行为。这种影响可能导致两极分化,并可能导致社会知识的总体扭曲。研究表明,算法可能会产生负面的作用,导致人们走向极端,并可能导致新的安全风险【Carley 2020年】。当前的工程实践没有评估个人参与算法的框架,也没有针对社会知识不受控制的扭曲创建保护措施。
- 社会技术系统每天为世界各地数十亿人提供直接联系,这大大增加了舆论操纵的潜在规模。与以前的被动媒体(如电视)相比,社会规模的系统使用主动互动和大量互动数据,这使得目标说服具有前所未有的有效性和规模。这种能力本质上使影响力民主化,允许个人、组织或国家操纵【Waltzman 2017年】。由于对这些系统缺乏了解,操纵可能是无意的,也可能是故意的,因为某些国家或流氓行为者创建了在线活动来操纵人口。对于许多人来说,这些系统创建了一个不同的虚拟社会,并允许使用不同的规则和行为规范进行交流,这可能导致错误的共识、偏见和两极分化。
5.8.3研究课题
为社会规模系统构建新的软件工程方法需要跨学科方法。正如计算社区联盟(CCC)最近的研究议程所述,软件研究“……将需要人文、社会科学、教育、新闻和计算机科学的融合,并得到广泛组织和机构的全面支持和参与”【Bliss 2020】。了解我们可以从这些学科中汲取什么,对于明确软件工程研究以构建未来的软件系统至关重要。

5.8.3.1 新的质量属性和架构
社会规模的社会技术系统具有尚未充分理解的新质量属性。如今,大多数软件架构的创建都是为了支持人们熟知的质量属性之间的权衡,例如性能、可靠性和安全性。定义新质量属性的部分目标包括定义绩效指标以及如何衡量绩效。
讨论质量属性的目的是了解社会规模系统中的设计决策与使用中的系统行为之间的关系。需要新的方法来处理人类行为的许多方面。对人类具有可预测影响的工程系统将有助于避免潜移默化的意识形态影响。信任、隐私和偏见并不是全新的,但新的是预测和监控这些属性的挑战。
我们想用社会科学作为理解这些质量属性的基础,就像我们用物理科学作为其他质量属性设计的基础一样。一种方法是将质量属性的可衡量表现与解释分开。例如,将投票作为衡量优点的标准(如最佳产品或解决方案)似乎很有用,但也存在挑战,包括偏见和理解选民样本的偏见。其他注意事项包括:
- 社会规模社会技术系统的新质量属性是什么?
- 我们如何识别和捕获社会规模的需求?
- 我们如何将个人选择联系起来,以预测更大的总体行为,并从工程角度确定它们是否在“预期”范围内?
- 我们如何开发跨组织和跨系统的扩展并实现个人控制的隐私模型?
- 我们如何确保对数据的信心?
5.8.3.2 使用社会学技术的软件系统开发
当软件工程师使用社会学技术构建软件系统时,会出现一种特殊情况。这是一个有趣的社会规模系统的使用,就是这些系统对软件工程师和软件工程活动的影响。这些系统和开源环境允许人们访问大量代码,并创建一种既影响软件工程师又受其影响的数字基础设施。示例包括:
- stack overflow,人们可能在不考虑其来源或影响的情况下使用解决方案
- GitHub,其中挖掘代码可能导致对软件质量的假设,并可能影响开发人员
- 社交编码环境,在技术决策过程中使用人气、用户或追随者数量、链接和大量其他类型的社会信息,例如采用的库和框架
- 新的学习方式,从大规模的在线课程(MOOC),到通过YouTube教程学习的开发人员
研究社会规模系统如何影响软件开发,对于更好地理解如何提高软件质量以及考虑如何集中这些影响以帮助解决劳动力挑战至关重要。例如,如果社会化技术系统影响软件开发人员做出更好的决策,那么这些系统可以作为AI增强软件开发的一个促成因素。
5.8.3.3 支持自然涌现的社交网络拓扑的分析工具
架构和软件分析工具必须实现自动化,以实现连续分析,但它们还必须能够支持新出现的网络拓扑。网络拓扑,数据源和影响映射的网络,会发生变化,因为一个人所连接的人会强烈影响他们所看到的内容。历史上,人们一直认为,建立系统是为了告知而不是影响人们。影响人们的拓扑映射在不断变化,有时话题激增或“病毒传播”,导致新的意外联系。这方面的具体挑战包括:
- 开发超大和自然涌现网络拓扑的自动化和连续分析
- 创建分析工具,使情景意识和人类对大规模趋势和预测的理解成为可能
5.8.3.4 开发社会化技术的知识创造理论
未来的软件开发人员必须考虑个人交互的多个维度,并理解这些个人交互如何对社会的一般知识造成风险。应对这一挑战需要了解知识是如何传播的,并确定提供“护栏”的机制,以限制多少信息被推测扭曲或影响。
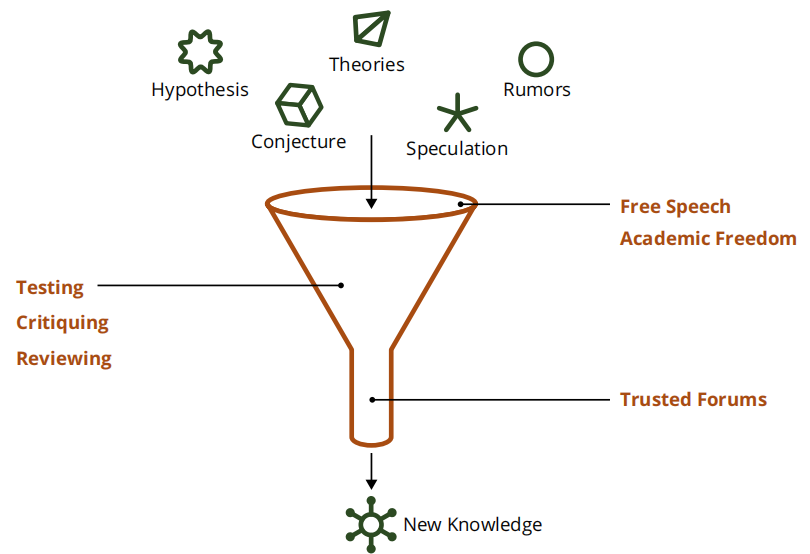
社会化技术系统中的沟通机制是信息流动的新途径,它们影响社会结构、规范和理解。以前,信息通过视频、音频或纸质媒体组织从少数来源流向大量受众,这些媒体通常包含有关来源的信息。虽然这些媒体组织有时会有偏见,但它们通常会认真进行核查或审查。今天,信息在社交网络中快速流动,不需要解释来源,很少审查信息,并且经常存在偏见。图3说明了一个概念性的“漏斗”,其中进入漏斗的数据在被视为事实或知识之前遵循多个步骤。不同的领域(如新闻、情报和学术领域)有不同版本的漏斗,但基于知识的专业都有测试和选择信息的方法,以确定哪些是有根据的,哪些是没有根据的。
目前的计算方法本身不足以做出通过漏斗传输数据所需的判断。具体关注领域包括:
- 通过识别知识漏斗机制保护社会认识论[Rauch 2018]
- 确定有效在线审核系统的基本特征,用于审查数据和评级数据源(例如,Karma on Reddit)
- 在社交媒体中大规模了解并减轻意外后果
- 识别并降低对知识创造产生负面影响的社会认识论影响者的风险
5.8.3.5 持续发展的社会化技术系统
自动检测和限定行为对于满足社会技术系统中数据的规模和数量至关重要。这需要考虑这些系统的架构演进、数据流和治理策略中的持续变化和不确定性。未来系统必须随着系统的变化而不断监测和调整。
需要强调的是,社会化规模系统的演变过程也需要了解和调整,以了解它们如何改变使用它们的人的行为。我们并不完全了解这些系统随着时间的推移会对人们产生什么样的影响,还有一系列的影响需要研究。这创造了一个有趣的反馈循环,在这个循环中,使用系统的人也在重塑系统。不断发展的社会技术系统包括以下问题:
- 当这些系统不断变化时,我们如何控制版本或修复错误?当系统和数据不一样时,这是一种新的软件开发方式吗?
- 我们如何理解导致创造知识的社会化技术保护机制的状态?

5.8.3.6 防止滥用社会化技术平台
社会化技术系统每天连接数十亿人,并对社会产生深远影响。检测社会规模的虚假信息或是否被操纵是困难的,因为信息可以采取多种形式,如文本、视频或音频[Twetman,2021]。响应在不同类型的数据中传播错误信息,规模大,速度快,需要重要的体系结构和数据机制。
其他感兴趣的话题包括:
- 操纵政治和舆论,引起国家安全担忧,尤其是外国势力操纵时
- 检测和处理意外后果
- 跟踪内容来源(即溯源)
5.8.3.7遵守政策
世界各国政府正在制定新的政策和规则来管理社会化技术系统。尽管社会化技术体系存在于全球范围内,但这些规则在国家、州甚至地方政府的边界上可能有所不同。当政策规则因地区而异时,需要新的机制来设计这些系统,并提供政府监管所需的测量和审计能力。软件工程研究必须为行业、政府和社会创建数据驱动和公开理解的技术,以便为社会规模的系统建立技术基础和适应性治理框架。此主题需要进一步研究,因为在治理解决多个考虑因素时,工程师面临许多权衡,包括以下因素:
• 当影响机制在软件中运行时,如何要求透明度
• 如何在保护个人隐私的同时监控政策遵守情况
• 如何防止公司、政府或其他行为者滥用过滤内容的能力
• 如何建立自动监控和报告,以确保遵守政策
5.8.3.8实验和测试
社会化技术系统的运作规模如此之大,人类互动如此之多样,以至于典型的实验和测试方法都是无效的。建模是一个选项,但这需要确认系统和模型是否一致。它还需要对个人和集体行为有更深的理解。另一种解决方案是作为运行系统的一部分进行实验和测试,例如许多科技公司进行的A-B测试。但是,作为一种总体策略,这种方法在限制实验方面存在技术挑战。它还具有潜在的与人体主体测试相关的法律和道德问题(在使用者不知情的情况下测试系统),增加了操纵风险。
需要更深入地了解测试对社会规模系统的真正意义,以及应该如何进行实验和测试。其他一些问题包括:
- 受系统影响的人是否应该在其设计中发挥作用(即参与式设计)?
- 我们如何创建实验环境来探索这些领域并测试新方法?(这个问题涉及到理解对实时用户测试什么是可以接受的阈值,以及为了让用户知道他们是测试的一部分,必须向用户透露什么。)
- 如果有这么多人依赖于社会化技术系统,那么是否应该有可靠性或安全期望来测试主枢纽何时发生故障,或确定系统如何安全地发生故障?
5.8.4研究问题
工程社会规模系统涉及许多挑战和问题,社会规模的问题需要利用来自社会和信息科学的软件工程以外的专业知识。以下问题强调了这一点:
- 我们如何测试解决方案,并充分考虑人们广泛变化的文化和行为背景?
- 我们如何监测社会认识论的影响,以及哪些社会审查过程能够有效防止故意或无意扭曲知识?
- 在系统中使用影响机制时,特别是在卫生或金融系统中,软件工程对透明度的期望是什么?
- 社会规模测量的重要方面是什么,以便能够持续评估系统是否符合不断变化的政府政策,以及测量何时可能侵犯隐私?
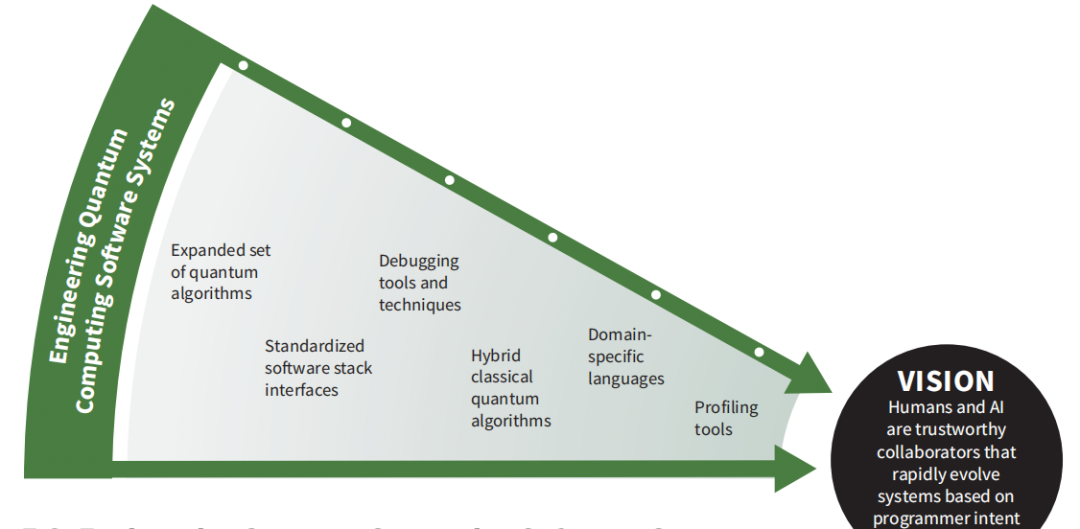
5.9 量子计算工程软件系统的重点研究领域
量子计算试图通过利用量子力学效应来改变计算方式。在20世纪80年代和90年代初,一种新型计算机的理论得到了发展:一种量子机械图灵机被描述并证明能够模拟经典图灵机所能做的一切。这些系统中的基本计算单位不是经典的二进制一位或零位,而是可以表示中间值和同时表示多个值的模拟值:一和零都是量子位或量子位。这种被称为叠加的表达能力,再加上多个量子比特被纠缠在一起以表达无法用级联、分离、单个量子比特系统表示的状态的能力,赋予了量子计算机强大的功能。事实上,具有n个量子比特的量子计算机可以编码2n-1个复数。激发理论的发展表明,对于某些特定的问题,量子计算机可能比经典计算机能力更强。这种计算机不受丘奇-图灵理论的限制,该理论认为所有经典计算机的性能只能比经典概率图灵机器快多项式。更好的是,很快就开发出了算法,表明量子计算机在解决特殊问题方面可以比经典计算机快得多。
这一开创性的理论推动了量子计算机设计和实现方面的额外工作。人们追求的是两类量子计算机:第一类包括初始化状态然后直接演化该状态的计算机,这样最终的系统状态就有很高的概率对计算的正确答案进行编码。这称为模拟量子计算,包括由D-Wave系统制造的量子计算机。第二类量子计算机将计算分解为一小组基本操作,然后依次执行这些操作,最终产生可能正确的结果。这些系统被称为基于门的系统,是我们在这里关注的系统,因为这些系统的离散性应允许使用错误校正,这将允许系统规模更大,从而解决更复杂的问题。
这些基于门的计算机的小规模实现正开始从不同的技术开发出来。开发这样的系统有很多挑战,需要将量子比特与环境隔离、纠缠和精确控制,因此目前还不知道哪些量子比特技术可以扩展到所需的大型系统。领先的竞争者包括俘获离子量子比特(由IonQ和Honeywell探索)和超导量子比特(IBM和Google探索),尽管学者和其他人正在探索光子量子比特和中性原子。高性能计算(如IBM)和云计算服务(如Google、Microsoft和Amazon)的主要提供商正在通过其平台访问当今的小型量子计算机。今天,这些系统的小尺寸和噪声量子比特限制了它们的应用;它们主要用于实验和科学有趣的演示,但在商业上并不重要。尽管如此,这类系统用于计算超越经典计算机的东西的前景仍然诱人。本节中的建议受到与从业者的对话以及最近几份优秀报告的影响【Martonosi 2018;NASEM 2019】。
5.9.1 目标
如果我们设想能够实现允许扩展的硬件进步,那么也需要软件和软件工程方面的进步。2018年国家量子信息科学战略概述【NSTC 2018】确定了ML、材料发现多体系统模拟、化学过程、量子场论和生物过程动力学等领域的重大挑战。在此列表中,我们添加了软件工程。
对于量子计算机,还有很多事情要做。我们所处的世界,量子计算机只有50-100个几乎无法工作的量子比特,约翰·普雷斯基尔称之为“噪音中等规模量子”(NISQ)技术【普雷斯基尔2018年】。我们拥有强大的软件工具,但每个量子比特都由程序员单独控制,自动化程度有限。我们的目标是首先使这些NISQ计算机易于编程,然后随着更大的、完全容错的量子计算系统的可用性而增加了抽象。

5.9.2当前实践的局限性
有如此多的软件工程片段缺失,以至于最容易将所需的进展视为软件工程堆栈中的层。我们将这些软件进步分为以下几类:量子算法、软件工程、开发工具和语言、计算平台和试验台。
5.9.3研究课题
5.9.3.1 量子和经典算法的进展
在本节中,我们将讨论尚未实现其全部潜力的基于通用门的量子计算机的特殊用途系统的软件工程。今天的系统很小而且不可靠,因此,由于缺乏可用性,本节中描述的依赖于大型系统的研究可能需要比其他部分更长的时间才能完成。尽管如此,即使时间框架可能不太准确,我们仍有足够的知识开始设想此类系统所需的软件工程挑战和研究。
理论计算机科学家关注算法的渐近行为。快速量子算法调整到量子计算机的独特方面:叠加和纠缠。这些算法的范围有限,风格与经典算法不同,需要大量的创造力和专业知识。
事实上,目前存在的所有量子算法中,理论上可能优于经典算法的所有算法在网上都被列为“量子算法展示集”。此类算法有四个主要领域:(1)代数和数论算法;(2) 口头或搜索算法;(3) 近似和仿真算法;优化、数值和机器学习算法。
不幸的是,今天的量子计算系统执行单个计算比经典计算机慢得多(在单位时间内)。它们具有较慢的时钟频率并产生概率结果,因此需要多次运行或检查发现的解决方案。考虑到当今实际硬件相对有限的性能,只有那些提供超级多项式加速的算法才可能实现真正的量子优势。只有少数实验证明了量子的优势,即解决问题的速度比经典计算机上解决的速度快。这仍然具有挑战性,因为量子和经典计算架构都将继续改进。
以下是该领域的研究主题:
- 扩展已知的量子算法集。
- 利用量子算法的新改进经典算法。
- 构建混合算法,利用最佳量子算法和经典算法协同工作。
- 开发可从高级语言调用的可证明正确的库。
- 制定基准,以便比较不同机器的性能。
5.9.3.2软件工程、开发工具和量子计算语言的进展
量子计算机工具尚处于初级阶段。有几个量子编程平台。Microsoft提供了一个量子开发工具包,允许使用面向对象的Q#语言进行编程[Svore 2018]。Amazon提供了一个开发工具包,支持使用BraKet语言编程[Amazon 2021]。IBM提供QISkit编程,这是一种多层语言,支持具有其他领域专业知识的程序员、量子电路开发人员和量子力学专家[Abraham 2019]。此外,还有几种学术(如Scaffold)和开源(如Quipper)语言和工具。函数式语言和命令式语言都得到了发展[Qiskit 2012;Gay 2006]。
这些语言中有许多是低级语言,大致类似于经典汇编语言。这一特点鼓励程序员思考量子计算机的独特方面,但使其很难从更高层次的算法角度进行思考。尚不清楚这是开发人员的最佳模型,也不清楚这些早期语言中的任何一种是否是最好的编程方式。此外,工具链有许多简单的组件,并且有诱人的暗示,更复杂的解决方案将产生显著的加速。例如,从语言到特定量子计算机的有效映射计算可以使算法的性能加倍。
以下是该领域的研究主题:
- 开发新的领域特定编程语言,允许程序员直接表达量子独特的并行性,同时防止不可能的操作,从而使量子程序员更高效。
- 开发量子编译器优化技术,将编程语言映射到多个目标体系结构,从而提高实现的运行时间和效率,并实现基准测试。
- 开发支持量子计算机持续集成的工具。
5.9.3.3硬件/软件计算平台的进展
在大多数情况下,用户通过云作为经典计算机的专用协处理器来访问当今的量子计算系统。大多数未来的算法将在经典计算机上执行一些操作(即加载数据和初始化系统),并在量子计算机上执行某些计算。决定在哪个组件上执行哪种计算仍然是一个挑战,测量系统的性能也是一个挑战。最后,不能用通常的方式在量子计算机上进行调试。

以下是该领域的研究主题:
- 开发分析量子算法和混合经典量子算法的新工具。
- 开发调试量子算法和混合经典量子算法的新工具。
- 优化接口:命令行、应用程序级和应用程序编程接口。
5.9.3.4 模拟器和试验台的进展
需要模拟器和试验台来推进该领域。模拟器已经存在,并且可以利用多核和高性能计算基础设施(例如,量子计算机的QuEST和高性能模拟)[Jones 2019]。基本上,可以使用模拟器来验证量子计算机的预期输出。在更高的抽象级别上,模拟器可以跟踪执行并揭示逻辑量子位的状态。这些模拟将有局限性,因为当前的模拟技术使用稀疏矩阵操作模拟逻辑操作,其中N比特计算机增长为2N。目前的超级计算机可以模拟大约50个量子比特的系统。
以下是可能的研究方向:
- 开发技术,以便进行更大的模拟:新的方法,或现有方法的新分解,实现多步骤和复杂算法的顺序模拟。
- 开发技术,自动比较模拟器和量子计算机的中间表示。
5.9.3.4 模拟器和试验台的进展
需要模拟器和试验台来推进该领域。模拟器已经存在,并且可以利用多核和高性能计算基础设施(例如,量子计算机的QuEST和高性能模拟)[Jones 2019]。基本上,可以使用模拟器来验证量子计算机的预期输出。在更高的抽象级别上,模拟器可以跟踪执行并揭示逻辑量子位的状态。这些模拟将有局限性,因为当前的模拟技术使用稀疏矩阵操作模拟逻辑操作,其中N比特计算机增长为2N。目前的超级计算机可以模拟大约50个量子比特的系统。
以下是可能的研究方向:
- 开发技术,以便进行更大的模拟:新的方法,或现有方法的新分解,实现多步骤和复杂算法的顺序模拟。
- 开发技术,自动比较模拟器和量子计算机的中间表示。

5.9.5 研究课题
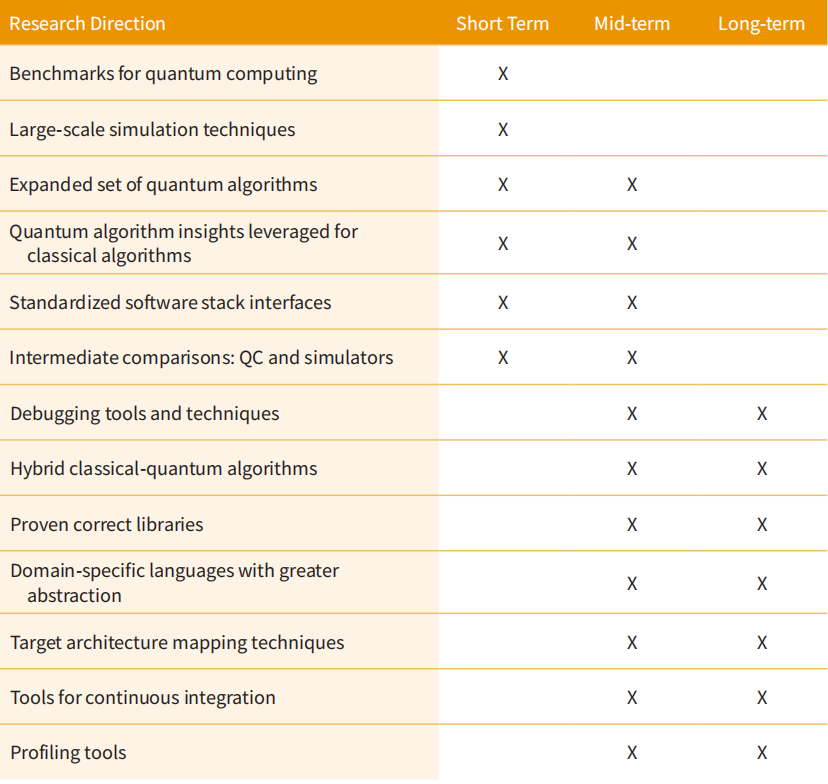
很难对上述任务进行排序,这些任务被组织为一个量子软件堆栈。然而,量子计算机有三个重要的时期:
- 科学时期:学习如何构建一个与外界完全隔离的量子系统,而该系统中的量子比特能够彼此强烈交互。需要解决的问题大多是物理领域的问题。软件挑战包括开发低级工具,类似于设备驱动程序,协调各个量子比特的控制信号。还有许多有趣的研究要做,但这不是本报告的重点。
- NISQ时期:一个其中有50到几百个量子比特的系统,这些系统大多与外界隔绝,能够根据需要相互作用。如今,已经建成了几台这样的量子计算机,达到了如此的规模和性能。有许多有趣的软件工程问题。
- 容错量子计算:这是一个数亿到数百万量子比特的阶段,与外部世界隔绝,并以精心控制的方式彼此强烈交互。
我们在下表中细分了里程碑,重点关注NISQ和容错量子计算的问题,并进行了类别选择:
- 短期。这些都是今后几年应该进行的努力。
- 中期。这些都是今后三至五年应继续进行的努力。
- 长期。这些都是今后六年或更长时间内应该进行的努力。
6 建议
本报告旨在呼吁采取行动,以应对当前和未来软件工程能力的不足。本节中的研究建议和颁布建议都有助于确定成功开发未来系统所需的行动。
第5节中的研究重点领域提出了研究建议,随后提出了一系列纲领性建议,这些建议侧重于将人员、投资和维护作为变革的工具,本节中的建议侧重执行。
6.1 研究建议
主要的调查结果推动了以下研究建议:
- 人工智能既是能力增强剂,也是工程不确定性的来源。
- 随着软件遍及一切,它越来越多地帮助我们想象新的使用方式。这导致了在有效保证软件可演化性的同时确保软件质量的工程挑战。
- 随着软件系统的规模和互联性不断增长,可进化性将越来越依赖于工程,需要从现有部分组成和重新组合系统。
- 过去,社会群体和社会在一定程度上受到物理距离的限制。现在,社交媒体可以实现大规模的互动,几乎没有限制。这导致需要为社会规模软件和社会化技术系创建新的工程原理。
- 随着软件继续触及了几乎所有事物,依赖软件的系统不可避免地变得越来越异构,包括数据、人员、组织、传感器、不同类型的计算设备和其他物理对象以及其他元素。由于存在许多不同和相互作用的领域,系统部件的这种异构性给工程带来了挑战。
以下研究建议适用于研究人员和从业人员。
建 议1-使人工智能成为可靠的系统能力增强器
软件工程和人工智能社区应该联合起来开发人工智能工程学科(也许从人工智能促进协会(AAAI)和IEEE计算机学会开始)。这将有助于开发和发展行为符合预期的AI软件系统。此外,这将使人工智能通过帮助常规软件工程活动,如根据程序员意图生成代码,帮助重构,并确保系统实现与其体系结构之间的一致性,而且被用作软件工程生产力的杠杆。
建议2——大规模开发软件进化和再保证的理论和实践
软件工程研究社区应该开发一种理论和相关实践,以重新确保不断发展的软件系统。这项研究的重点是保证论据,它应该是一个与系统架构同等重要的软件工程工件。研究应包括制定保证论据的表述和构建保证论据方法,以便小的系统变更只需要增量再保证。
建议3——为组合技术开发形式化的语义
计算机科学界应该关注最新一代的组合技术,以确保依赖注入框架等技术通过指定系统行为的各个抽象级别来保留语义。这将允许我们通过组合获得开发的好处,同时实现可预测运行时的行为。
建议4——成熟社会规模社会技术系统的工程
软件工程社区应与社会科学社区合作,为社会技术系统制定工程原则。应使用社会学和心理学等学科的理论和技术来发现社会技术系统的新设计原则,这反过来会导致社会规模系统(如社交媒体)的行为更加可预测。
建议5——促进对新计算模型工程的更多关注,重点关注量子软件系统。
软件工程社区应该与量子计算社区合作,为量子计算系统预测新的架构范例。重点应该是理解量子计算模型如何影响软件堆栈的所有层。可以预见,利用量子计算将需要确定量子模型的细节应该隐藏在哪里,而不是软件系统的其他元素所知道的地方。
6.2 法规建议
虽然研究建议侧重于实现变革的科学和工程障碍,但法规建议侧重于体制障碍,如经济、人力和政策上的障碍。
- 动力更换需要投资,制度上的挑战是引起投资者关注。
- 无论自动化程度如何,系统都是由人构建的。制度上的挑战是重新定义软件工程人员。
- 自我维持的变革需要政策和做法制度化。
以下法规建议适用于研究资助者、政策制定者和行业领导者。
建议6——投资优先级应反映软件工程作为关键国家能力的益处
软件工程界、软件行业领袖、国家实验室和政府部门应将软件工程视为国家的优先事项。需要在政策上给予更高的认识,以使政府和行业能够持续投资于软件工程研究,从而有利于国家竞争力和安全。
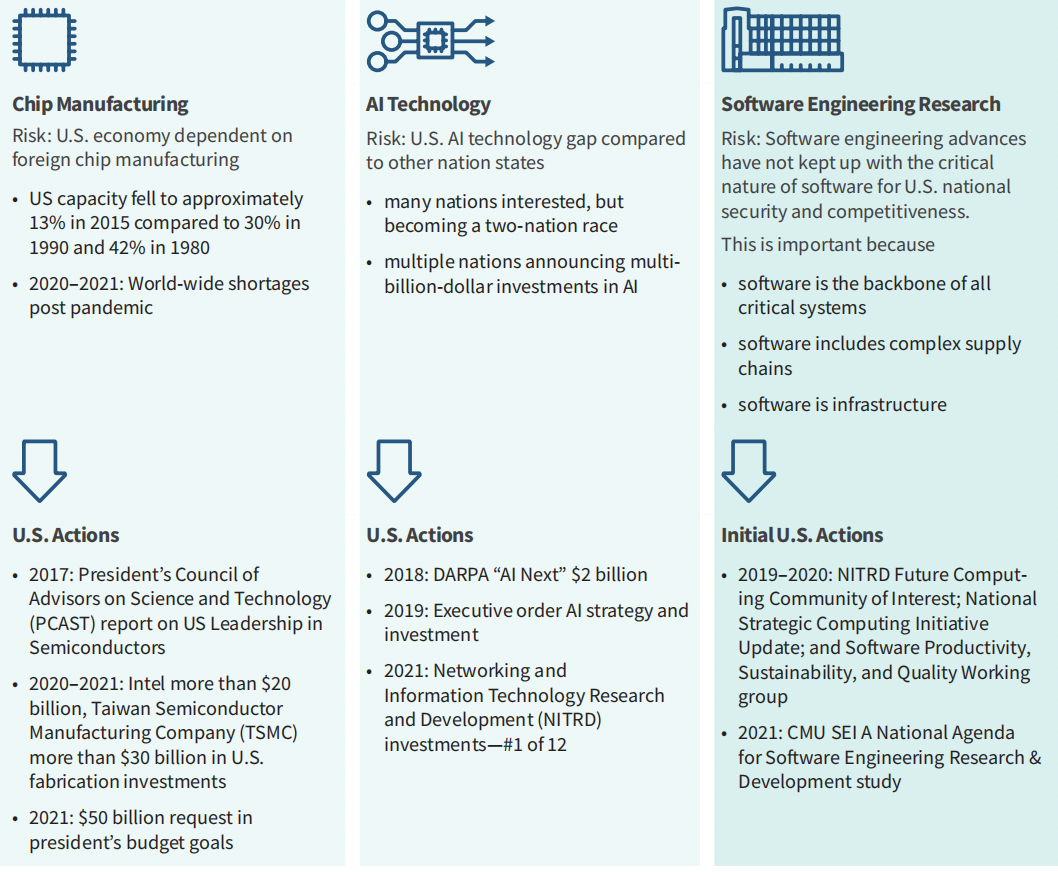
软件工程在国家安全和全球市场竞争力中的战略作用应反映在国家研究活动中,包括白宫科学技术政策办公室(OSTP)和网络与信息技术研究及开发办公室(NITRD)开展的研究活动。这些研究活动应将软件工程研究视为与芯片制造和人工智能同等重要的投资重点。例如,美国经济依赖外国芯片制造业的风险最近促使美国采取多项行动,包括约500亿美元的行业投资和拟议的500亿美元政府投资。人工智能技术投资遵循了类似的路径,可能的美国技术差距促使政府从DAPRA和NITRD投资,以及主要的行业投资。在这两个例子中,提高对国家安全和美国经济风险的认识推动了包括工业和政府投资在内的行动。投资软件工程研究同样重要(见下页的表格)。
如果没有对软件工程技术的持续投资和改进,下一代应用程序将根本不可能实现。软件以及软件工程,是大多数新技术快速创新的共同推动者。如本报告研究重点领域所述,未来的软件工程技术挑战需要新的解决方案。
正如2018年国防战略所述,“安全环境也受到快速技术进步和不断变化的战争特征的影响。开发新技术的动力是坚持不懈的,以更低的进入门槛扩展到更多的参与者,并以更快的速度前进。技术快速发展的环境突显出技术领导力丧失的速度有多快,而软件进入门槛的降低意味着不同国家,甚至非国家行为者,可以迅速利用技术。
还建议由DARPA、国家科学基金会(NSF)和FFRDC来赞助软件工程的这些重大挑战。重大挑战已成为快速调动现有关键问题能力的有效方式,同时在学术界和工业界建立新的伙伴关系。
建议7——使软件工程研究的持续发展制度化
软件工程界、软件行业领袖、国家实验室和政府部门应将软件工程视为国家的优先事项。需要在政策上给予更高的认识,以使政府和行业能够持续投资于软件工程研究,从而有利于国家竞争力和安全。
软件工程的持续发展要求将软件工程研究的持续审查和再投资周期制度化,以及它对软件工程实践对我们软件工程生态系统结构的影响。保持国家软件工程水平需要研究资金来源以及与软件工程界的行业和政府领导人合作的机构定期审查软件工程的状态。国防部的国防战略(前身为四年防务评估)可以作为一个范例。确保进行此类审查的责任应属于具有影响力的高层组织,如OSTP或总统科学技术顾问委员会(PCAST)。
建议8——保证战略的确定
面向软件工程未来的劳动力是怎样的?目前,软件工程是由一大批具有跨学科技能的人员执行的,这些人员并不总是接受了软件工程的正式培训。此外,软件工程的性质似乎随着软件系统的流动性而发生变化。由于这些趋势,传统的专业领域,如架构、设计、实现和测试,可能会让位于其他专业领域。
我们需要更好地了解所需劳动力的性质以及如何促进其增长。软件工程界、软件行业和学术界应制定一项战略,以确保未来软件工程劳动力的有效性。
这些问题和该研究路线图的其他后果需要研究,以得出一组详细的劳动力建议。
7 结论
架构软件工程的未来:国家软件工程研究与开发议程是为期一年的社区活动结果,旨在重新验证软件工程的重要性和中心地位;确定该学科当前和未来的挑战;并制定研究议程,以促进软件工程生态系统为未来做好准备。
我们总结了一路走来获得(或重新获得)的一些见解,以此结束本文件。
软件涉及生活的各个方面和基础设施的各个方面,是许多学科研究的关键;总的来说,这对国家安全的各个方面都很重要。因此,软件是社会越来越多方面与层次的重要推动者。环顾周围,很难看不到里面没有软件的东西。软件的重要性和普遍性自然意味着我们必须仔细关注如何构建和发展软件。也就是说,我们必须认真关注软件工程。否则,我们就有可能让软件工程不仅成为新功能的促成者,而且成为漏洞的来源。
软件工程最初是根据其他古老工程学科的精神构思的,但由于其独特的性质,它似乎正在寻找自己的根基。也许,与土木工程等其他工程学科不同,软件工程不会发展成为一门“成熟”的学科。在软件工程的实践成为常规之后,它很快就会自动化,软件工程将前进以应对新的挑战。然后,由于软件的概念性质,软件工程的实践将在能力、复杂性、与其他领域的紧密性和互联性方面不断增长和变化。软件的发展似乎没有停滞期,因此,软件工程的挑战也没有尽头。
软件的不断进步是自动化的自然驱动力,自动化导致帮助人类创建和发展软件的责任和权限不断增加。人工智能在帮助软件工具超越程序员扩展的角色方面发挥着重要作用。它还为工程师创造了一个新角色,使其成为同行,并最终成为AI的合作者。这个扩展的角色将使软件工程成为可能,部分原因是允许软件工程师和最终用户通过让软件知道他们期望它做什么来“编程”软件。以这种方式通过意图进行编程将成为一个重要的专业。
对软件的日益依赖促使人们需要不断、快速地改变它。事实上,过去的“需求”已经变成了防御系统的“需要”。变化的威胁促使人们需要通过更好的传感器实现灵活的响应和增强的能力。人工智能分析推动了快速部署的需求。这些新能力反过来又推动了新的任务概念。快速的变化需要快速的再保证,这使得构建证据和保证论据的方式越来越重要,以允许以增量和组合的方式进行再保证。
未来的研究必须考虑到软件生态系统,并且必须代表关键的软件工程挑战。软件工程可以从两个正交的维度来考察:“做软件”和“软件做什么”。我们重点讨论了三个似乎是上述软件工程不断变化的本质的核心:提高自动化的驱动力;重新保证的必要性;以及组合的重要性质。“软件做什么”让我们思考了三种可能导致高级架构范例的挑战:人类是系统的一部分;系统中的AI组件;量子处理器是新计算模型的典范。
我们以这种方式看待软件工程的目标是具有代表性和包容性,而不必详尽无遗。我们希望这个框架邀请其他人考虑其他高级开发范例,这些范例是软件工程性质变化的关键,以及其他类型的挑战,这些挑战可能会导致其他高级架构范例,从而扩展这一已经开始的路线图。
持续性自我评估需要制度化。如前所述,软件工程的进步似乎没有尽头。这意味着软件工程需要持续的反思和激励来支持进步。反过来,这需要一名高级倡导者,以及资金和定期审查,以继续开展这项研究。
软件有时被比作空气:它是无形的,无处不在,每个人和每件事都需要它。这种感觉可以导致两种不同的方式来考虑软件,因此也就是软件工程:(1)让它保持无形,并将其视为理所当然;或(2)培养,关心,保护并改进它。我们希望这份报告能够让您相信,考虑软件工程的真正可行的方法只有一种。
【关联阅读】
- 软件开发中的10个认知偏差
- 软件依赖的一知半解
- Crash?! ——软件崩溃后的数据一致性
- 软件系统的多维性能模型
- 关于软件研发生产力的误区与思考
- 远程软件工程师的10个最佳实践
- 软件架构的10个常见模式
- 关于软件开发,都应该知道的10个常识
- 嵌入式开源软件的十大弊端
版权归原作者 半吊子全栈工匠 所有, 如有侵权,请联系我们删除。