
Index of /dist/hadoop/commonhttps://archive.apache.org/dist/hadoop/common
集群规划:
注意:
- NameNode和SecondaryNameNode不要安装在同一台服务器
- ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
机器ip分配节点hadoop001192.168.56.201NameNode、DataNode、NodeManagerhadoop002192.168.56.202ResourceManager、DataNode、NodeManagerhadoop003192.168.56.203SecondaryNameNode、DataNode、NodeManager1、解压到linux,配置环境变量在/etc/profile.d/hadoop_env.sh
#!/bin/bash
export JAVA_HOME=/data/soft/jdk1.8.0_201
export HADOOP_HOME=/data/soft/hadoop-3.3.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2、cd /data/soft/hadoop-3.3.4/etc/hadoop
[root@hadoop001 soft]# cd hadoop-3.3.4
[root@hadoop001 hadoop-3.3.4]# ll
total 100
drwxr-xr-x 2 1024 1024 4096 Jul 29 09:44 bin
drwxr-xr-x 3 1024 1024 20 Jul 29 08:35 etc
drwxr-xr-x 2 1024 1024 106 Jul 29 09:44 include
drwxr-xr-x 3 1024 1024 20 Jul 29 09:44 lib
drwxr-xr-x 4 1024 1024 4096 Jul 29 09:44 libexec
-rw-rw-r-- 1 1024 1024 24707 Jul 28 16:30 LICENSE-binary
drwxr-xr-x 2 1024 1024 4096 Jul 29 09:44 licenses-binary
-rw-rw-r-- 1 1024 1024 15217 Jul 16 14:20 LICENSE.txt
-rw-rw-r-- 1 1024 1024 29473 Jul 16 14:20 NOTICE-binary
-rw-rw-r-- 1 1024 1024 1541 Apr 22 2022 NOTICE.txt
-rw-rw-r-- 1 1024 1024 175 Apr 22 2022 README.txt
drwxr-xr-x 3 1024 1024 4096 Jul 29 08:35 sbin
drwxr-xr-x 4 1024 1024 31 Jul 29 10:21 share
3、修改其中的一些文件
(1)hadoop-env.sh,修改JAVA_HOME为具体的路径
export JAVA_HOME=/data/soft/jdk1.8.0_201

(2)core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/soft/hadoop-3.3.4/datas</value>
</property>
<!-- 在Web UI访问HDFS使用的用户名。-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
(3)hdfs-site.xml
<!-- NN web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop001:9870</value>
</property>
<!-- 设定SNN运行主机和端口。-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop003:9868</value>
</property>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--如果为"true",则在HDFS中启用权限检查;如果为"false",则关闭权限检查;默认值为"true"。-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
(4)mapred-site.xml
<!-- 指定mapreduce运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
(5)yarn-site.xml
<!-- Site specific YARN configuration properties -->
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop002</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<!--开启日志聚合-->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<!--日志聚合hdfs存储路径-->
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/soft/hadoop-3.3.4/nodemanager-remote-app-logs</value>
</property>
<property>
<!--hdfs上的日志保留时间-->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<!--应用执行时存储路径-->
<name>yarn.nodemanager.log-dirs</name>
<value>file:///data/soft/hadoop-3.3.4/nodemanager-logs</value>
</property>
<property>
<!--应用执行完日志保留的时间,默认0,即执行完立刻删除-->
<name>yarn.nodemanager.delete.debug-delay-sec</name>
<value>604800</value>
</property>
(6)配置workers
hadoop001
hadoop002
hadoop003
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
4 、启动集群
(1)如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
hdfs namenode -format
(2)启动HDFS
start-dfs.sh
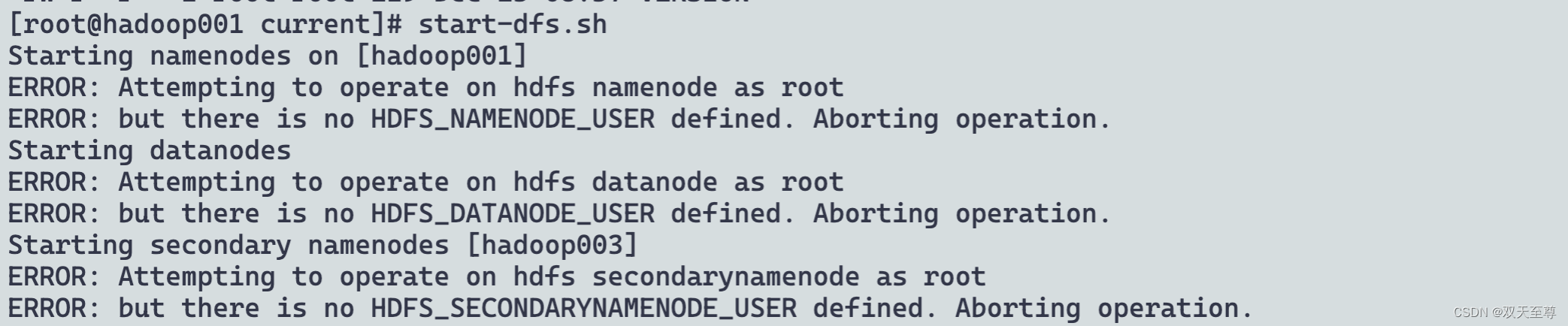
处理:
vim /data/soft/hadoop-3.3.4/sbin/start-dfs.sh,stop-dfs.sh
添加以下几行:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
(3)在配置了ResourceManager的节点(hadoop002)启动YARN
start-yarn.sh

处理:
vim /data/soft/hadoop-3.3.4/sbin/start-dfs.sh,stop-dfs.sh
添加以下几行:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
Hadoop集群启动关闭-手动逐个进程启停
每台机器上每次手动启动关闭一个角色进程
HDFS集群
hdfs --daemon start namenode|datanode|secondarynamenode
hdfs --daemon stop namenode|datanode|secondarynamenode
YARN集群
yarn --daemon start resourcemanager|nodemanager
yarn --daemon stop resourcemanager|nodemanager
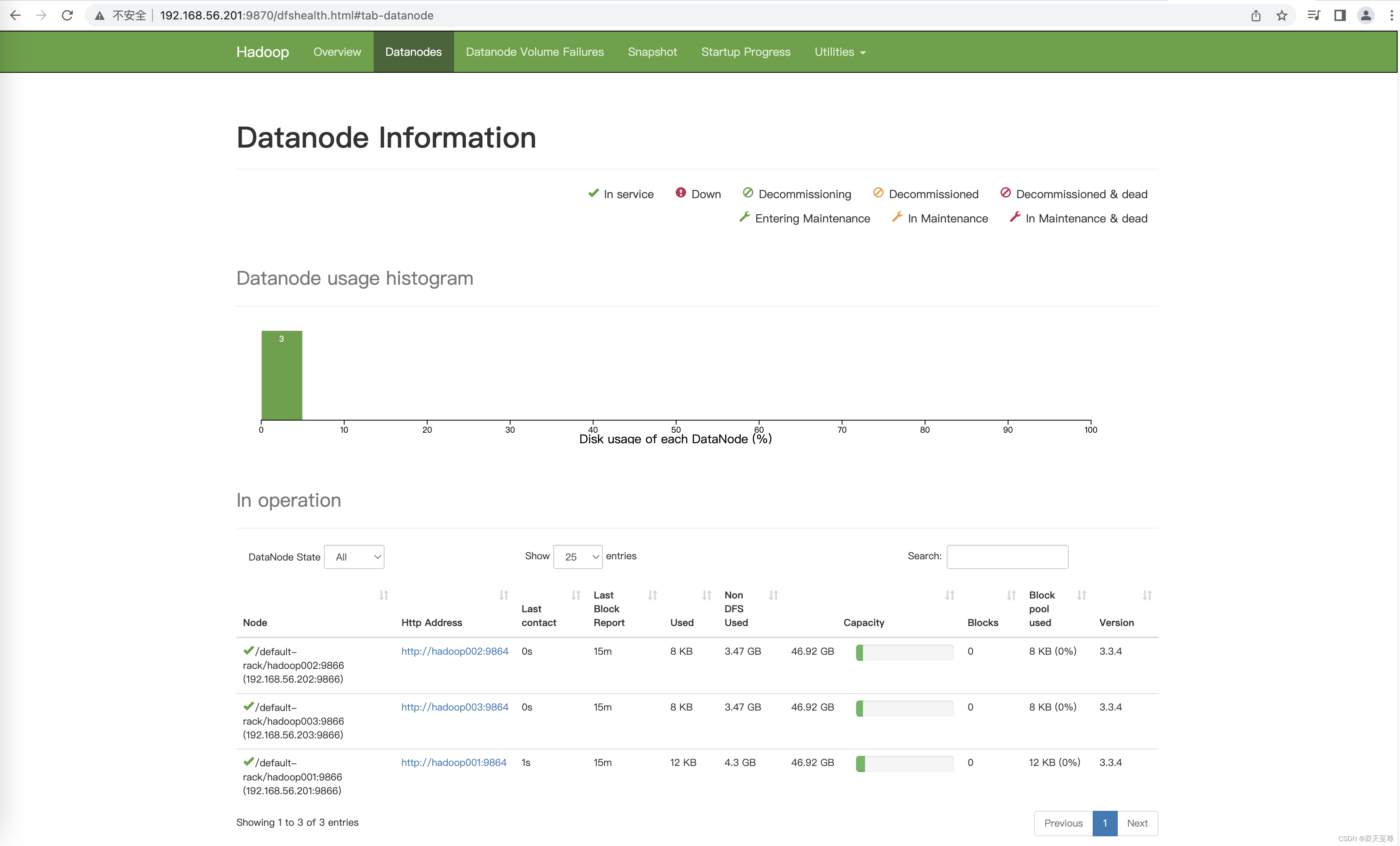
启动界面


修改hdfs的web端口和yarn的web端口的配置
hdfs-site.xml配置http:
<property>
<name>dfs.http.address</name>
<value>hadoop001:9870</value>
</property>
yarn-site.yml配置如下:
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop002:8088</value>
</property>
配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
(1)配置mapred-site.xml
增加如下配置:
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop001:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop001:19888</value>
</property>
分发配置文件到所有的主机!!!
mapred --daemon start historyserver

hadoop jar /data/soft/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount /words.txt /out


配置日志的聚集
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
开启日志聚集功能具体步骤如下:
(1)****配置yarn-site.xml
<property>
<!--开启日志聚合-->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop001:19888/jobhistory/logs</value>
</property>
<property>
<!--日志聚合hdfs存储路径-->
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/soft/hadoop-3.3.4/nodemanager-remote-app-logs</value>
</property>
<property>
<!--hdfs上的日志保留时间-->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<!--应用执行时存储路径-->
<name>yarn.nodemanager.log-dirs</name>
<value>file:///data/soft/hadoop-3.3.4/nodemanager-logs</value>
</property>
<property>
<!--应用执行完日志保留的时间,默认0,即执行完立刻删除-->
<name>yarn.nodemanager.delete.debug-delay-sec</name>
<value>604800</value>
</property>
分发配置文件到所有的主机!!!
先关闭NodeManager 、ResourceManager和History****Server
然后重启NodeManager 、ResourceManage和History****Server
版权归原作者 AI机械师 所有, 如有侵权,请联系我们删除。