
1.索引的本质
索引的本质就相当于"书的目录",通过目录就能快速定位到我们需要的某个章节的位置
索引的主要作用就是为了加快查找的速度
在数据库操作中,查询的频率是非常高的,使用索引可以帮助我们快速查找到所需要的信息
缺点
1.数据库索引提高查询速度的同时也增加了增加删除修改操作的开销,进行增删改操作之后,调整数据之后还要修改索引,因此增加了其他开销,但是这是次要矛盾,主要矛盾是查询的速度,相比之下还是很值得的
2.不仅如此,索引还提高了空间的开销,构造索引需要额外的硬盘空间来保存
虽然有这些缺点,但是他能解决我们的主要矛盾,在软件开发中会经常遇到这样的问题.一般的都没有那个方法能解决所有问题,需要进行取舍,解决主要矛盾
2.索引的使用
2.1查看索引
mysql> show index from student3;
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student3 | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
如果表里有主键,主键这列就会自动创建索引
还有unique,foreign key 的列也会自动创建索引
2.2创建索引
mysql> create index index_name on student3(name);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from student3;
+----------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student3 | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
| student3 | 1 | index_name | 1 | name | A | 0 | NULL | NULL | YES | BTREE | | |
+----------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
此时就有两个索引,针对name新加了一个索引
在创建索引的时候,最好是在表创建的时候就把索引创建好,否则,如果这个表的记录十分多了,再创建索引,就很危险了!!是因为此时创建索引会花很长的时间,占用了大量的的磁盘IO,此时是无法对数据库进行访问的的,也无法正常使用,那带来的损失就太大了
2.3删除索引
mysql> drop index index_name on student3;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from student3;
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student3 | 0 | PRIMARY | 1 | id | A | 0 | NULL | NULL | | BTREE | | |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
1 row in set (0.00 sec)
此时只剩一个索引了,和刚刚创建索引相似的是,删除索引也会有较大的开销,所以在创建表的时候我们就要规划好索引,一旦表里有大量的数据了,再进行操作就需要慎重考虑了!!
那么创建好了索引,是怎么使用索引的呢?
创建好索引之后,是不需要手动的调用的,SQL是通过数据库的执行引擎来执行的,涉及到一些优化操作,执行引擎会自动评估哪种方案成本最低速度最快,可以使用explain关键字显示出查询过程中索引的具体使用情况,结果分析还是比较复杂的
3.索引的数据结构
MySQL中索引的数据结构是什么呢?
索引既然能极大提高搜索的效率,我们肯定能先想到的数据结构就是哈希表,哈希表的查询时间复杂度是O(1),但是哈希表不适合做数据库的索引,原因在于哈希表只能比较相等,无法进行范围查询,像<>这样的操作都不行
3.1B树
其次,二叉搜索树查询元素的时间复杂度是O(N),相比于哈希表,二叉搜索树好像可以进行范围查询了,但是还存在一个问题,当元素数太多时,树的高度就会比较高,而数的高度又决定了树查询的时候比较的次数,数据库比较的时候需要读取硬盘,因此更希望书的高度能降低一点,那么就考虑使用N叉搜索树了
N叉搜索树,每个节点有很多个值,同时有很多的分叉,降低了树的高度,减少了比较的次数
一种典型的实现N叉搜索树的方式就是B树
我们看一下B树的结构

这种结构降低了树的高度,没有减少比较次数(但是在一个节点上比较多次了),减少了对硬盘的读写次数,节点都是保存在硬盘上的,能一定程度的解决问题,适合做索引
3.2B+树
还有种更适合做索引的数据结构,就是B+树
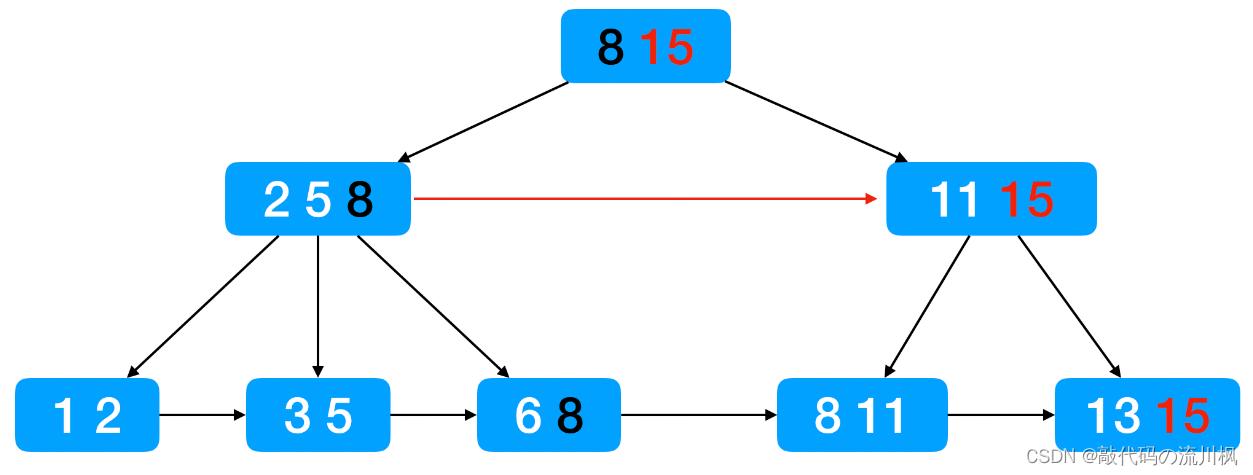
B+树的特点:
1.B+树也是一个N叉树,增加了新的特点,每个节点上包含N个Key,N个Key划分出N个区间,每个区间的最后一个key就是最大值
2.父元素的Key会在子元素中出现并且为最大值,重复出现导致了,叶子节点就包含了所有数据的全集!
那么非叶子结点的所有元素都在叶子节点中体现
3.叶子节点用类似于链表的形式相连起来,构成了B+树
B+树这个数据结构做索引好处太明显了
1.既有B树高度比较低的特点,又更适合范围查询,比如查找>6且<15的元素,结果集非常容易取得,效率很高
2.对于所有的查询,都要落在叶子节点上,中间的比较次数是差不多的,查询操作比较均衡
对B树来说,在根节点或者深度不深的元素查询快,别的地方查询慢,不均衡,B+树都是一样的,都落在叶子节点上了
3.由于所有的Key都会在叶子节点中出现,因此非叶子节点不用存表的真实记录,只要把说有的数据行放在叶子节点上即可,非叶子节点只用存索引列的值,比如id这些,非叶子节点占用的空间就很小了,有可能在内存中放进去缓存了,更进一步降低了硬盘IO,提高了查询的速度
综上,B+树是非常适合作为索引的数据结构的
有的表不只是有主键索引,还有别的非主键列也有索引,此时会构造另一个B+树,非叶子节点里面存储这一列的Key,到了叶子节点这一层不再存储完整的数据行了,而是存储主键索引的id,那么使用主键索引查询时只用查一次B+树就好了,使用非主键列索引要先查一遍另外构造的B+树,然后查一次主键列的B+树(这个操作称为回表操作)
当前B+树这个结构适用于MySQL的InnoDB这个数据引擎,不同的数据库,不同的引擎存储数据的数据结构还是有差异的
4.事务
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
4.1 事物的回滚(rollback)
当一个事务在执行时,执行中间出错了,就让它恢复成原来的样子
涉及到的操作就是回滚,具体实现是把执行过的操作逆向恢复回去
数据库会把执行的每个操作都记录下来,如果某个操作出错了,就会把事务中之前的操作进行回滚,根据之前的操作,进行逆操作(前面插入回滚就是删除之前插入的)
有了这个操作,那么删表删库是不是就不危险了呢?反正可以回滚么,事实当然不是这样的,回滚的操作是有很大开销的,可以保执行的操作,但也不能无限保存,最多就是保存正在执行的事务,当数据量特别大时,更不可能保存每个数据如何得到,因此删表删库仍然是很危险的操作!!
4.2事务的四大特性(ACID)
事务的四大特性主要是:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
4.2.1 原子性
原子性是指事务是一个不可分割的工作单位,事务中的操作要么全部成功,要么全部失败。比如在同一个事务中的SQL语句,要么全部执行成功,要么全部执行失败
4.2.2 一致性
事务必须使数据库从一个一致性状态变换到另外一个一致性状态,事物的执行前后数据是合法的
比如银行转账时,A给B转了100,A转出100,B却没有收到100,这时就出现了数据不合法,没有达到一致性
4.2.3 持久性
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响,保证事务对数据库的改变是生效的
4.2.4 隔离性
一个数据库服务器同时执行多个事务的时候,事物之间的相互影响的程度
隔离性越高,事务之间并发程度越低,执行效率慢,但是数据准确性高,像银行转账.....
隔离性越低,事务之间并发程度越高,执行效率快,但是数据准确性低,像点赞数.....
5.并发引起的问题
5.1 "读脏数据"
当一个事务修改某个数据后,另一事务对该数据进行了读取,由于某种原因前一事务撤销了对数据的修改(即将修改过的数据恢复原值),那么后一事务读到的数据与数据库中的数据不一致,这称之为读脏数据
为了解决这个问题,要降低并发性,提高隔离性,具体操作就是给''写操作''加锁,写的时候不能被读取,降低了一定的效率,但是提高了数据的准确性
5.2 "不可重复读"
当一个事务读取某个数据后,另一事务执行了对该数据的更新,当前事务再次读取该数据(希望与第一次读取的是相同的值)时,得到的数据与前一次的不一样,这是由于第一次读取数据后,事务B对其做了修改,导致再次读取数据时与第一次读取的数据不相同
这次给''读操作''加锁,读的时候数据不能被修改,并发程度进一步降低,隔离性进一步增加,运行速度变慢,数据准确性进一步提高了
5.3 "幻读"
事务A 按照一定条件进行数据读取, 期间事务B 插入了相同搜索条件的新数据,事务A再次按照原先条件进行读取时,发现了事务B
新插入的数据 称为幻读
为了解决这个问题,需要彻底舍弃并发,进行串行化操作,在读的时候不进行其他的操作
6.MySQL的隔离级别
MySQl为了控制并发程度的高低,引入了四个隔离级别,通过修改配置文件就可以改变隔离级别
6.1 read uncommitted
不做任何处理,事务间随意并发,当然上面的三个问题都存在,隔离性最低,并发程度最高
6.2 read committed
对写操作加锁,解决了读脏数据问题,还存在另外两个问题
6.3 repeatable read
对读写操作加锁,解决了读脏数据问题,不可重复读问题
还存在幻读问题
6.4 serializable
严格串行化,解决了三个由并发引起的问题,并发程度最低,隔离性是最高的
看这张图比较直观

版权归原作者 敲代码の流川枫 所有, 如有侵权,请联系我们删除。