
=============HBase==================
package functions import java.util import com.alibaba.fastjson.{JSON, JSONObject} import entity.TableProcess import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction} import org.apache.hadoop.hbase.{HColumnDescriptor, HTableDescriptor, TableName} import org.apache.hadoop.hbase.client.{Admin, Connection, Put, Scan, Table} import utils.{HbaseUtil, MyMysqlUtils} class MyHbaseSink extends RichSinkFunction[JSONObject] { //初始化连接 var con: Connection = _ var table: Table = _ var admin:Admin=_ var sink_table:String=_ //用于在内存中存放配置表信息的Map <表名:操作,tableProcess> var map: util.HashMap[String, TableProcess] = new util.HashMap[String, TableProcess]() //定义一个空put var put:Put=null //初始化 override def open(parameters: Configuration): Unit = { con=HbaseUtil.getCon admin=con.getAdmin //先调用 refreshMetas() } override def invoke(value: JSONObject, context: SinkFunction.Context): Unit = { //获取表明 val tb = value.getString("table") //获取表类型 val ty = value.getString("type") //获取数据 val data = value.getJSONObject("data") //赋值给sink_table sink_table = value.getString("sink_table") //获取所有的key val mysqlKeys = map.keySet() //迭代器 val mysqlItertor = mysqlKeys.iterator() //获取每一个 while (mysqlItertor.hasNext){ val key = mysqlItertor.next() //将传进来的table名字跟map里存入的key做对比 if (tb.equals(key)){ //调用方法 传入表明跟列族 create(sink_table,Array("info")) //添加数据将列族跟数据传入 insert("info",data) } } } def create (tableName:String,columnFamilys:Array[String]): Unit ={ //操作的表名 val tName = TableName.valueOf(tableName) //当表不存在的时候创建Hbase表 if (!admin.tableExists(tName)) { //创建Hbase表模式 val descriptor = new HTableDescriptor(tName) //创建列簇i for (columnFamily <- columnFamilys) { descriptor.addFamily(new HColumnDescriptor(columnFamily)) } //创建表 admin.createTable(descriptor) } } def insert (columnFamily:String,json:JSONObject): Unit ={ //获取hbase的表明 table=con.getTable(TableName.valueOf(sink_table)) //获取所有的key val keys = json.keySet() val iter = keys.iterator() while (iter.hasNext){ //获取json中的id 因为有的json数据第一个不是id所以要先从json中获取id val id = json.getString("id") //判断id不为空 if (id!=null){ val key = iter.next() if (!key.equals("id")){ val value = json.get(key).toString //添加rowkey put =new Put(id.getBytes()) //添加每一列数据 put.addColumn(columnFamily.getBytes(),key.getBytes(),value.getBytes()) //添加数据 table.put(put) } } } } def refreshMetas (): Unit = { //数据库里的规则表 var sql = "select distinct source_table from table_process where sink_type='hbase'" val tableprocress = new MyMysqlUtils[TableProcess] val process: util.List[TableProcess] = tableprocress.queryList(sql, classOf[TableProcess], true) for (i <- 0 until process.size()) { val p: TableProcess = process.get(i) val sourceTable = p.sourceTable // map.forEach((x,y)=>println("key"+x+"value"+y.sinkTable+y.operateType)) map.put(sourceTable, p) if (map == null || map.size() == 0) { throw new RuntimeException("没有从数据库的配置表中读取到数据"); } } } }
=======MyMysqlUtils========
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet, ResultSetMetaData} import java.util import org.apache.commons.beanutils.BeanUtils import com.google.common.base.CaseFormat import entity.TableProcess class MyMysqlUtils[T] { def queryList(sql: String, clzL: Class[T], underScoreToCamel: Boolean): util.List[T] = { var con: Connection = null var ps: PreparedStatement = null var re: ResultSet = null //注册驱动 Class.forName("com.mysql.jdbc.Driver") //创建连接 con = DriverManager.getConnection("jdbc:mysql://hadoop101:3306/gmall?", "root", "root") //创建数据库操作对象 ps = con.prepareStatement(sql) re = ps.executeQuery() //处理结果集 //查询结果的元数据信息 // id student_name age val metaData: ResultSetMetaData = re.getMetaData val count: Int = metaData.getColumnCount println(count) val resultList = new util.ArrayList[T]() //判断结果集中是否存在数据,如果有,那么进行一次循环 while (re.next()) { //创建一个对象,用于封装查询出来一条结果集中的数据 // val t = classOf[TableProcess] 传入的类中需要无参方法 val t = clzL.newInstance() //对查询的所有列进行遍历,获取每一列的名称 for (i <- 1 to metaData.getColumnCount) { val columnName = metaData.getColumnName(i) //获取每一列的名称 var propertyName = columnName if (underScoreToCamel) { //如果指定将下划线转换为驼峰命名法的值为 true,通过guava工具类,将表中的列转换为类属性的驼峰命名法的形式 propertyName = CaseFormat.LOWER_UNDERSCORE.to(CaseFormat.LOWER_CAMEL, columnName) } //调用apache的commons-bean中工具类,给obj属性赋值 BeanUtils.setProperty(t, propertyName, re.getObject(i)) } //将当前结果中的一行数据封装的obj对象放到list集合中 resultList.add(t) } resultList } }
======TableProcess =======
//规则类 class TableProcess extends Serializable { //来源表 @BeanProperty var sourceTable: String = _ //操作类型 insert,update,delete @BeanProperty var operateType: String = _ //输出类型 hbase kafka @BeanProperty var sinkType: String = _ //输出表(主题) @BeanProperty var sinkTable: String = _ //输出字段 @BeanProperty var sinkColumns: String = _ //主键字段 @BeanProperty var sinkPk: String = _ //建表扩展 @BeanProperty var sinkExtend: String = _ //无参方法 def f1 = { } }
=========规则表格式========
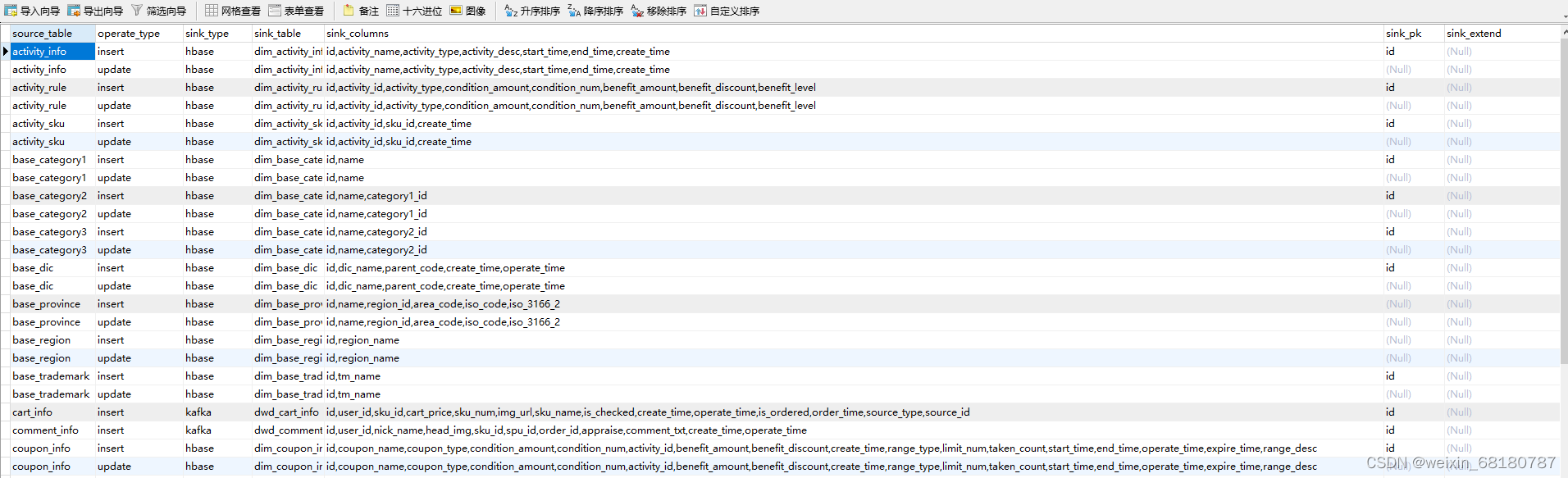
本文转载自: https://blog.csdn.net/weixin_68180787/article/details/126410565
版权归原作者 LHQ- 所有, 如有侵权,请联系我们删除。
版权归原作者 LHQ- 所有, 如有侵权,请联系我们删除。