
您好,我是码农飞哥(wei158556),感谢您阅读本文,欢迎一键三连哦。
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 2.网上优质的Python题库很少,这里给大家推荐一款非常棒的Python题库👉点击跳转刷题网站进行注册学习
❤️ 3. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当 。python爬虫入门进阶
❤️ 4. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 5. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
😁 6. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
文章目录
1. 简介
1. 简介
上一篇文章我们介绍了
【MySQL从入门到精通】【高级篇】(二十五)EXPLAIN中ref、rows、filtered、Extra字段的剖析 通过前面几篇文章的学习,相信小伙伴们对EXPLAIN命令有了一个更加深入理解。这篇文章我们将来学习索引失效的11种情况。有时候并不是说加了索引,就一定能用上索引,还是要具体情况具体分析。
都有哪些维度可以进行数据库调优?简而言之:
- 索引失效,没有充分利用到索引—索引建立
- 关联查询太多JOIN (设计缺陷或不得已的需求) — SQL优化
- 服务器调优及各个参数设置(缓冲,线程数等)---- 调整my.cnf
- 数据过多 ----分库分表
关于数据库调优的知识点非常分散,不同的DBMS,不同的公司,不同的职位,不同的项目遇到的问题都不尽相同。
虽然SQL查询优化的技术有很多,但是大方向上完全可以分成物理查询优化和逻辑查询优化 两大块。
- 物理查询优化是通过索引和表连接方式等技术来进行优化,这里重点需要掌握索引的使用。
- 逻辑查询优化就是通过等价变换提升查询效率,直白一点就是说,换一种查询写法执行效率可能更高。
2. 数据准备
学生表(student)插入50万条数据,班级表(class)插入1万条数据。
2.1. 建表
-- 班级表CREATETABLE class(
id INTNOTNULLAUTO_INCREMENT,
classname VARCHAR(30)DEFAULTNULL,
address VARCHAR(40)DEFAULTNULL,
monitor INTNULL,PRIMARYKEY(id))ENGINE=INNODBAUTO_INCREMENT=1DEFAULTCHARSET=utf8;-- 学生表CREATETABLE student(
id INTNOTNULLAUTO_INCREMENT,
stuno INTNOTNULL,
name VARCHAR(20)DEFAULTNULL,
age INT(3)DEFAULTNULL,
classId INT(11)DEFAULTNULL,PRIMARYKEY(id))ENGINE=INNODBAUTO_INCREMENT=1DEFAULTCHARSET=utf8;
2.2. 设置参数
命令开启,允许创建函数设置:
setglobal log_bin_trust_function_creators=1;#不加global只是当前窗口有效
2.3. 创建函数
保证每条数据都不同
CREATEFUNCTION`rand_string`(n INT)RETURNSvarchar(255)CHARSET utf8 COLLATE utf8_unicode_ci
BEGINDECLARE chars_str VARCHAR(100)DEFAULT'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ';DECLARE return_str VARCHAR(255)DEFAULT'';DECLARE i INTDEFAULT0;WHILE i<n DOSET return_str=CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));SET i=i+1;ENDWHILE;RETURN return_str;END
随机生成班级编号
CREATEFUNCTION`rand_num`(from_num INT,to_num INT)RETURNSint(11)BEGINDECLARE i INTDEFAULT0;SET i=FLOOR(from_num+RAND()*(to_num-from_num+1));RETURN i;END
2.4. 创建存储过程
创建往student表中插入数据的存储过程
-- 创建往student表中插入数据的存储过程DELIMITER//CREATEPROCEDURE insert_stu(STARTINT,max_num INT)BEGINDECLARE i INTDEFAULT0;SET autocommit=0;#设置手动提交事务REPEAT#循环SET i=i+1;#赋值INSERTINTO student(stuno,name,age,classId)VALUES((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000));
UNTIL i=max_num
ENDREPEAT;COMMIT;#提交事务END//DELIMITER;
创建往class表中插入数据的存储过程
DELIMITER//CREATEPROCEDURE insert_class(max_num INT)BEGINDECLARE i INTDEFAULT0;SET autocommit=0;#设置手动提交事务REPEAT#循环SET i=i+1;#赋值INSERTINTO class(classname,address,monitor)VALUES(rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i=max_num
ENDREPEAT;COMMIT;END//DELIMITER;
2.5. 调用存储过程
class
-- 执行存储过程,往class表添加1万条数据CALL insert_class(10000);
student
CALL insert_stu(100000,500000);
3. 索引失效的情况
MySQL中提高性能的一个最有效的方式是对数据表设计合理的索引。索引提供了高效访问数据的方法,并且加快了查询的速度,因此索引对查询的速度有着至关重要的影响。
- 使用索引可以快速地定位表中的某条记录,从而提高数据库查询的速度,提高数据库的性能。
- 如果查询时没有使用索引,查询语句就会扫描表中的全部记录。在数据量大的情况下,这样查询的速度会很慢。
大多数情况下都默认采用B+树来构建索引,只是空间列类型的索引使用R树,并且MEMORY表还支持hash索引。
其实用不用索引最终都是优化器说了算,优化器是基于什么的优化器?基于cost开销(CostBaseOptimizer), 它不是基于规则(Rule-BaseOptimizer),也不是基于语义。怎么样开销小就怎么样来。另外,SQL语句是否使用索引,跟数据库版本,
3.1. 索引使用的简单说明
- 全值匹配的话,如果在字段上添加索引,那么可以使用到索引
- 最佳左前缀法则:即在MySQL建立联合索引的时会遵循最佳左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。 举例: 在student表中建立一个联合索引
CREATEINDEX idx_age_classid_name ON student(age,classId,name);
直接使用 name 字段进行查询的话则不能使用索引,不明白原理的话可以看下【MySQL从入门到精通】【高级篇】(七)设计一个索引&InnoDB中的索引方案,简单的说,就是在构建索引是是从最左边的字段开始构建的。
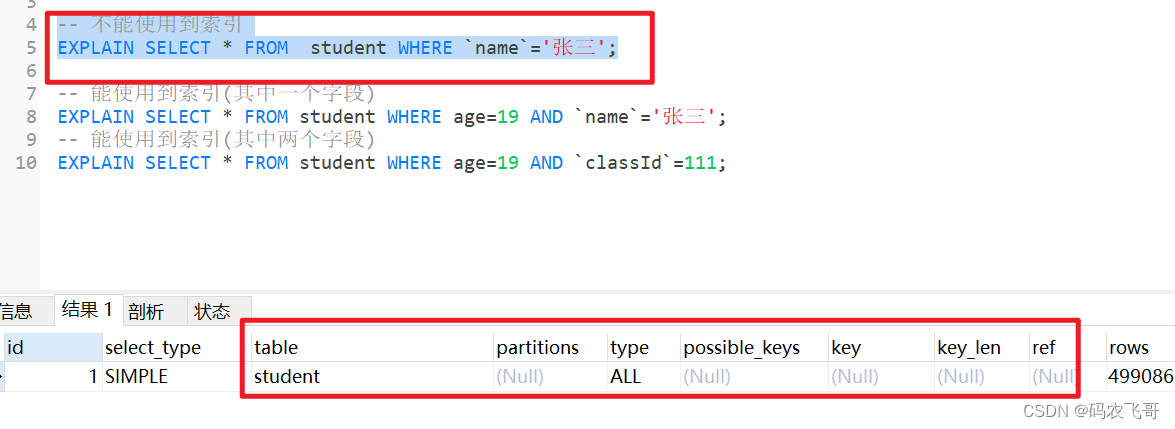
-- 不能使用到索引EXPLAINSELECT*FROM student WHERE`name`='张三';
能使用索引的情况:
-- 能使用到索引(其中一个字段)EXPLAINSELECT*FROM student WHERE age=19AND`name`='张三';-- 能使用到索引(其中两个字段)EXPLAINSELECT*FROM student WHERE age=19AND`classId`=111;
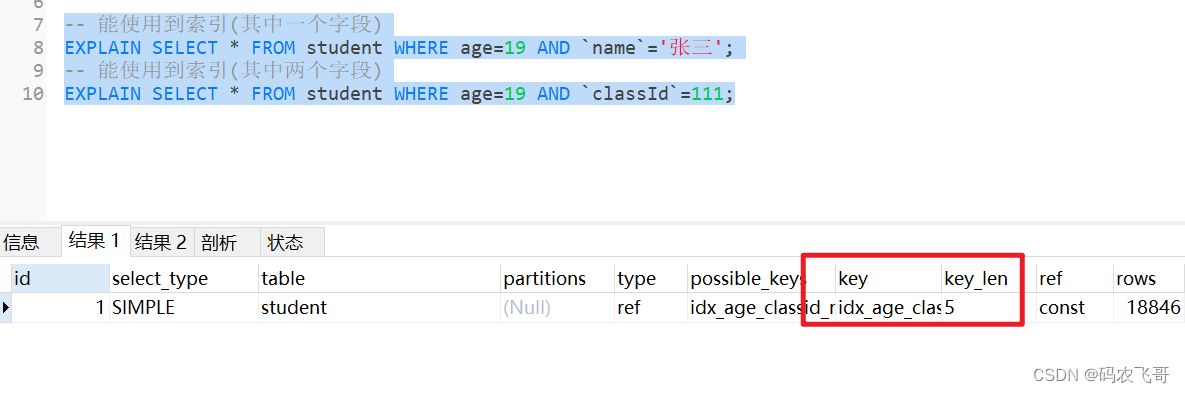
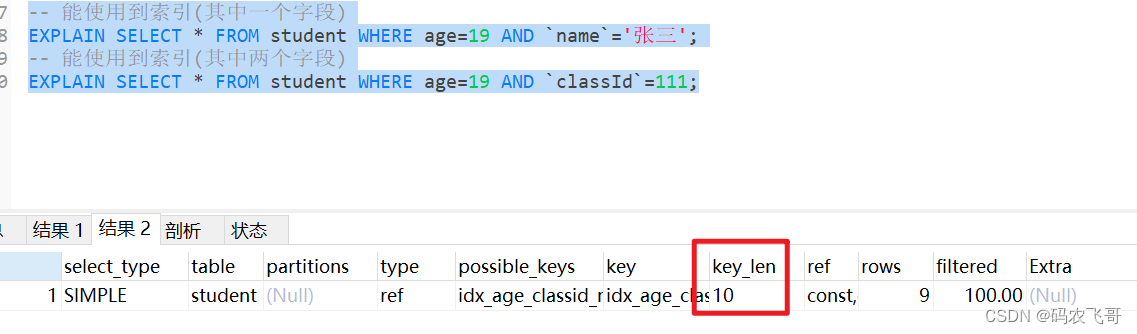
从key_len 字段的值就能够验证我们的结论。
结论:MySQL可以为多个字段创建索引,一个索引可以包含16个字段,对于多列索引,过滤条件要使用索引必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。 如果查询条件中没有使用这些字段中第一个个字段时,多列(或联合)索引不会被使用。
Aibaba《Java开发手册》中指出:索引文件具有B+树的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
- 主键插入顺序 对于一个使用InnoDB存储引擎的表来说,在我们没有显式的创建索引时,表中的数据实际上都是存储在聚簇索引的叶子节点的。 而记录又是存储在数据页中的,数据页和记录又是按照主键值从小到大的顺序进行排序,所以我们插入的记录的主键值依次增大的。那我们每插入满一个数据页就换到下一个数据页继续插入,如果我们插入的主键值忽大忽小的话,就比较麻烦了,假设某个数据页存储的记录已经满了,它存储的主键值在1~100之间:
 可这个数据页已经满了,在插进来咋办呢?我们需要把当前页面分裂成两个页面,把本页中的一些记录移动到新创建的这个页中。页面分裂和记录移位意味着什么?意味着:性能损耗!所以如果我们想尽量避免这样无谓的性能损耗,最好让插入的记录的主键值一次递增,这样就不会发生这样的性能损耗了,所以我们建议:让主键具有AUTO_INCREMENT。
可这个数据页已经满了,在插进来咋办呢?我们需要把当前页面分裂成两个页面,把本页中的一些记录移动到新创建的这个页中。页面分裂和记录移位意味着什么?意味着:性能损耗!所以如果我们想尽量避免这样无谓的性能损耗,最好让插入的记录的主键值一次递增,这样就不会发生这样的性能损耗了,所以我们建议:让主键具有AUTO_INCREMENT。
3.2. 计算、函数、类型转换(自动或手动)导致索引失效
在MySQL中对查询字段使用函数,或者对字段进行统计,又或者发生隐式转换的情况下会导致索引失效。
3.2.1. 在字段上使用计算
在查询字段上使用计算时,即使该字段上创建了索引,MySQL也不能使用该索引。举例如下:
-- 创建索引CREATEINDEX idx_stuno ON student(stuno);-- 不使用计算,能使用索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE stuno=100007;-- 使用计算,不能使用索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE stuno+1=100007;
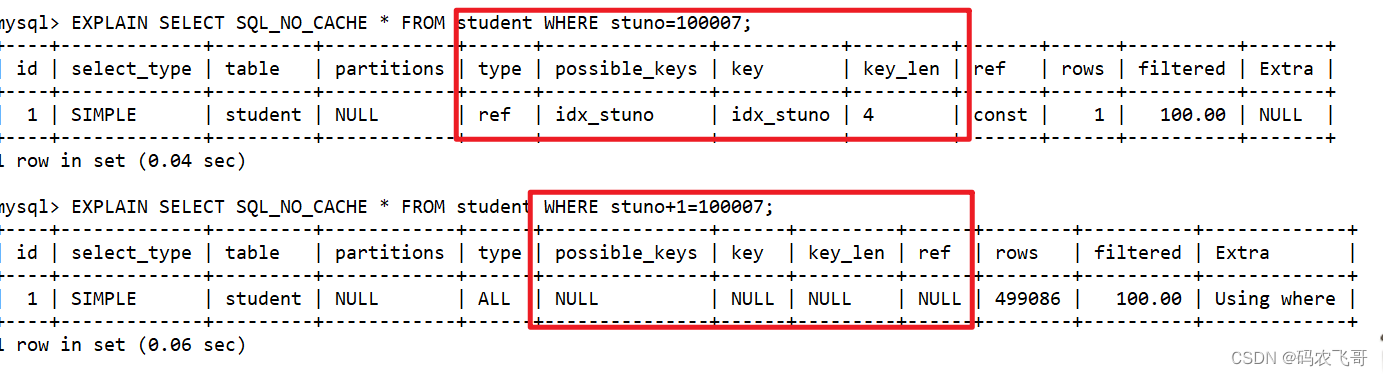
3.2.2. 使用函数
在student表的name字段上创建索引idx_name,查询name字段的前缀是abc开头的字段,第一个查询没有使用函数,第二个查询在查询字段上使用了字段。举例如下:
-- 创建索引CREATEINDEX idx_name ON student(NAME);-- 不使用函数,能使用索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE student.`name`LIKE'abc%';-- 使用函数,不能使用索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERELEFT(student.`name`,3)='abc';

3.2.3. 类型转换导致索引失效
student 表的name字段的数据类型是varchar类型,正常的话需要传入一个字符串,如果我们传入一个数字给该字段会发生什么呢?
-- 没有类型转换,索引有效EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE name='VcByPC';-- 有类型转换的情况,索引失效EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE name=111111;
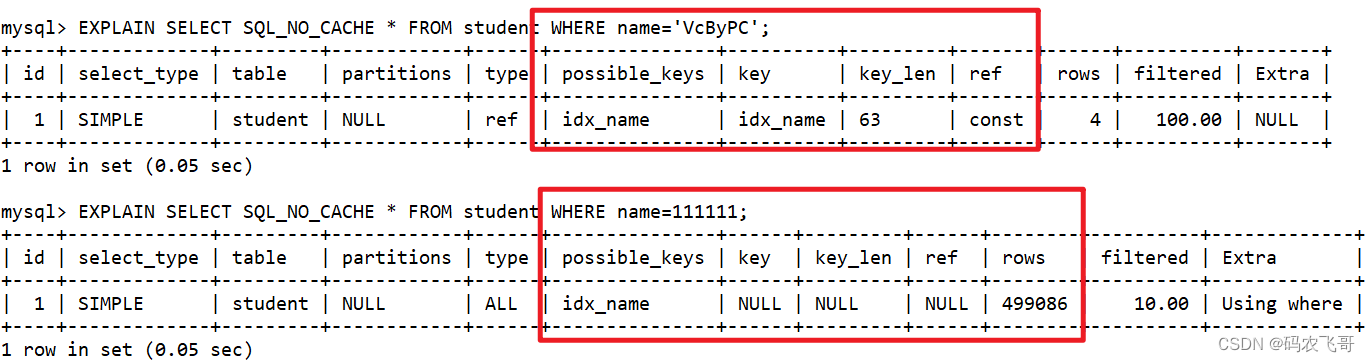
3.3. 范围条件右边的列索引失效
让我们先来看一个例子:
-- 删除其他索引ALTERTABLE student DROPINDEX idx_name;ALTERTABLE student DROPINDEX idx_stuno;-- 创建一个联合索引CREATEINDEX idx_classid_age_name ON student(classId,age,name);-- 正常使用索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE classId='1211'AND age=10and NAME='VcByPC';-- 范围条件右边的列索引失效EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE classId='1211'AND age>10and NAME='VcByPC';
首先,创建一个名为idx_classid_age_name的联合索引,列的顺序是classId,age,name。
接着两个查询都是用到了这三个列作为查询条件,两者唯一的区别第一个查询是全值匹配, 而第二个查询中 age的查询条件是age>10 是一个范围条件,让我们来看看最终的效果: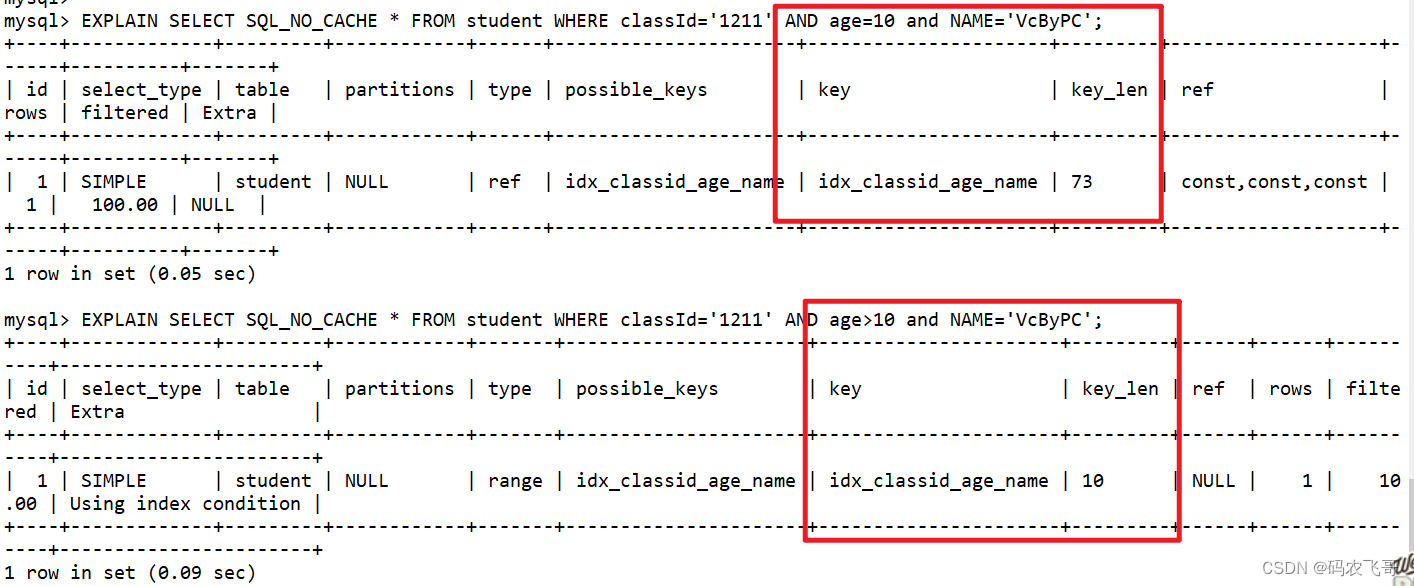
从效果图可以看出,两个查询都使用到了联合索引idx_classid_age_name,两者的区别在于key_len字段差别很大,第一个查询的key_len有73=
20*3
+1+2+5+5,因为 name字段的类型varchar(20),长度为20, 在utf-8中一个字符占用3个字节,那么就是
20*3
,并且name有可能为空就需要加1,而且name字段是变长的,那么需要1个字节存储长度,存储索引1个字节。而classId字段和age字段都是int类型,utf8中int类型占用4个字节,存储索引信息1个字节,而第二个查询的key_len则只有10。
应用开发中范围查询,例如:金额查询,日期查询往往都是范围查询。应将查询条件放置where语句最后。
3.4. 不等于索引失效
字段的条件是不等于的情况下,在字段上建立的索引会失效。
-- 创建索引CREATEINDEX idx_stuno ON student(stuno);-- 等于,能使用索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE stuno=100007;-- 不等于,不能使用索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE stuno!=100007;

等于查询是精确的等值查询,能直接用上在该字段上建的索引,而不等于查询在是范围查询,需要全表遍历。
3.5. is not null 不能使用索引(is null可以使用索引)
如下在name字段上建立索引之后,一个查询的条件是:
name IS NULL
,另一个查询的条件是:
NAME IS NOT NULL
。
CREATEINDEX idx_name ON student(NAME);-- IS NULL可以触发索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE`name`ISNULL;-- IS NOT NULL不能触发索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE NAME ISNOTNULL;
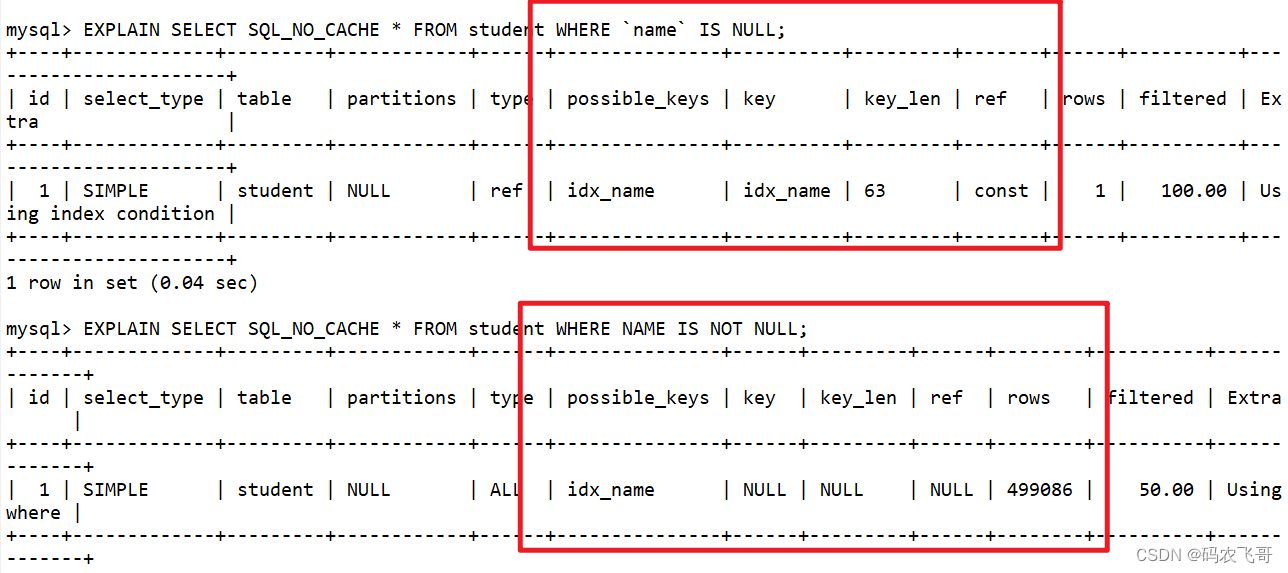
结果如上图所示:IS NULL可以触发索引,而IS NOT NULL 则无法触发索引。由此我们可以得出如下结论:最好在设计数据表就将字段设置为 NOT NULL 约束,比如你可以将INT类型的字段,默认值设置为0,将字符串类型的默认值设置为空字符串(’ ')。
同理,在查询中使用 not like 也无法使用索引,导致全表查询。
3.6. like (左匹配能使用索引,右匹配或者全模糊查询不能使用索引)
在使用 LIKE 关键字进行查询的查询语句中,如果匹配字符串的第一个字符为‘%’,索引就不会起作用,只有’%' 不在第一个位置,索引才会起作用。
-- 左匹配,能使用索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE`name`LIKE'abc%';-- 右匹配,不能使用索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE`name`LIKE'%abc';

在用like进行模糊查询时,建议使用左匹配,禁用全模糊查询,遇到全模糊查询时应该考虑走索引。
3.7. OR 前后存在非索引的列
在WHERE子句中,如果在OR前的条件进行索引,而在OR后的条件列没有进行索引,那么索引会失效,也就是说,OR前后的两个条件中的列都是索引时,查询中才使用索引。
因为OR的含义就是两个只要满足一个即可,因此只有一个条件里进行了索引是没有意义的。只要有条件列没有进行索引,就会进行全表扫描。因此索引也会失效。
-- 未使用索引EXPLAINSELECT SQL_NO_CACHE *FROM student WHERE`name`='VcByPC'OR age=10;

总结
本文详细介绍了索引失效的六种情况,其实大家也不用去背诵这几种情况,只需要深入的理解索引的结构就能够想明白。MySQL的InnoDB的索引本质上是一个平衡多叉树,按照索引字段的大小从小到大构建。尤其适合唯一性高的字段的全值匹配查询。
综上所述,建议如下:
- 对于单列索引,尽量选择针对当前query过滤性更好的索引。
- 在选择组合索引的时候,当前query中过滤性最好的字段在索引字段顺序中,位置越靠前越好。
- 在选择组合索引的时候,尽量能够包含当前query中的where子句中更多字段的索引。
- 在选择组合索引的时候,如果某个字段可能出现范围查询时,尽量把这个字段放在索引次序的最后面。
总之,书写SQL语句时,尽量避免造成索引失效的情况。
粉丝福利
1. 送书活动
为了回馈广大粉丝们长期以来的厚爱,本博主决定给小伙伴们送出2类共4本图书。在此特别感谢 机械工业出版社有限公司的赞助,所有图书均包邮包邮包邮!!!!
第一类【MySQL数据库进阶实战】:共3本
《MySQL数据库进阶实战》,本书是作者基于多年的教学与实践进行的总结,重点介绍了MySQL数据库的核心原理与体系架构,涉及开发、运维、管理与架构等知识。全书共12章,包括MySQL数据库基础、详解 InnoDB存储引擎、MySQL用户管理与访问控制、管理MySQL的数据库对象、MySQL应用程序开发、MySQL的事务与锁、MySQL备份与恢复、MySQL的主从复制与主主复制、MySQL的高可用架构、MySQL性能优化与运维管理、MySQL数据库的监控和使用MySQL数据库的中间件。读者根据本书中的实战步骤进行操作,可以在实际项目的生产环境中快速应用并实施MySQL。
第二类【检索匹配:深度学习在搜索、广告、推荐系统中的应用】:共1本
《检索匹配:深度学习在搜索、广告、推荐系统中的应用》,本书主要介绍了深度学习在互联网核心的三大类业务(搜索、广告、推荐系统)检索系统中的应用。书中详细讲述了检索匹配的理论、演进历史,以及在业务中落地一个基于深度学习算法模型的全流程技能,包括业务问题建模、样本准备、特征抽取、模型训练和预测等,并提供了相应的代码。
如何免费获得该书呢?
所有获奖用户先三连:评论,点赞,收藏。
1. 评论获得
- 本文优质评论两条,且该评论点赞数是最高的,分别获得《MySQL数据库进阶实战》一本!
例如2条评论点赞数并列第一的,以评论的时间谁早!
2. 抽奖获得
- 私聊博主,博主会随机抽取两个小伙伴,获得《MySQL数据库进阶实战》一本或《检索匹配:深度学习在搜索、广告、推荐系统中的应用》一本。
统计截止时间:2022/10/19 18:00:00
2. DAMS中国数据智能管理峰会 门票免费拿
12月2日,来DAMS中国数据智能管理峰会-上海站,大家一起探索大数据与云原生强强联合的方式、挖掘由此激发的软件发展和技术进步。
演讲嘉宾所在单位:京东、美团、字节跳动、蚂蚁集团、网易、新浪、携程、唯品会、哔哩哔哩、vivo、货拉拉、工商银行、平安银行、光大银行、华夏银行、汇丰科技等产研界技术领跑单位。
演讲议题聚焦:
大数据&数据资产管理:数据治理丨存算分离丨云原生OLAP丨湖仓一体丨智能分析
数据库:云原生分布式丨时间序列丨服务自治丨中间件
运维:AIOps丨故障分析丨性能优化丨离在线混部丨高可用建设
金融科技:规模化监控丨实时数仓丨分布式改造丨国产化替代丨数字化转型
主会场限时免费,仅限10人,先到先得,报名通道戳➡:https://www.bagevent.com/event/8100960?bag_track=MNFG
版权归原作者 码农飞哥 所有, 如有侵权,请联系我们删除。