
文章目录
1. 拥塞控制
整个网络中的所有主机和设备 遵守的是 TCP/IP协议
如: 一个班中有30个人,进行考试,只有2个或者3个人挂科了,这很正常
但若只有2个或者3个人过了,其他人都挂科了,就很不正常
同样是挂科,挂少和挂多 是不同的事情
当主机A给主机B发送消息时
若发送1000个报文,只有1个或者2个人丢失了,就认为算是正常丢包,进行超时重传 补发数据即可
发送1000个报文 丢失 900多个,主机A绝对不认为是自己发送的问题,认为是网络的问题
把网络出现的潜在问题的状态 称为 网络拥塞
当处于网络拥塞时,会影响网络覆盖的所有主机,不仅主机A出现大量丢包,其他主机也会出现大量丢包
大量丢包时,发送方的发送策略是什么?
先减少发送量
- 给网络继续有缓冲的时间
- 给所有主机继续摸清楚网络的严重情况
如果出现网络拥塞,则需保证
1.保证网络拥塞不能加重
2. 在网络拥塞有起色的情况下,尽快恢复网络通信
慢启动
TCP引入 慢启动 机制,先发少量的数据,摸清当前网络拥堵状态,再决定按照多大的速度传输数据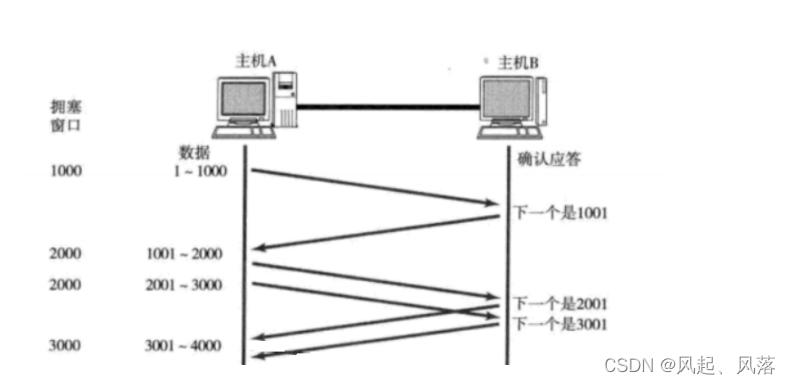
当前判定网络拥塞了,主机A向主机B发送一个报文,先进行询问,若收到应答,则主机A再发送两个报文向主机B
若再收到应答,则 主机A发送4个报文,依次类推
若能收到应答,则下次发送当前2倍的报文数量
若收不到应答,收到主机A给主机B发送的报文过不去,当前发送的数据量就能直观反映出网络拥塞的严重程度
报文从发送1个、2个、4个,叫做 网络状态的探测
拥塞窗口 可以看作是 发送方主机,衡量网络健康状态的指标
需要借助 拥塞窗口,来衡量 网络拥塞的严重程度
当发送超过拥塞窗口大小的报文时,可能会出现网络拥塞的情况
滑动窗口最终大小
滑动窗口 = min(对端主机的接收能力win ,网络的拥塞窗口)
一次向对端发送的数据量,取决于 对端主机的接受能力与网络拥塞窗口的最小值
所以最开始时,拥塞窗口为1,每收到一次ACK应答,拥塞窗口加1
每次发送数据包时,将拥塞窗口和接收端主机反馈的窗口大小作比较,取较小值作为实际发送的窗口
为什么采用指数增加的方案,来设计对应的拥塞窗口的增加速度?
如:有一个地主,有很多的房子,手下有一个佃农,租地主的房子
佃农欠了地主一年多的房租,有一天地主向佃农讨要房租
佃农就开始诉苦,想要等把粮食卖了再还
地主不同意这种做法,然后出了一个看似很好的方法给佃农
地主告诉佃农,今天给我一粒米,明天给我两粒米,每次按照指数增加 给我一个月就算把房租还上
佃农一听非常高兴,就同意了这种做法
可佃农刚给了十天不到,就发现自己给不起了
这种增加特点为 前期很慢,一旦过了临界点后,增加速度就非常快
所以慢启动只是前期慢,但是增张速度快
地主一想,这样一直指数增长上去,佃农也还不起,压榨有些过头了
所以地主就换了一种偿还方式,前期还是指数增加还,还到一定程度就用这么还了,按照线性增长还即可
如:还到1w后,每次只需固定增加1000即可
为了不增加那么快,因此不能使拥塞窗口单纯的加倍
引入一个慢启动的阈值
当拥塞窗口超过整个阈值,不再按照指数方式增长,而是按照线性方式增加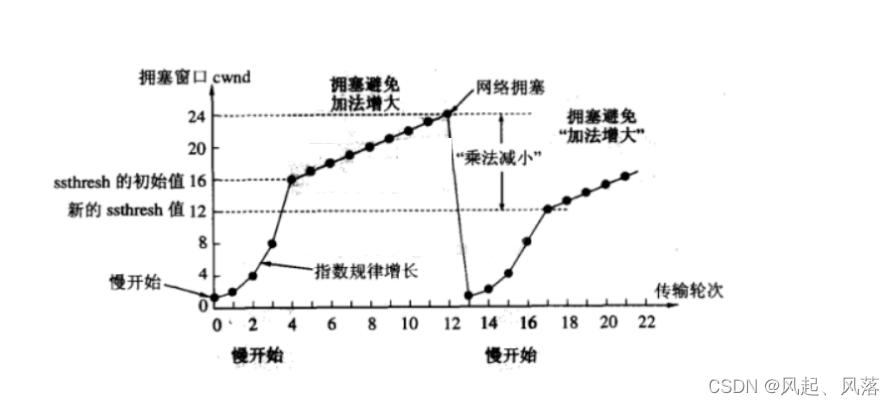
刚开始 由于是慢启动,以指数增加,增长速度很快,当达到 慢启动的阈值(ssthresh)时,不在以指数增加
而是以线性方式增加,当拥塞窗口大小探测到24时, 发现造成 网络拥塞
慢启动的阈值变为原来的一半,变为新的ssthresh值
同时 拥塞窗口被置为1,重新按照指数增长,当再次到达新的 慢启动的阈值时,再次以线性方式增加
2. 延迟应答
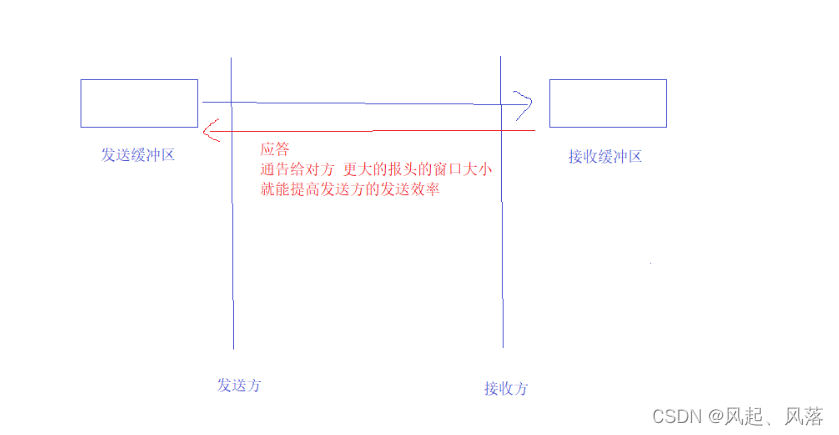
将数据从发送缓冲区 拷贝到接收缓冲区
作为接收方,通过应答 通告给对方 更大的 报头的窗口 ,从而进一步提高发送方的发送效率
对方就会更新出更大的滑动窗口
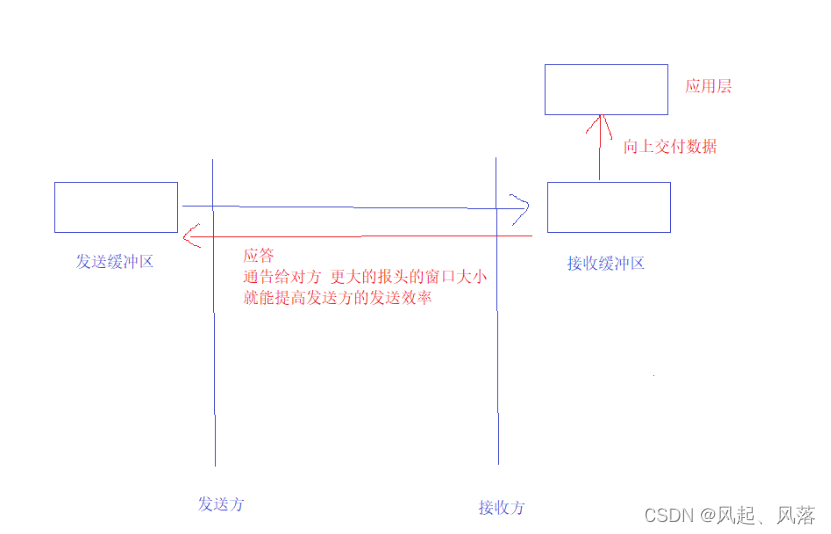
只要当把接收方的数据尽快向上层交付,才能使接收缓冲区的剩余空间 更多,即 报头的窗口更大
所以给接收方的上层更多的时间进行读取
1.让它在这段时间内,尽快读取
2. 若一直在读,读取更多
所以引入了 延迟应答 的概念,在不超过它的超时时间的范围内,等待一会,再应答
延迟应答的本质 是提高效率
一般延迟应答 有两者延迟策略
- 数量限制 :每隔N个包就应答一次
- 时间限制:超过最大延迟时间就应答一次
3. 粘包问题
并不清楚对方是如何发的,TCP面向字节流,收发不直接相关,别人如何发的并不清楚
要保证 读到一个完整的报文
要么读一个,要么读多个,但每一个都可以分开,这样才可以对应用层报文正确处理
读取时,对下一个保文,多读或者少读的情况,称为数据包的 粘包问题
如: 假设你家蒸了包子,刚出了一锅包子,你饿的不行,伸手就去拿
此时拿到的包子可能是半个包子,也可能一下拿了好几个
因为包子与包子之间是粘在一起的
所以正常把包子蒸好后,立马把包子一个个的分开,此时再去拿包子就是一个个的了
把包子分开 可以看作是解决数据包的粘包问题
粘包问题的本质 :明确包子之间的边界
方案1
采用定长报头,发送方基于套接字 基于应用层 发送的报文大小都是定长的(1024、4096)
所以对方在读取数据时,必须在(1024)4096个字节下读取,读不到不往上交付
方案2
在报文与报文之间添加特殊符号
如:在报文与报文之间用 空格 作为分隔符
4. TCP异常情况(面试题)
进程终止
将链接建立好了,客户端的进程与服务端的进程 使用对应的文件描述符
使客户端和服务器 双方进行通信
若通信双方有一方的进程直接崩掉了,那维护的链接怎么办?
一个进程曾经申请了很多资源,最终进程挂掉了,进程所申请的内存不在了
进程的PCB 地址空间等都被操作系统管理着
操作系统在创建进程时,申请资源,当进程崩溃了,操作系统要将对应的资源回收
所以当进程退出时,该进程通过系统调用创建的链接或文件,会被操作系统自动关掉
机器重启
当打开画图板时,若不关闭画图板,而直接将电脑关机,此时操作系统就会提示,当前系统中还有正在运行的进程,是否要终止
若点击是,则关机之前,先会把进程杀掉
关机之前,进程首先将自己的资源回收
所以在服务里启动 更多的进程,关机时,时间会更久一点
关机之前 会自动进行四次挥手,把链接全部断开,进程全部杀掉
网线断开
客户端和服务器在正常通信,双方正在收发消息,把客户端的网线拔了
当客户端打开浏览器访问某一个页面时,浏览器会立马识别到页面发生变化了,无法正常工作
说明拔网线这种硬件行为,可以被本地的操作系统识别
底层网络出现问题,对应的链接在客户端上,操作系统能识别到网络无法正常通信,所以链接维护就没有意义, 操作系统可以做到把链接直接关掉
服务器是不知道网线被拔了,就出现了 链接状态 认知不一致的问题
服务器有对应的保活策略,定期问客户端的TCP链接,是否活着,若没有应答,会把链接关掉
5. 全连接队列
TCP协议,需要在底层维护,全连接队列,最大长度是 listen函数的第二个参数+1
如:listen函数的第二个参数为1,则最多连接成功2个
若再有连接,则服务器都会处于 SYN_RECV状态
若服务器长时间不处理ACK,因为上层一直有两个连接存在,所以服务器压力很大
所以会维护一点时间,若还是完成不了三次握手,该链接会被释放掉
全连接:已经处于连接成功状态,还未来得及被上层取走
 如:假设你是一个海底捞服务员,里面已经坐满人了 当有客人来询问时,你要是说已经满了,去其他地方就餐吧,客人就走了 但是极有可能再过几分钟时,里面有位置了,对应的桌椅 就要空闲几分钟
如:假设你是一个海底捞服务员,里面已经坐满人了 当有客人来询问时,你要是说已经满了,去其他地方就餐吧,客人就走了 但是极有可能再过几分钟时,里面有位置了,对应的桌椅 就要空闲几分钟
所以就推出了让客人排队的方式
此时再有客人来询问,你就可以告诉他,里面已经满了,但是再过几分钟就有位置了,可以排队等待下
这样就可以使座椅的利用率达到百分百
要排队的理由 就在于 要 时时刻刻保证自己餐厅内部资源的使用率是百分百
结论:
海底捞不能没有外部排队
全连接队列不能没有,当服务器内部有一些客户退出了,把对应的网络资源腾出来了,立马在底层把连接获取上来
对外提供服务,不会让服务器处于空转的情况
若海底捞的老板,在外面安排非常多的座位,用于客户排队,但排很长的队,客户是不愿意的
有这些座位的钱还不如 将餐厅扩大一些
队列不应该太长,将维护队列的成本嫁接到服务器上面,让服务器有更大的吞吐量
版权归原作者 风起、风落 所有, 如有侵权,请联系我们删除。