
1. 前言
在现代软件开发中,性能优化至关重要,尤其是在资源受限的系统和处理大量数据的应用程序中。C/C++ 作为低级编程语言,提供了对底层硬件的直接访问,使其成为性能关键应用程序的理想选择。
然而,编写高效的 C/C++ 代码是一项具有挑战性的任务,需要对语言特性、编译器优化、硬件架构、数据结构和算法有深入的理解。本文旨在为 C/C++ 程序员提供一个全面的指南,涵盖各种优化技术,以提高代码性能,重在指南引导,不讲细节。
2. 编译器
编译器不仅仅编译链接代码为可执行文件,更是会在编译链接过程中优化代码以达到更好的性能。
2.1. 优化级别
调试版本使用-O0优化,生成的汇编代码与实际代码能够更好对应,且附加调试信息,更利于分析调试代码。
发布版本建议使用-O2,其会启用内联、循环展开、指令顺序优化、常量替换等技术优化代码性能。
激进优化级别-O3,过度的循环展开、内联等,会导致可执行文件变大,甚至可能导致栈溢出,其负作用较大。此优先级别优先级靠后。
针对Arm内核时,armcc比gcc有更好的性能优化。
2.2. 内联函数
修饰符inline标识函数可以被内联优化。但是编译器在-O2时会自带内联优化功能,简单的函数(小于10行且逻辑简单)的函数,编译器会自动内联优化。过于复杂的函数即使标识了inline,编译器也可能不会使用内联优化。
既然编译器能够自动完成内联优化,那么手动添加inline的作用是什么呢?手动添加inline的作用更多是给程序员看的,指明这个函数希望进行内联,后续的修改不要太过复杂影响编译器内联。
对于一些无法明确是否内联的函数,可以在-O2级别下生成的汇编文件中查找目标函数名,如果查找到了表明没有优化,否则就是被内联优化了。
**2.3. **内置指令
内核指令集中有一些复杂指令,针对一些特殊场景,可以提供更好的性能。其使用较复杂,所以编译器提供了内置指令,让用户可以更方便调用这些内置指令。常见的内置性能优化指令有:
- __builtin_prefetch(addr, rw, locality): 预取数据或指令到缓存中。
- __builtin_assume_aligned(ptr, align): 假设指针 ptr 指向对齐为 align 字节边界的内存,避免对齐检查。
- __builtin_memcpy(dest, src, n): 使用汇编语言实现的快速内存复制。
- __builtin_memset(dest, c, n): 使用汇编语言实现的快速内存设置。
- __builtin_clz(x): 计算整数 x 的前导零位的数量。
- __builtin_ctz(x): 计算整数 x 的尾随零位的数量。
- __builtin_popcount(x): 计算整数 x 中设置的位的数量。
- __builtin_bswap32(x): 字节交换 32 位整数 x。
- __builtin_bswap64(x): 字节交换 64 位整数 x。
注意:有些编译器可能只支持上述部分内置指令,另外可能存在内核关闭了SIMD模块导致部分指令无效。所以在使用上述内置指令时,需要实际验证是否支持。
2.4. 其他优化参数
- -ffunction-sections -fdata-sections 和 -Wl,--gc-sections:这些选项用于将函数和数据段放置在独立的小节中,并在链接时移除未使用的小节,从而减小目标代码的大小。
- -flto:启用链接时优化(Link-Time Optimization)。这个选项允许编译器在链接阶段进行全局优化,包括函数内联、死代码消除等。它可以提供更大范围的优化,但可能会增加编译和链接时间。
3. CPU
无论是X86_64、ARM还是RISC-V,在指令优化方面的技术基本类似,主要包括流水线、分支预测、SIMD 指令集和内存读写管理等。编程上充分利用这些CPU优化特性,可以写出更能发挥CPU性能的代码。
3.1. 流水线
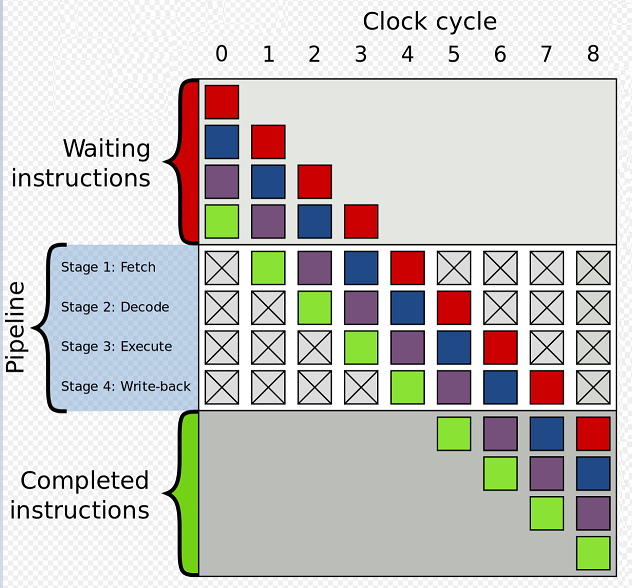
内核CPU的流水线(Pipeline),简单来说就是将CPU执行指令的过程拆分为几个阶段来并行执行,以提升代码执行效率。流水线级数越多,其单位时间内执行的指令就越多,表现为其性能就越好。
3.1.1. 顺序执行
下图是一个4级流水线,缓存行(Cache Line, 一般是L1,一级缓存)上存放Waiting Instructions。
- Clock 1时取出绿色指令放入流水线。
- Clock 2时取出紫色指令放入流水线,并行解码绿色指令。
- Clock 3时取出蓝色指令放入流水线,并行解码紫色指令,并行执行绿色指令。
- Clock 4时取出红色指令放入流水线,并行解码蓝色指令,并行执行紫色指令,并行回写绿色指令。
- Clock 5时,绿色指令执行完成,流水线空出一级,可以从缓存行上取出新的指令加入流水线,继续类似前面的执行流程。
3.1.1. 乱序执行
顺序执行按顺序从缓存行中取出指令加入流水线执行。后一条指令如果需要前面指令做前提,就会导致后一条指令等待前一条指令执行完再执行,这会影响并行执行效率。
乱序执行会将命令进行一些处理,会优先执行那些没有相关性的指令,这样会提升指令并行执行的效率。针对缓存行上的代码相关性的分析,在处理有中断函数、多核并行代码中的共享变量时,可能判断失误,导致异常。针对这种情况,需要指定内存屏障(Memory Barriers)指令来优化。内存屏障影响性能,所以只在需要的地方使用。
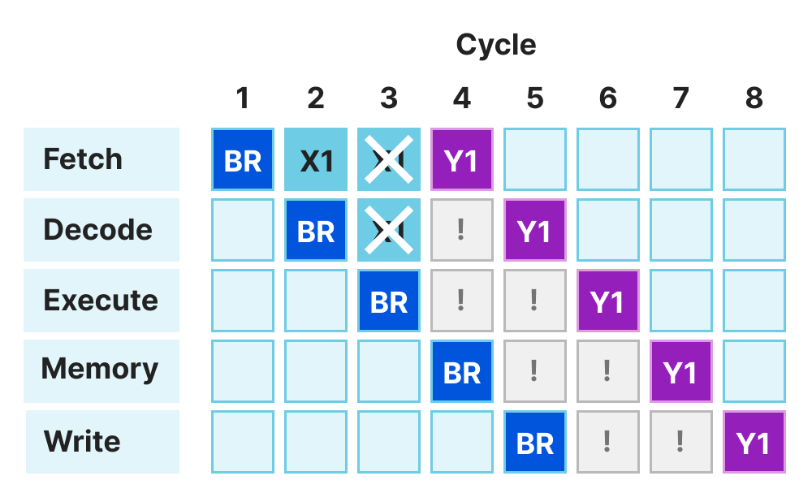
3.1.2. 分支预测
CPU遇到比较跳转指令时,后续取指令是顺序取还是取跳转处指令?这个非常影响流水线效率。如:
BR label_a;
X1
...
label_a:
Y1
BR指令在执行时,发现流水线上的指令在接下来无用,需要取址Y1指令才可以。这样后续流水线的效率就会降低。
编译器提供内置指令,可以指定代码的发生的概率,让CPU更好地处理分支预判。
// __builtin_expect的第2参数指示编译器预测第1个参数x的结果,1指示x > 0为正。
if (__builtin_expect(x > 0, 1)) {
// x 为正的后续代码
} else {
// x 为非正的后续代码
}
// __builtin_expect的第2参数指示编译器预测第1个参数y的结果,0指示y > 0为负。
if (__builtin_expect(y > 0, 0)) {
// y 为正的后续代码
} else {
// y 为非正的后续代码
}
stackoverflow上点赞最多的一个问答就是关于分支预测的。排序过后的循环判断比未排序的循环判断快近10倍。因为排序过后的循环判断分支预测是稳定的,cpu分支预测根据上一次的判断结果来预测下一次,基本就不会出现预测错误的情况,导致性能非常好。
int main()
{
// Generate data
const unsigned arraySize = 32768;
int data[arraySize];
for (unsigned c = 0; c < arraySize; ++c)
data[c] = std::rand() % 256;
// !!! With this, the next loop runs faster.
std::sort(data, data + arraySize);
// Test
clock_t start = clock();
long long sum = 0;
for (unsigned i = 0; i < 100000; ++i)
{
for (unsigned c = 0; c < arraySize; ++c)
{ // Primary loop.
if (data[c] >= 128)
sum += data[c];
}
}
double elapsedTime = static_cast<double>(clock()-start) / CLOCKS_PER_SEC;
std::cout << elapsedTime << '\n';
std::cout << "sum = " << sum << '\n';
}
3.2. 缓存
3.2.1. 概念
CPU的流水线取指速度非常快,如果直接从内存上取,速度太慢。所以CPU流水线会配置一个速度非常快的缓存来存放指令,这就是缓存行。有些CPU配置的缓存可能有多级,如L1、L2、L3三级。L1是离CPU执行核心最近的缓存,所以CPU访问L1速度最快。依据CPU架构的设计,有些内核是没有缓存的。
Cortext-M0因为是低功耗设计,其不支持缓存,只能直接从SRAM或Flash上取指。
Cortex-M7、Cortext-R82或risc-v一般是支持缓存设计,且只有一级缓存。
缓存大小从几百字节到几十K字节不等,为了提升从主存读取内容到缓存,缓存又分为多个缓存行,其大小16、32、64或128字字,每次只从主存上取缓存行大小的内容到缓存行上。缓存行详细数值参数CPU技术文档。
缓存又分为指令缓存(Instruction Cache,I-Cache)和数据缓存(Data Cache,D-Cache),分别存储指令和数据。
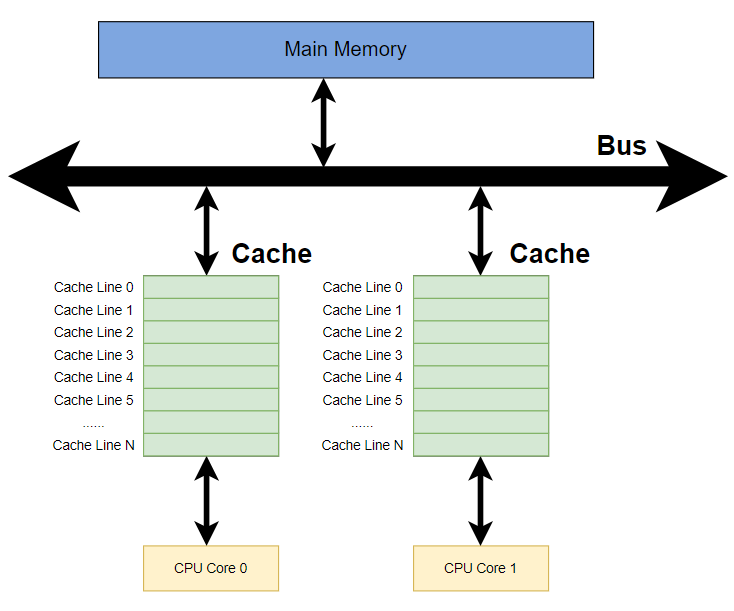
3.2.1. 缓存命中率
CPU读取先从缓存上去读取指令或数据,如果缓存没有找到想要的指令或数据,即缓存未命中(Cach Miss),再从主要去加载。这个找到指定指令和数据的概率就是缓存命中率。更高的缓存命中率(Cache Hit Rate),意味着更高的执行效率。所以提升缓存命中率是提升执行性能的重要手段。
3.2.2. 缓存行
缓存行是缓存操作的最小单位,其大小为16的倍数,实际与具体的CPU内核相关。尤其是在嵌入式CPU内核中,因为成本的原因,其缓存更小。当缓存行都转存了数据之后,需要加入新数据到缓存中时,必将有部分缓存行失败。缓存行管理算法,一般使用"最近最少使用(Least Recently Used,LRU)",即按使用时间先后来失效缓存行。
3.2.3. 数据局部性
为了提升缓存的命中率,编程中访问数据的设计需要更符合LRU算法。如下示例:
const int ROW = 512;
const int CLO = 1024;
int nArr[ROW][CLO] = {};
int main(int nArg, char *args)
{
for (int i = 0; i < ROW; i++)
{
for (int j = 0; j < CLO; j++)
{
// 访问的数据内存是连续的,不需要频繁从主存读取数据到缓存
// 这样的操作效率高,体现出数据的局部性
nArr[i][j] = i + j;
}
}
for (int i = 0; i < CLO; i++)
{
for (int j = 0; j < ROW; j++)
{
// 访问的数据内存是不连续的,需要频繁从主存读取数据到缓存
// 这样的操作效率很低
nArr[i][j] = i + j;
}
}
return 0;
}
3.2.4. 指令局部性
指令缓存同样需要遵循LRU算法,以提升命中率。如果下图示例,是否使用拆分循环体来提升指令缓存命中率,取决于具体的代码大小布局。
// 方式1,如果FA、FB、FC、FD一起导致指令缓存不够用
// 那么就会发生每次循环重新加载指令,影响性能
// 如果FA、FB、FC、FD一起导致指令缓存够用,则不影响性能
for (int i = 0; i < 1024; i++)
{
FA();
FB();
FC();
FD();
}
// 方式2,如果如果FA、FB、FC、FD一起导致指令缓存不够用,可以拆分为多个循环
// 保证循环过程中不重复加载指令
for (int i = 0; i < 1024; i++)
FA();
for (int i = 0; i < 1024; i++)
FB();
for (int i = 0; i < 1024; i++)
FC();
for (int i = 0; i < 1024; i++)
FD();
3.2.5. 缓存友好型数据结构
缓存友好数据结构的特点:
- 数据起始位位置缓存行对齐。
- 数据分布紧凑,尽量分布在缓存大小内。
数组是缓存友好型数据结构,传统的链表不是缓存友好型数据结构,可以考虑用跳表或块状链表来替换传统的链表,也可以将链表预分配到连续的内存上以实现缓存友好。
3.2.6. 缓存一致性
缓存一致性主要在多核/多线程中需要考虑。如果CPU0和CPU1同时操作位于同一个缓存行对应上的数据,为了保证数据的正确性,不仅CPU需要做一些额外的操作来保证数据同步,系统软件也要加一些内存屏障来保证数据的同步。所以在多核操作时,不同CPU操作的数据尽量不要在同一个缓存行内,减少缓存行同步带来的性能影响。
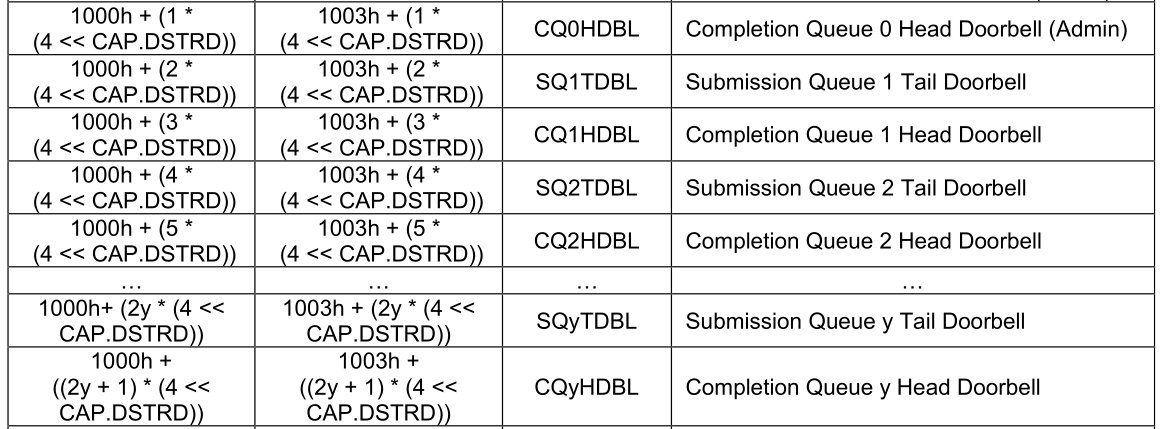
举例:NVMe协议中有一个字段CAP.DSTRD,其作用是配置主机驱动Doorbell 步进的。因为主机驱动是一个CPU对应一个Doorbell。假设有4个CPU,那么就有4个Doorbell,如果4个Doorbell放在同一个缓存行中,那么CPU更新访问Doorbell的效率会降低好几倍。通过配置CAP.DSTRD来添加缓存行填充,让4个Doorbell分布在4个缓存行,会大大提升CPU更新访问Doorbell的效率。CAP.DSTRD的作用就是缓存行填充,以避免出现多核访问出现竞态,提升效率。
3.2.6. 预取
通过预测算法,提前预测出要取的数据,然后使用预取指令将数据提前加载到缓存上来。下面的代码来自Linux内核,使用__builtin_prefetch提前预取下面操作的内容到缓存上去,降低Cache Miss的概率,提升性能。
依据CPU类型和编译器不同,__builtin_prefetch的效果也不一样,在某些情况下甚至会负作用,因为阻碍了系统优化。如连续的内存,一般没必要预取,这种编译器和CPU能够自动处理提前预取,减少出现Cache Miss现象。预取内存主要针对那些与当前操作的内存相隔较远的内存。所以在使用预取指令时,一定要进行基准性能验证,不要轻易使用。
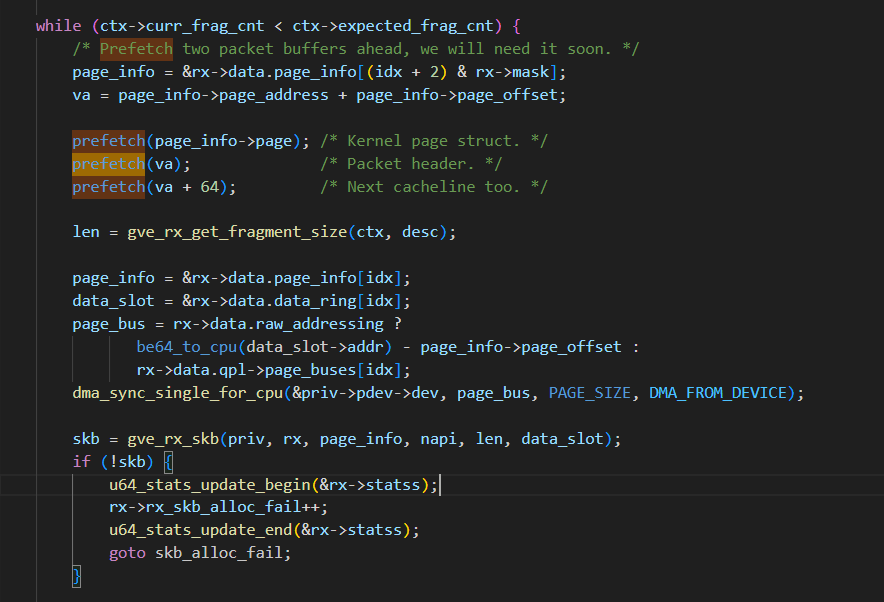
参考Is software prefetching (__builtin_prefetch) useful for performance? – Daniel Lemire's blog
3.3. CPU总线
在嵌入式MCU设计领域,芯片内部的连接总线一般使用AXI或AHB来连接CPU、内核和外设。AHB总线相对简单,支持突发传输,不支持缓存一致性,所以AHB一般应用于单核且非超高频率的MCU。而AXI总线是复杂的支持超高速,支持突发传输,支持缓存一致性,所以更多用于多核CPU的设计架构。
3.3.1. 总线传输类型
总线访问内核分为非突发传输和突发传输。
- 非突发传输就是地址-数据传输,即通过总线传输地址,再通过总线读写数据。
- 突发传输就是传输一个地址,后续连续多个读写数据操作,这样可以减少地址传输,提升传输性能。
总线突发传输的特性要求编程中的数据越连续,其读写性能越好。
3.3.2. 地址
为了简化总线传输的复杂度,总线传输过程中都是以对齐地址来进行访问的。32位CPU对齐32位地址,64位CPU对齐64位地址。以下以32位CPU为例。
3.3.2.1. 地址对齐
- 读int32的变量,一次传输即可以完成,效率高。
- 写int32的变量,一次传输即可以完成,效率高。
- 读char的变量,配合字节掩码,一次传输即可以完成,效率高。
- 写char的变量,配合字节掩码,一次传输即可以完成,效率高。
3.3.2.2. 地址未对齐
- 读int32的变量,需要将未对齐地址拆分为两个对齐地址,配合字节掩码进行传输,再合并数据,效率低。
- 写int32的变量,需要将未对齐地址拆分为两个对齐地址,并拆分数据,配合字节掩码进行传输,效率低。
- 读char的变量,总线发起对齐地址,再配置字节掩码,一次传输读取数据,后续处理数据,效率较低。
- 写char的变量,处理数据,总线发起对齐地址,再配置字节掩码,一次传输写入数据,效率较低。
3.3.2.3. 位域操作
总线处理地址不对齐,需要用到字节掩码(1个bit表示1个字节有效,这样可以节约字节掩码总线资源),无法精确到位操作。
- 位域读操作,总线读出对齐地址的数据,再移位完成位操作,效率较低。
- 位域写操作,总线先读出位域对齐地址的数据,再按位域要求修改个就位的数据,再将数据写回去。如果位域对应地址不对齐,还要拆分操作,效率会更低。
总结:位域操作,一般针对寄存器。如果其他场合需要用到位域,一定要综合考虑位域的便利性和性能代价。针对一些性能要求高的场景,变量或结构体中的成员都尽量地址对齐。
3.3.3. 地址边界
为了更方便地管理总线传输时的一主多从的情况,每个从模块都有独立的地址空间,不会受其他从模块影响。实现方式是总线的地址区间按页管理,AXI总线中每个页默认4KB,AHB总线中每个页默认1KB。每个Burst传输大小不能超出页大小。
这样,在AXI总线中,传输4K连续的数据,如果起始地址4KB对齐,那么只要1个Burst传输即可,传输一个地址,后面连续4K数据。如果4KB数非4KB地址对齐,那么就会跨4KB地址边界,这样4K数据必须拆分为2个Brust传输来完成。性能影响分析:4KB数据,256bit数据带宽,跨越地址边界,分成2个Burst传输,在配置Outstanding约束下(优化了多Burst传输间的间隔),4KB/256bit=128,那么其性能影响就接近1%,这个影响不小。如果跨地址边界传输的数据更小,那么影响更大。如果跨越地址边界的数据更大,那么其性能影响就会变小。
在AHB中,地址边界为1KB,相应的数据带宽为32/64bit,在传输1KB跨越边界的数据,其性能影响也是接近1%。
所以,在MCU设计中使用ABH总线时,固件高频访问的内存,建议按1KB地址对齐;在MCU设计中使用AXI总线时,固件高频访问的内存,建议按4KB地址对齐。
**3.4. ** SIMD指令
SIMD(Single Instruction, Multiple Data,单指令多数据)指令是一种并行计算技术,它允许在同一时间执行多个相同操作的指令,但这些指令作用于不同的数据元素。SIMD指令广泛应用于各种领域,如图像处理、音视频编解码、数值计算等,以提高程序的性能和效率。针对低功耗的嵌入式内核,一般在设计之初会关闭SIMD功能。如果设计的CPU要兼容Linux内核,一般会打开SIMD指令功能。
3.5. 硬件加速模块
IC因为其并行的架构,可以提供非常好的计算能力。因此,一些软件中影响性能的软件算法,可能会被设计到硬件中。如内存拷贝,bit查找,除法(Cortex-M系列很多会关闭浮点计算功能)等。详细参考MCU技术文档。
华为手机在CPU性能不如高通的情况下,为什么综合性能不输高通平台。比如后台软件唤醒测试。现在的App内存消耗五六百兆很普通,为什么8GB内存可能在后台暂存几十个App呢?这里就用到内存压缩技术。后台的大部分App的内存都是压缩存储的,这样就可以在后台暂存更多App的内存,唤醒的时候再解压出来即可。高通平台的手机是利用软件实现压缩和解压的,而麒麟CPU已经内置LZ4解压缩算法,这样华为手机在CPU性能稍差的情况下,依然能够在后台唤醒App上和高通平台手机相当。苹果手机内存一直小于安卓手机,但是其后台暂存App的能力完全不输内存更大的安卓手机。这是因为苹果手机CPU更强大,其内置了比lz4更复杂强大的解压缩算法。
针对自研CPU的厂商,利用好内置加速模块,可以大大提升代码性能。
版权归原作者 -飞鹤- 所有, 如有侵权,请联系我们删除。