
Stable-Diffusion-Webui 是一个基于Gradio库的Stable Diffusion的浏览器界面,可以说是AI绘画集合体,支持目前主流的开源AI绘画模型,例如 NovelAi/Stable Diffusion,有了它,我们就可以很方便地配置和生成AI绘画作品,并且进行各种精细地配置。
一、搭建指南
1、安装Python 3.10.6和git
2、下载stable-diffusion-webui源码
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
3、将模型文件放在项目根目录下的models/Stable-diffusion文件夹里
4、运行 webui-user.bat 启动
5、在浏览器中输入 http://127.0.0.1:7860 打开SD页面

launch.py可自动运行模型,运行时可以使用一些命令参数,比如:
python launch.py --opt-split-attention --ckpt model.ckpt
命令行参数和优化:
命令行参数解释
--share
online运行,也就是public address
--listen
使服务器侦听网络连接。这将允许本地网络上的计算机访问UI。
--port
更改端口,默认为端口7860。
--xformers
使用xformers库。极大地改善了内存消耗和速度。Windows 版本安装由C43H66N12O12S2 维护的二进制文件
--force-enable-xformers
无论程序是否认为您可以运行它,都启用 xformers。不要报告你运行它的错误。
--opt-split-attention
Cross attention layer optimization 优化显着减少了内存使用,几乎没有成本(一些报告改进了性能)。黑魔法。默认情况下torch.cuda,包括 NVidia 和 AMD 卡。
--disable-opt-split-attention
禁用上面的优化
--opt-split-attention-v1
使用上述优化的旧版本,它不会占用大量内存(它将使用更少的 VRAM,但会限制您可以制作的最大图片大小)。
--medvram
通过将稳定扩散模型分为三部分,使其消耗更少的VRAM,即cond(用于将文本转换为数字表示)、first_stage(用于将图片转换为潜在空间并返回)和unet(用于潜在空间的实际去噪),并使其始终只有一个在VRAM中,将其他部分发送到CPU RAM。降低性能,但只会降低一点-除非启用实时预览。
--lowvram
对上面更彻底的优化,将 unet 拆分成多个模块,VRAM 中只保留一个模块,破坏性能
*do-not-batch-cond-uncond
防止在采样过程中对正面和负面提示进行批处理,这基本上可以让您以 0.5 批量大小运行,从而节省大量内存。降低性能。不是命令行选项,而是使用–medvramor 隐式启用的优化–lowvram。
--always-batch-cond-uncond
禁用上述优化。只有与–medvram或–lowvram一起使用才有意义
--opt-channelslast
更改 torch 内存类型,以稳定扩散到最后一个通道,效果没有仔细研究。
完整的命令行参数详见:
Command Line Arguments and Settings · AUTOMATIC1111/stable-diffusion-webui Wiki · GitHubStable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Command-Line-Arguments-and-Settings
二、主要功能
WebUI分为以下几个模块:
- txt2img --- 标准的文字生成图像
- img2img --- 根据图像成文范本、结合文字生成图像
- Extras --- 优化(清晰、扩展)图像
- PNG Info --- 图像基本信息
- Checkpoint Merger --- 模型合并
- Train --- 训练模型
- Settings --- 默认参数修改
txt2img(文转图)
prompt:对于图像进行描述,有内容风格等信息进行描述。
Negative prompt:提供给模型我不想要什么样的风格
Sampling Steps:diffusion model 生成图片的迭代步数,每多一次迭代都会给 AI 更多的机会去比对 prompt 和当前结果,去调整图片。更高的步数需要花费更多的计算时间,但不一定意味着更好的结果。当然迭代步数不足(少于 50)肯定会降低结果的图像质量;
Sampling method:扩散去噪算法的采样模式,不同的采样模式会带来不一样的效果
Width、Height:图像长宽,可以通过send to extras 进行扩大,所以这里不建议设置太大[显存小的特别注意];
Restore faces:优化面部,绘制面部图像特别注意
Tiling:生成一个可以平铺的图像
Highres.fix:高清修复,使用两个步骤的过程进行生成,以较小的分辨率创建图像,然后在不改变构图的情况下改进其中的细节,选择该部分会有两个新的参数 Scale、latent 在潜空间中对图像进行缩放。另一种方法是从潜在的表象中产生完整的图像,将其升级,然后将其移回潜在的空间。Denoising strength 决定算法对图像内容的保留程度。为0时,什么都不会改变,而为1时,你会得到一个不相关的图像;
Batch count、 Batch size:都是生成几张图,前者计算时间长,后者需要显存大;
CFG Scale:分类器自由引导尺度——图像与提示符的一致程度——越低的值产生越有创意的结果;
Seed:种子,只要种子值一样,参数一致、模型一样图像就能重新
img2img(图转图)
Just resize、 Crop and resize、 Resize and fill:这三种模式保证图输出效果,因为下面会有新的尺寸,分别表示只需调整大小、裁剪和调整大小、调整大小和填充。
Denoising strength:与原图一致性的程度,一般大于0.7出来的都是新效果,小于0.3基本就会原图缝缝补补;
Extras(更多)
对图片进行优化缩放
GFPGAN visibility:对图像清晰度进行优化
常用的Highres.fix(高清放大)算法:
- Latent:是一种基于 VAE 模型的图像增强算法,通过将原始图像编码成潜在向量,并对其进行随机采样和重构,从而增强图像的质量、对比度和清晰度。一般情况下,这个算法就能得到不错的效果,和4x-UltraSharp、R-ESRGAN等相比,显存消耗比较小,但效果不是最优。
- Lanczos:将对称矩阵通过正交相似变换变成对称三对角矩阵的算法(鸡肋,通常不用)。
- ESRGAN:Enhanced Super-Resolution Generative Adversarial Networks (增强超分生成对抗网络)是对SRGAN关键部分网络结构、对抗损失、感知损失的增强。从这里开始就不是单纯的图像算法,进入人工智能的领域了。实测确实增加了很多看上去很真实的纹理,但是有时又会把一张图片弄得全是锯齿或怪异的纹理。可能对待处理的图片类型有要求。
- 4x-UltraSharp:基于ESRGAN做了优化模型,更适合常见的图片格式。真人模型最佳选择。
- ESRGAN 4x(Real ESRGAN):完全使用纯合成数据去尽量贴近真实数据,然后去对现实生活中数据进行超分的一个方法。这个算法来自于腾讯贡献。
- **R-ESRGAN 4x+**:基于Real ESRGAN的优化模型,针对照片效果不错。
- R-ESRGAN 4x+ Anime6B:基于Real ESRGAN的优化模型,二次元最佳,如果你的模型是动漫类的,该选项是最佳选择。
- R-ESRGAN General 4xV3:基于Real ESRGAN的优化模型,体积小,计算快,效果差。
- SwinIR_4x:使用Swin Transformer思想,采用一个长距离连接,将低频信息直接传输给重建模块,可以帮助深度特征提取模块专注于高频信息,稳定训练。
- LDSR:Latent Diffusion Super Resolution(潜在扩散超分辨率模型)是Stable Diffusion最基础的算法模型,但速度比较慢。
三、在Intel显卡的主机上安装
Stable-Diffusion-WebUI现在可以在Intel的CPU和GPU(集成和独立图形)等硬件上运行,并配有Intel分发OpenVINO工具包。
1、安装OpenVINO
带有 torch.compile 支持的 OpenVINO 现在可以在 OpenVINO 预发布包中预览。使用命令安装最新的预发布软件包
pip install --pre openvino
2、下载stable-diffusion-webui源码并安装
git clone https://github.com/openvinotoolkit/stable-diffusion-webui.git
cd stable-diffusion-webui
first-time-runner.bat
torch-install.bat
3、将模型文件放在项目根目录下的models/Stable-diffusion文件夹里
4、运行 webui-user.bat 启动
5、开启openvino加速
在script下拉菜单选择“Accelerate with OpenVINO”
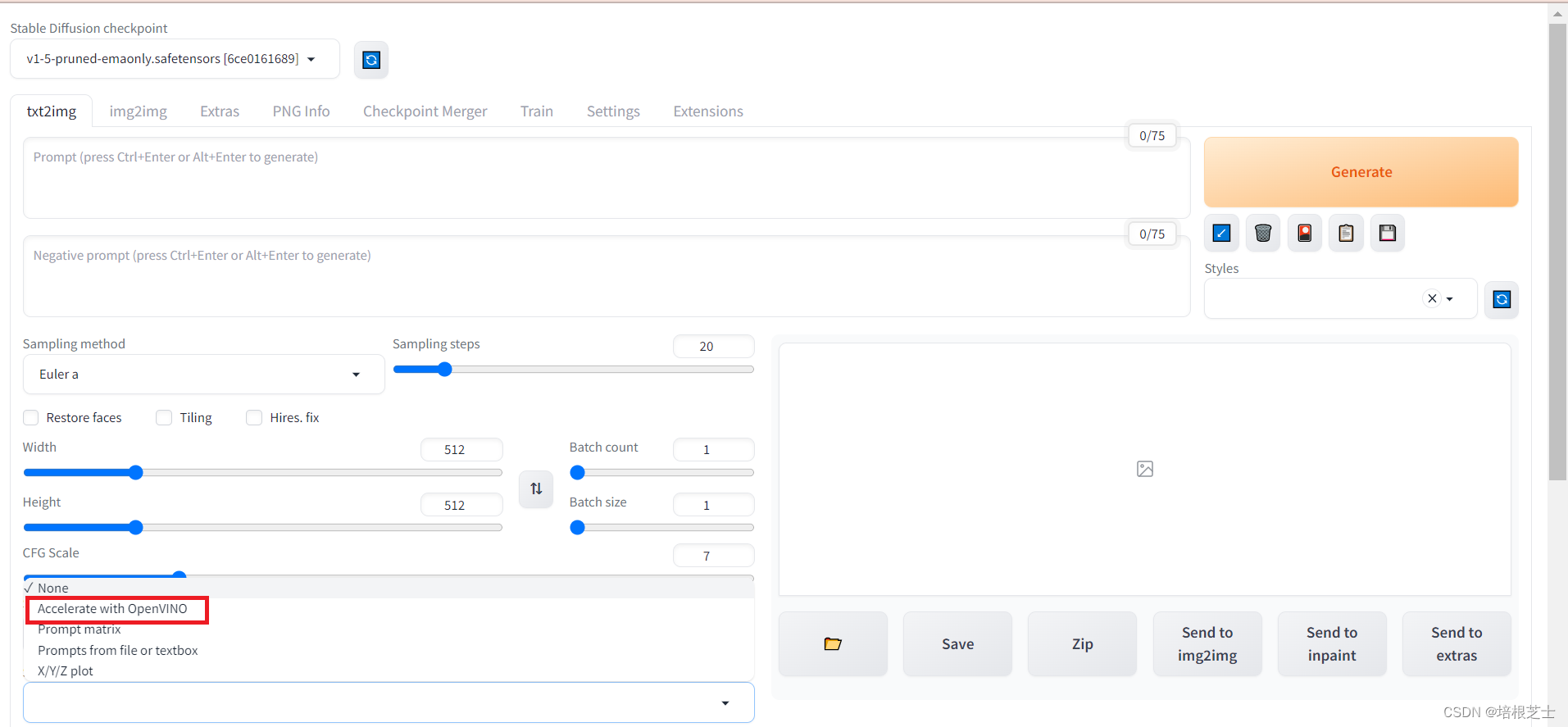
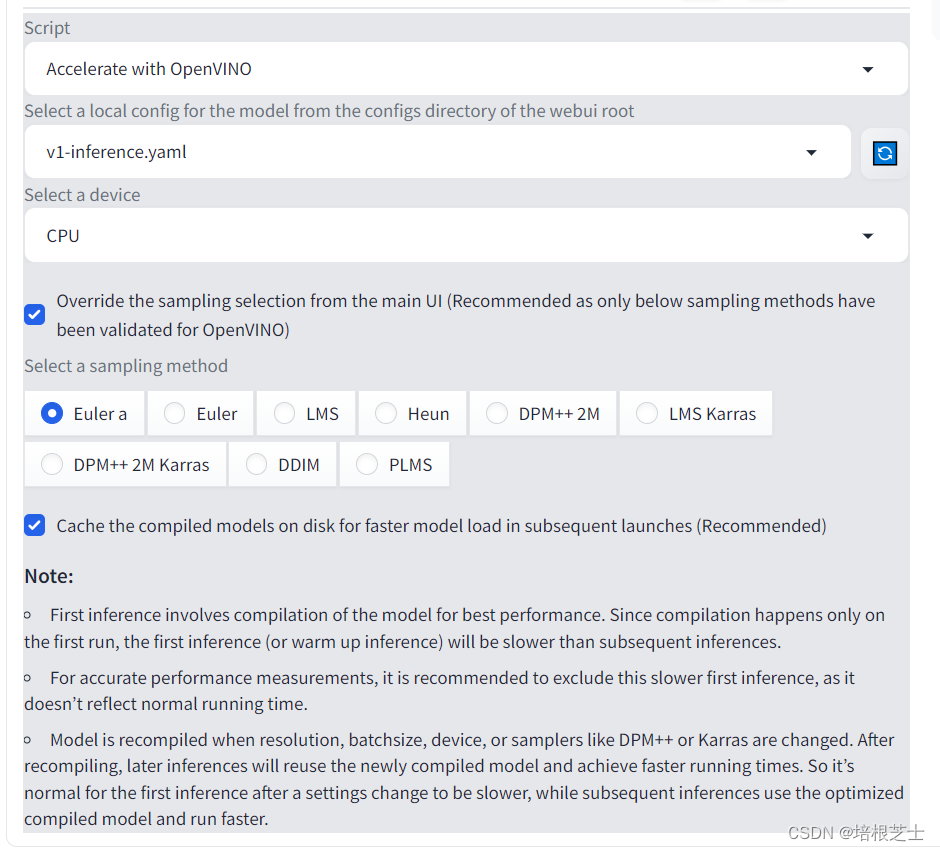
使用OpenVINO自定义脚本,可以配置以下选项:
- 配置文件:模型检查点需要与相应的配置文件相关联。通常,配置文件由diffusers库自动下载。但是,如果模型检查点的起源不同或是一个自定义检查点,则相应的配置文件(以“yaml”格式)需要放置在WebUI根目录的“configs”目录中。
- 设备:使用OpenVINO,可以在英特尔CPU或GPU上加速Stable-Diffusion-WebUI。所有支持OpenVINO的设备都列在下拉列表中。用户可以选择他们选择的加速设备。当用户选择新设备时,建议从性能测量中排除第一次预热迭代,因为模型会为目标硬件重新编译。
- 采样方法:OpenVINO加速使用"Hugging Face Diffusers"库。我们使用来自扩散器的等效采样方法,并验证了一些流行的采样方法。推荐勾选“Override the sampling selection from the main UI”,尚未支持主UI的一些采样方法,将回退到“Euler a”采样方法。
- 缓存:OpenVINO支持缓存编译的模型,以便后续使用同一模型。这大大减少了热身时间。建议启用此设置。编译的模型保存在WebUI根目录的“缓存”目录中。用户可以删除不再需要的文件以节省磁盘空间。我们不会自动删除文件,以避免删除用户稍后可能使用的文件。
版权归原作者 培根芝士 所有, 如有侵权,请联系我们删除。