
一、树形查询的定义
树形查询是一种用于查询具有父子关系的数据的方法。该查询通常用于查询组织结构、分类目录等具有层级结构的数据。
二、树形查询的组成
树形查询是由查询语句和查询结果组成的。查询语句通常使用递归查询或连接查询实现,以查询具有父子关系的数据。查询结果是一个树形结构,每个节点表示一个数据项,节点之间通过父子关系连接。递归查询使用WITH RECURSIVE语句,而连接查询使用CONNECT BY语句。
2.1递归查询的语法:
WITH RECURSIVE cte (column1, column2, ...) AS (
SELECT column1, column2, ...
FROM table
WHERE condition
UNION ALL
SELECT column1, column2, ...
FROM table
JOIN cte ON cte.parent_id = table.id
)
SELECT column1, column2, ...
FROM cte;
cte是递归查询的公共表达式,column1、column2等为查询结果列,table为查询的表,condition为查询条件,parent_id为父节点ID列,id为节点ID列。
2.1.1解释递归查询
递归查询是指在数据库中查询数据时,通过嵌套查询来实现多层级查询的过程。递归查询通常用于查询树形结构或层次结构的数据。递归查询是Oracle中树形查询的一种实现方式,它可以查询具有父子关系的数据。
递归查询的作用是可以方便地查询多层级数据,避免了多次查询的麻烦。例如,如果要查询一个公司的所有部门以及部门下的所有员工,递归查询可以轻松实现这一需求。
递归查询的过程可以通过使用WITH RECURSIVE语句来实现,通过递归地查询子节点来构建树形结构。在这个语句中,可以定义递归查询的初始条件和递归条件,并在语句中使用递归查询来获取结果,但是需要使用CONNECT BY和START WITH语句来实现递归查询。
2.1.2递归查询的实例
假设有一个表employee,其中包含员工的编号(id)、姓名(name)和上级员工的编号(manager_id)。
例题1.查询所有员工的姓名和其直接和间接上级的姓名。
首先,我们需要定义一个公共表达式cte,用于递归地查询员工的上级信息。查询语句如下:
WITH RECURSIVE cte (id, name, manager_id, level) AS (
SELECT id, name, manager_id, 0
FROM employee
WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name, e.manager_id, c.level + 1
FROM employee e
JOIN cte c ON c.id = e.manager_id
)
SELECT id, name, manager_id, level
FROM cte
ORDER BY level, id;
在公共表达式cte中,首先查询没有上级的员工,即manager_id为NULL的员工,并将它们的信息作为初始结果集。然后,递归地查询每个员工的上级信息,直到查询到没有上级的员工为止。在递归查询时,使用JOIN连接公共表达式cte和表employee,通过c.id = e.manager_id来连接每个员工和它的上级。在查询结果中,还添加了一个level列,用于表示每个员工的层级。
最后,在查询结果中选择id、name、manager_id和level列,并按照level和id进行排序。这样,就可以得到所有员工及其直接和间接上级的信息,并按照层级和编号排序。
注意:
在递归查询中,必须指定递归结束的条件。否则,查询语句将会进入死循环,导致查询失败。在例题1中,使用manager_id IS NULL作为递归结束的条件,表示查询到没有上级的员工时递归结束。
例题2.如何查询一个员工的所有下属:
WITH RECURSIVE subordinates AS (
SELECT employee_id, manager_id, employee_name
FROM employees
WHERE manager_id = 1
UNION ALL
SELECT e.employee_id, e.manager_id, e.employee_name
FROM employees e
JOIN subordinates s ON e.manager_id = s.employee_id
)
SELECT * FROM subordinates;
在示例中,WITH RECURSIVE子句定义了一个名为subordinates的递归查询,并在初始条件中选择了manager_id等于1的员工。然后,在递归条件中,使用JOIN和ON语句来获取下属的详细信息。最后,通过SELECT语句来查询结果。
备注:
WITH RECURSIVE子句在Oracle11g中是不可以使用的。WITH RECURSIVE子句是SQL:1999标准中引入的语法,但是在Oracle 11g中并不支持这个语法。如果需要实现递归查询,可以使用Oracle的CONNECT BY语法。CONNECT BY语法可以实现树形结构数据的查询,但是相比于WITH RECURSIVE语法,连接查询的效率较低且语法较为复杂。
在Oracle 12c版本中,WITH RECURSIVE子句被引入,称为"Recursive Subquery Factoring",可以使用这个语法来实现递归查询。如果需要使用WITH RECURSIVE来实现递归查询,建议升级到Oracle 12c及以上版本。
2.2连接查询的语法:
SELECT column1, column2, ...
FROM table
START WITH condition
CONNECT BY PRIOR id = parent_id;
--常用格式
SELECT [LEVEL,]列1,列2...
FROM 表
[WHERE 条件]
[START WITH 条件 ] --从谁开始,不写默认从每个人出发
CONNECT BY PRIOR 子列=父列 --查下级 --prior(先前的) 所以很好理解谁在前就查谁
父列=儿列 --查上级
[ORDER SIBLINGS BY 列] --同一级别的排序;siblings(兄弟姐妹同胞)
table为查询的表,condition为查询条件,id为节点ID列,parent_id为父节点ID列,PRIOR用于表示父子关系。
四个需要理解的点:
LEVEL 代表节点的深度
函数:sys_connect_by_path(列,'分隔符')--合并层级
比如:把一个根节点下所有的子节点通过某个分隔符进行划分,通常是'/' --/张三/张小三/张思睿connect_by_root 列--返回根节点
connect_by_isleaf --判断是否是叶子节点
是叶子节点,返回1,不是返回0
因此树形查询通常是由根节点、父节点、子节点、叶子节点组合;
根节点:当前节点之上没有节点的节点。(除了根节点的都是子节点)
叶子节点:当前节点之下没节点的节点。(除了叶子节点的都是父节点)
父节点:当前节点之下还有节点的节点。
子节点:当前节点之上还是节点的节点。
2.2.1解释连接查询
连接查询(Join)是在关系型数据库中常用的一种查询方式,它可以将两个或多个表中的数据通过某些条件进行关联,从而得到更全面、更有价值的查询结果。连接查询可以帮助用户在多个表中查找相关的数据,从而提高查询的效率和准确性。
连接查询可以使用JOIN语句来实现。常用的连接查询包括内连接、左连接、右连接和全连接。连接查询可以使用如下的语法:
SELECT column1, column2, ...
FROM table1
[JOIN type] table2
ON table1.column = table2.column;
JOIN type是连接类型,可以是INNER JOIN(内连接)、LEFT JOIN(左连接)、RIGHT JOIN(右连接)或FULL OUTER JOIN(全外连接)之一。ON是连接条件,用于指定连接两个表的条件。
2.2.2连接查询的实例
例题1查询出所有部门及其下属员工的信息,并以树形结构的形式展示出来
假设有两张表,一张为部门表(DEPARTMENT),另一张为员工表(EMPLOYEE)
CREATE TABLE departments (
dept_id INT PRIMARY KEY,
dept_name VARCHAR(50),
parent_dept_id INT
);
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50),
dept_id INT
);
departments表中的parent_dept_id字段表示该部门的上级部门编号,如果该部门是最高级部门,则parent_dept_id为NULL;employees表中的dept_id字段表示该员工所属的部门编号。
使用CONNECT BY子句来实现树形查询,使用INNER JOIN来连接departments表和employees表,具体的SQL语句如下:
SELECT LPAD(' ', 4 * (LEVEL - 1)) || d.dept_name dept_name,
e.emp_name
FROM departments d
INNER JOIN employees e
ON d.dept_id = e.dept_id
START WITH d.parent_dept_id IS NULL
CONNECT BY PRIOR d.dept_id = d.parent_dept_id;
使用START WITH指定根节点的条件,即parent_dept_id为NULL;使用CONNECT BY指定连接条件,即当前节点的dept_id等于上级节点的parent_dept_id。在查询结果中,用LPAD函数来实现缩进,使得结果以树形结构的形式展示出来。
例题2已知员工表emp,现查询所有没有下属的员工信息
select *
from (
select e.*,connect_by_isleaf 节点
from emp e
START WITH mgr is null
CONNECT BY PRIOR EMPNO=MGR)
where 节点=1;
对这个SQL语句进行优化,使用INNER JOIN代替WHERE子句过滤,可以提高查询效率。
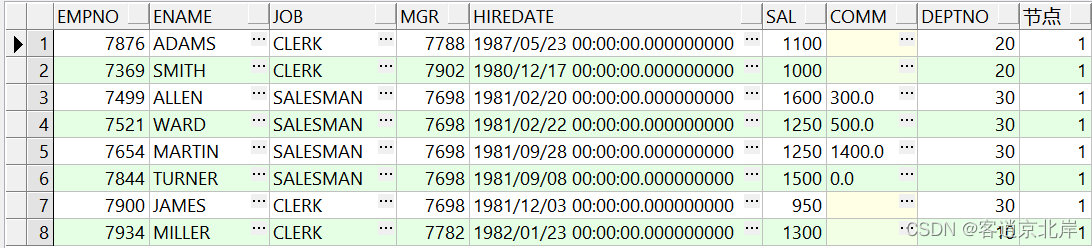
SELECT e.*
FROM emp e
INNER JOIN (
SELECT EMPNO, CONNECT_BY_ISLEAF AS 节点
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR EMPNO = MGR
) t ON e.EMPNO = t.EMPNO
WHERE t.节点 = 1;
最后执行结果如下:
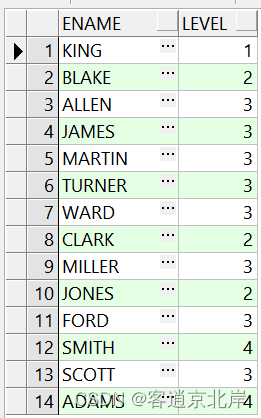
例题3查询emp表的层级关系
SELECT ename, level
FROM emp
START WITH MGR IS NULL
CONNECT BY PRIOR EMPNO = MGR
ORDER SIBLINGS BY ename;
执行结果如下:
例题4.查询SCOTT的上级显示节点深度,显示level和缩进后的姓名
SELECT ename,level,lpad(ename,length(ename)+level*3,' ')
FROM emp
START WITH empno = (SELECT mgr FROM emp WHERE ename = 'SCOTT')
CONNECT BY PRIOR mgr=empno;
总结:
无论是递归查询还是连接查询,都可以使用其他查询语句进行过滤和排序。
三、树形查询优缺点
树形查询在查询具有层级结构的数据时,可以方便地获取树形结构的查询结果,便于展示和分析数据。例如,在查询组织结构时,可以使用树形查询获取每个部门的子部门和员工信息。总结下树形查询的优缺点:
3.1优点
- 可以清晰地显示数据之间的层级关系,使得数据的结构更加清晰明了。
- 可以方便地进行数据的分类和归纳,从而更好地进行数据分析和挖掘。
- 可以快速地定位数据,提高数据的查询效率和准确性。
- 可以方便地进行数据的导航和展示,使得数据的呈现更加美观和直观。
3.2缺点
- 树形查询的数据结构比较复杂,需要占用较多的存储空间。
- 树形查询的查询效率受到树形结构的影响,可能存在较大的查询延迟。
- 树形查询的数据结构比较固定,不太适合动态修改和更新。
因此在实际应用中需要根据具体情况进行选择和权衡。
四、树形查询中的函数
常用的树形查询函数包括CONNECT BY PRIOR、LEVEL和SYS_CONNECT_BY_PATH等,下面分别进行说明:
4.1 CONNECT BY PRIOR:
该函数用于建立父子节点之间的关系,常用于同一级别的排序,语法格式为:
SELECT ... FROM ... WHERE PRIOR ...
其中PRIOR是指父节点,可以用于建立多层次的树形结构。例如:
SELECT empno, ename, mgr
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr;
该语句表示查询emp表中的员工编号、员工姓名和领导编号,并以领导编号为父节点建立树形结构。
4.2 LEVEL:
该函数用于表示当前节点的层次,语法格式为:
SELECT ... FROM ... WHERE LEVEL ...
其中LEVEL表示当前节点的层次,可以用于查询树形结构中的深度。例如:
SELECT empno, ename, LEVEL
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr;
该语句表示查询emp表中的员工编号、员工姓名和员工所在的层次,即员工在树形结构中的深度。
4.3SYS_CONNECT_BY_PATH:
该函数用于表示当前节点到根节点的路径,常用于合并层级,语法格式为:
SELECT ... FROM ... WHERE SYS_CONNECT_BY_PATH ...
其中SYS_CONNECT_BY_PATH表示当前节点到根节点的路径,可以用于查询树形结构中的路径。例如:
SELECT empno, ename, SYS_CONNECT_BY_PATH(ename, '/') AS path
FROM emp
START WITH mgr IS NULL
CONNECT BY PRIOR empno = mgr;
该语句表示查询emp表中的员工编号、员工姓名和员工到根节点的路径,即员工在树形结构中的路径。
总结:
树形查询函数可以用于建立父子节点之间的关系、查询节点的层次和路径等,可以方便地进行树形结构的查询和分析。
五、伪列
5.1伪列的定义
Oracle中的伪列是指在SELECT语句中使用的特殊列,它们不是表中的实际列(即它不实际存在于表中),因此不能删除和修改伪列,但可以在SELECT语句中使用。伪列是由Oracle自动生成的,系统提供的一些特殊的列,用于提供一些特殊的功能和效果。这些伪列可以用于在查询结果中提供一些额外的信息,例如行号、层次结构、当前用户等。
5.2常用伪列及说明
5.2.1ROWNUM:
该伪列用于返回查询结果中的行号,从1开始递增。例如:
SELECT ROWNUM, ename FROM emp;
执行结果如下:

5.2.2ROWID:
该伪列用于返回行的物理地址,可以用于在UPDATE和DELETE语句中定位行。例如:
SELECT ROWID, ename FROM emp;
执行结果如下:
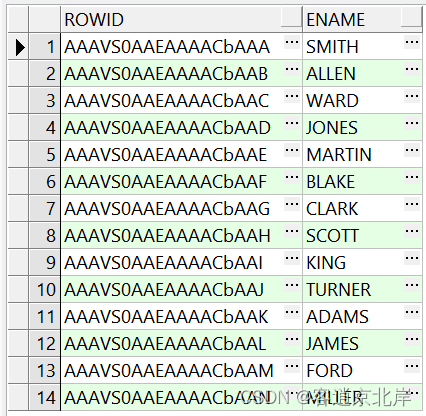
5.2.3LEVEL:
该伪列用于返回查询结果中每行所处的层次级别,通常在树形结构查询中使用。例如:
SELECT ename, LEVEL
FROM emp
CONNECT BY PRIOR empno = mgr;
执行结果如下:
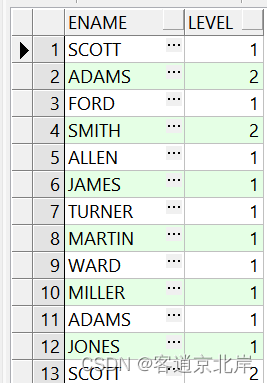
5.2.4CONNECT_BY_ISLEAF:
connect_by_isleaf是Oracle中的一个伪列,它用于判断当前行是否为树结构中的叶子节点。在使用CONNECT BY查询时,connect_by_isleaf可以用于确定当前行是否为叶子节点,返回1或0,并根据需要执行相应的操作。例如:查询将获取“emp”表中员工的树形结构,并在每行中显示该员工的姓名、所在部门的名称和是否为叶子节点
SELECT emp.ename, dept.dname, connect_by_isleaf AS is_leaf
FROM emp
JOIN dept ON emp.deptno = dept.deptno
CONNECT BY PRIOR emp.mgr = emp.empno;
执行结果如下:

在该查询中,connect_by_isleaf将返回1或0,表示当前行是否为叶子节点。
5.2.5CONNECT_BY_ROOT:
connect_by_root也是Oracle中一种特殊的伪列,用于在树形结构查询中返回根节点的值。在使用CONNECT BY查询时,connect_by_root可以用于引用根节点的值,以便在查询结果中显示。例如:查询emp表中员工的树形结构,并在每行中显示该员工的姓名以及其所在部门的名称和根节点的名称
SELECT emp.ename, dept.dname, connect_by_root dept.dname AS root_dept_name
FROM emp
JOIN dept ON emp.deptno = dept.deptno
CONNECT BY PRIOR emp.mgr = emp.empno;
执行结果如下:

在该查询中,connect_by_root dept.dname将返回当前查询行的根节点部门名称。
5.2.6SYSDATE:
该伪列用于返回当前系统日期和时间。例如:
SELECT SYSDATE FROM dual;
执行结果如下:

5.2.7USER:
该伪列用于返回当前用户的用户名。例如:
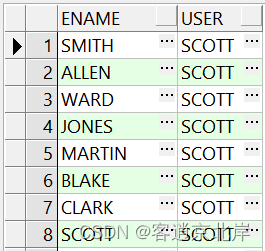
SELECT ename, USER FROM emp;
执行结果如下:
5.3使用伪列的好坏:
使用伪列可以帮助我们更好地理解查询结果,并进行更加高效的数据处理,可以获得一些特殊的功能和效果,但也有一些坏处。
5.3.1好处:
- 可以获取一些特殊的信息,如ROWNUM伪列可以用于获取行号,LEVEL伪列可以用于递归查询等。
- 可以在SELECT语句中使用伪列进行计算和操作,如ROWNUM伪列可以用于分页查询。
- 可以在SELECT语句中使用伪列进行分组和排序,如ROLLUP和CUBE操作中使用的GROUPING_ID伪列。
5.3.2坏处:
- 伪列不能用于UPDATE和INSERT操作,因为它们不实际存在于表中。
- 在大数据量的查询中,使用伪列可能会影响查询性能,因为它们需要额外的计算和操作。
- 在使用伪列时,需要注意不同的伪列的语法和用法,以避免出现错误和不必要的麻烦。
注意:
注意伪列的使用方法和注意事项,避免出现问题和影响查询性能。
六、总结level用法
6.1level使用场景
level表示的是查询结果中每一行所处的层级,必须从1开始,并且是连续的 。它可以在多个方面表示不同的含义,例如:
- 在递归查询中,level表示当前行在递归树中的深度。
- 在连接查询中,level表示连接路径的深度。
- 在分层聚合查询中,level表示当前行所处的分层级别。
- 在层次结构查询中,level表示当前行在层次结构中的层级。
LEVEL用于分层聚合查询中,表示当前行所处的分层级别。通过使用LEVEL可以实现对分层聚合数据的查询,例如查询某个分层级别的汇总数据。
WITH t (id, level_id, amount) AS ( SELECT 1, 1, 100 FROM dual UNION ALL SELECT 2, 1, 200 FROM dual UNION ALL SELECT 3, 2, 150 FROM dual UNION ALL SELECT 4, 2, 250 FROM dual UNION ALL SELECT 5, 3, 180 FROM dual UNION ALL SELECT 6, 3, 220 FROM dual ) SELECT level_id, SUM(amount) FROM t CONNECT BY PRIOR id = level_id START WITH level_id = 1 GROUP BY level_id, LEVEL;语句使用了LEVEL伪列,通过CONNECT BY和PRIOR关键字指定了分层聚合的条件,通过START WITH关键字指定了分层聚合的起始级别,输出结果为每个分层级别的ID和汇总金额。
level在树形查询中不仅能够返回节点深度,还可以控制显示格式,比如:控制缩进;
同时level也具有生成多条记录和一行变多行的用法!!!
6.2生成多条记录
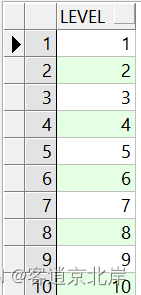
select level
from dual
connect by level<=100;
执行结果部分如下:
例题1查询1-19所有的整数,100以内所有的奇数
--1-19所有的整数
select level
from dual
connect by level<=19;
--100以内所有的奇数
select level*2-1
from dual
connect by level<=100/2;
--或
select level
from dual
where mod(level,2)=1
connect by level<=100;
例题2查询本月所有的周日,今年所有的星期五
--本月所有的周日
select trunc(sysdate,'mm')+level-1
from dual
where to_char(trunc(sysdate,'mm')+level-1,'d')=1
connect by level<=to_char(last_day(sysdate),'dd');
--今年所有的星期五
select trunc(sysdate,'yyyy')+level-1
from dual
where to_char(trunc(sysdate,'yyyy')+level-1,'d')=6
connect by level<=to_char(to_date(to_char(sysdate,'yyyy')||'-12-31','yyyy-mm-dd'),'ddd');
例题3编写sql查询出下面图形
select rpad('*',level*2-1,' *')
from dual
connect by level<=5;
*
* *
* * *
select rpad(lpad('*',6-level+1,' '),6+level-1,' *')
from dual
connect by level<=6;
备注:
图形查询编写sql可以使用循环完成更方便快捷!!!
6.3一行变多行
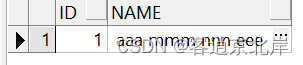
创建表abc,语句如下;
create table abc(a varchar2(20));
insert into abc(id,name) values(1,' aaa mmm nnn eee');
commit;
select * from abc;
原表执行结果如下:
对name列进行分行,每三位换一行
select substr(name,4*level-3,3)
from abc
connect by level<=length(replace(name,','))/3;
执行结果如下:

①当一行数据中有分隔符,要求每个部分有n位时,则用下面语句划分:
select substr(str,(n+1)*level-n,n)
from 表
connect by level<=length(replace(str,'分隔符'))/n;
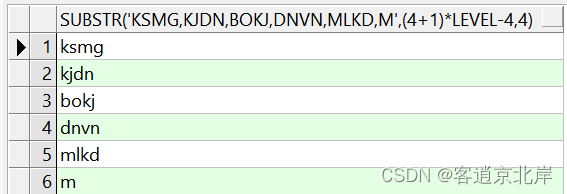
比如:把‘ksmg,kjdn,bokj,dnvn,mlkd,m ’每四位换一行显示
select substr('ksmg,kjdn,bokj,dnvn,mlkd,m',(4+1)*level-4,4)
from dual
connect by level<=ceil(length(replace('ksmg,kjdn,bokj,dnvn,mlkd,m',','))/4);
执行结果如下:
②当一行数据中没有分隔符,要求每个部分有n位时,则用下面语句划分:
select substr(str,n*level-(n-1),n)
from 表
connect by level<=ceil(length(str)/n);
比如:把'ksmgkjdnbokjdnvnmlkdmn'每三位换一行显示
select substr('ksmgkjdnbokjdnvnmlkdmn',3*level-(3-1),3)
from dual
connect by level<=ceil(length('ksmgkjdnbokjdnvnmlkdmn')/3);
执行结果如下:

总结:
LEVEL在Oracle11g中主要用于处理层次结构数据,可以实现递归查询、分层聚合查询等功能。
版权归原作者 龙西 所有, 如有侵权,请联系我们删除。