
不适用的场景
首先副本表无法实现下图的设计,这是因为clickhouse中的副本是一张实实在在的物理表,而你不能在一台clickhouse服务器上创建两个相同的表
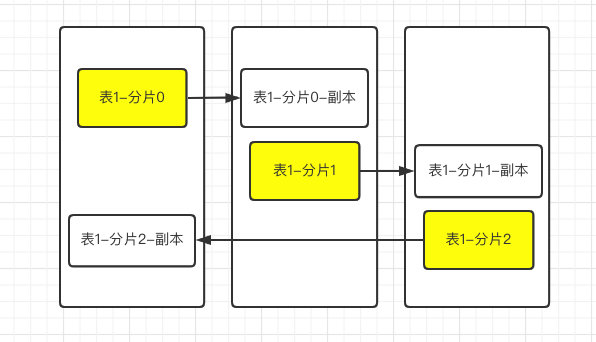
我们可以尝试一下,三分片一副本,按照上图中的逻辑配置,如下配置:
<!-- 三分片1副本 --><bdp_3S_1R><shard><replica><host>bdp-dc-001</host><port>9300</port></replica><replica><host>bdp-dc-002</host><port>9300</port></replica></shard><shard><replica><host>bdp-dc-002</host><port>9300</port></replica><replica><host>bdp-dc-003</host><port>9300</port></replica></shard><shard><replica><host>bdp-dc-003</host><port>9300</port></replica><replica><host>bdp-dc-001</host><port>9300</port></replica></shard></bdp_3S_1R>
不出意外重启后创建表报错
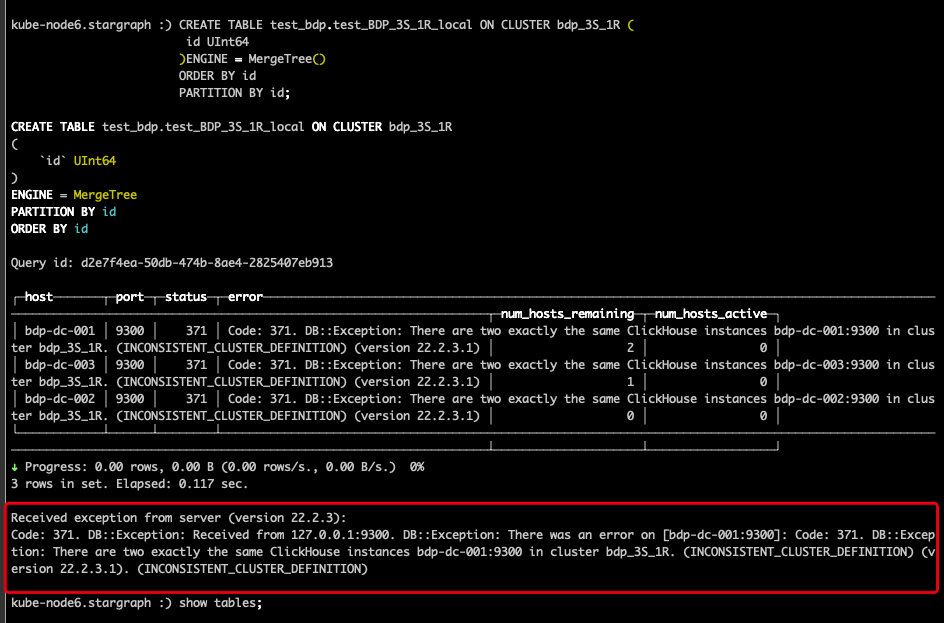
翻译:DB异常:在集群bdp_3S_1R中有两个完全相同的ClickHouse实例bdp-dc-001:9300。(不一致的集群定义)(版本22.2.3.1)
对于多个分片多个副本只能如下图:下图为两个分片,一个副本,最少需要四台clickhouse节点!
原理

副本表ReplicatedMergeTree完全依赖zookeeper,表的创建和写入数据都依赖zookeeper做通知,而副本表之所以副本就是在于创建表ReplicatedMergeTree后面跟的zookeeper的路径,如果两张表zookeeper路径不一致,则完全不会副本,故副本表中zookeeper路径是关键。
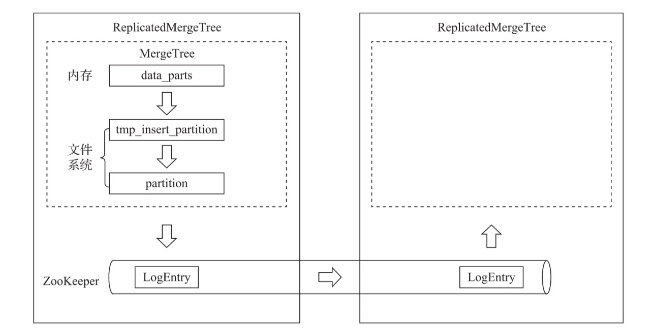
clickhouse中采用先建临时分区文件,最终完成后才会设置为正式分区文件
注意:副本在同步的时候会有延迟,因为主分区表会先将分区数据保存好再发送请求到zookeeper,此时副本表才会监听到消息从而向主表拉取数据,故会存在副本数据延迟。
实操
假设我们在bdp-dc-001、bdp-dc-002 两台服务器上创建副本表,希望实现任意一台服务器上新增数据,另一台服务器都能查看到相同数据副本,此副本表的创建有以下四种方式:
1、原生创建-不指定集群名,不使用宏变量
# bdp-dc-001CREATETABLE test_bdp.replicated_sales_0
(`id` String,`price` Float64,`create_time`DateTime)ENGINE= ReplicatedMergeTree('/clickhouse/tables/0/replicated_sales_0','bdp-dc-001')PARTITIONBY toYYYYMM(create_time)ORDERBY id
# bdp-dc-002CREATETABLE test_bdp.replicated_sales_0
(`id` String,`price` Float64,`create_time`DateTime)ENGINE= ReplicatedMergeTree('/clickhouse/tables/0/replicated_sales_0','bdp-dc-002')PARTITIONBY toYYYYMM(create_time)ORDERBY id
# bdp-dc-001插入数据insertinto replicated_sales_0 values('1',1.0,'2020-01-01')
结果:

2、通过宏变量创建表
宏变量的使用可以让副本表在创建的时候轻松很多,先修改config.xml文件:
<!-- 001宏变量 --><macros><shard>01</shard><replica>bdp-dc-001</replica></macros><!-- 002宏变量 --><macros><shard>01</shard><replica>bdp-dc-002</replica></macros>
修改后记得重启,然后分别在两台服务器上创建表:可以看到关键变量通过{}变量替换
# bdp-dc-001CREATETABLE test_bdp.replicated_sales_1
(`id` String,`price` Float64,`create_time`DateTime)ENGINE= ReplicatedMergeTree('/clickhouse/tables/{shard}/replicated_sales_1','{replica}')PARTITIONBY toYYYYMM(create_time)ORDERBY id
# bdp-dc-002CREATETABLE test_bdp.replicated_sales_1
(`id` String,`price` Float64,`create_time`DateTime)ENGINE= ReplicatedMergeTree('/clickhouse/tables/{shard}/replicated_sales_1','{replica}')PARTITIONBY toYYYYMM(create_time)ORDERBY id
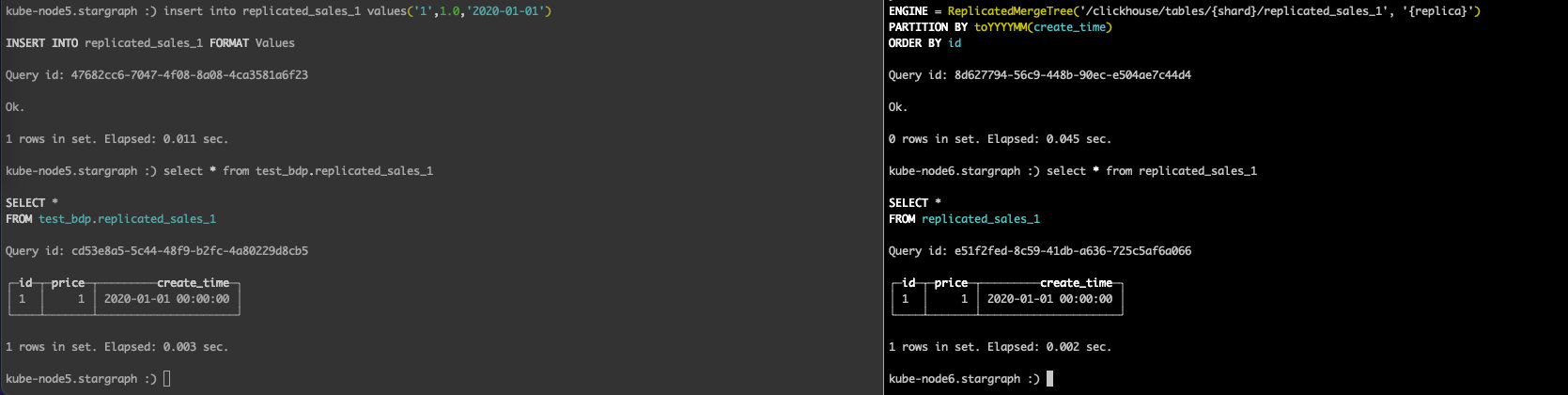
# bdp-dc-001插入数据insertinto replicated_sales_1 values('1',1.0,'2020-01-01')
结果一致
3、通过指定集群名,使用宏变量
我们每次去两台服务器上操作太麻烦,这时可以通过集群标签解决,更改bdp-dc-001、bdp-dc-002 两台服务器上的config.xml
<!-- 1分片1副本-本地表使用副本表 --><bdp_1S_1R><shard><replica><host>bdp-dc-001</host><port>9300</port></replica><replica><host>bdp-dc-002</host><port>9300</port></replica></shard></bdp_1S_1R>
保存后重启,在bdp-dc-001服务器上执行命令:
# bdp-dc-001CREATETABLE test_bdp.replicated_sales_2 ON CLUSTER bdp_1S_1R
(`id` String,`price` Float64,`create_time`DateTime)ENGINE= ReplicatedMergeTree('/clickhouse/tables/{shard}/replicated_sales_2','{replica}')PARTITIONBY toYYYYMM(create_time)ORDERBY id
此时去bdp-dc-002服务器上可以看到此表:
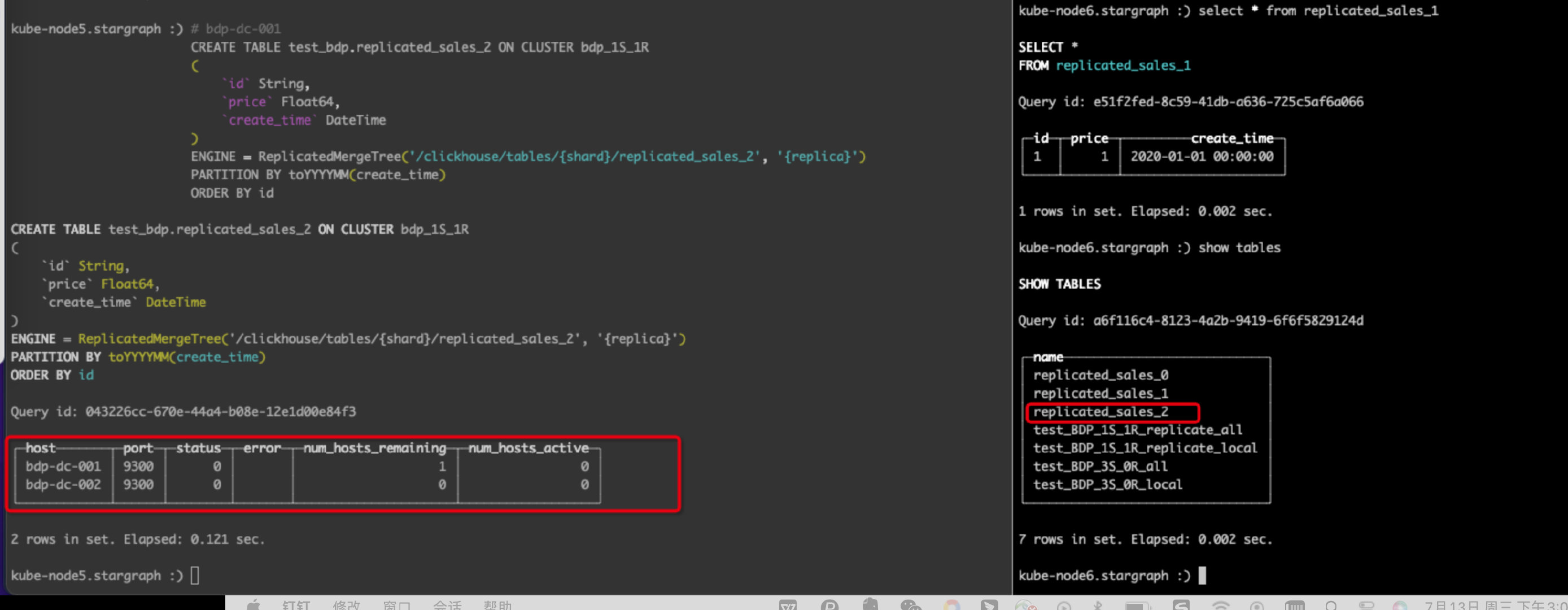
新增数据:
# bdp-dc-001插入数据insertinto replicated_sales_2 values('1',1.0,'2020-01-01')
查看结果:

4、通过指定集群名,使用配置文件默认配置创建
虽然上面已经方便很多,但是依然要在ReplicatedMergeTree引擎上指定命令,十分麻烦,官方给出了一种更简约的写法:

更改config.xml:在默认配置中使用宏变量
<!-- bdp-dc-001默认配置 --><default_replica_path>/clickhouse/tables/{shard}/{database}/{table}</default_replica_path><default_replica_name>{replica}</default_replica_name><!-- bdp-dc-002默认配置 --><default_replica_path>/clickhouse/tables/{shard}/{database}/{table}</default_replica_path><default_replica_name>{replica}</default_replica_name>
更改后重启服务后创建表:
# bdp-dc-001CREATETABLE test_bdp.replicated_sales_3 ON CLUSTER bdp_1S_1R
(`id` String,`price` Float64,`create_time`DateTime)ENGINE= ReplicatedMergeTree
PARTITIONBY toYYYYMM(create_time)ORDERBY id
此时去bdp-dc-002服务器上可以看到此表:
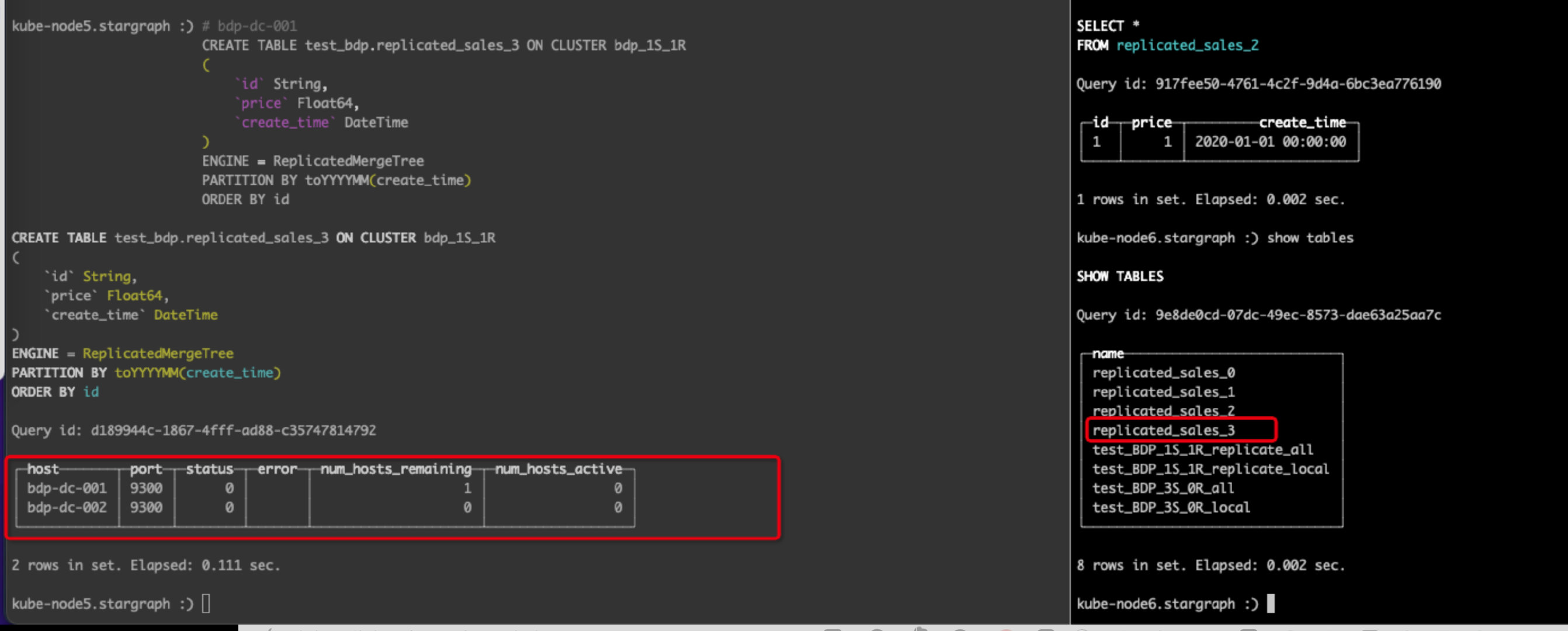
新增数据:
# bdp-dc-001插入数据insertinto replicated_sales_3 values('1',1.0,'2020-01-01')
查看结果:

on cluster语法
on cluster不仅可以创建副本表,分布式表,还可以创建数据库,还可以创建mergeTree表,可以说on cluster是为了让用户不用到处去别的服务其创建表了,而是通过<remote_servers> 集群标签自动在里面的服务器上创建表或数据库
例如:快捷构建数据库
CREATEDATABASE test_bdp ON CLUSTER bdp_3S_0R;
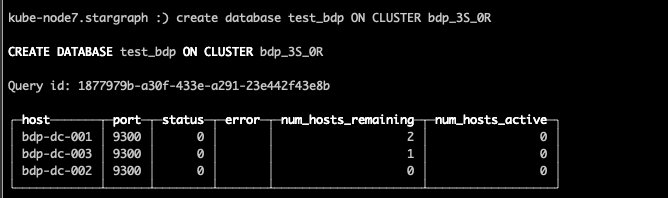
此时各个节点上都应该存在此库
副本表唯一性功能

然后我们验证一下,发现确实数据如果一致确实有去重功能
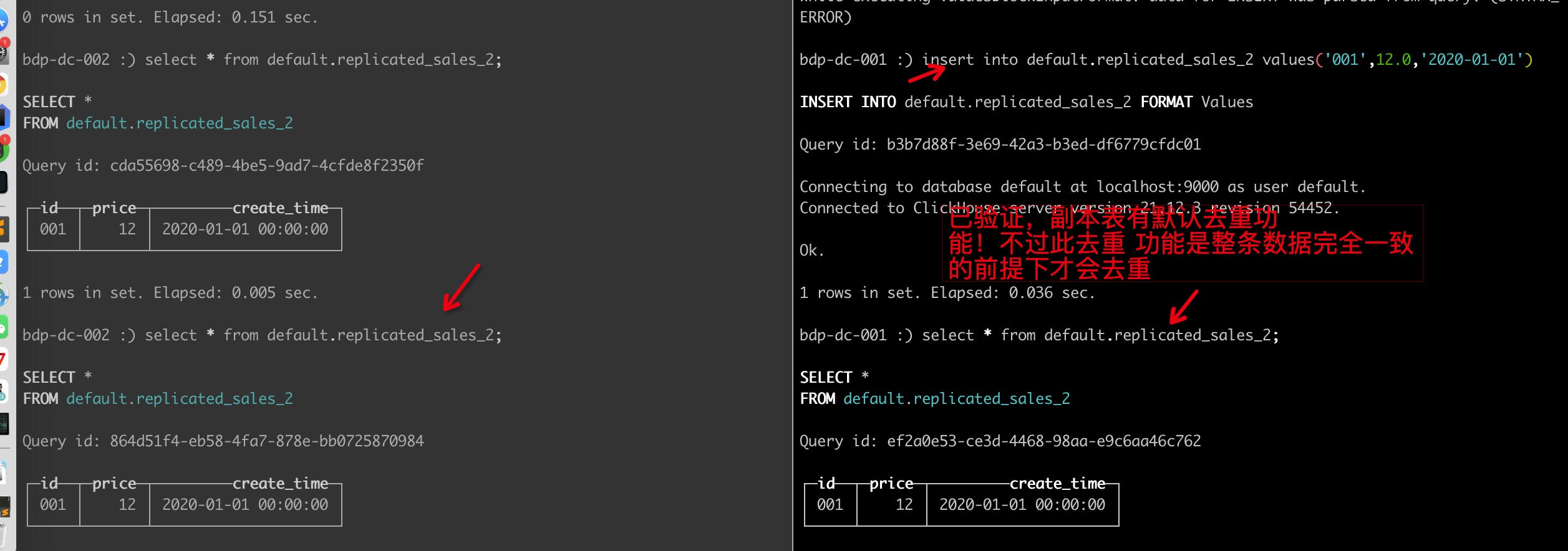
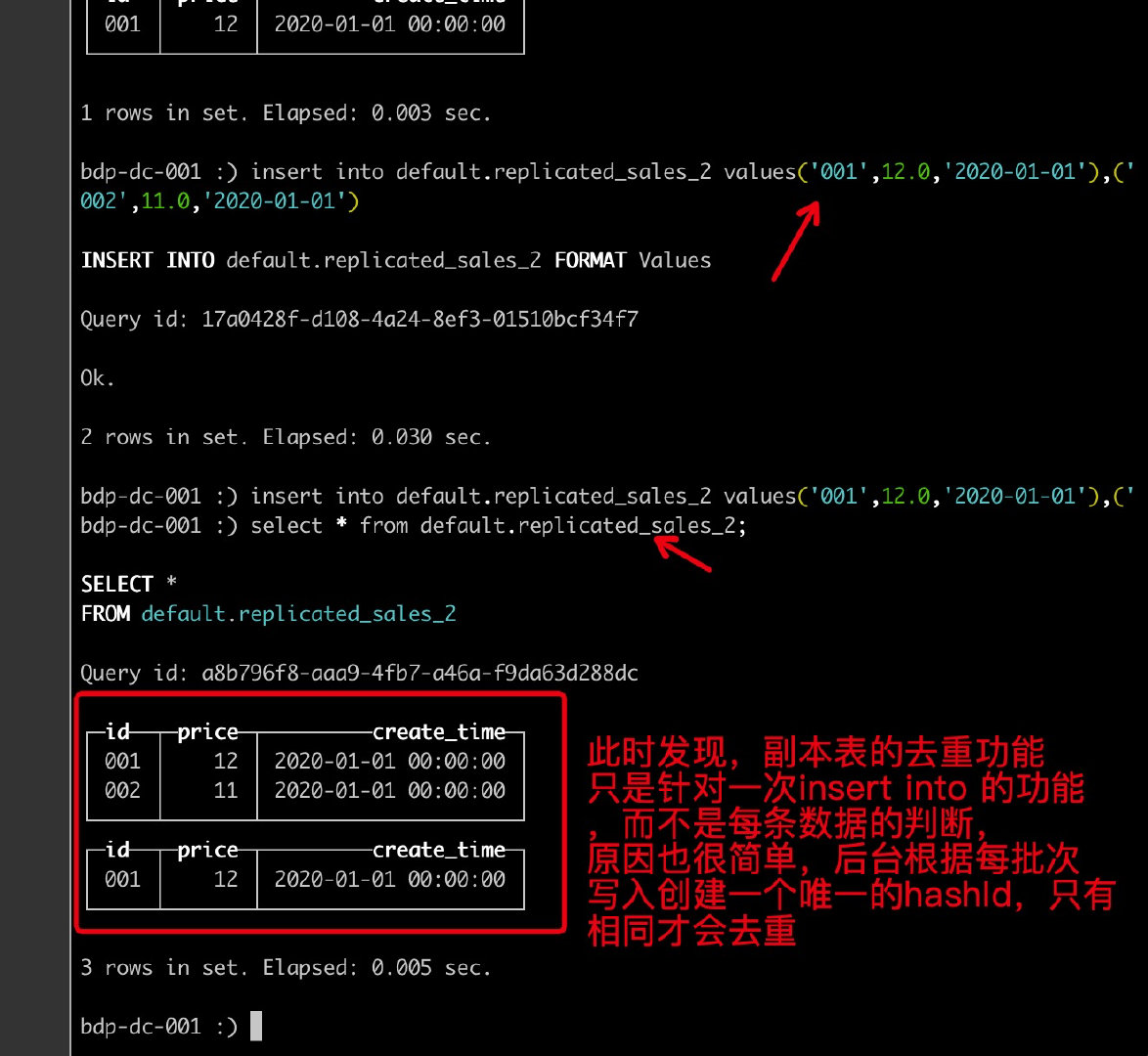
但是注意,此去重是一批次的去重,而不是根据每一条数据的去重
版权归原作者 高世之智 所有, 如有侵权,请联系我们删除。