
项目场景
atlas支持对hive元数据的管理,通过执行bin/import-hive.sh脚本即可,但目前大多数离线平台是用spark分析数据的,而spark元数据atlas解析不出来数据血缘,这就需要我们自己通过解析spark执行计划再结合atlas rest-api组建出来我们的数据血缘,接下来和大家分享一下atlas rest-api使用方法。
依赖引入
<!-- Atlas2.0 -->
<dependency>
<groupId>org.apache.atlas</groupId>
<artifactId>atlas-client-v2</artifactId>
<version>2.0.0</version>
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.atlas</groupId>
<artifactId>atlas-client-common</artifactId>
<version>2.0.0</version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
</exclusions>
</dependency>
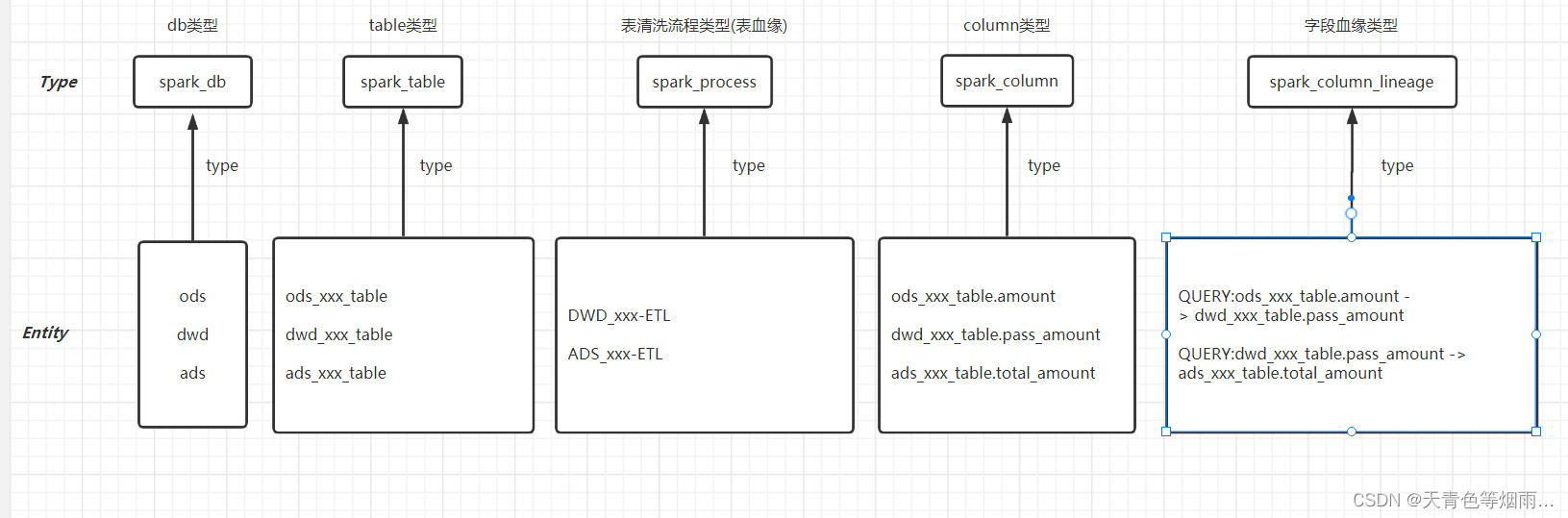
1.Type
1.1 概述
Type即元数据类型定义,这里可以是数据库、表、列等,还可以细分spark表(spark_table),hive表(hive_table)等,atlas自带了很多类型,如DataSet,Process等,一般情况下,数据相关的类型在定义类型的时候都会继承DataSet,而流程相关的类型则会继承Process,便于生成血缘关系。
注:Atlas管理的对象就是各种Type的Entity,因此先创建好Type再创建Entity,Type创建一次即可。
1.2 类型构建
1.Atlas自带hive相关类型如下: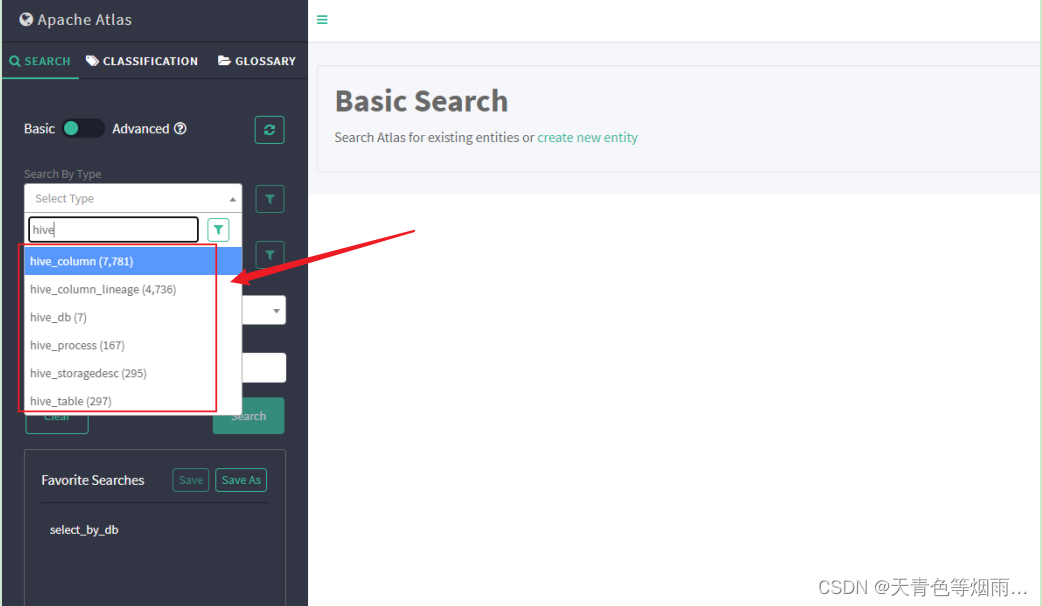
2.流程相关类型创建举例:
// 定义父类
val superType: Set[String]=Set(AtlasBaseTypeDef.ATLAS_TYPE_PROCESS)// 流程相关的类型继承Process(表血缘、字段血缘)// 类型创建对象
val typesDef = new AtlasTypesDef()// 类型定义
val columnLineageType = new AtlasEntityDef()// 类型对象
columnLineageType.setName("spark_column_lineage")// 类型名
columnLineageType.setSuperTypes(superType.asJava)// 父类
columnLineageType.setServiceType("spark")
columnLineageType.setTypeVersion(1.0)// 版本号
val typeList =List(columnLineageType)// 将类型放到集合里
typesDef.setEntityDefs(typeList.asJava)// 赋值// 构建查询过滤条件
val searchFilter = new SearchFilter()
searchFilter.setParam("name","spark_column_lineage")// 如果该类型不存在则创建
val allTypeDefs: AtlasTypesDef = atlasClientV2.getAllTypeDefs(searchFilter)if(allTypeDefs.getEntityDefs.isEmpty){// 类型创建
atlasClientV2.createAtlasTypeDefs(typesDef)}
说明:atlas自带spark_db/spark_table/spark_column/spark_process类型(旧版本中spark类型可能不完善),这里创建spark_column_lineage字段血缘类型作为参考。
3.数据相关类型创建举例(类型间存在关系如:db/table)
注:本次示例我们定义一个spark_db类型、spark_table类型,并且让spark_db一对多 spark_table
// 定义父类
val superType: Set[String]=Set(AtlasBaseTypeDef.ATLAS_TYPE_DATASET)// 数据相关的类型继承DataSet(库、表、字段)// 类型创建对象
val typesDef = new AtlasTypesDef()// db
val dbType = new AtlasEntityDef()// 类型对象
dbType.setName("spark_db")// 类型名
dbType.setSuperTypes(superType.asJava)// 父类
dbType.setServiceType("spark")
dbType.setTypeVersion(1.0)// 版本号// table
val tableType = new AtlasEntityDef()// 类型对象
tableType.setName("spark_table")// 类型名
tableType.setSuperTypes(superType.asJava)// 父类
tableType.setServiceType("spark")
tableType.setTypeVersion(1.0)// 版本号
val typeList =List(dbType,tableType)// 将类型放到集合里
typesDef.setEntityDefs(typeList.asJava)// 赋值// db与table之间存在依赖关系(一对多),下面创建它们的关系使其联系起来//定义relationshipDef
val relationshipDef1 = new AtlasRelationshipDef()
relationshipDef1.setName("table_db")// 关系名自定义
relationshipDef1.setServiceType("spark")
relationshipDef1.setTypeVersion("1.0")/**
* 关系类型:
* ASSOCIATION:关联关系,没有容器存在,1对1
* AGGREGATION:容器关系,1对多,而且彼此可以相互独立存在
* COMPOSITION:容器关系,1对多,但是容器中的实例不能脱离容器存在
*/
relationshipDef1.setRelationshipCategory(AtlasRelationshipDef.RelationshipCategory.AGGREGATION)// 推导tag:NONE-不推导
relationshipDef1.setPropagateTags(AtlasRelationshipDef.PropagateTags.NONE)//定义endDef1
val endDef1 = new AtlasRelationshipEndDef()
endDef1.setType("spark_talbe")//表中关联的属性名称
endDef1.setName("db")//代表这头是不是容器
endDef1.setIsContainer(false)//cardinality:三种类型SINGLE(单值), LIST(多值可重复), SET(多值不重复)
endDef1.setCardinality(AtlasStructDef.AtlasAttributeDef.Cardinality.SINGLE)
relationshipDef1.setEndDef1(endDef1)//定义endDef2
val endDef2 = new AtlasRelationshipEndDef()
endDef2.setType("spark_db")//数据库关联的属性名称
endDef2.setName("tables")
endDef2.setIsContainer(true)// db 包含 table,table不能重复,所以类型设置为 SET
endDef2.setCardinality(AtlasStructDef.AtlasAttributeDef.Cardinality.SET)
relationshipDef1.setEndDef2(endDef2)//关系可能有多种,定义关系集合relationshipDefs
val relationshipDefs =List(relationshipDef1)
typesDef.setRelationshipDefs(relationshipDefs.asJava)// 构建查询过滤条件
val searchFilter = new SearchFilter()
searchFilter.setParam("name","spark_db")// 如果该类型不存在则创建
val allTypeDefs: AtlasTypesDef = atlasClientV2.getAllTypeDefs(searchFilter)if(allTypeDefs.getEntityDefs.isEmpty){// 类型创建
atlasClientV2.createAtlasTypeDefs(typesDef)}
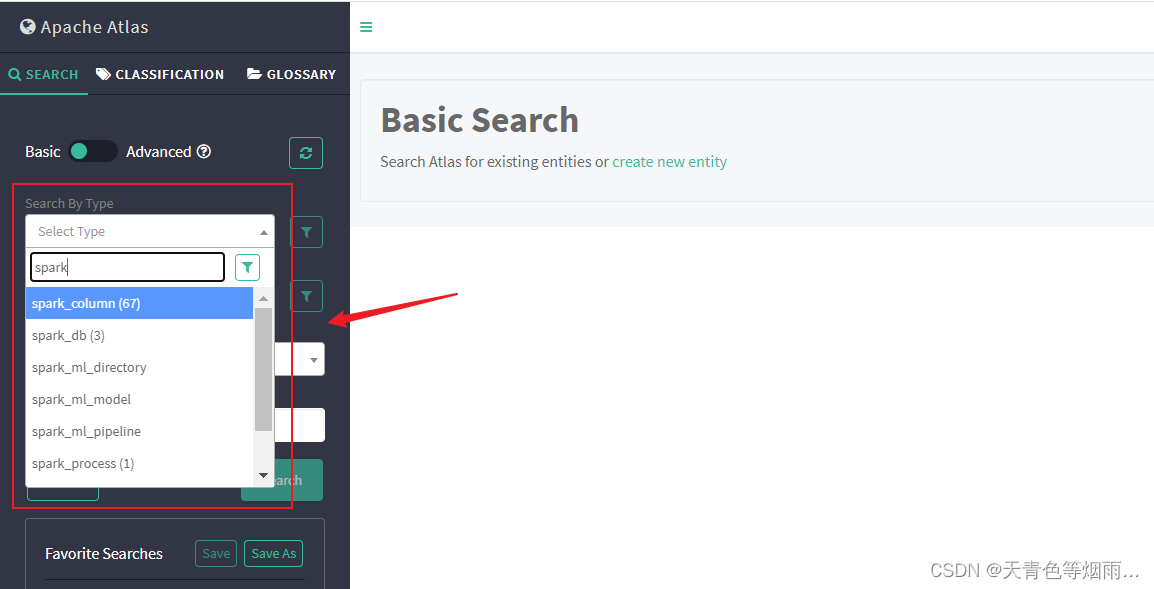
执行完毕后,可前往 Atlas 主页查看,类型已创建成功:
1.3 类型查询
// 构建查询过滤条件
val searchFilter = new SearchFilter()
searchFilter.setParam("name","spark_db")// 查询
val allTypeDefs: AtlasTypesDef = atlasClientV2.getAllTypeDefs(searchFilter)
*注意*
创建实体时有必要提前查看一下类型,因为需要注意该类型下所有属性的“getIsOptional”值即是否可选,如果为true,创建该类型下的实体时可以忽略该属性,如果为false,创建实体时必须给该属性赋值,否则会创建失败。
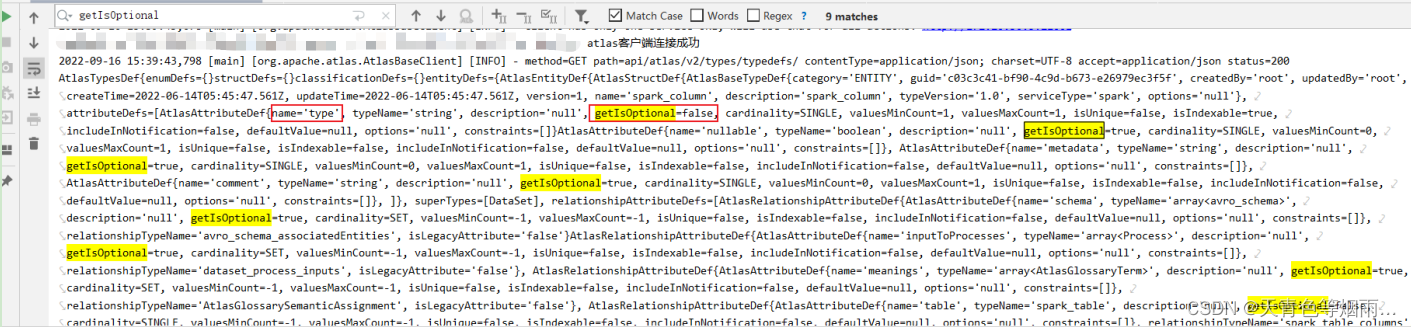
报错类似如下:
“Invalid instance creation/updation parameters passed : spark_column.type: mandatory attribute value missing in type spark_column”
// 传递的实例创建/更新参数无效:spark_column。Type: spark_column类型中缺失的必选属性值
例如:创建spark_column类型下的字段实体,如果没有给该实体的“type”属性赋值就会创建失败。
1.4 类型删除
val myProcess = new AtlasEntityDef()
myProcess.setName("spark_process")// 类型名
val myType = new AtlasTypesDef()
myType.setEntityDefs(Seq(myProcess).asJava)
atlasClientV2.deleteAtlasTypeDefs(myType)
说明:对类型下的实体进行删除,默认情况下atlas为标记删除(删除策略见配置文件atlas-application.properties下的atlas.DeleteHandlerV1.impl),从2.1.0版本才支持对已“标记删除”的实体进行清除,因此在2.1.0以前如果想彻底删除atlas的实体,需要在没有创建任何实体之前修改atlas删除策略为物理删除,否则实体标记删除对type依然存在引用,这样对type进行删除操作会失败,报“给定类型xxx有引用”的错误。
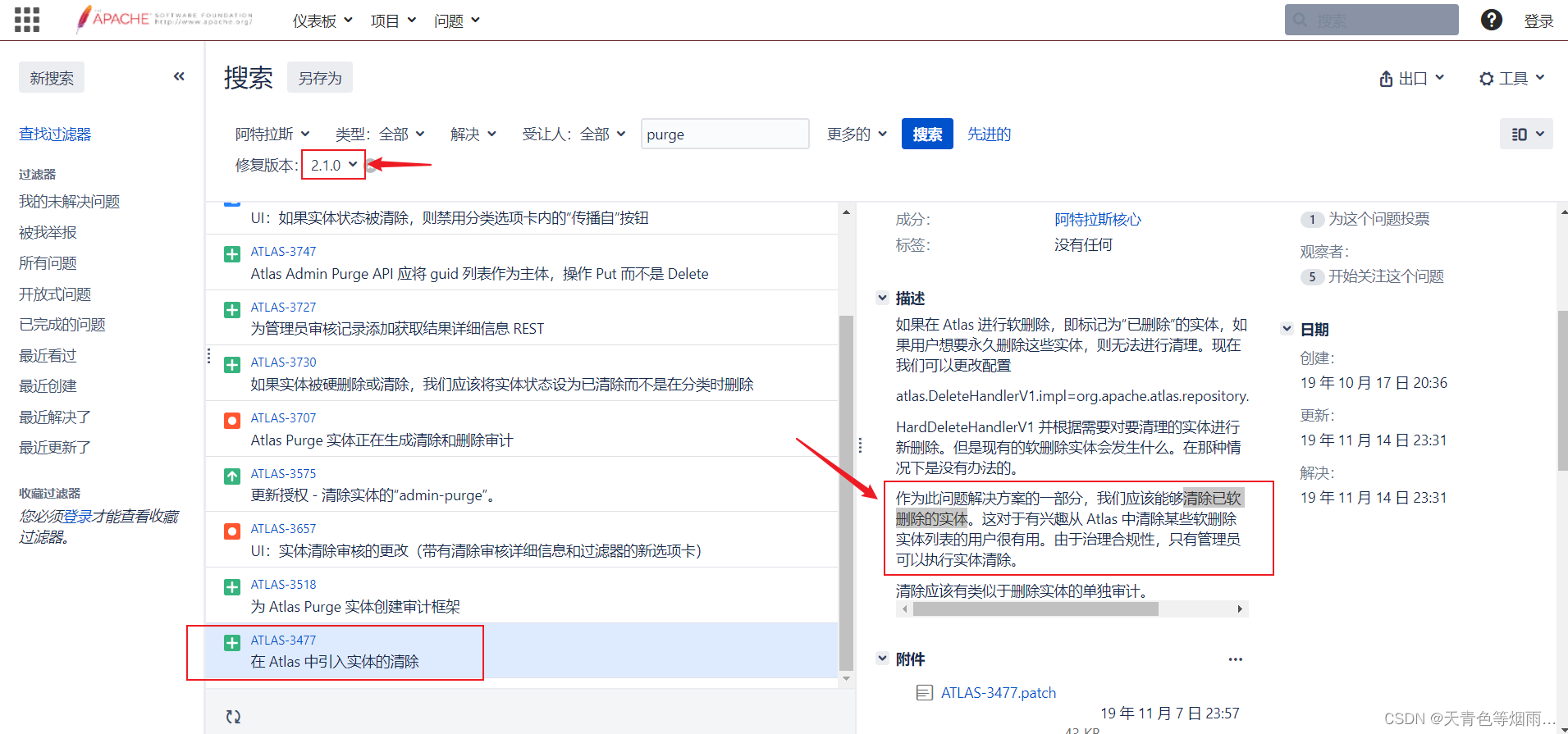

类型删除成功客户端返回的状态为204

2.Entity
2.1 概述
Entity即实体,表示具体的元数据,Atlas管理的对象就是各种Type的Entity,如一个表是一个实体(Entity),一个字段也是一个实体等等。
2.2 实体创建
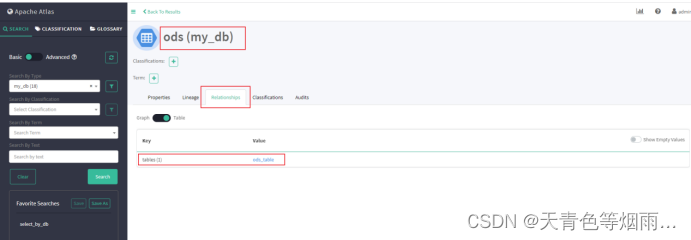
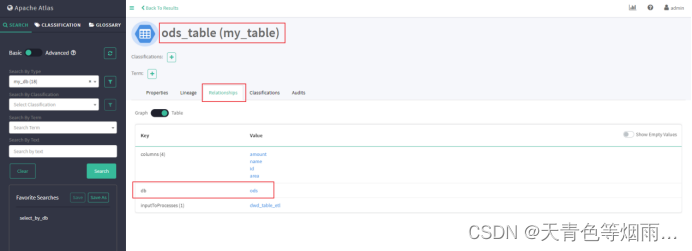
注:本次示例我们创建ods和dwd数据库实体到spark_db下,创建ods_table和dwd_table表实体到spark_table下,并且定义dwd_table的数据来自ods_table,生成两个表实体的血缘关系依赖;创建amount(ods_table)和maxAmount(dwd_table)字段实体到spark_column下,并且定义maxAmount的数据来自amount,生成两个字段实体的血缘关系依赖。
// 数据库实体
val ods = new AtlasEntity()
ods.setTypeName("spark_db")// 实体类型
val odsAttributes: Map[String, AnyRef]=Map("qualifiedName"->"ods","name"->"ods","description"->"测试创建db-ods")// 实体属性配置
ods.setAttributes(odsAttributes.asJava)
val dwd = new AtlasEntity()
dwd.setTypeName("spark_db")// 实体类型
val dwdAttributes: Map[String, AnyRef]=Map("qualifiedName"->"dwd","name"->"dwd","description"->"测试创建db-dwd")// 实体属性配置
dwd.setAttributes(dwdAttributes.asJava)// 表实体
val odsTable = new AtlasEntity()
odsTable.setTypeName("spark_table")// 实体类型// 实体属性配置
val odsTableAttributes: Map[String, AnyRef]=Map("qualifiedName"->"ods.ods_table","name"->"ods_table","description"->"测试创建ods_table","db"->new AtlasObjectId("spark_db","qualifiedName","ods"))// 指明该表所在的数据库
odsTable.setAttributes(odsTableAttributes.asJava)
val dwdTable = new AtlasEntity()
dwdTable.setTypeName("spark_table")// 实体类型// 实体属性配置
val dwdTableAttributes: Map[String, AnyRef]=Map("qualifiedName"->"dwd.dwd_table","name"->"dwd_table","description"->"测试创建dwd_table","db"->new AtlasObjectId("spark_db","qualifiedName","dwd"))// 指明该表所在的数据库
dwdTable.setAttributes(dwdTableAttributes.asJava)// 表血缘实体
val process = new AtlasEntity()
process.setTypeName("spark_process")// 实体类型// 实体属性配置
val processAttributes: Map[String, AnyRef]=Map("qualifiedName"->"dwd_table_etl","name"->"dwd_table_etl","description"->"dwd_table的数据来自ods_table","inputs"->Array(new AtlasObjectId("spark_table","qualifiedName","ods.ods_table")),// 血缘输入"outputs"->Array(new AtlasObjectId("spark_table","qualifiedName","dwd.dwd_table")))// 血缘输出
process.setAttributes(processAttributes.asJava)// 字段实体
val odsTableColumn = new AtlasEntity()
odsTableColumn.setTypeName("spark_column")// 实体类型// 实体属性配置
val odsTableColumnAttributes: Map[String, AnyRef]=Map("qualifiedName"->"ods.ods_table.amount","name"->"amount",
AtlasConstant.ATTRIBUTE_COMMENT->"额度","table"->new AtlasObjectId("spark_table","qualifiedName","ods.ods_table"))// 指明该字段所在的表
odsTableColumn.setAttributes(odsTableColumnAttributes.asJava)
val dwdTableColumn = new AtlasEntity()
dwdTableColumn.setTypeName("spark_column")// 实体类型// 实体属性配置
val dwdTableColumnAttributes: Map[String, AnyRef]=Map("qualifiedName"->"dwd.dwd_table.maxAmount","name"->"maxAmount",
AtlasConstant.ATTRIBUTE_COMMENT->"最大额度","table"->new AtlasObjectId("spark_table","qualifiedName","dwd.dwd_table"))// 指明该字段所在的表
dwdTableColumn.setAttributes(dwdTableColumnAttributes.asJava)// 字段血缘实体
val columnLineage = new AtlasEntity()
columnLineage.setTypeName("spark_column_lineage")// 实体类型// 实体属性配置
val columnLineageAttributes: Map[String, AnyRef]=Map("qualifiedName"->"Query:ods.ods_table.amount->dwd.dwd_table.maxAmount","name"->"Query:ods.ods_table.amount->dwd.dwd_table.maxAmount",
AtlasConstant.ATTRIBUTE_COMMENT->"dwd.dwd_table.maxAmount的数据来自ods.ods_table.amount","inputs"->Array(new AtlasObjectId("spark_column","qualifiedName","ods.ods_table.amount")),// 血缘输入"outputs"->Array(new AtlasObjectId("spark_column","qualifiedName","dwd.dwd_table.maxAmount")))// 血缘输出
columnLineage.setAttributes(columnLineageAttributes.asJava)// 将所有实体放入seq集合中
val entities: Seq[AtlasEntity]=Seq(ods,odsTable,odsTableColumn,dwdTable,dwd,process,dwdTableColumn,columnLineage)// 调用工具类的实体创建方法
AtlasUtils.createAllEntities(atlasClientV2,entities)
AtlasUtils.createAllEntities()
/**
* 实体创建
* @param atlasClientV2
* @param atlasEntities
*/
def createAllEntities(atlasClientV2: AtlasClientV2,atlasEntities: Seq[AtlasEntity]): Unit ={
val entitiesGroupMap: Map[String, Seq[AtlasEntity]]= atlasEntities.groupBy(_.getTypeName)// 所有实体按类型名分组// 逐层创建if(entitiesGroupMap.contains("spark_db")){
atlasClientV2.createEntities(new AtlasEntity.AtlasEntitiesWithExtInfo(entitiesGroupMap.get("spark_db").get.asJava))}if(entitiesGroupMap.contains("spark_table")){
atlasClientV2.createEntities(new AtlasEntity.AtlasEntitiesWithExtInfo(entitiesGroupMap.get("spark_table").get.asJava))}if(entitiesGroupMap.contains("spark_process")){
atlasClientV2.createEntities(new AtlasEntity.AtlasEntitiesWithExtInfo(entitiesGroupMap.get("spark_process").get.asJava))}if(entitiesGroupMap.contains("spark_column")){
atlasClientV2.createEntities(new AtlasEntity.AtlasEntitiesWithExtInfo(entitiesGroupMap.get("spark_column").get.asJava))}if(entitiesGroupMap.contains("spark_column_lineage")){
atlasClientV2.createEntities(new AtlasEntity.AtlasEntitiesWithExtInfo(entitiesGroupMap.get("spark_column_lineage").get.asJava))}}
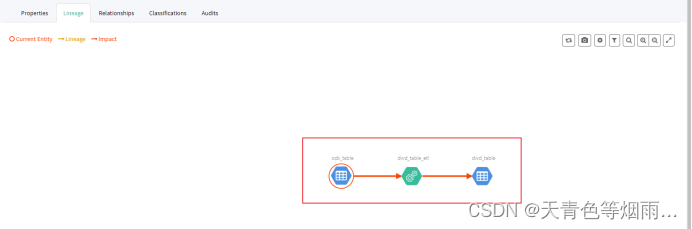
执行以上代码,然后打开主页,点击spark_table中的ods_table,查看lineage标签,表血缘关系已成功构建:
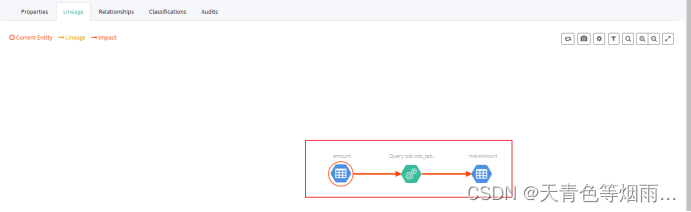
点击spark_column中的amount,查看lineage标签,字段血缘关系已成功构建:
2.3 实体删除
/**
* 实体删除
* @param atlasClientV2
* @param typeName 实体类型
* @param qualifiedName
*/
def deleteEntity(atlasClientV2: AtlasClientV2,typeName: String,qualifiedName: String): Unit ={
val attributes: Map[String, String]=Map("qualifiedName"-> qualifiedName)
atlasClientV2.deleteEntityByAttribute(typeName,attributes.asJava)}
说明:该方式通过指明实体类型及qualifiedName,还可通过guid等进行删除
2.4 实体查询
// 构建查询条件
val queryAttributes: Map[String, String]=Map("qualifiedName"->"ods")// 第一个参数为查询的实体类型
Val extInfo = atlasClientV2.getEntityByAttribute("spark_db", queryAttributes)
2.5 实体的独立性
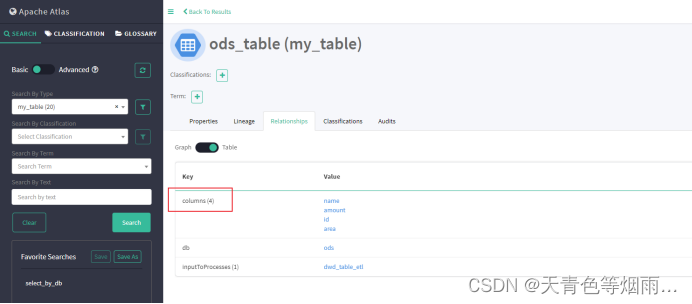
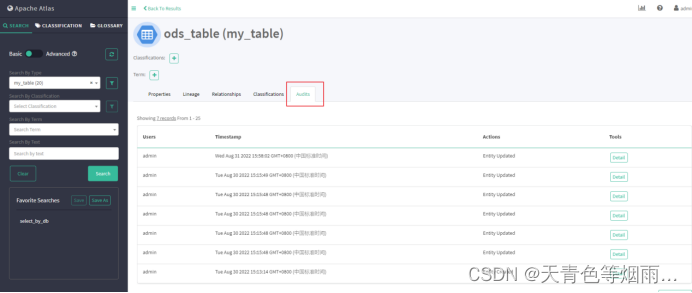
在atlas中实体是独立的,因此当有业务变更涉及增删字段时,删除某字段实体会在相应表实体columns属性中移除,但表实体的Audits栏中并不会新增一条更新操作记录(可能是使用的版本存在bug);
当新增字段实体时,仅且需要创建该字段实体即可,无需重新建表,我们可以观察到新增该字段实体的同时,表实体的columns的属性中新增了该字段,Audits栏中新增了一条更新操作记录。
当创建atlas中已存在的实体时,如果该实体所有属性均未发生改变,那么在atlas中不会看到任何变化,实体的Audits栏中也不会新增一条创建或更新的操作记录;若有部分属性发生变化,则会对该实体进行更新,可以观察到发生变化的属性,而且Audits栏中新增了一条更新操作记录。
2.6 实体的依赖性
值得注意的是,无论是在创建或删除操作时都需要注意实体间的依赖关系:
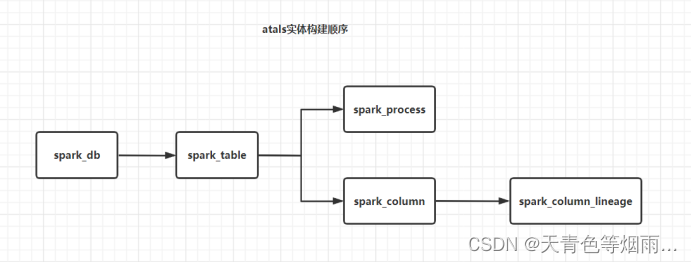
创建时务必从左到右(比如创建dwd_xxx_xxx表实体时需要提前创建好dwd实体,因为建表实体需要拿到库实体的的唯一标识,或是Guid或是AtlasObjectId,来确定该表所在的库是哪个也就是指明它们之间的关系,atlas中每个实体均带有唯一的Guid,创建时随机生成,获取不到会报下图所示的错误而失败,因此需要创建好上层再创建下层)。

删除时顺序反之,如果先删除数据库实体,操作可以成功,不会影响下层的血缘,但会影响库与表之前定义好的关系,涉及到该数据库的表实体db属性也会连带删除,若将该数据库实体重新创建回来也不能恢复它与表之间的关系,表实体也需要重建。
3.Lineage
3.1概述
数据血缘,表示数据之间的传递关系,通过 Lineage 我们可以清晰的知道数据的从何而来又流向何处,中间经历了哪些操作,这样一旦数据出现问题,可以迅速追溯,定位是哪个环节出现错误。
4.Classification
4.1 概述
分类,通俗点就是给元数据打标签,分类是可以传递的,比如 A 视图是基于 A 表生成的,那么如果 A 表打上了 a 这个标签,A 视图也会自动打上 a 标签,这样的好处就是便于数据的追踪。
记得点赞收藏奥,关注不迷路~
版权归原作者 天青色等烟雨... 所有, 如有侵权,请联系我们删除。