
5.5 输出算子
5.5.1 概述
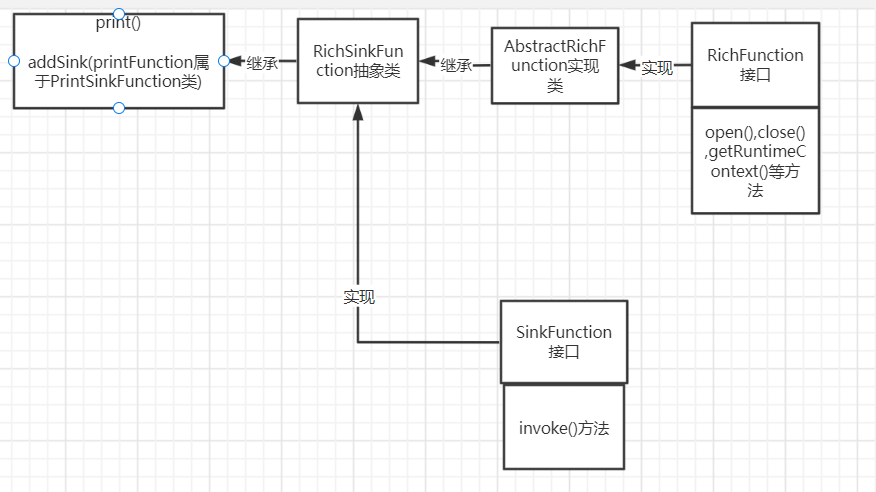
- 调用print是返回输出类,作为最后一环sink存在

该方法创建了一个PrintSinkFunction 操作,然后作为addSink方法的参数

PrintSinkFunction这个类继承自RichSinkFunction富函数类
- RichSinkFunction类

- 继承了AbstractRichFunction富函数类
因此就可以调用富函数类(是一个实现类)的声明周期方法,例如open,close,以及获取运行时上下文,运行环境,定义状态等等
- RichSinkFunction类同时也实现了SinkFunction这个接口,所以本质上也是SinkFunction


- SinkFunction接口的抽象方法有invoke,传入是value,以及当前的上下文
- 关系图
- 如果需要自定义输出算子

可以调用DataStream的addSink方法

然后传入自己实现的SinkFunction
- flink提供的第三方系统连接器

5.5.2 输出到文件
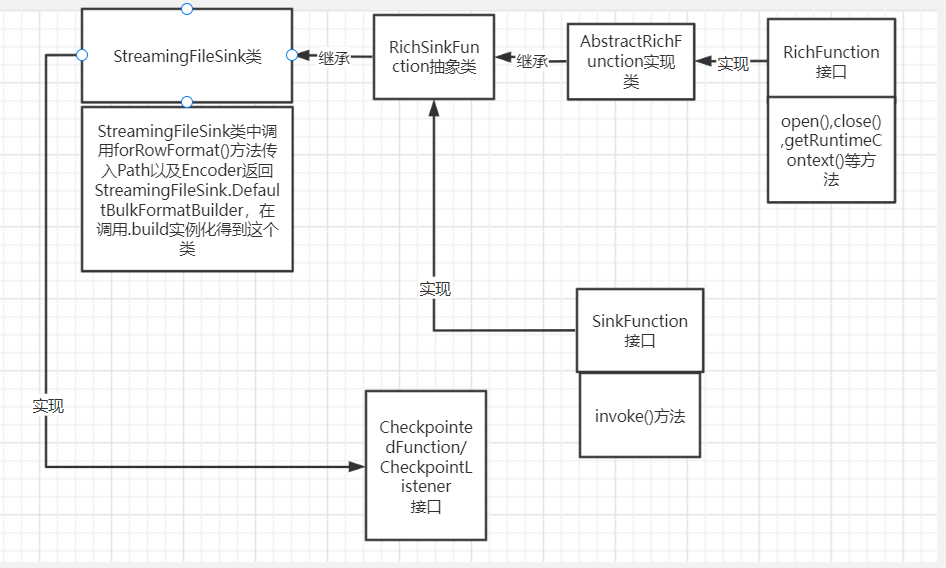
- StreamingFileSink流文件输出类
- 来源

继承RichSinkFunction类,并实现CheckpointedFunction,CheckpointListener(检查点)
- 创建实例

在StreamingFileSink类中调用forRowFormat()方法传入Path以及Encoder返回StreamingFileSink.DefaultBulkFormatBuilder,DefaultBulkFormatBuilder是一个静态类并继承RowFormatBuilder类,RowFormatBuilder类又继承BucketsBuilder类,底层将数据写入bucket(桶),桶里面分大小存储分区文件,实现了分布式存储

使用Builder构建器构建


RowFormatBuilder是行编码

BulkFormatBuilder是列存储编码格式
- 关系图
- 代码
publicclassSinkToFileTest{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);DataStreamSource<Event> stream = env.fromElements(newEvent("Mary","./home",1000L),newEvent("Bob","./cart",2000L),newEvent("Alice","./prod?id=100",3000L),newEvent("Bob","./prod?id=1",3300L),newEvent("Alice","./prod?id=200",3000L),newEvent("Bob","./home",3500L),newEvent("Bob","./prod?id=2",3800L),newEvent("Bob","./prod?id=3",4200L));//2.为了得到并传入SinkFunction,需要构建StreamingFileSink的一个对象//调用forRowFormat方法或者forBulkformat方法得到一个DefaultRowFormatBuilder// 其中forBulkformat方法前面还有类型参数,以及传参要求一个目录名称,一个编码器//写入文件需要序列化,需要定义序列化方法并进行编码转换,当成Stream写入文件//然后再使用builder创建实例StreamingFileSink<String> streamingFileSink =StreamingFileSink.<String>forRowFormat(newPath("./output"),newSimpleStringEncoder<>("UTF-8")).withRollingPolicy(//指定滚动策略,根据事件或者文件大小新产生文件归档保存DefaultRollingPolicy.builder()//使用builder构建实例.withMaxPartSize(1024*1024*1024).withRolloverInterval(TimeUnit.MINUTES.toMinutes(15))//事件间隔毫秒数.withInactivityInterval(TimeUnit.MINUTES.toMinutes(15))//当前不活跃的间隔事件,隔多长事件没有数据到来.build()).build();//1.写入文件调用addSink()方法,并传入SinkFunction
stream
.map(data -> data.toString())//把Event类型转换成String.addSink(streamingFileSink);
env.execute();}}
- 结果

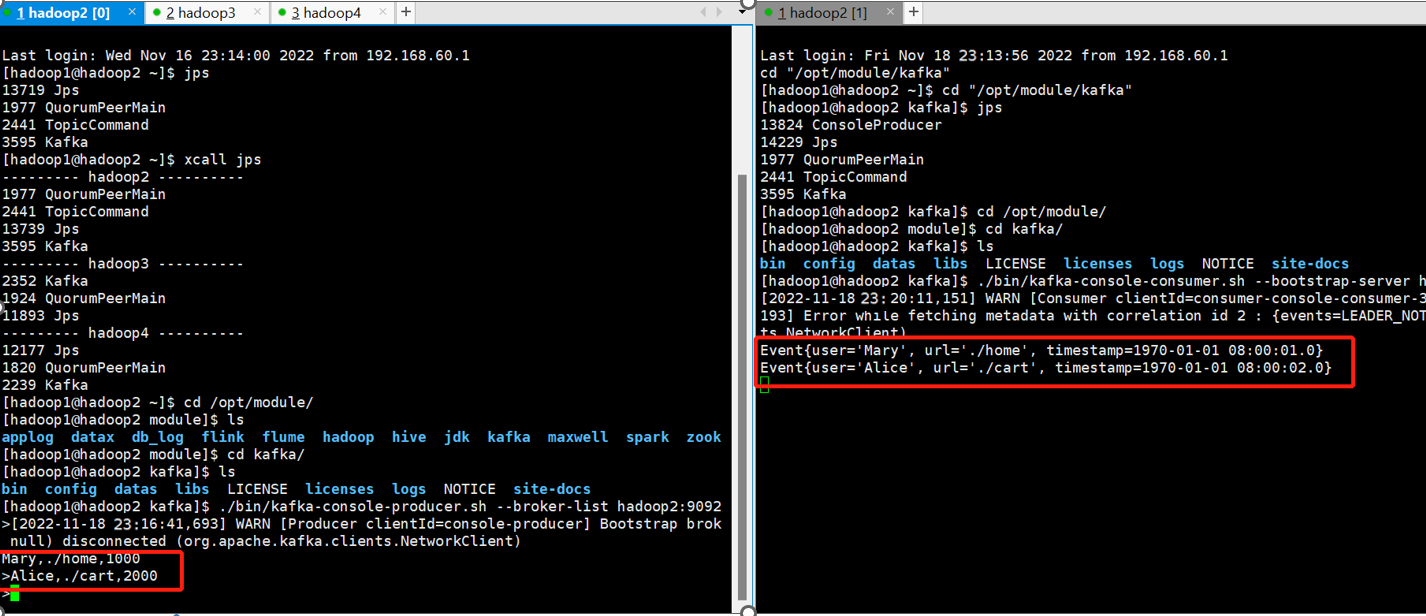
5.5.3 输出到kafka

构造FlinkKafkaProducer类传入三个参数:brokerList(主机+端口号)和topicId(topic)以及serializationSchema(编码序列化)完成构造
- 代码
publicclassSinkToKafka{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//1.从kafka中读取数据Properties properties =newProperties();
properties.setProperty("bootstrap.servers","hadoop2:9092");
properties.setProperty("group.id","consumer-group");DataStreamSource<String> kafkaStream = env.addSource(newFlinkKafkaConsumer<String>("clicks",newSimpleStringSchema(), properties));//2.用flink进行简单的etl处理转换SingleOutputStreamOperator<String> result = kafkaStream.map(newMapFunction<String,String>(){@OverridepublicStringmap(String value)throwsException{String[] fields = value.split(",");returnnewEvent(fields[0].trim(), fields[1].trim(),Long.valueOf(fields[2].trim())).toString();}});//3.结果数据写入kafka//FlinkKafkaProducer传参borckList,topicid,序列化
result.addSink(newFlinkKafkaProducer<String>("hadoop2:9092","events",newSimpleStringSchema()));
env.execute();}}
- kafka输出结果
5.5.4 输出到redis
- 引入依赖
<dependency><groupId>org.apache.bahir</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.0</version></dependency>
- 分析
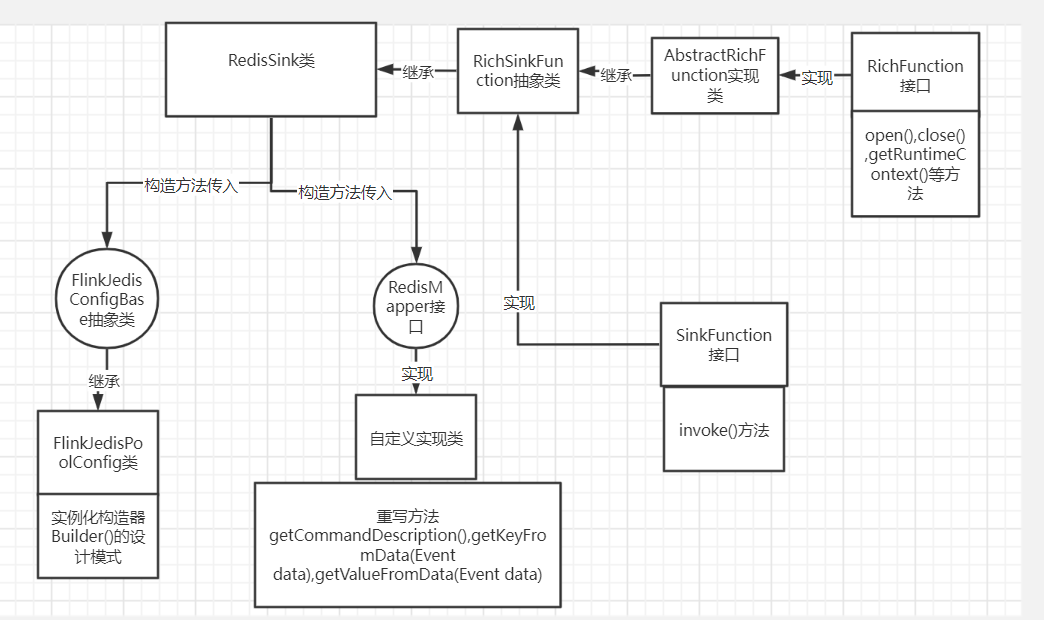
- RedisSink类分析

RedisSink类继承自RichSinkFunction
- 参数分析

去调构造方法,传入redis集群的配置FlinkJedisConfigBase以及RedisMapper写入命令

new FlinkJedisConfigBase的时候,可以使用FlinkJedisPoolConfig没毛病,直接继承的FlinkJedisConfigBase

FlinkJedisConfigBase是一个接口
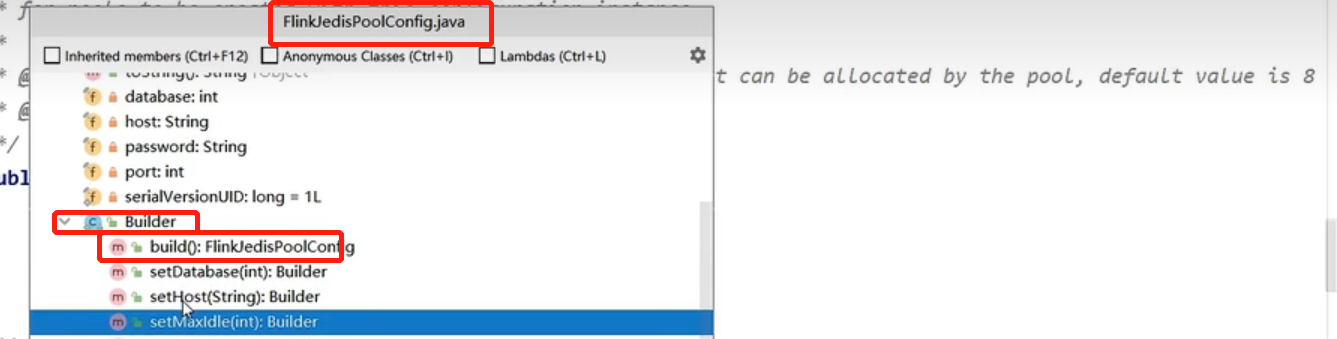
实例FlinkJedisPoolConfig的时候也是使用的构造器Builder()的设计模式即,同样再使用.build实例它
- 第二个参数分析

RedisMapper是一个接口

自定义一个实现类并重写方法getCommandDescription(),getKeyFromData(Event data),getValueFromData(Event data)
- 关系图
- 代码
publicclassSinkToRedis{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//1.输入ClickSource是自定义输入DataStreamSource<Event> stream = env.addSource(newClickSource());//2.创建一个jedis连接配置//FlinkJedisPoolConfig直接继承的FlinkJedisConfigBaseFlinkJedisPoolConfig config =newFlinkJedisPoolConfig.Builder().setHost("hadoop2").build();//3.写入redis
stream.addSink(newRedisSink<>(config,newMyRedisMapper()));
env.execute();}//3.自定义类实现 redisMapper接口publicstaticclassMyRedisMapperimplementsRedisMapper<Event>{@Override//返回一个redis命令的描述publicRedisCommandDescriptiongetCommandDescription(){returnnewRedisCommandDescription(RedisCommand.HSET,"clicks");//写入哈希表}@Override//把key定义成userpublicStringgetKeyFromData(Event data){return data.user;}@Override//把value定义成urlpublicStringgetValueFromData(Event data){return data.url;}}}
- 结果
运行redis
[hadoop1@hadoop2 redis]$ ./src/redis-server
[hadoop1@hadoop2 bin]$ pwd
/usr/local/bin

5.5.5 输出到ElasticSearch
- 引入依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-elasticsearch6_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency>
- 分析
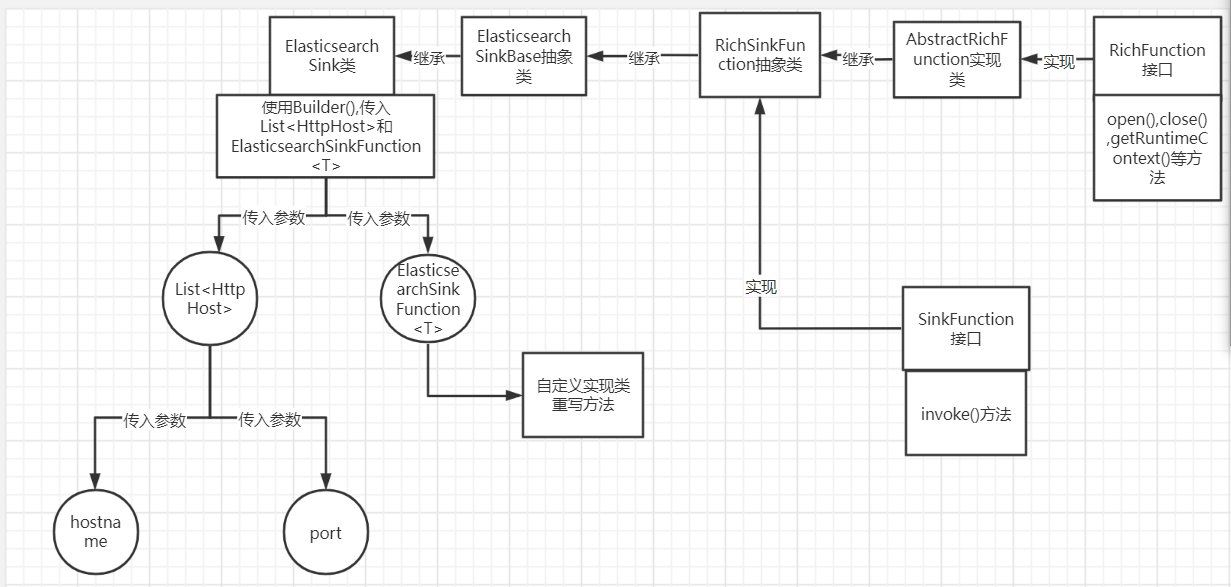
- ElasticsearchSink类分析


ElasticsearchSink类继承ElasticsearchSinkBase抽象类,ElasticsearchSinkBase抽象类继承RichSinkFunction接口
- 实例

ElasticsearchSink类调用Builder()传入参数是List和ElasticsearchSinkFunction

HttpHost需要参数主机名和端口号

是一个接口,写一个实现类重写他的方法,写入逻辑
- 关系图
- 代码
publicclassSinToES{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//1.输入DataStreamSource<Event> stream = env.fromElements(newEvent("Mary","./home",1000L),newEvent("Bob","./cart",2000L),newEvent("Alice","./prod?id=100",3000L),newEvent("Bob","./prod?id=1",3300L),newEvent("Alice","./prod?id=200",3000L),newEvent("Bob","./home",3500L),newEvent("Bob","./prod?id=2",3800L),newEvent("Bob","./prod?id=3",4200L));//2.定义hosts的列表ArrayList<HttpHost> httpHosts =newArrayList<>();
httpHosts.add(newHttpHost("hadoop",9200));//3.定义ElasticsearchSinkFunction<T>,是个接口,重写process方法//向es发送请求,并插入数据ElasticsearchSinkFunction<Event> elasticsearchSinkFunction =newElasticsearchSinkFunction<Event>(){@Override//输入,运行上下文,发送任务请求publicvoidprocess(Event element,RuntimeContext ctx,RequestIndexer indexer){HashMap<String,String> map =newHashMap<>();
map.put(element.user, element.url);//构建一个indexrequestIndexRequest request =Requests.indexRequest().index("clicks").type("types").source(map);
indexer.add(request);}};//4.写入es//传入参数是List<HttpHost>和ElasticsearchSinkFunction<T>
stream.addSink(newElasticsearchSink.Builder<>(httpHosts,elasticsearchSinkFunction).build());
env.execute();}}
- 结果


5.5.6 输入到Mysql
- 引入依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.47</version></dependency>
- 分析
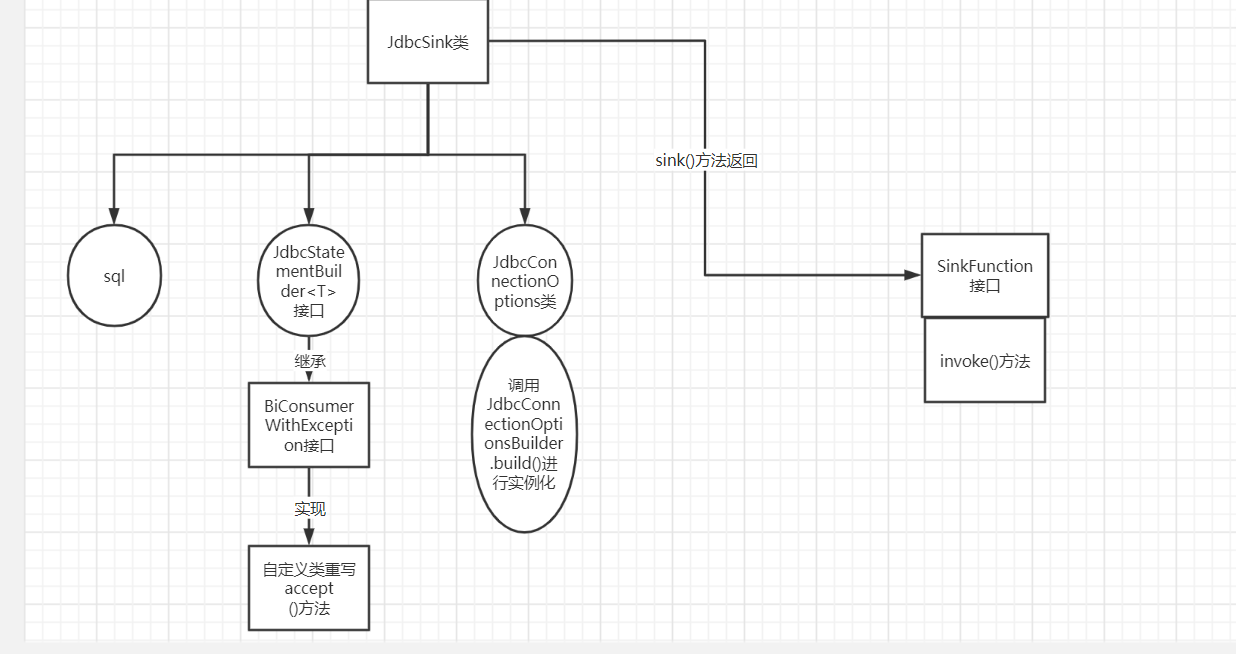
- JdbcSink来源

无继承,无实现

定义了sink方法,三个参数,sql,JdbcStatementBuilder构造,JdbcConnectionOptions等sql的连接配置,然后返回SinkFunction
- 参数分析
JdbcStatementBuilder是个接口,实现了BiConsumerWithException接口
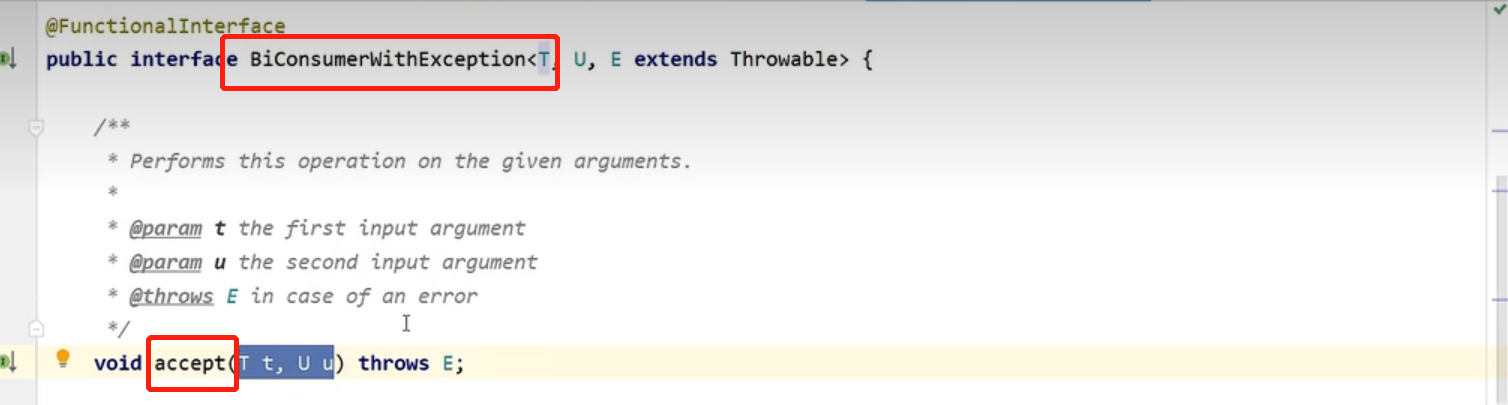
单一抽象方法accept(),lambda使用

构造器私有,因此调用JdbcConnectionOptionsBuilder.build()进行实例化
- 关系图
- 代码
publicclassSinkToMysql{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);//1.输入DataStreamSource<Event> stream = env.fromElements(newEvent("Mary","./home",1000L),newEvent("Bob","./cart",2000L),newEvent("Alice","./prod?id=100",3000L),newEvent("Bob","./prod?id=1",3300L),newEvent("Alice","./prod?id=200",3000L),newEvent("Bob","./home",3500L),newEvent("Bob","./prod?id=2",3800L),newEvent("Bob","./prod?id=3",4200L));//三个参数,sql,JdbcStatementBuilder构造,JdbcConnectionOptions等sql的连接配置
stream.addSink(JdbcSink.sink("INSERT INTO clicks (user,url) VALUES(?,?)",((statement,event)->{
statement.setString(1,event.user);
statement.setString(2,event.url);}),newJdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl("jdbc:mysql://localhost:3306/test2").withDriverName("com.mysql.jdbc.Driver").withUsername("root").withPassword("123456").build()));
env.execute();}}
- mysql前期准备
- 创建mysql的test2
- 创建clicks表
mysql>createtable clicks(->uservarchar(20)notnull,-> url varchar(100)notnull);
Query OK,0rows affected (0.02 sec)
- 结果

5.5.7 自定义Sink输出
- 分析
调用DataStream的addSink()方法,并传入自定义好的SinkFunction(采用富函数类),重写关键方法invoke(),并且重写富函数类的生命周期相关方法open和close
- 导入依赖
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>${hbase.version}</version></dependency>
- 代码
略
版权归原作者 :Concerto 所有, 如有侵权,请联系我们删除。