
配置环境:
CentOS 7
Hive-3.1.3
Hadoop-3.1.3
Java 1.8
Mysql-5.7.28
1 下载地址
http://archive.apache.org/dist/hive/
2 安装部署
2.1 安装Hive
1)把apache-hive-3.1.3-bin.tar.gz上传到Linux的**/opt/software**目录下
2)解压apache-hive-3.1.3-bin.tar.gz到**/opt/module/**目录下面
tar -zxvf /opt/software/apache-hive-3.1.3-bin.tar.gz -C /opt/module/
3)修改apache-hive-3.1.3-bin.tar.gz的名称为****hive-3.1.3
mv /opt/module/apache-hive-3.1.3-bin/ /opt/module/hive-3.1.3
4)修改**/etc/profile.d/my_env.sh,添加环境变量**
sudo vim /etc/profile.d/my_env.sh
(1)添加内容
#HIVE_HOME
export HIVE_HOME=/opt/module/hive-3.1.3
export PATH=$PATH:$HIVE_HOME/bin
(2)source一下
source /etc/profile.d/my_env.sh
5)初始化元数据库(默认是derby****数据库)
bin/schematool -dbType derby -initSchema
2.2 启动并使用Hive
1)启动Hive
bin/hive
2)使用Hive
hive> show databases;
hive> show tables;
hive> create table stu(id int, name string);
hive> insert into stu values(1,"ss");
hive> select * from stu;
观察HDFS的路径/user/hive/warehouse/stu,体会Hive与Hadoop之间的关系。
Hive中的表在Hadoop中是目录;Hive中的数据在Hadoop中是文件。
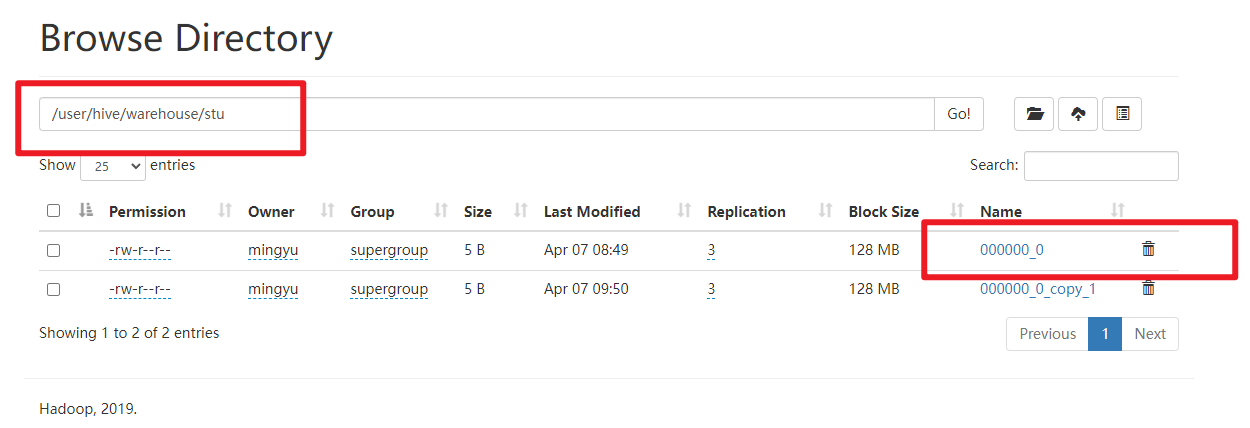
3)在Xshell窗口中开启另一个窗口开启Hive**,在/tmp/atguigu目录下监控hive.log**文件
[atguigu@hadoop102 atguigu]$ tail -f hive.log
Caused by: ERROR XSDB6: Another instance of Derby may have already booted the database /opt/module/hive/metastore_db.
at org.apache.derby.iapi.error.StandardException.newException(Unknown Source)
at org.apache.derby.iapi.error.StandardException.newException(Unknown Source)
at org.apache.derby.impl.store.raw.data.BaseDataFileFactory.privGetJBMSLockOnDB(Unknown Source)
at org.apache.derby.impl.store.raw.data.BaseDataFileFactory.run(Unknown Source)
...
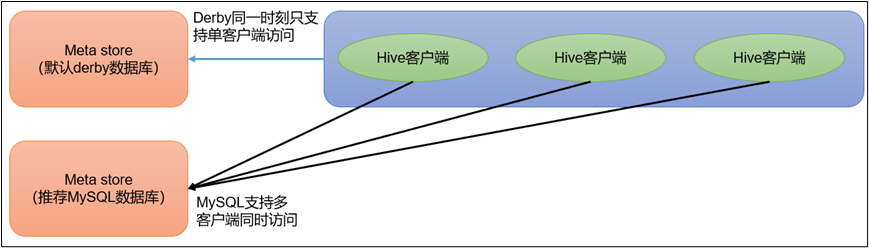
原因在于Hive默认使用的元数据库为**derby**。**derby****数据库的特点是同一时间只允许一个客户端访问。如果多个Hive****客户端同时访问,就会报错。**由于在企业开发中,都是多人协作开发,需要多客户端同时访问Hive,怎么解决呢?我们可以将Hive的元数据改为用MySQL存储,MySQL支持多客户端同时访问。
4)首先退出hive客户端。然后在Hive的安装目录下将derby.log和metastore_db删除,顺便将HDFS****上目录删除
hive> quit;
[atguigu@hadoop102 hive]$ rm -rf derby.log metastore_db
[atguigu@hadoop102 hive]$ hadoop fs -rm -r /user
5)删除HDFS中/user/hive/warehouse/stu中数据
2.3 MySQL安装
2.3.1 安装MySQL
1)上传MySQL安装包以及MySQL驱动jar****包
mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
mysql-connector-java-5.1.37.jar
2)解压MySQL****安装包
[atguigu@hadoop102 software]$ mkdir mysql_lib
[atguigu@hadoop102 software]$ tar -xf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar -C mysql_lib/
3)卸载系统自带的mariadb
[atguigu@hadoop102 ~]$ sudo rpm -qa | grep mariadb | xargs sudo rpm -e --nodeps
4)安装MySQL依赖
依次安装,注意依赖顺序
[atguigu@hadoop102 software]$ cd mysql_lib
[atguigu@hadoop102 mysql_lib]$ sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
[atguigu@hadoop102 mysql_lib]$ sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
[atguigu@hadoop102 mysql_lib]$ sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
5)安装****mysql-client
sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
6)安装****mysql-server
sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
注意:若出现以下错误
warning: 05_mysql-community-server-5.7.16-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY
error: Failed dependencies:
libaio.so.1()(64bit) is needed by mysql-community-server-5.7.16-1.el7.x86_64
解决办法****:
sudo yum -y install libaio
7)启动****MySQL
sudo systemctl start mysqld
8)查看MySQL密码
sudo cat /var/log/mysqld.log | grep password
2.3.2 配置MySQL
配置主要是root用户 + 密码,在任何主机上都能登录MySQL数据库。
1)用刚刚查到的密码进入MySQL(如果报错,给密码加单引号)
mysql -uroot -p'password'
2)设置复杂密码(由于MySQL密码策略,此密码必须足够复杂)
mysql> set password=password("Qs23=zs32");
3)更改MySQL密码策略
validate_password_policy=0 有三种安全策略,0,1,2,0最不安全,2最安全
mysql> set global validate_password_policy=0;
mysql> set global validate_password_length=4;
4)设置简单好记的密码
mysql> set password=password("123456");
5)进入MySQL库
mysql> use mysql
6)查询user表
mysql> select user, host from user;
7)修改user表,把Host表内容修改为**%**
mysql> update user set host="%" where user="root";
8)刷新
mysql> flush privileges;
9)退出
mysql> quit;
2.3.3 卸载MySQL说明
若因为安装失败或者其他原因,MySQL****需要卸载重装,可参考以下内容。
(1)清空原有数据
①通过/etc/my.cnf查看MySQL数据的存储位置
[atguigu@hadoop102 software]$ sudo cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
②去往/var/lib/mysql路径需要root权限
[atguigu@hadoop102 mysql]$ su - root
[root@hadoop102 ~]# cd /var/lib/mysql
[root@hadoop102 mysql]# rm -rf * (注意敲击命令的位置)
(2)卸载MySQL相关包
①查看安装过的MySQL相关包
[atguigu@hadoop102 software]$ sudo rpm -qa | grep -i -E mysql
mysql-community-libs-5.7.16-1.el7.x86_64
mysql-community-client-5.7.16-1.el7.x86_64
mysql-community-common-5.7.16-1.el7.x86_64
mysql-community-libs-compat-5.7.16-1.el7.x86_64
mysql-community-server-5.7.16-1.el7.x86_64
②一键卸载命令
rpm -qa | grep -i -E mysql\|mariadb | xargs -n1 sudo rpm -e --nodeps
2.4 配置Hive元数据存储到MySQL
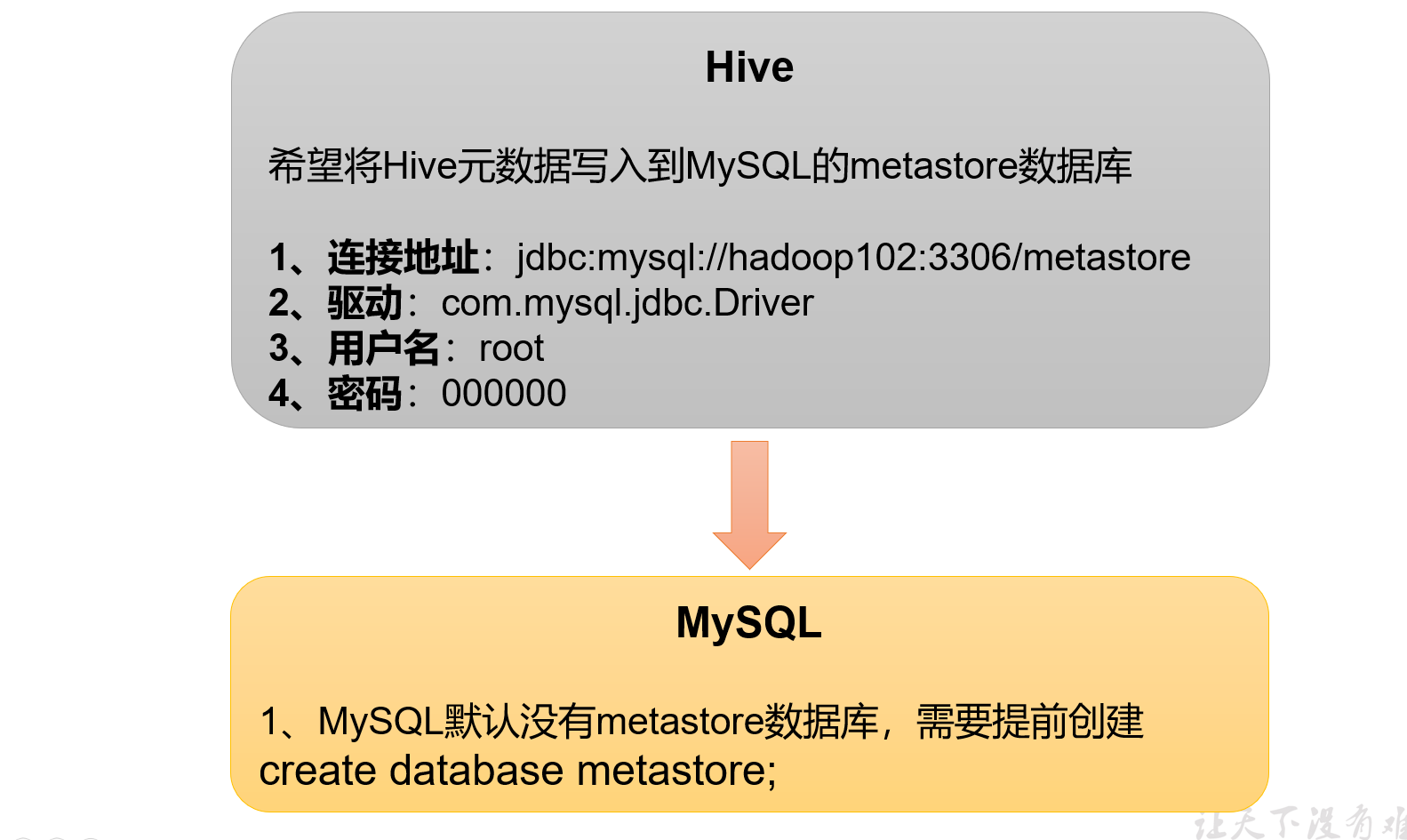
2.4.1 配置元数据到MySQL
1)新建Hive****元数据库
#登录MySQL
[atguigu@hadoop102 software]$ mysql -uroot -p123456
#创建Hive元数据库
mysql> create database metastore;
mysql> quit;
2)将MySQL的JDBC驱动拷贝到Hive的lib目录下。
[atguigu@hadoop102 software]$ cp /opt/software/mysql-connector-java-5.1.37.jar $HIVE_HOME/lib
3**)在$HIVE_HOME/conf目录下新建hive-site.xml**文件
[atguigu@hadoop102 software]$ vim $HIVE_HOME/conf/hive-site.xml
添加如下内容:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
5)初始化Hive元数据库(修改为采用MySQL****存储元数据)
[atguigu@hadoop102 hive]$ bin/schematool -dbType mysql -initSchema -verbose
2.4.2 验证元数据是否配置成功
1)再次启动Hive
[atguigu@hadoop102 hive]$ bin/hive
2)使用Hive
hive> show databases;
hive> show tables;
hive> create table stu(id int, name string);
hive> insert into stu values(1,"ss");
hive> select * from stu;
3)在Xshell窗口中开启另一个窗口开启Hive(两个窗口都可以操作Hive****,没有出现异常)
hive> show databases;
hive> show tables;
hive> select * from stu;
2.4.3 查看MySQL中的元数据
1)登录MySQL
[atguigu@hadoop102 hive]$ mysql -uroot -p123456
2****)查看元数据库metastore
mysql> show databases;
mysql> use metastore;
mysql> show tables;
(1)查看元数据库中存储的库信息
mysql> select * from DBS;
+-------+-----------------------+-------------------------------------------+---------+------------+------------+-----------+
| DB_ID | DESC | DB_LOCATION_URI | NAME | OWNER_NAME | OWNER_TYPE | CTLG_NAME |
+-------+-----------------------+-------------------------------------------+---------+------------+------------+-----------+
| 1 | Default Hive database | hdfs://hadoop102:8020/user/hive/warehouse | default | public | ROLE | hive |
+-------+-----------------------+-------------------------------------------+---------+------------+------------+-----------+
(2)查看元数据库中存储的表信息
mysql> mysql> select * from TBLS;
+--------+-------------+-------+------------------+--------+------------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+
| TBL_ID | CREATE_TIME | DB_ID | LAST_ACCESS_TIME | OWNER | OWNER_TYPE | RETENTION | SD_ID | TBL_NAME | TBL_TYPE | VIEW_EXPANDED_TEXT | VIEW_ORIGINAL_TEXT | IS_REWRITE_ENABLED |
+--------+-------------+-------+------------------+--------+------------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+
| 1 | 1680832178 | 1 | 0 | mingyu | USER | 0 | 1 | stu | MANAGED_TABLE | NULL | NULL | |
+--------+-------------+-------+------------------+--------+------------+-----------+-------+----------+---------------+--------------------+--------------------+--------------------+
(3)查看元数据库中存储的表中列相关信息
mysql> select * from COLUMNS_V2;
+-------+---------+-------------+-----------+-------------+
| CD_ID | COMMENT | COLUMN_NAME | TYPE_NAME | INTEGER_IDX |
+-------+---------+-------------+-----------+-------------+
| 1 | NULL | id | int | 0 |
| 1 | NULL | name | string | 1 |
+-------+---------+-------------+-----------+-------------+
2 rows in set (0.00 sec)
2.5 Hive服务部署
2.5.1 hiveserver2服务
Hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。
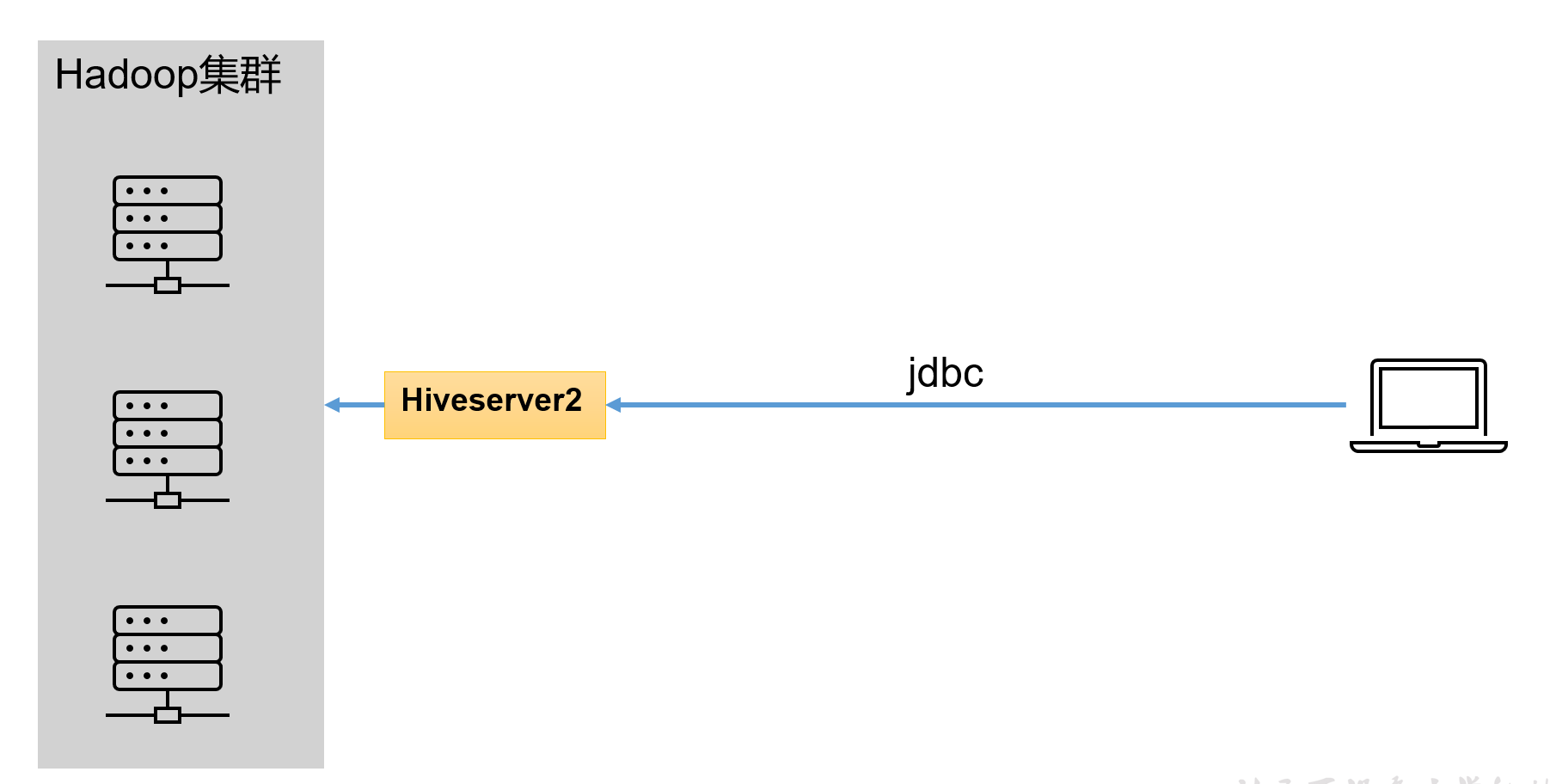
1****)用户说明
在远程访问Hive数据时,客户端并未直接访问Hadoop集群,而是由Hivesever2代理访问。由于Hadoop集群中的数据具备访问权限控制,所以此时需考虑一个问题:那就是访问Hadoop集群的用户身份是谁?是Hiveserver2的启动用户?还是客户端的登录用户?
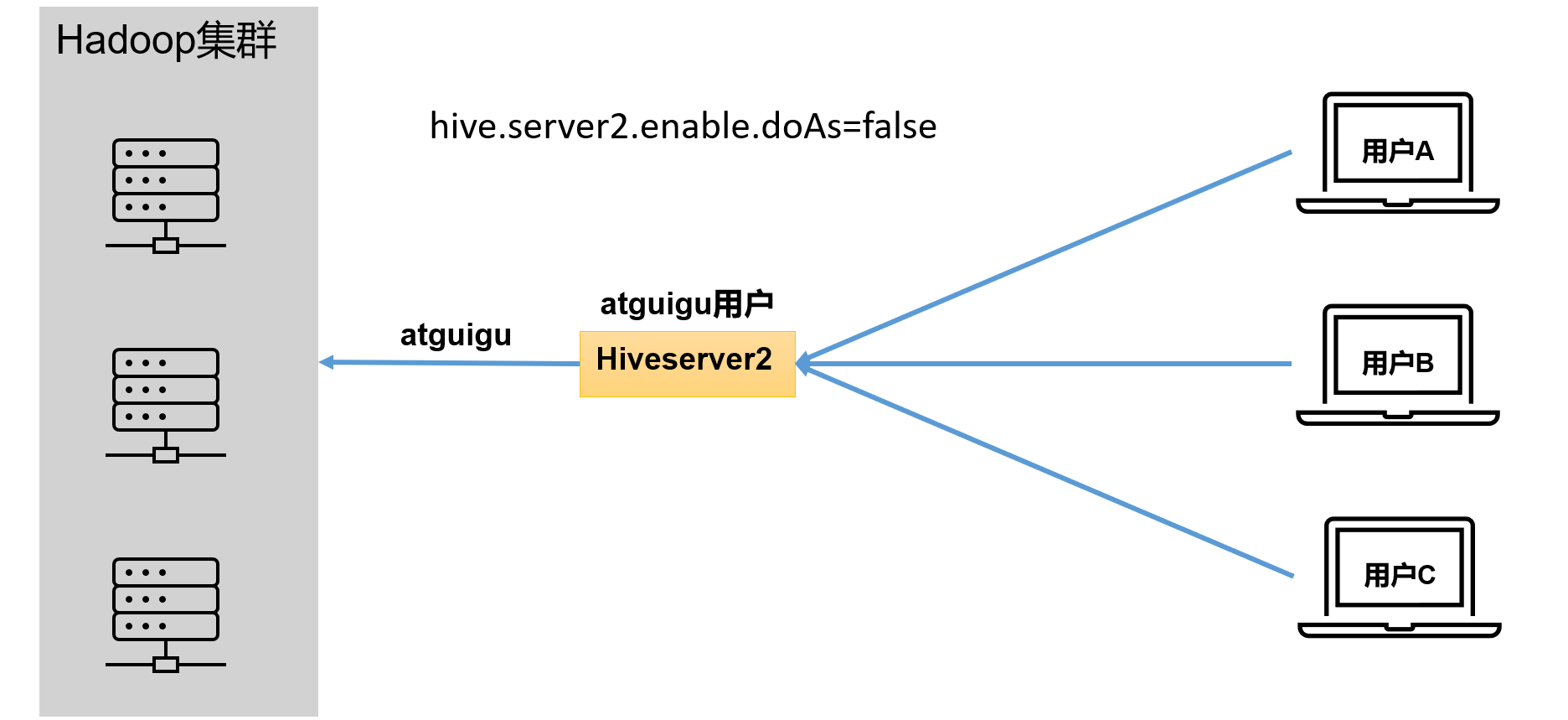
答案是都有可能,具体是谁,由Hiveserver2的**hive.server2.enable.doAs**参数决定,该参数的含义是是否启用Hiveserver2用户模拟的功能。若启用,则**Hiveserver2会模拟成客户端的登录用户去访问Hadoop集群的数据**,不启用,则Hivesever2会直接使用启动用户访问Hadoop集群数据。模拟用户的功能,默认是开启的。
具体逻辑如下:
未开启用户模拟功能:
开启用户模拟功能:
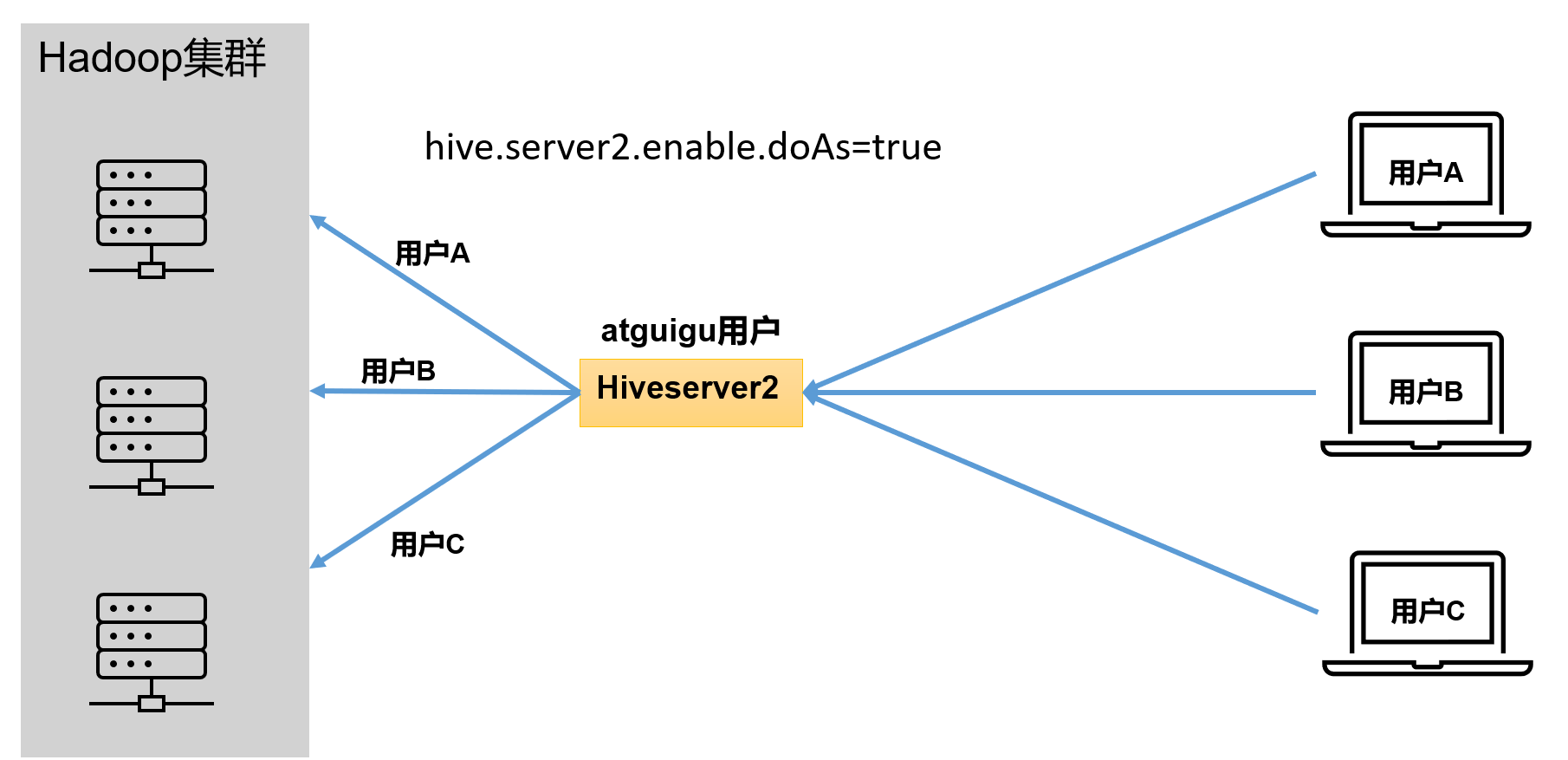
生产环境,推荐开启用户模拟功能,因为开启后才能保证各用户之间的权限隔离。
*2)*hiveserver2部署 **
(1)Hadoop端配置
hivesever2的模拟用户功能,依赖于Hadoop提供的proxy user(代理用户功能),只有Hadoop中的代理用户才能模拟其他用户的身份访问Hadoop集群。因此,需要将hiveserver2的启动用户设置为Hadoop的代理用户,配置方式如下:
修改配置文件core-site.xml,然后记得分发三台机器
[atguigu@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[atguigu@hadoop102 hadoop]$ vim core-site.xml
增加如下配置:
<!--配置所有节点的mingyu用户都可作为代理用户-->
<property>
<name>hadoop.proxyuser.mingyu.hosts</name>
<value>*</value>
</property>
<!--配置mingyu用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.mingyu.groups</name>
<value>*</value>
</property>
<!--配置mingyu用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.mingyu.users</name>
<value>*</value>
</property>
(2)Hive端配置
在hive-site.xml文件中添加如下配置信息
[atguigu@hadoop102 conf]$ vim hive-site.xml
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
3****)测试
(1)启动hiveserver2
bin/hive --service hiveserver2
不想出现阻塞式进程,可以使用以下代码代替
nohup bin/hiveserver2 >/dev/null 2>&1 &
 ** 解释:**
** 解释:**
nohup:表示不挂断地运行命令,即使终端关闭或用户注销,该命令也会继续在后台运行。bin/hiveserver2:是要运行的 HiveServer2 可执行文件的路径。>/dev/null:将标准输出重定向到/dev/null,这是一个特殊的设备文件,所有写入它的数据都会被丢弃。2>&1:将标准错误输出重定向到标准输出,这样可以将错误输出也丢弃到/dev/null。&:将命令放入后台运行,使命令执行后立即返回命令提示符,而不会阻塞当前终端会话。
综合来说,这条命令的含义是在后台启动 HiveServer2 进程,并将其输出和错误输出都重定向到
/dev/null
,从而在后台静默运行 HiveServer2 进程,不产生任何输出。
/dev/null 也就是黑洞
(2)使用命令行客户端beeline进行远程访问
启动beeline客户端
bin/beeline -u jdbc:hive2://hadoop102:10000 -n mingyu
看到如下界面
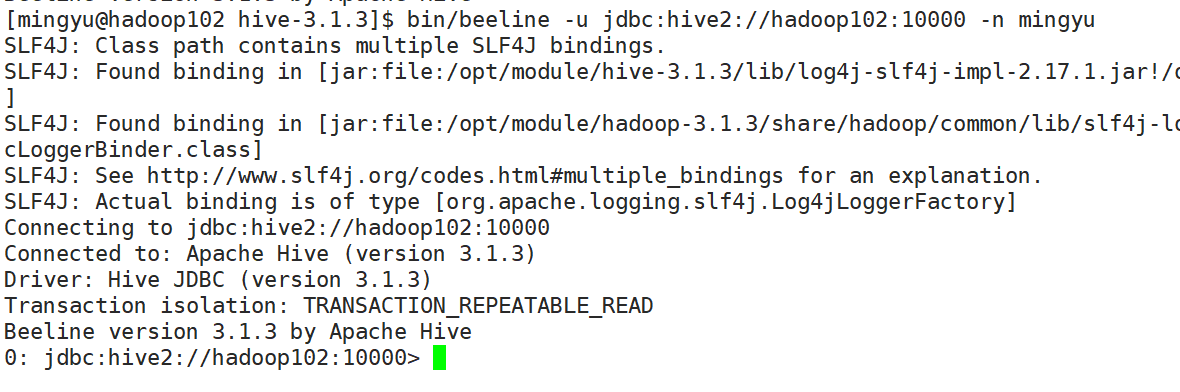
连接hiveserver2
0: jdbc:hive2://hadoop102:10000> !connect jdbc:hive2://hadoop102:10000
看到
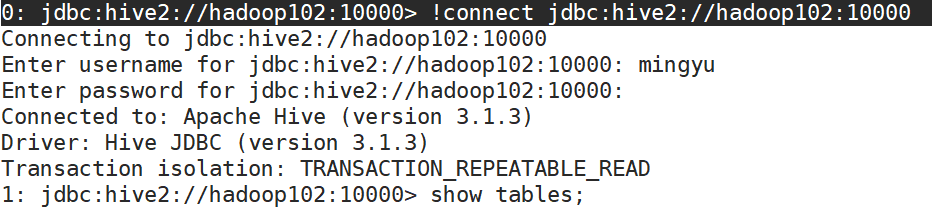
使用
1: jdbc:hive2://hadoop102:10000> show tables;
查看所有表格
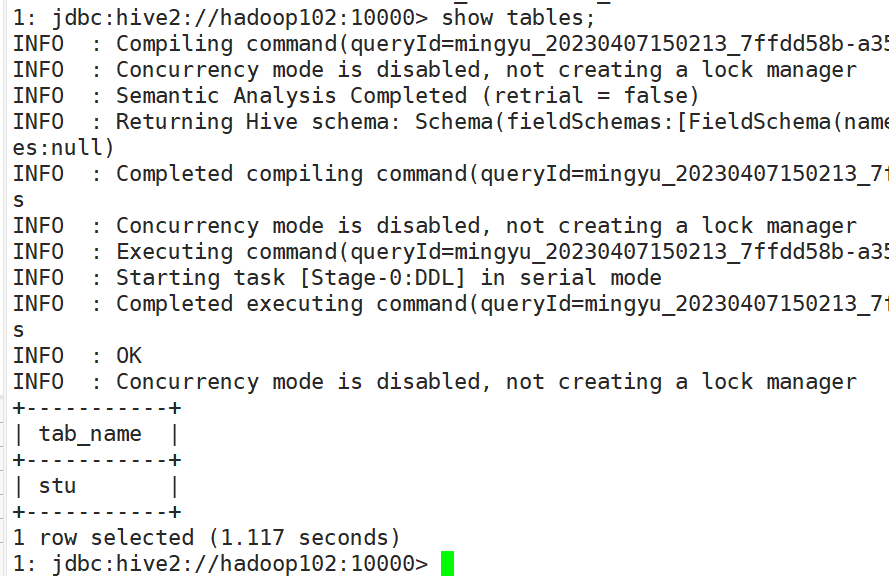
(3)使用Datagrip图形化客户端进行远程访问
打开DataGrip,新建连接
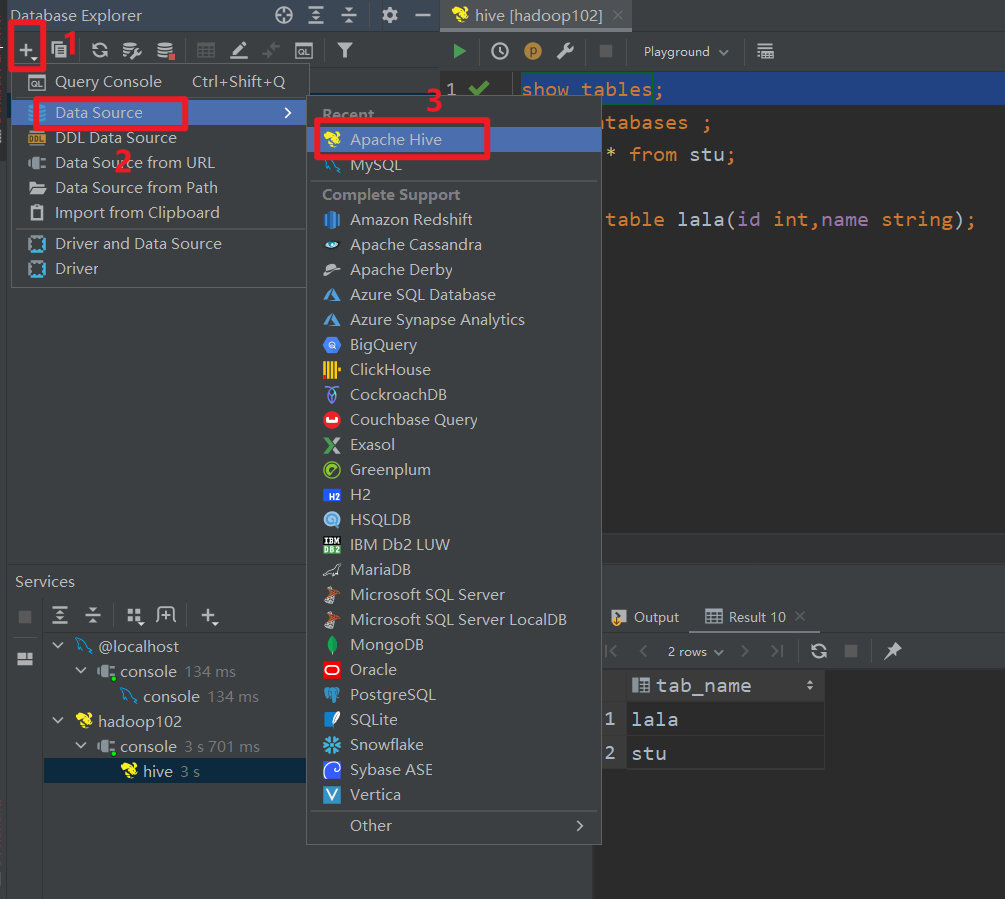
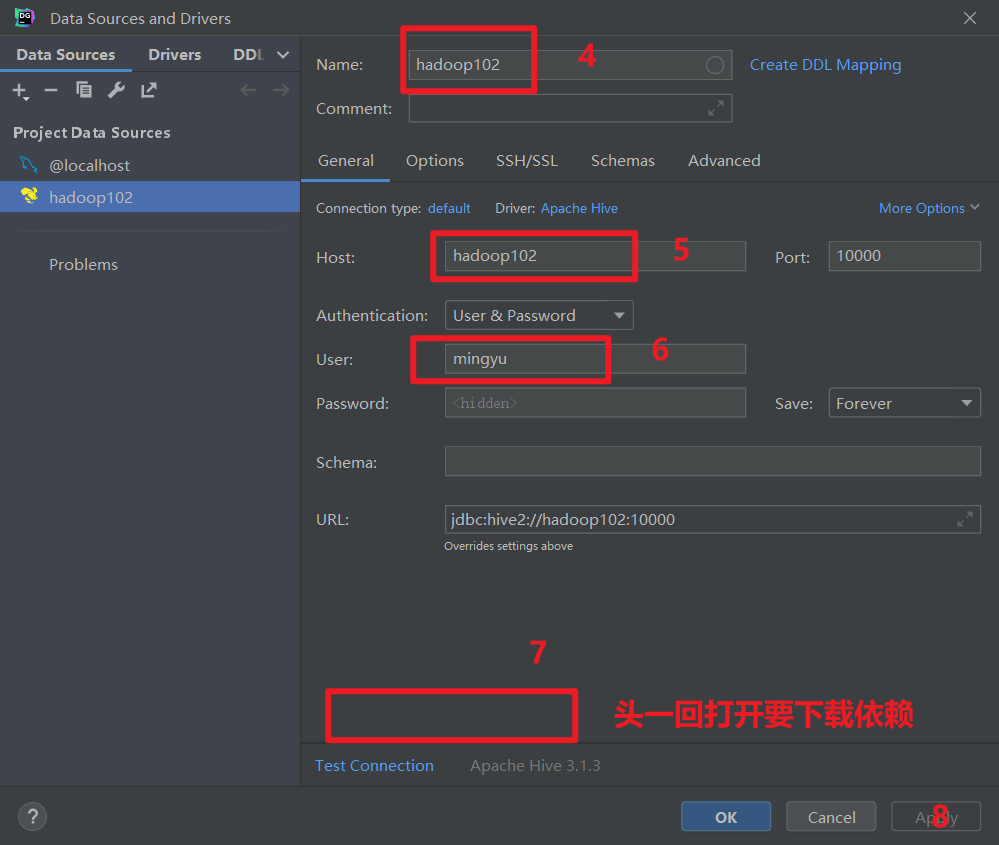
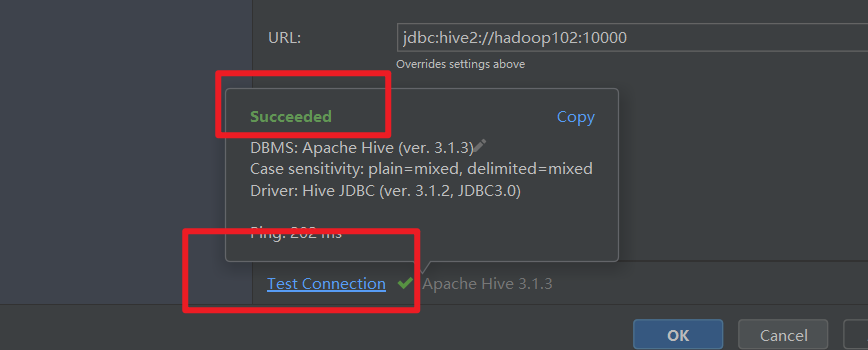
测试连接
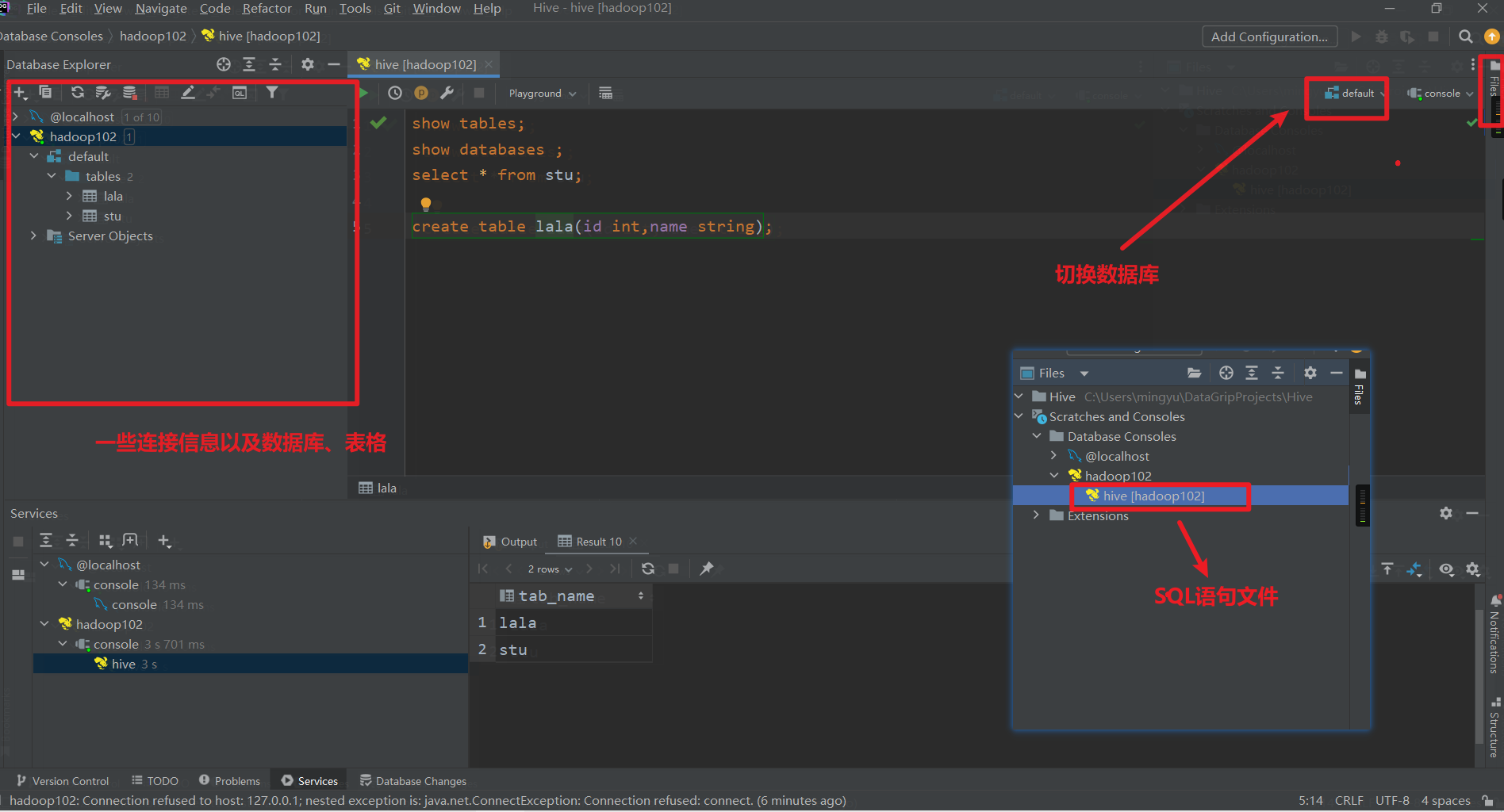
界面相关功能
2.5.2 metastore服务
Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口。
1)metastore****运行模式
metastore有两种运行模式,分别为嵌入式模式和独立服务模式。下面分别对两种模式进行说明:
(1)嵌入式模式
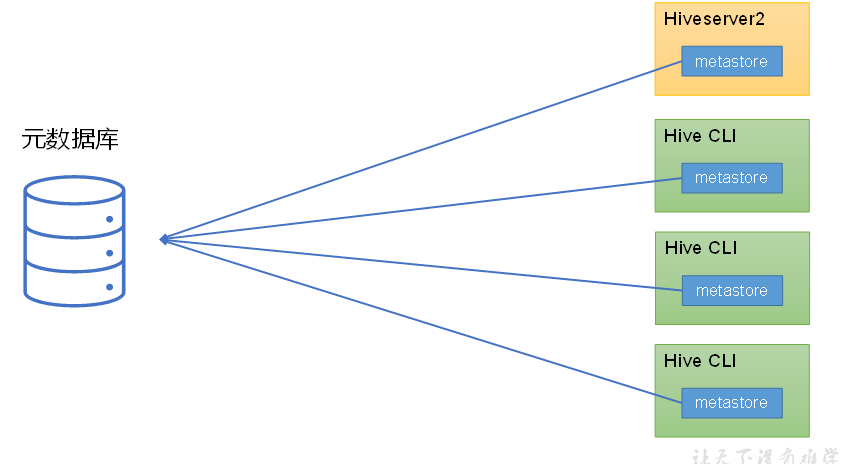
(2)独立服务模式
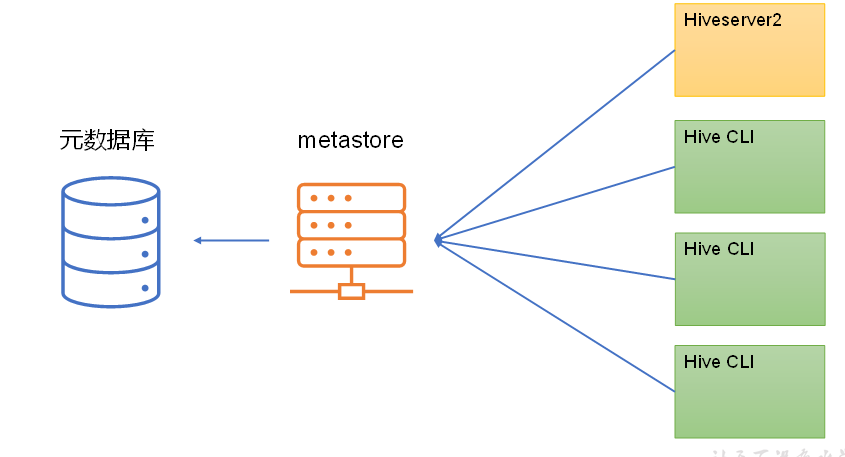
生产环境中,不推荐使用嵌入式模式。因为其存在以下两个问题:
(1)嵌入式模式下,每个Hive CLI都需要直接连接元数据库,当Hive CLI较多时,数据库压力会比较大。
(2)每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证。
2)metastore****部署
(1)嵌入式模式(个人测试)
嵌入式模式下,只需保证Hiveserver2和每个Hive CLI的配置文件hive-site.xml中包含连接元数据库所需要的以下参数即可:
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
(2)独立服务模式
独立服务模式需做以下配置:
首先,保证运行metastore服务所在节点的配置文件hive-site.xml中包含连接元数据库所需的以下参数:
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
其次,保证Hiveserver2和每个Hive CLI的配置文件hive-site.xml中包含访问metastore服务所需的以下参数:
<!-- 指定metastore服务的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
注意:主机名需要改为metastore服务所在节点,端口号无需修改,metastore服务的默认端口就是9083。
3****)测试
此时启动Hive CLI,执行shou databases语句,会出现一下错误提示信息:
hive (default)> show databases;
FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
这是因为我们在Hive CLI的配置文件中配置了hive.metastore.uris参数,此时Hive CLI会去请求我们执行的metastore服务地址,所以必须启动metastore服务才能正常使用。
metastore服务的启动命令如下:
[atguigu@hadoop202 hive]$ hive --service metastore
2022-04-24 16:58:08: Starting Hive Metastore Server
或者后台挂载该服务
nohup hive --service metastore >/dev/null 2>&1 &
注意:启动后该窗口不能再操作,需打开一个新的Xshell窗口来对Hive操作。
重新启动 Hive CLI,并执行shou databases语句,就能正常访问了
bin/hive
2.5.3 编写Hive服务启动脚本(了解)
前台启动的方式导致需要打开多个Xshell窗口,可以使用如下方式后台方式启动
- nohup:放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态
- /dev/null:是Linux文件系统中的一个文件,被称为黑洞,所有写入该文件的内容都会被自动丢弃
- 2>&1:表示将错误重定向到标准输出上
- &:放在命令结尾,表示后台运行
- 一般会组合使用:nohup [xxx命令操作]> file 2>&1 &,表示将xxx命令运行的结果输出到file中,并保持命令启动的进程在后台运行。
[atguigu@hadoop202 hive]$ nohup hive --service metastore 2>&1 &
[atguigu@hadoop202 hive]$ nohup hive --service hiveserver2 2>&1 &
为了方便使用,可以直接编写脚本来管理服务的启动和关闭
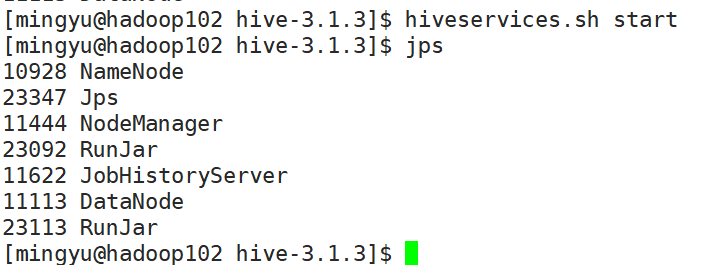
[atguigu@hadoop102 hive]$ vim $HIVE_HOME/bin/hiveservices.sh
内容如下:此脚本的编写不要求掌握。直接拿来使用即可。
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
2.6 Hive使用技巧
2.6.1 Hive常用交互命令
[atguigu@hadoop102 hive]$ bin/hive -help
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the console)
1)在Hive命令行里创建一个表student,并插入1****条数据
2**)“-e”不进入hive的交互窗口执行hql**语句
[atguigu@hadoop102 hive]$ bin/hive -e "select id from student;"
3**)“-f”执行脚本中的hql**语句
(1)在/opt/module/hive/下创建datas目录并在datas目录下创建hivef.sql文件
[atguigu@hadoop102 hive]$ mkdir datas
[atguigu@hadoop102 datas]$ vim hivef.sql
(2)文件中写入正确的hql语句
select * from student;
(3)执行文件中的hql语句
[atguigu@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql
(4)执行文件中的hql语句并将结果写入文件中
[atguigu@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql > /opt/module/hive/datas/hive_result.txt
2.6.2 Hive参数配置方式
1****)查看当前所有的配置信息
hive>set;
2****)参数的配置三种方式
(1)****配置文件方式
- 默认配置文件:hive-default.xml(弃用)
- 用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
(2****)命令行参数方式
①启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。例如:
[atguigu@hadoop103 hive]$ bin/hive -hiveconf mapreduce.job.reduces=10;
注意:仅对本次Hive启动有效。
②查看参数设置
hive (default)> set mapreduce.job.reduces;
(3****)参数声明方式
可以在HQL中使用SET关键字设定参数,例如:
hive(default)> set mapreduce.job.reduces=10;
注意:仅对本次Hive启动有效。
查看参数设置:
hive(default)> set mapreduce.job.reduces;
上述三种设定方式的优先级依次递增。即配置文件** < ****命令行参数 < **参数声明。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
2.6.3 Hive常见属性配置
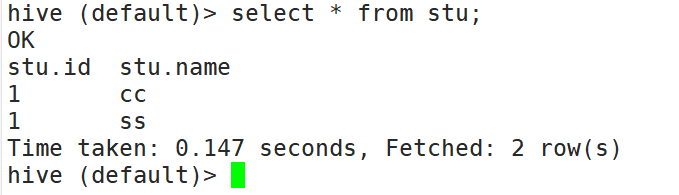
1)Hive****客户端显示当前库和表头
(1)在hive-site.xml中加入如下两个配置**:**
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>
(2)hive客户端在运行时可以显示当前使用的库和表头信息
2)Hive****运行日志路径配置
(1)Hive的log默认存放在**/tmp/mingyu/hive.log**目录下(当前用户名下)

(2)修改Hive的log存放日志到**/opt/module/hive/logs**
1修改**$HIVE_HOME/conf/hive-log4j2.properties.template**文件名称为
hive-log4j2.properties
mv hive-log4j2.properties.template hive-log4j2.properties
2在hive-log4j2.properties文件中修改log存放位置
vim hive-log4j2.properties
修改配置如下
property.hive.log.dir=/opt/module/hive/logs
3)Hive的JVM****堆内存设置
新版本的Hive启动的时候,默认申请的JVM堆内存大小为256M,JVM堆内存申请的太小,导致后期开启**本地模式**,执行复杂的SQL时经常会报错:java.lang.OutOfMemoryError: Java heap space,因此最好提前调整一下HADOOP_HEAPSIZE这个参数。
(1)修改$HIVE_HOME/conf下的hive-env.sh.template为hive-env.sh
[atguigu@hadoop102 conf]$ pwd
/opt/module/hive/conf
[atguigu@hadoop102 conf]$ mv hive-env.sh.template hive-env.sh
(2)将hive-env.sh其中的参数** export HADOOP_HEAPSIZE修改为2048**,重启Hive。
修改前
# The heap size of the jvm stared by hive shell script can be controlled via:
# export HADOOP_HEAPSIZE=1024
修改后
# The heap size of the jvm stared by hive shell script can be controlled via:
export HADOOP_HEAPSIZE=2048
4)关闭Hadoop****虚拟内存检查
在yarn-site.xml中关闭虚拟内存检查(虚拟内存校验,如果已经关闭了,就不需要配了)。
(1)修改前记得先停Hadoop
(2)添加如下配置
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
(3)修改完后记得分发yarn-site.xml,并重启yarn。
版权归原作者 一抹鱼肚白 所有, 如有侵权,请联系我们删除。