
优质博文:IT-BLOG-CN
一、为什么要备份
【1】容灾恢复:硬件故障、不经意的 Bug 导致数据损坏,或者服务器及其数据由于某些原因不可获取或无法使用等(例如:机房大楼烧毁,恶意的黑客攻击或 Mysql 的 Bug 等)。
【2】人们改变想法:很多人经常会在删除某些数据后,又想恢复这些数据。
【3】审计:有时需要知道数据或 Schema 在过去的某个时间点的状态和数据,或发现了应用的一个 Bug,想知道在此之前发生了什么等等。
【4】测试:定期使用生产数据来更新测试服务器(备份是为了恢复,这样也可以验证备份的数据是否完整,是否能够正常还原等)。如果备份的方案非常简单,只需要将备份文件还原到测试服务器上即可。
规划备份和恢复策略时,有两个重要的需求:恢复点目标(RPO)定义了可以容忍丢失多少数据,恢复时间目标(RTO)定义了需要等待多久将数据恢复。
二、在线备份还是离线备份
如果可以,关闭 MySQL 做备份是最简单安全的,也是获取一致性最好的方法,而且损坏和不一致的风险最小。根本不用关心 InnoDB 缓冲池中的脏页或其他缓存。也不需要担心数据在尝试备份的过程中被修改,并且因服务器不对应用提供访问,因此会更快的完成备份。
但在高负载和高数据量下关闭和重启 MySQL 可能要花很长一段时间,即使最小化停顿时间,服务器停机的代价也会很昂贵。因此需要在线备份。即便如此,由于一致性的需要,对服务器进行在线备份,仍然会有明显的服务中断。MyISAM 在线备份的一个最大问题是使用 FLUSH TABLES WITH READ LOCK(关闭所有打开的表并使用全局读锁锁定所有数据库的所有表,不会刷新脏块) 操作,这会导致 MySQL 关闭并锁住所有的表,将 MyISAM 的数据文件刷新到磁盘上,并且刷新查询缓存。该操作需要非常长的时间,具体需要多久不可预估。因为如果一个会话中使用表锁(LOCK TABLES tbl_name lock_type)语句对某表加了表锁,在该表锁未释放前,那么另外一个会话如果执行 FLUSH TABLES WITH READ LOCK 也会被堵塞。除非锁被释放,否则不能在服务器上更改任何数据。 FLUSH TABLES WITH READ LOCK 不像关闭服务器代价那么高,因为大部分缓存仍然在内存中,并且服务器一直是“预热”状态,但是它也有非常大的破坏性。避免使用 FLUSH TABLES WITH READ LOCK 的最好办法是只使用 InnoDB 表。
【在规划备份时,有一些与性能相关的因素需要考虑】:
■ 锁时间:需要持有锁多长时间,例如在备份期间持有的全局 FLUSH TABLES WITH READ LOCK ?
■ 备份时间:复制备份到目的地需要多久。
■ 备份负载:在复制备份到目的地时对服务器性能的影响是多少?
■ 恢复时间:把备份镜像从存储位置复制到 MySQL 服务器,重放二进制日志等,需要多久?
最大的权衡是备份时间与备份负载。可以牺牲其一以增强另外一个。例如,可以降低服务器性能,来提高备份的优先级。
三、逻辑备份还是物理备份
逻辑备份(也叫“导出”)和直接复制原始文件的物理备份。逻辑备份将数据包含在一种 MySQL 能够解析的格式中,要么是 SQL,要么是以某个符号分隔的文本。原始文件是指存在硬盘上的文件。
【1】逻辑备份,优点如下:
■ 逻辑备份可以用编辑器或像 grep 和 sed 之类的命令查看和操作的普通文件。当需要恢复数据或只想查看数据但不恢复时,这都非常有帮组。
■ 恢复非常简单。可以通过管道把他们输入到 mysql,或者使用 mysqlimport。
■ 通过网络来备份和恢复,相当于在与 MySQL 主机不同的另外一台机器上操作。
■ 可以在类似 Amazon RDS(关系型数据库服务) 这种不能访问底层文件系统的系统中使用。
■ 非常灵活,因为 mysqldump(大部分人都喜欢的工具)可以接受许多选项,例如可以用 WHERE 子句来限制需要备份的数据。
■ 与存储引擎无关。因为是从 MySQL 服务器中提取数据而生成,所以消除了底层数据存储的不同。因此可以从 InnoDB 表中备份,然后只需要极小的工作量就可以还原到 MYISAM 表中。而原始数据却不能这么做。
■ 有助于避免数据损坏。如果磁盘驱动器有故障需要复制原始文件时,将得到一个错误或部分损坏的备份。如果 MySQL 在内存中的数据还没有损坏,可以得到一个可以信赖的逻辑备份。
【逻辑备份的缺点如下】:
■ 必须由数据库服务器完成生成逻辑备份工作,因此要使用更多的 CPU 周期。
■ 无法保证导出后再还原出来的一定时同样的数据。浮点表示问题、软件 Bug 等都会导致问题,尽管非常少见。
■ 从逻辑备份中还原需要 MySQL 加载和解释语句,转化为存储格式,并重建索引,所有这一切都会很慢。
最大的缺点是从 MySQL 中导出数据和通过 SQL 语句将其加载回去的开销。如果使用逻辑备份,测试恢复需要的时间将非常重要。Percona Server 中包含的 mysqldump 在使用 InnoDB 表时能起到帮组作用,因为它会对输出格式化,以便在重新加载时利用 InnoDB 的快速建索引的优点。我们测试显示这样做可以减少 2/3 甚至更多的还原时间。索引越多,好处越明显。
【2】物理备份,优点如下:
■ 基于文件的物理备份,只需要将需要的文件复制目标地址即可完成备份。不需要其他额外的工作来生成原始文件。
■ 物理备份的恢复可能更简单,取决于存储引擎。对于 MyISAM 只需要简单的复制文件到目的地即可。对于 InnoDB 则需要停止数据库服务,可能还要采取其他一些步骤。
■ InnoDB 和 MyISAM 的物理备份非常容易跨平台、操作系统和 MySQL 版本。
■ 从物理备份中恢复会更快,因为不需要执行任何 SQL 和构建索引。如果有很大的 InnoDB 表,无法完全缓存再内存中,则物理备份的恢复要快非常多,只是要快一个数量级。事实上,逻辑备份最可怕的地方就是不确定的还原时间。
【物理备份的缺点如下】:
■ InnoDB 的原始文件通常比相应的逻辑备份要大的多。InnoDB 的表空间往往包含很多未使用的空间。还有很多空间被用来做存储以外的用途(插入缓冲,回滚段等)。
■ 物理备份不总是可以跨平台、操作系统及 MySQL 版本。文件名大小写敏感和浮点格式是可能会遇到的麻烦。很可能因浮点格式不同而不能移动文件到另一个系统。
物理备份简单高效,但也容易出错。尽管如此对于长期保留的备份,还是很适合的。但尽量不要完全依赖物理备份。至少每隔一段时间还是需要做一次逻辑备份。建议混合使用物理和逻辑两种方式来做备份:先使用物理复制,以此数据启动 MySQL 服务器实例并运行 mysqlcheck。然后周期性地使用 mysqldump 执行逻辑备份。这样做可以获得两种方法的优点,不会使生产服务器在导出时过度负担。如果能够利用文件系统的快照,也可以生成一个快照,将该快照复制到另一个服务器上并释放,然后测试原始文件,再执行逻辑备份。
备份文件一定要经过数据恢复测试,特别是物理备份。不要自认为数据备份是正常的,这样容易酿成大错。对 InnoDB 来说,这意味着需要启动一个 MySQL 实例,执行 InnoDB 恢复操作,然后执行 CHECK TABLES。也可以跳过这一操作,仅对文件运行 innochecksum(是一个用于校验 innodb 表空间文件完整性的工具,是一个官方自带的工具),但不建议这样做。
四、增量备份和差异备份
当数据量很庞大时,一个常见的策略是做定期的增量或差异备份。差异备份是对自上次全量备份后所有改变的部分而做的备份,而增量备份则是从任意类型的上次备份后所有修改做的备份。
::: tip
例如,周日做一个全备份,在周一,对周日以来所有的改变做一个差异备份。在周二,就有两个选择:备份自周日以来所有的改变(差异),或只备份自从周一备份后所有的改变(增量)
:::
两者都是部分备份能够减少服务器开销(不一定:例如,Percona XtraBackup 和 MySQL Enterprise Backup,仍会扫描服务器上的所有数据块,因而并不会节约太多时间的开销)、备份时间以及备份空间。
■ 使用 Percona XtraBackup 和 MySQL Enterprise Backup 等软件中的增量备份特性。
■ 备份二进制日志。可以在每次备份后使用 FLUSH LOGS 来开始一个新的二进制日志,这样就只需要备份新的二进制日志。
■ 不要备份没有改变的表。MyISAM 引擎会记录每个表最后修改时间。可以通过查看磁盘上的文件或运行 SHOW TABLE STATUS 来看这个时间。如果使用 InnoDB 可以利用触发器记录修改时间到一个表中。
■ 不要备份没有改变的行。如果一个表只是做插入,可以增加一列(时间戳),然后只备份自上次备份后插入的行。
■ 备份所有数据,然后发送到一个有去重特性的目的地,例如 ZFS 文件管理程序。
增量备份的缺点: 增加恢复复杂性,额外的风险,以及更长的恢复时间。如果可以全备,考虑到简便性,尽量经常做全备。建议至少一周一次,周内通过增量的方式进行备份。
五、备份什么
最简单的策略是只备份数据和定义表,但这是一个最低的要求。在生产环境中恢复数据库一般需要更多的工作,例如:
【1】非显著数据: 不要忘记那些容易被忽略的数据,例如:二进制日志和 InnoDB 事务日志等。
【2】代码: MySQL 服务器可以存储许多代码,例如触发器和存储过程。如果备份了 MySQL数据库,大部分这类代码也就备份了,但此时如果还原单个业务数据库会比较麻烦。
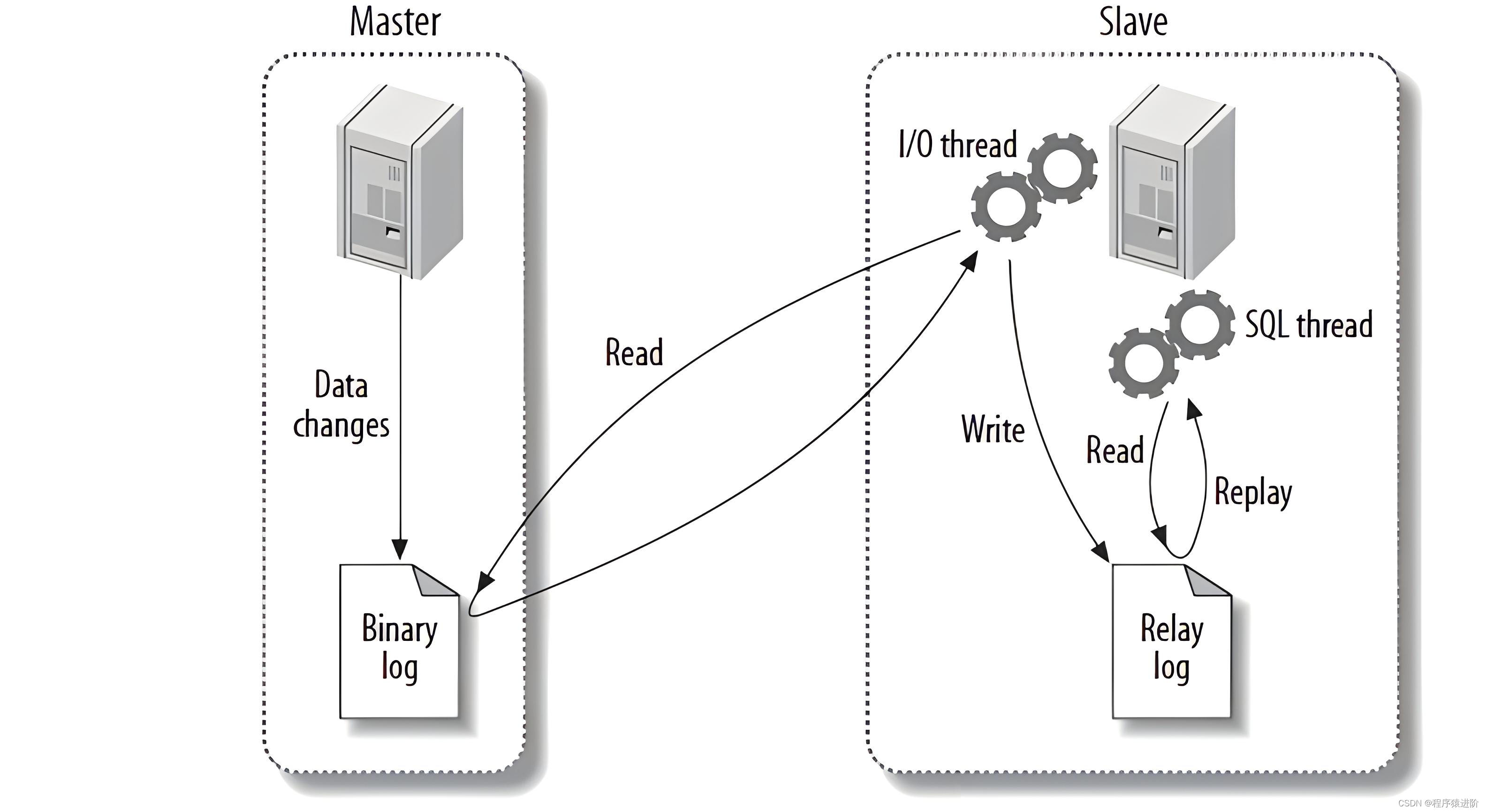
【3】复制配置: 如果恢复一个设计复制关系的服务器,应该备份所有与复制相关的文件(二进制日志、中继日志、日志索引文件和.info 文件)。至少应该包含 SHOW MASTER STATUS 和 SHOW SLAVE STATUS 的输出。执行 FLUSH LOGS 也非常有好处,可以让 MySQL 从一个新的二进制日志开始。从日志文件的开头做基于故障时间点的恢复要比从中间更容易。
【4】服务器配置: 如果需要从灾难中恢复,这时需要在新数据中心构建服务器,如果此时备份中包含服务器配置会免去很多工作。
【5】选定的操作系统文件: 对于服务器配置来说,备份中对生产服务器至关重要的任务外部配置,都十分重要。在 UNIX 服务器上,这可能包括 cron 任务(实现 linux 定时任务)、用户和组的配置、管理脚本,以及 sudo(是 linux 系统管理指令,是允许系统管理员让普通用户执行一些或者全部的 root 命令的一个工具) 规则。
六、存储引擎和一致性
MySQL 对存储引擎的选择会导致备份明显更复杂。如何对给定的存储引擎后,得到一致的备份。实际上有两类一致性需要考虑:数据一致性和文件一致性。
【1】数据一致性: 当备份时,应该考虑是否需要数据在指定时间点一致。例如,淘宝中的发货单和付款之间的一致性。付款时如果不考虑其发货单,或反过来都会导致麻烦。
如果做在线备份,可能需要所有相关表的一致性备份。InnoDB 的多版本控制功能可以帮助我们。开始一个事务,转储(存储)一组相关的表,然后提交事务。再要在服务器上使用 REPEATABLE READ 事务隔离级别,并且没有任何 DDL,就一定会有完美的一致性,以及基于时间点的快照数据,且在备份过程中不会阻塞任何后续工作。如果不是事务型存储引擎,则只能在备份时用LOCK TABLES 来锁住所有要一起备份的表,备份完后在释放锁。
也可以用 mysqldump 来获得 InnoDB 表的一致性逻辑备份,采用 --single-transaction 选项。但可能会导致一个很长的事务,在某些负载下会导致开销大到不可接受。
【2】文件一致性: 所有备份的文件相互之间应该一致,包括每个文件的内部一致性也非常重要。如果是在不同的时间复制相关文件,他们彼此可能也不一致。MyISAM 的 .MYD 和 .MYI 文件就是个栗子。InnoDB 检测到不一致或损坏,会记录错误日志直到让服务器崩溃。
对于非事务型存储引擎 MyISAM,需要锁表并刷新表。这意味着要么用 LOCK TABLES 和 FLUSH TABLES 结合的方法以使服务器将内存中的变更刷新到磁盘上,要么使用 FLUSH TABLES WITH READ LOCK。一但刷新完成,就可以安全地复制 MyISAM 的原始文件。
对于事务型存储引擎 InnoDB,确保文件的一致性比较困难。即使使用 FLUSH TABLES WITH READ LOCK,InnoDB 依旧在后台运行:插入缓存、日志和写线程继续将变更合并到日志和表空间文件中。这些线程设计上是异步的(这也是InnoDB 取得更高并发性的原因)与 LOCK TABLES 无关。因此,不仅需要确保每个文件内部是一致的,还需要同时复制同一个时间点的日志和表空间。如果在备份时有其他线程在修改文件,或备份表空间与日志文件时间点不同,会在恢复后再次因系统损坏而告终。可以通过如下几个方法规避这个问题:
■ 等待直到 InnoDB 清除线程和插入缓冲合并线程完成。可以观察 SHOW INNODB STATUS 的输出,当没有脏缓存或挂起的写时,就可以复制文件。尽管如此,这种方法可能需要很长一段时间;因为 InnoDB 的后台线程涉及太多的干扰而不太安全。不推荐使用。
■ 在一个类似 LVM(Logical Volume Manager:逻辑卷管理)的系统中获取数据和日志文件的快照,必须让数据和日志文件在快照中是相互一致;单独取它们的快照是没有意义的。
■ 方式一个 STOP 信号给 MySQL,做备份,然后在发送一个 CONT 信号来再次唤醒 MySQL。看起来像是一个很少推荐方式,但如果另一种方法是在备份过程中需要关闭服务器,则这种方法值得考虑。至少这种技术不需要重启服务器后预热。
在复制数据到其他地方后,就可以释放锁以使 MySQL 服务器再次正常运行。同时,也可以从备库中备份,这样的好处是可以不干扰主库,避免在主库上增加额外的负载。
版权归原作者 程序猿进阶 所有, 如有侵权,请联系我们删除。