
在实际使用Datax的时候,可能会使用Datax同步mysq数据到mysql,实现数据库跨库同步或者多个mysql之间相互同步,那么怎么实现呢?我们一步步来实现(基于Datax 3.0.0)
1、检查环境,需要安装完一个Datax
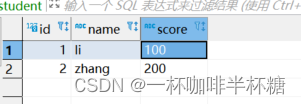
2、在mysql中创建源表和目标表,并在原表中插入数据,我们的目标是把源表的mysql数据同步到目标表中,我们当前测试表如下(注意,数据库的源表以及目标表都需要有,Datax不会帮你创建)
源数据库:test
源表结构:
CREATE TABLE
student(
idbigint(20) NOT NULL AUTO_INCREMENT,
namevarchar(100) DEFAULT NULL,
scorevarchar(100) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
插入数据如下
目标数据库名:datax
目标表
CREATE TABLE
test(
idbigint(20) NOT NULL AUTO_INCREMENT,
namevarchar(100) DEFAULT NULL,
scorevarchar(100) DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8
3、我们在安装Datax的服务器上创建json文件,我们文件创建在/opt/datax/job目录下,开发者可自定义保存文件路径
vim mysql2mysql.json
4、文件内容如下(需要修改的或者重要的已标红,大家直接修改即可)
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "mysql登录用户名",
"password": "mysql登录密码",
"connection": [
{
"querySql": [
"select id,name from student;"
],
"jdbcUrl": [
"jdbc:mysql://node01:3306/test"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "mysql登录用户名",
"password": "mysql登录密码",
"column": [
"id",
"name"
],
"preSql": [
"delete from test"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://node01:3306/datax?useUnicode=true",
"table": [
"test"
]
}
]
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
标红解释如下:
jdbcUrl:数据库的jdbcurl链接
username:mysql用户名
password:mysql用户登陆密码
querySql:mysqlreader中的参数,用作自定义sql,根据sql的灵活编写实现数据的增量、全量、特定列数据的同步,注意需要sql和mysqlwriter中的column字段数量、名称、类型需要对应上
column:mysqlwriter中的配置,写出你要写入目标表的列
preSql:在写入目标表的时候执行的语句,我们写了删除表中数据,这样才能保证目标表中没有脏数据
table:目标表名称
channel:执行的并行度,写大点性能会提高一些,不过要根据实际情况合理配置,数据量少1个够了
5、执行Datax,首先去到Datax的bin目录,然后执行
./datax.py /opt/datax/job/mysql2mysql.json
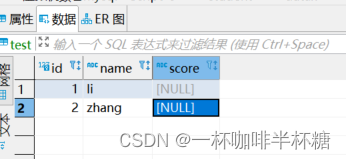
6、看到如下则证明执行成功

再看数据库已经同步成功了
版权归原作者 一杯咖啡半杯糖 所有, 如有侵权,请联系我们删除。