
1:grep命令
使用grep命令可以查找文件内符合条件的字符串
语法:grep 【选项】 【查找值】 【文件名】
-E:是一个可扩展的正则表达式
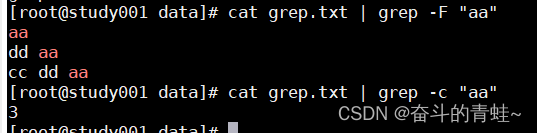
-F:是一组由断行符分割的定长字符串
-c:只显示匹配行的数量
-i:不区分大小写
-n:在输出前加上匹配字符串所在行的行号
-v:只显示不匹配字符串的一行
grep -E 后可跟正则表达
grep -n "aa" 显示匹配值所在的行

grep -in ”ee“ 不区分大小写 显示匹配值所在的行(默认区分大小写)
grep -inv ”ee" 不区分大小写显示不匹配值所在的行




2:awk命令
awk命令是一种文本处理语言,逐行读取文件内容,默认以空格做分隔符
格式:awk 【选项】 'BEGIN{命令} pattern{命令} END{命令}' 文件
**BEGIN:**BEGIN后跟的是开始程序代码块,只会执行一次,一般初始化一些参数【可选】
pattern:pattern boby部分 主体逻辑部分,对每一行数据都会执行一次主体逻辑部分【必选】
**END:**END后跟的是程序结束代码块,只会执行一次【可选】
** -F:**用于指定分隔符(awk默认分隔符是空格)
**-v var=value **:赋值一个用户自定义变量,将外部变量传递给awk
-f:scriptfile 从脚本文件中读取awk命令
awk内置变量
$n:当前记录的第n个字段,n为1表示第一个字段。。。
**$0:**执行过程中当前行的文本内容
**NR:**表示记录数,在执行过程中对应于当前的行号
**FS:**字段分隔符
**NF:**表示字段数,在执行过程中对应于当前的字段数,print $NF 对于一行中最后一个字段
awk 'BEGIN{print "序号\t姓名"} {print FS:}' awk.txt 设置输出的开头
awk -F: '{print $2 $NF}' awk.txt ,以:为分隔符显示第二个字段 显示当前行最后一个值

awk -F: '{print $2}' awk.txt 以:分割显示第二个字段
**awk -F: '{print $2 NF}' awk.txt **
** awk -F: '{print $2 $0}' awk.txt 以:分割显示第二个字段 并将整行数据显示出来**




3:sed命令
sed 命令类似一种在线编辑器可以对文件内容进行重定向,和awk一样逐行读取文件内容 将读取到的文件内容存储在临时的缓冲区中 称为”模式空间“,sed命令会处理缓冲区的内容,在将数据输出到屏幕上。主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
格式:sed 【选项】 ‘【动作】’文件
-n:列出经过sed命令处理后的行数据
-v:显示版本
-i:直接修改读取到的内容,不将读取到的数据输出到终端
-e:在命令模式下进行sed编辑
-f:将sed的动作写在一个文件内,可以直接执行文件内的sed动作
sed动作
a:新增 a的后面可以接字符串,而这些字符串会在新的一行出现(目标的下一行)
c:取代 c的后面可以接字符串,而这些字符串可以代替n1,n2之间的行
d:删除 d后面通常不带任何字符串
i:插入 i的后面可以跟字符串,而这些字符串会在新的一行插入(目标的上一行)与a新增相反
p:打印 将某个选项的数据打印出来 通常会与参数 sed -n 一起运行
s:取代,将s后面跟的字符串 取代目标字符串
sed 's/要被取代的字串/新的字串/g' g 标识符表示全局查找替换,使 sed 对文件中所有符合的字符串都被替换,修改后内容会到标准输出,不会修改原文件:
**cat sed.txt |grep -i "ff" | sed 'a hh' **查询到ff在他下面新增一条hh
**cat sed.txt |grep -i "ff" | sed 'c hh' **查询到ff替换成hh

**sed '2,5d' sed.txt |cat -n **删除2-5行

**cat sed.txt |grep -i "ff" | sed 'i hh' **查询到ff在他上面新增一条hh

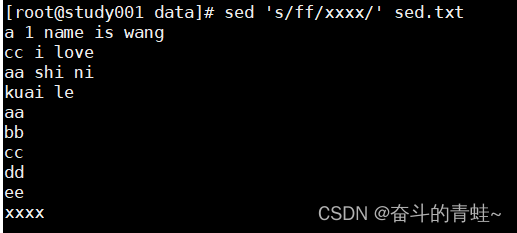
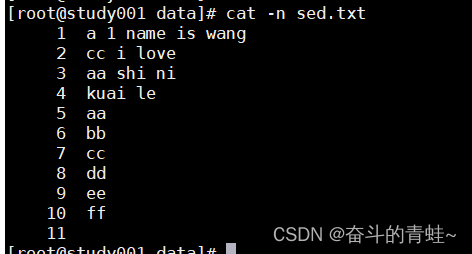
**sed 's/ff/xxxx/' sed.txt **将ff 替换成xxxx

4:find命令
find命令可以将文件系统内符合条件的文件列出来,可以指定文件名称、类别、时间、大小以及权限等不同信息的组合
**语法:find 【路径】【选项】 '【查找值】' **
-name:按照文件名来查询文件
-size:按照文件大小来查找文件
-type<文件类型>:按照文件类型查找文件

5:locate命令
使用locate命令可以通过数据库(/var/lib/mlocate/mlocate.db文件)来查找文件(当天新增的文件查询不到 数据库每一天已更新 t-1 使用sudo updatedb 可以立即更新数据库),他的速度要比find快
locate [选项] [目标文件]
** -q:**安静模式,不会显示任何错误信息
-r:使用正则表达式作为搜索的条件
-i:不区分大小写
-c:显示找到的数量
-w:匹配完整的路径名
版权归原作者 奋斗的青蛙~ 所有, 如有侵权,请联系我们删除。