
1.什么是spark
在官网上对于spark的解释是以下一段话

意思是Apache SparkTM 是一个多语言引擎,用于在单节点机器或集群上执行数据工程、数据科学和机器学习。
Spark是一种快速、通用、可扩展的大数据分析引擎,2009年诞生于加州大学伯克利分校AMPLab,2010年开源,2013年6月成为Apache孵化项目,2014年2月成为Apache顶级项目。目前,Spark生态系统已经发展成为一个包含多个子项目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLlib等子项目,Spark是基于内存计算的大数据并行计算框架。Spark基于内存计算,提高了在大数据环境下数据处理的实时性,同时保证了高容错性和高可伸缩性,允许用户将Spark部署在大量廉价硬件之上,形成集群。Spark得到了众多大数据公司的支持,这些公司包括Hortonworks、IBM、Intel、Cloudera、MapR、Pivotal、百度、阿里、腾讯、京东、携程、优酷土豆。当前百度的Spark已应用于凤巢、大搜索、直达号、百度大数据等业务;阿里利用GraphX构建了大规模的图计算和图挖掘系统,实现了很多生产系统的推荐算法;腾讯Spark集群达到8000台的规模,是当前已知的世界上最大的Spark集群。
2.spark的特点
1、Speed:速度快

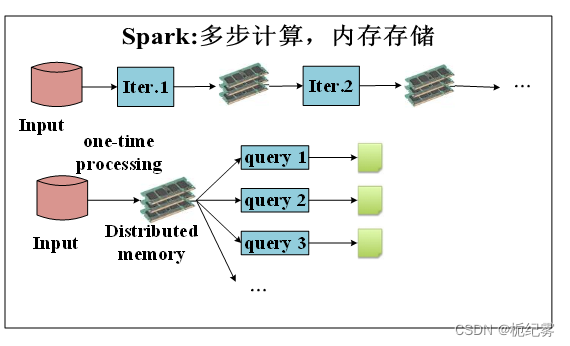

一般情况下,对于迭代次数较多的应用程序,Spark程序在内存中的运行速度是Hadoop MapReduce运行速度的100多倍,在磁盘上的运行速度是Hadoop MapReduce运行速度的10多倍。
由于Spark是基于内存进行计算的,所以它的计算性能理论上可以比MapReduce快100倍。
Spark使用最先进的DAG调度器、查询优化器和物理执行引擎,实现了高性能的批处理和流处理。
注意:批处理其实就是离线计算,流处理就是实时计算,只是说法不一样罢了,意思是一样的。
2、Easy of Use:易用性

Spark的易用性主要体现在两个方面:
1、可以使用多种编程语言快速编写应用程序,例如Java、Scala、Python、R和SQL
2、Spark提供了80多个高阶函数,可以轻松构建Spark任务。
看这个图中的代码,spark可以直接读取json文件,使用where进行过滤,然后使用select查询指定字段中的值。
3、Generality:通用性
Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming(流计算),并且支持在一个应用中同时使用这些组件。

Spark提供了Core、SQL、Streaming、MLlib、GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、SQL交互式查询、流式实时计算,机器学习、图计算等常见的任务
从这可以看出来Spark也是一个具备完整生态圈的技术框架,它不是一个人在战斗。
4.随处运行
用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon和任何分布式文件系统读取数据。

5.代码简洁


3.spark的生态系统
在实际应用中,大数据处理主要包括一下3个类型:
① 复杂的批量数据处理:时间跨度通常在数十分钟到数小时之间。
② 基于历史数据的交互式查询:时间跨度通常在数十秒到数分钟之间。
③ 基于实时数据流的数据处理:时间跨度通常在数百毫秒到数秒之间。
当同时存在以上三种场景时,就需要同时部署三种不同的软件


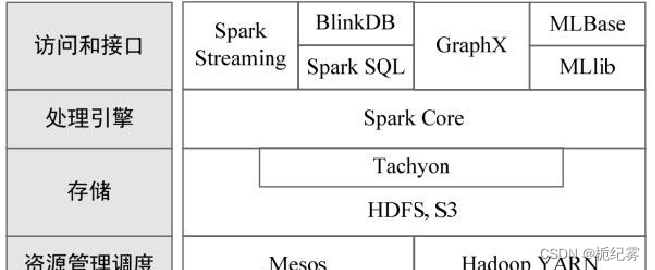
spark生态系统:


了解Spark作业运行流程
Standalone****模式运行流程

4.Spak 和Hadoop区别
spark是在MapReduce上发展而来,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷:
1.提高了效率
Spark把中间数据放到内存中,迭代运算效率高。MapReduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率
2.容错性高
Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,需要进行重建。
相比来说spark更加通用,spark提供了更多的数据集操作类型,处理节点之间通信模型不是向hadoop只采用Shuffle模式,而是采用用户可命名,控制中间结果的存储,分区。
Spark Core
1)提供了有向无环图(DAG)的分布式并行计算框架,并提供Cache机制来支持多次迭代计算或者数据共享,大大减少迭代计算之间读取数据局的开销,这对于需要进行多次迭代的数据挖掘和分析性能有很大提升
2)在Spark中引入了RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”对它们进行重建,保证了数据的高容错性;
移动计算而非移动数据,RDD Partition可以就近读取分布式文件系统中的数据块到各个节点内存中进行计算
使用多线程池模型来减少task启动开稍
3)采用容错的、高可伸缩性的akka作为通讯框架
Spark Streaming
SparkStreaming是一个对实时数据流进行高通量、容错处理的流式处理系统,可以对多种数据源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)进行类似Map、Reduce和Join等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。
Spark SQL
SparkSQL的前身是Shark,Shark是伯克利实验室Spark生态环境的组件之一,它修改了内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。Shark过于依赖Hive,它是当时唯一运行在Hadoop上的SQL-on-Hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低运行效率.SparkSQL在数据兼容性、性能优化、组件扩展等方面做了很大提升。
5.spark的运行模式
Spark有三种运行模式:local模式、standalone模式和集群模式。
- local模式:在本地机器上运行Spark应用程序,不需要启动集群。这种模式适用于开发和调试小规模的应用程序。
- standalone模式:在一个独立的Spark集群上运行应用程序。在这种模式下,一个节点被指定为主节点,负责协调任务的分配和调度。其他节点作为工作节点,执行任务。这种模式适用于中小规模的集群环境。
- 集群模式:在大规模的分布式集群上运行Spark应用程序。Spark可以与各种资源管理器(如YARN、Mesos)集成,通过它们来管理集群资源。在这种模式下,Spark应用程序被分解为多个任务,并在集群中的多个节点上并行执行。这种模式适用于大规模数据处理和分析任务。
6.spark的框架
Spark 框架模块包含:Spark Core、 Spark SQL、 Spark Streaming、 Spark GraphX、 Spark MLlib,而后四项的能力都是建立在核心引擎之上。
【Spark Core】:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、
Scala、R语言的API,可以编程进行海量离线数据批处理计算。
【SparkSQL】:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同
时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
【SparkStreaming】:以SparkCore为基础,提供数据的流式计算功能。
MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
【GraphX】:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算
二、 Spark的架构角色
1、【YARN角色回顾】
YARN主要有4类角色,从2个层面去看:
资源管理层面
(1)集群资源管理者(Master):ResourceManager
(2)单机资源管理者(Worker):NodeManager
任务计算层面
(1) 单任务管理者(Master):ApplicationMaster
(2)单任务执行者(Worker):Task(容器内计算框
架的工作角色)
2、【Spark运行角色】
Spark中由4类角色组成整个Spark的运行环境
资源管理层面:
(1)管理者:Spark是Master角色,Yarn是ResourceManager
(2)工作中:Spark是Worker角色,Yarn是NodeManager
从任务执行层面
(1)某任务管理者:Spark是Driver角色,Yarn是ApplicationMaster
(2)某任务执行者:Spark是Executor角色,Yarn是容器中运行的具体工作进程。
正常情况下Executor是干活的角色,不过在特殊场景下(Local模式)Driver可以即管理又干活
7.Spark作业的运行流程
1.构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
2.资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
3.SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
4.Task在Executor上运行,运行完毕释放所有资源。
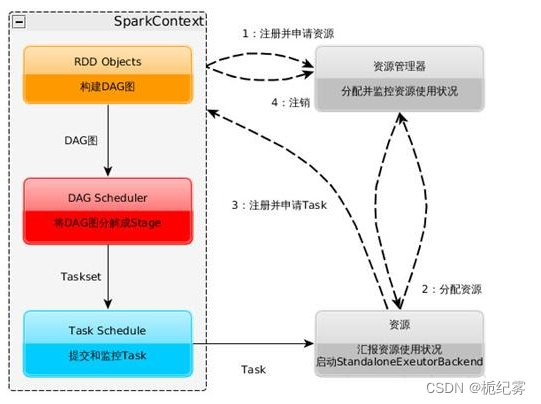
Spark运行架构特点:
- 每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。这种Application隔离机制有其优势的,无论是从调度角度看(每个Driver调度它自己的任务),还是从运行角度看(来自不同Application的Task运行在不同的JVM中)。当然,这也意味着Spark Application不能跨应用程序共享数据,除非将数据写入到外部存储系统。
- Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
- 提交SpzarkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换;如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。
- Task采用了数据本地性和推测执行的优化机制。
**8.Spark的核心数据集RDD **
1 RDD定义
RDD(Resilient Distributed Dataset)叫做弹性 分布式 数据集,是Spark中最基本的数据抽象,
代表一个不可变类型、可分区、里面的元素可并行计算的集合。可以认为RDD是分布式的"列表List或数组Array"(与其说是列表不如说是元组【其本身是不可变类型,只能通过血缘追踪】)

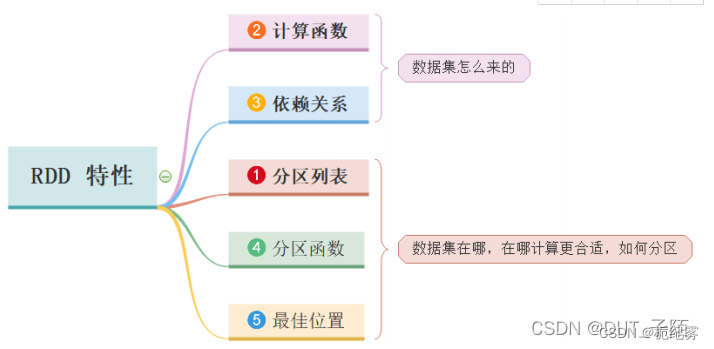
2.RDD的五个特征
每个RDD都由一系列的分区构成
RDD的计算操作,是对RDD每个分区的计算
一个RDD会依赖于其他多个RDD
可选的,如果是二元组【KV】类型的RDD,在Shuffle过程中可以自定义分区器
可选的,Spark程序运行时,Task的分配可以指定实现最优路径解:最优计算位置
3 RDD的分区
分区是一个偏物理层的概念,也是 RDD 并行计算的核心。数在 RDD 内部被切分为多个子集合,每个子集合可以被认为是一个分区,运算逻辑最小会被应用在每一个分区上,每个分区是由一个单独的任务(task)来运行的,所以分区数越多,整个应用的并行度也会越高。子RDD的分区数 = 父RDD的分区数
RDD分区的设置
RDD分区的原则是使得分区的个数尽量等于集群中的CPU核心(core)数目,这样可以充分利用CPU的计算资源;
在实际中为了更加充分的压榨CPU的计算资源,会把并行度设置为cpu核数的2~3倍;
版权归原作者 栀纪雾 所有, 如有侵权,请联系我们删除。