
hive
小白的hive学习笔记 2024/4/27 17:24 今天写的比较急,先凑活看,有空的话再完善一下
文章目录
是一个数据挖掘工具
会sql就会hive
hive安装

这四个文件传到root下

在线安装
-y:安装过程都同意(yes)
yum install -y
4.安装mysql
4.1****tar -xzvf hive.tar.gz
目录结构
bin可执行 examples lib jar NOTICE RELEASE_NOTES.txt
conf配置文件 hcatalog(Hcatalog是apache开源的对于表和底层数据管理统一服务平台,hive就是通过hcatlog获取元数据信息) LICENSE README.txt scripts
cp /usr/local/hive/lib/jline-2.12.jar /usr/local/hadoop/share/hadoop/yarn/lib
rm -rf /usr/local/hadoop/share/hadoop/yarn/lib/jline-0.9.94.jar
4.2 让mysql当作metastore
4.2.1mysql安装
64位安装
安装:
1.先安装依赖包
yum install -y perl-Module-Install.noarch
yum -y install autoconf
2.添加mysql组
groupadd mysql
添加mysql用户
useradd -r -g mysql mysql
3.RPM的方式安装server
yum install libaio
rpm -e mariadb-libs-1:5.5.56-2.el7.x86_64 --nodeps 强制删除
rpm -ivh MySQL-server-5.6.36-1.linux_glibc2.5.x86_64.rpm
结尾显示这些内容就说明server安装成功了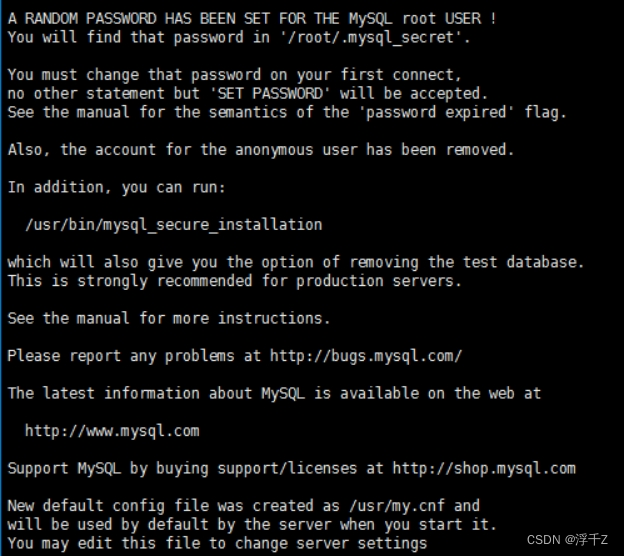
4.RPM的方式安装client
rpm -ivh MySQL-client-5.6.36-1.linux_glibc2.5.x86_64.rpm
5.修改密码
#先确保mysql没有启动
#如果启动了 使用 service mysql stop关闭
mysqld_safe --user=mysql --skip-grant-tables --skip-networking &
#新开一个命令窗口
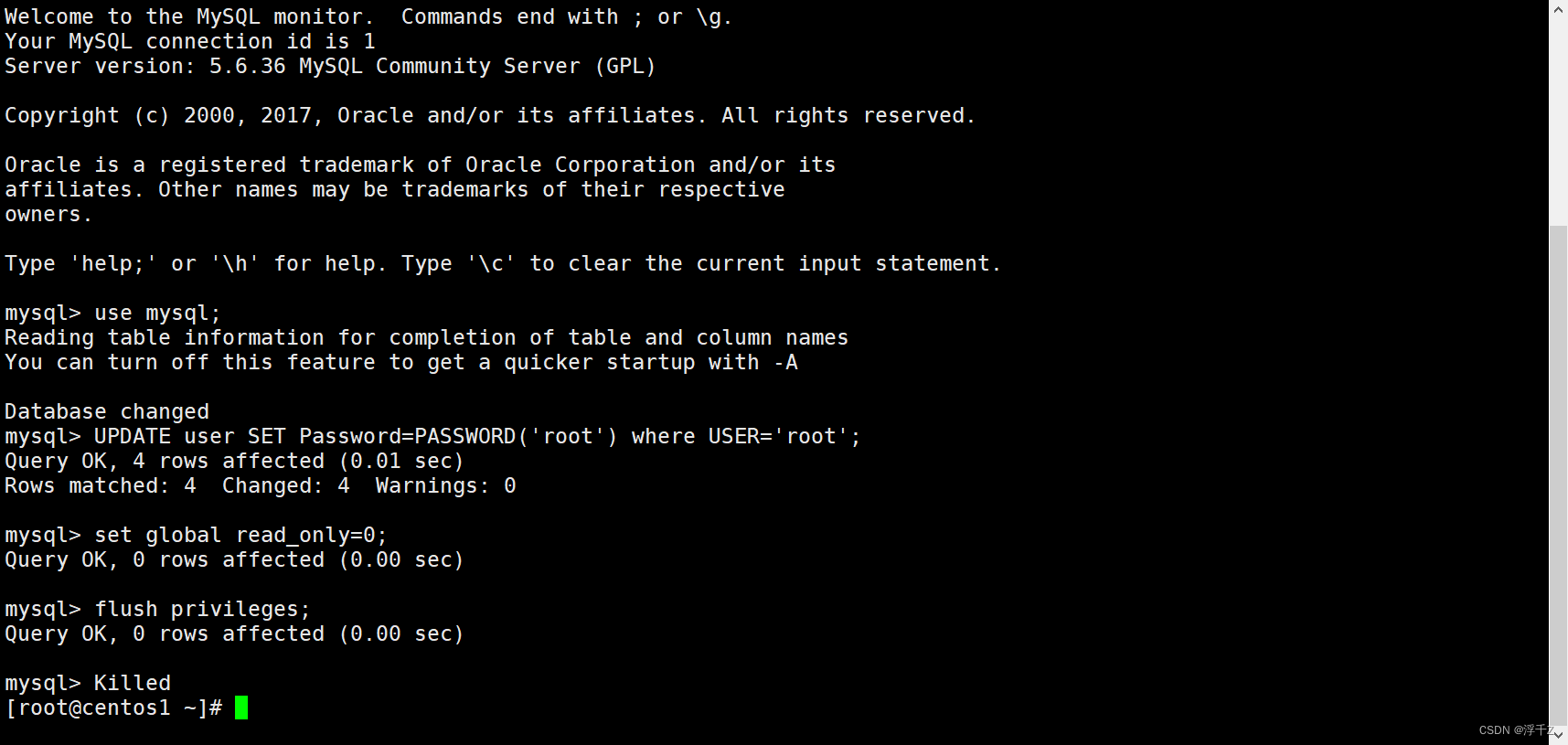
mysql -u root
use mysql;
#修改root密码
UPDATE user SET Password=PASSWORD(‘root’) where USER=‘root’;
#关闭只读状态
set global read_only=0;
flush privileges;
新打开一个窗口:
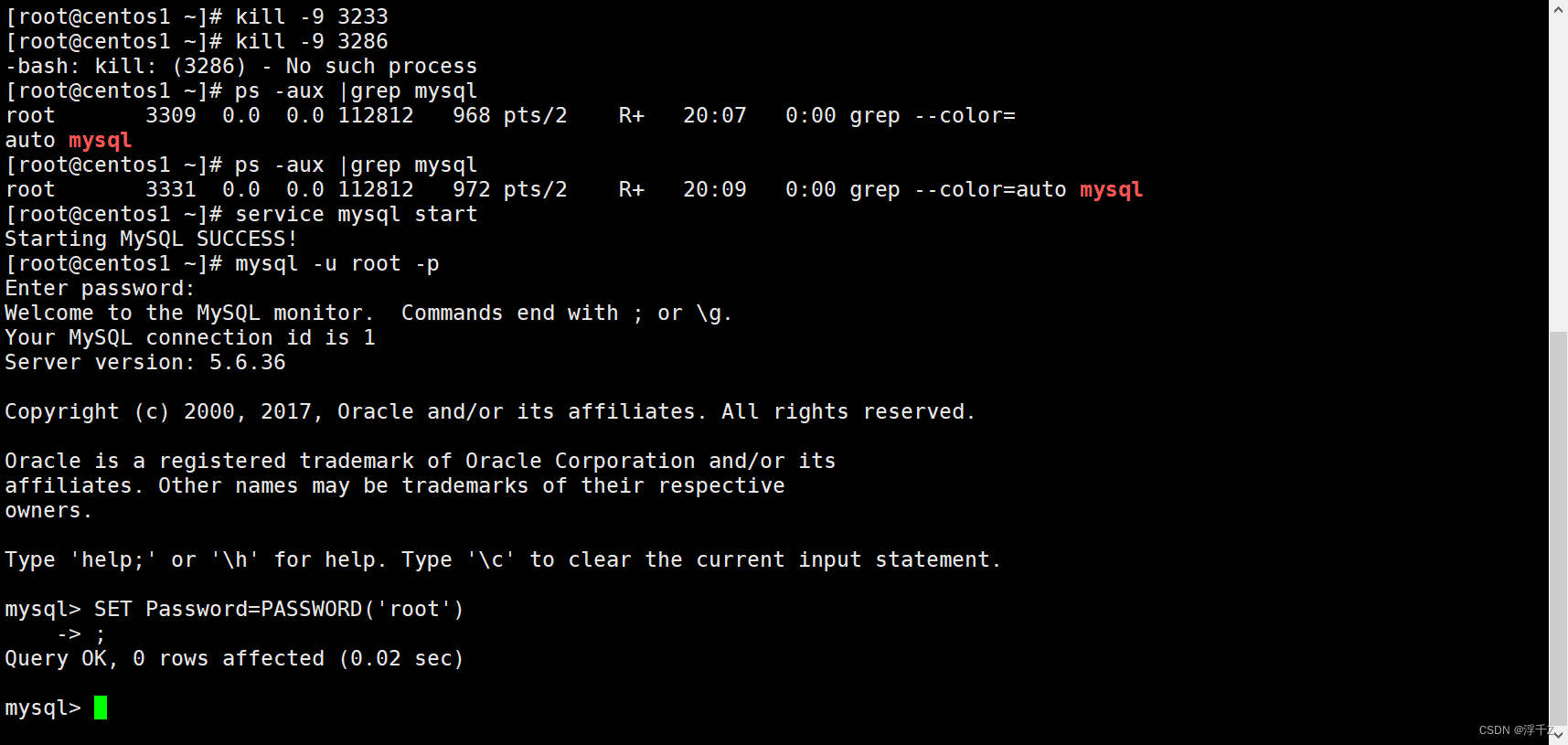
ps -aux |grep mysql
将所有进程kill掉

6.启动mysql服务
service mysql start
mysql -u root -p
SET Password=PASSWORD(‘root’)

mysql
create database 库名;
库就是文件夹,为了组织表方便
安装hive
1.解压安装
在root下
-C 拷贝
tar-zxvf apache-hive-1.2.1-bin.tar.gz -C /usr/local/
tar:
用来创建归档文件,可以解压、也可以压缩
rpm:
安装rpm
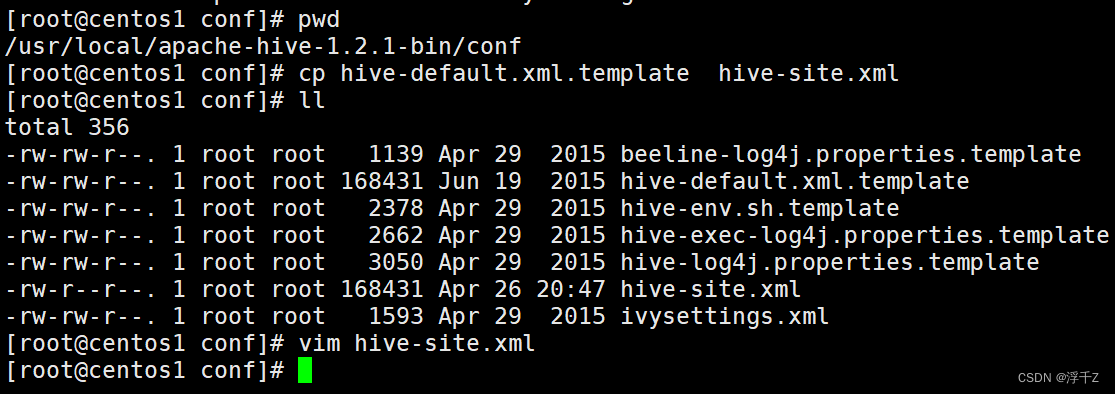
删除
vim hive-site.xml
从22行到/<//configuration>之前都删除
:22,3900d(这是快捷删除22 行到3900行,这里的具体删除不是22到3900)
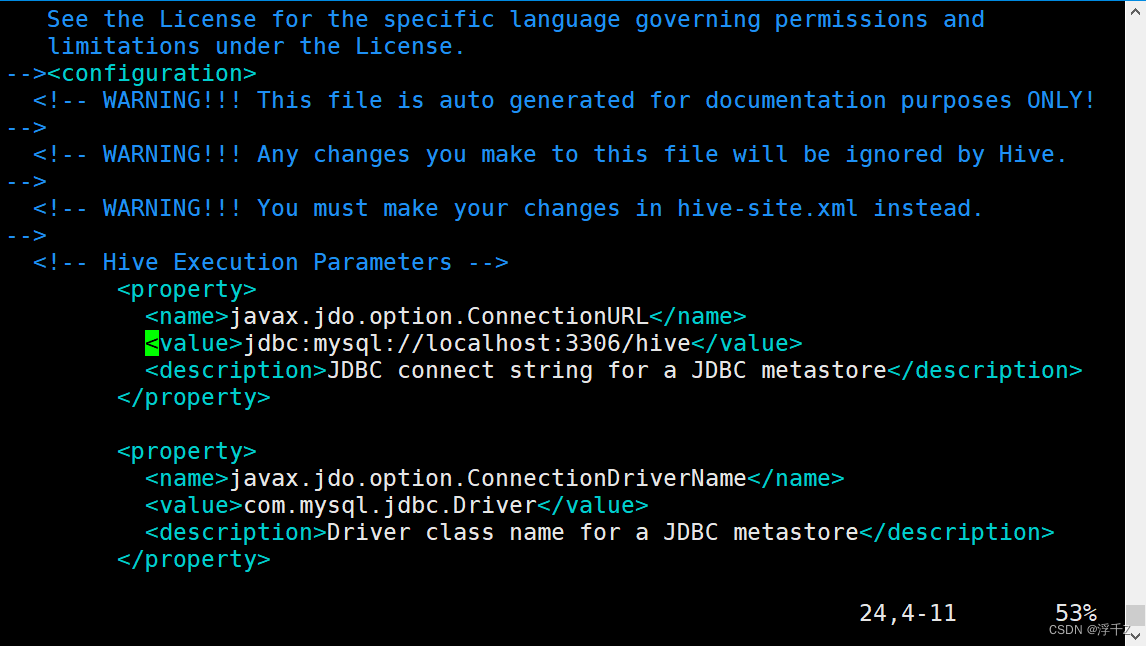
把下面的复制到confguration下面
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.38.1:3306/hive</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
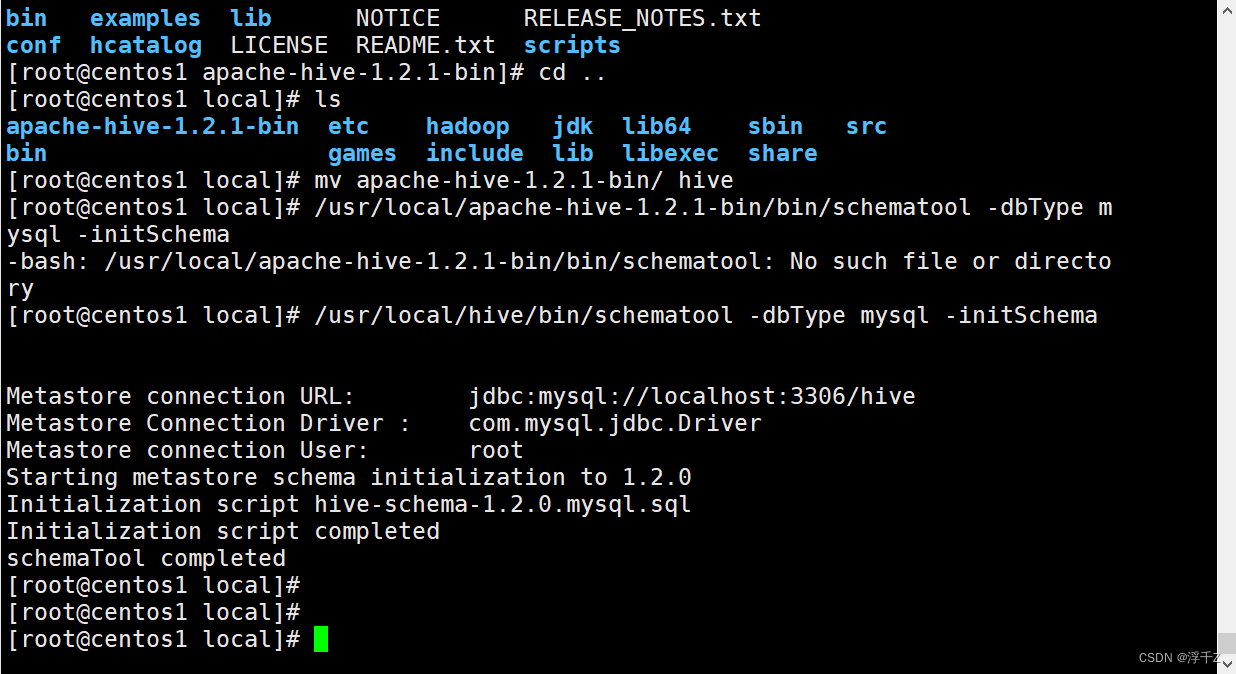
执行
/usr/local/hive/bin/schematool -dbType mysql -initSchema
用来再hive下面生成53张表
包括数据位置,在表TBLS中存储
hive安装完毕
hive的存储和计算都需要Hadoop
所以要使用hive,就要先start-dfs.sh start-yarn.sh
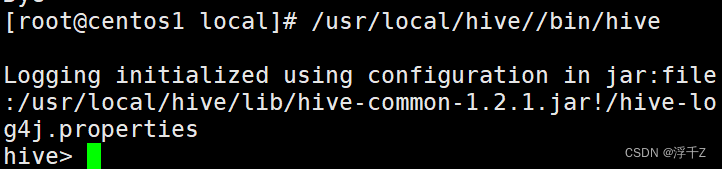
进入hive
处理数据的过程
创建内部表
mysql
创建库 create database
创建表 create table 表名(列1, 数据类型…)
单表查询
一般:
where:
group by
多表查询
内连接
外连接:左,右,全
子查询
- 用查询结果当表
- 把查询结果当条件
mysql数据类型:int , bigint ,varhcar,date,datetiome,char,decimal
- 简单理解
- hive和mysql一模一样
- 会mysql就会mysql
varchar 可以直接向string

数据文件分隔符
设置分隔符为”,“
row format delinited fields terminated by ',';
split(”,“);
加入数据,可以insert into,但是比较慢
加载数据
load data local inpath '/root/1.txt' into table stu;

单表查询
跟mysql一样
一insert into hive就mapreduce,hive本质就是mapreduce
查看表结构
desc stu;
多表查询

子查询
当表
当条件
select max(count(1)) from stu group by sex;
select sex,count(1) from stu group by sex;
select * from stu where sex in
(
select sex from
(select sex,count(1) from stu group by sex;)
where
(select max(count(1)) from stu group by sex;)
)
会创建分区表
通常,按照某个范围进行数据统计,举例TB,每天都产生大量的数据,每天处理每天的数据
如果把所有数据不分区存,需要先where一下,过滤大量的数据
- 注意,hive没有主键
创建:
delimited 打错了


分区为什么速度快?
会精确到每天的文件夹下,而不是把表内所有数据拿来运算。
添加数据
1. insert into
2.load

3.手动创建目录,直接将文件上传

问题:不能自动加分区,mysql没变
所以要向mysql添加分区
修复这个表
msck repair table ord_info;
外部表
加了一个关键字:external


外部表比较安全,删掉了,数据不会丢
会创建UDF函数
相当于mysql自定义函数
当hive的函数不够用,我们可以自定义函数
用java写

会设置map个数
一个map处理多大数据?
用公式如下

然后用数据总的大小,除一个map处理的数据,得到map的个数
数据很大的时候,可以设置多个map,加快速度
设置redudce个数

explain 查看执行计划,看看这个sql好不好

explain 能看到程序的执行过程
处理数据倾斜
什么是数据倾斜?
reduce处理一组一组数据的,假设有两组数据,一个reduce处理一组数据,假设,一个reduce运行不完了、长时间运行,一个reduce很快运行结束。
说明一个key对应太多的数据,一个key对应太少的数据,数据不平衡,也就是数据倾斜
版权归原作者 浮千Z 所有, 如有侵权,请联系我们删除。