

前言
Docker 是一个
开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的
Linux或Windows操作系统的机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。
📕作者简介:热爱跑步的恒川,致力于C/C++、Java、Python等多编程语言,热爱跑步,喜爱音乐的一位博主。
📗本文收录于恒川的日常汇报系列,大家有兴趣的可以看一看
📘相关专栏C语言初阶、C语言进阶系列等,大家有兴趣的可以看一看
📙Python零基础入门系列,Java入门篇系列正在发展中,喜欢Python、Java的朋友们可以关注一下哦!
Docker中 AUFS、BTRFS、ZFS、存储池的概念 讲解

1. AUFS
AUFS (AnotherUnionFS)是一种
Union FS, 简单来说就是支持将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)的文件系统, 更进一步地, AUFS支持为每一个成员目录(AKA branch)设定
'readonly', 'readwrite'和
'whiteout-able'权限, 同时AUFS里有一个类似
Docker对container的使用基本是建立在LXC基础之上的,然而LXC存在的问题是难以移动 -
难以通过标准化的模板制作、重建、复制和移动 container。
在以VM为基础的虚拟化手段中,有image和snapshot可以用于VM的复制、重建以及移动的功能。想要通过container来实现快速的大规模部署和更新, 这些功能不可或缺。
Docker 正是利用AUFS来实现对container的快速更新 - 在docker0.7中引入了storage driver, 支持
AUFS
, VFS, device mapper, 也为
BTRFS
以及
ZFS
引入提供了可能。
1.1 分层的概念
对 readonly 权限的branch可以逻辑上进行修改(增量地, 不影响readonly部分的)。通常 Union FS有两个用途, 一方面可以实现不借助 LVM, RAID 将多个disk和挂在到一个目录下, 另一个更常用的就是将一个readonly的branch和一个writeable的branch联合在一起,Live CD正是基于此可以允许在 OS image 不变的基础上允许用户在其上进行一些写操作。Docker在AUFS上构建的container image也正是如此,接下来从启动container中的linux为例介绍docker在AUFS特性的运用。
典型的Linux启动到运行需要两个FS - bootfs + rootfs (从功能角度而非文件系统角度)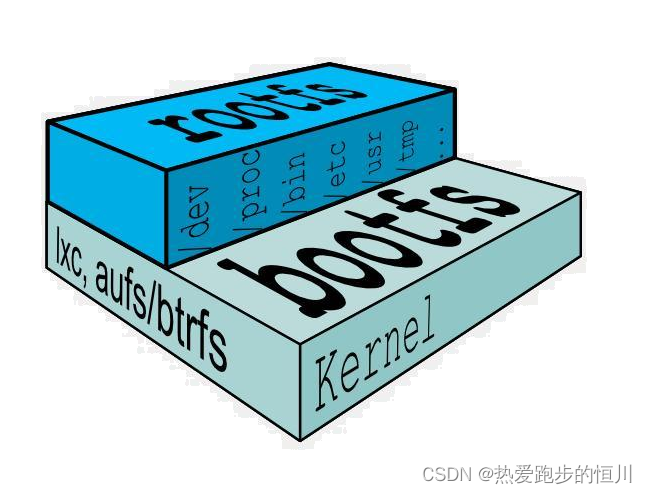
bootfs (boot file system) 主要包含 bootloader 和 kernel, bootloader主要是引导加载kernel, 当boot成功后 kernel 被加载到内存中后 bootfs就被umount了.
rootfs (root file system) 包含的就是典型 Linux 系统中的 /dev, /proc, /bin, /etc 等标准目录和文件。
由此可见对于不同的linux发行版, bootfs基本是一致的, rootfs会有差别, 因此不同的发行版可以公用bootfs 如下
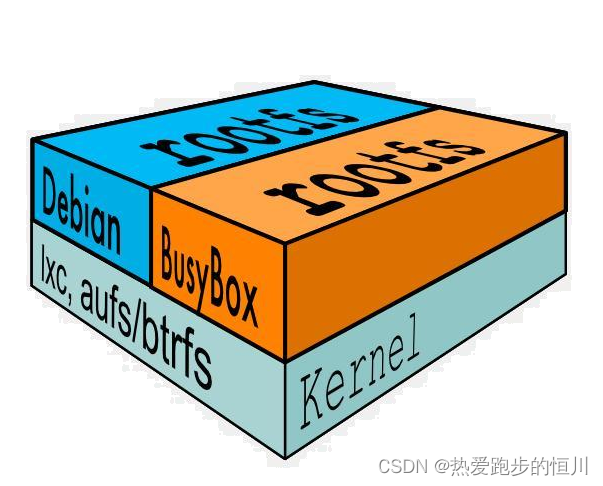
1.2 采用AUFS的好处
采用AUFS作为docker的container的文件系统,能够提供如下好处:
- 节省存储空间 - 多个container可以共享base image存储
- 快速部署 - 如果要部署多个container,base image可以避免多次拷贝
- 内存更省 - 因为多个container共享base image, 以及OS的disk缓存机制,多个container中的进程命中缓存内容的几率大大增加
- 升级更方便 - 相比于 copy-on-write 类型的FS,base-image也是可以挂载为可writeable的,可以通过更新base image而一次性更新其之上的container
- 允许在不更改base-image的同时修改其目录中的文件 - 所有写操作都发生在最上层的writeable层中,这样可以大大增加base image能共享的文件内容。
2. BTRFS

BTRFS(通常念成Butter FS),由Oracle于2007年宣布并进行中的COW(copy-on-write式)文件系统。目标是取代Linuxext3文件系统,改善ext3的限制,特别是单一文件大小的限制,总文件系统大小限制以及加入文件校验和特性。加入ext3/4未支持的一些功能,例如可写的磁盘快照(snapshots),以及支持递归的快照(snapshots of snapshots),内建磁盘阵列(RAID)支持,支持子卷(Subvolumes)的概念,允许在线调整文件系统大小。
2.1 系统介绍
Btrfs宣称专注在“容错、修复与易于管理”。
Btrfs已在2010年7月推出的openSUSE11.3中得到了应用.
Btrfs也已在2010年10月推出的ubuntu10.10中得到了应用.
2011年6月8日,在Fedora工程指导委员会会议上,委员会决定Fedora 16将以Btrfs作为默认文件系统.
2011年8月9日, Fedora撤回了决定,Btrfs不再作为Fedora 16默认文件系统,原因是时间不充足,无法达到改变默认文件系统所要满足的基本要求。
2011年10月5日,Fedora 16测试版发布,BTRFS 将做为其默认文件系统。
2011年11月8日,Fedora 16正式版发布,默认文件系统依然采用ext4,并未采用预计的Btrfs文件系统。
2020年8月24日,Btrfs将取代ext4作为Fedora 33中的默认文件系统。
2.2 特性
首先是扩展性 (scalability) 相关的特性,btrfs 最重要的设计目标是应对大型机器对文件系统的扩展性要求。 Extent,B-Tree 和动态 inode 创建等特性保证了 btrfs 在大型机器上仍有卓越的表现,其整体性能而不会随着系统容量的增加而降低。
其次是数据一致性 (data integrity) 相关的特性。系统面临不可预料的硬件故障,Btrfs 采用 COW 事务技术来保证文件系统的一致性。 btrfs 还支持 checksum,避免了 silent corrupt 的出现。而传统文件系统则无法做到这一点。
第三是和多设备管理相关的特性。 Btrfs 支持创建快照 (snapshot),和克隆 (clone) 。 btrfs 还能够方便的管理多个物理设备,使得传统的卷管理软件变得多余。
最后是其他难以归类的特性。这些特性都是比较先进的技术,能够显著提高文件系统的时间 / 空间性能,包括延迟分配,小文件的存储优化,目录索引等。
2.3 相关特性
2.3.1 B-Tree
btrfs 文件系统中所有的 metadata 都由 B-Tree 管理。
使用 B-Tree 的主要好处在于查找,插入和删除操作都很高效。可以说 B-Tree 是 btrfs 的核心。
一味地夸耀 B-Tree 很好很高效也许并不能让人信服,但假如稍微花费一点儿时间看看 ext2/3 中元数据管理的实现方式,便可以反衬出 B-Tree 的优点。
妨碍 ext2/3 扩展性的一个问题来自其目录的组织方式。目录是一种特殊的文件,
在 ext2/3 中其内容是一张线性表格
。
这种结构在文件个数有限的情况下是比较直观的设计,但随着目录下文件数的增加,查找文件的时间将线性增长。 2003 年,ext3 设计者开发了目录索引技术,解决了这个问题。目录索引使用的数据结构就是 B-Tree 。如果同一目录下的文件数超过 2K,inode 中的 i_data 域指向一个特殊的 block 。在该 block 中存储着目录索引 B-Tree 。
B-Tree 的查找效率高于线性表
,
但为同一个元数据设计两种数据结构总是不太优雅。在文件系统中还有很多其他的元数据,用统一的 BTree 管理是非常简单而优美的设计。
Btrfs 内部所有的元数据都采用 BTree 管理,拥有良好的可扩展性。 btrfs 内部不同的元数据由不同的 Tree 管理。在 superblock 中,有
指针指向这些 BTree 的根。
FS Tree 管理文件相关的元数据,如 inode,dir 等; Chunk tree 管理设备,每一个磁盘设备都在 Chunk Tree 中有一个 item ; Extent Tree 管理磁盘空间分配,btrfs 每分配一段磁盘空间,便将该磁盘空间的信息插入到 Extent tree 。查询 Extent Tree 将得到空闲的磁盘空间信息;
Tree of tree root 保存很多 BTree 的根节点。
比如用户每建立一个快照,btrfs 便会创建一个 FS Tree 。为了管理所有的树,btrfs 采用 Tree of tree root 来保存所有树的根节点; checksum Tree 保存数据块的校验和。
2.3.2 基于 Extent 的文件存储
现代很多文件系统都采用了 extent 替代 block 来管理磁盘。
Extent 就是一些连续的 block,一个 extent 由起始的 block 加上长度进行定义。
Extent 能有效地减少元数据开销。为了进一步理解这个问题,我们还是看看 ext2 中的反面例子。
ext2/3 以 block 为基本单位,将磁盘划分为多个 block 。为了管理磁盘空间,
文件系统需要知道哪些 block 是空闲的
。 Ext 使用 bitmap 来达到这个目的。 Bitmap 中的每一个 bit 对应磁盘上的一个 block,当相应 block 被分配后,bitmap 中的相应 bit 被设置为 1 。这是很经典也很清晰的一个设计,但不幸的是当磁盘容量变大时,bitmap 自身所占用的空间也将变大。这就导致了扩展性问题,随着存储设备容量的增加,bitmap 这个元数据所占用的空间也随之增加。而人们希望无论磁盘容量如何增加,元数据不应该随之线形增加,
这样的设计才具有可扩展性。
2.4 优化支持
SSD 是固态存储 Solid State Disk 的简称。
在过去的几十年中,CPU/RAM 等器件的发展始终遵循着摩尔定律,但硬盘 HDD 的读写速率却始终没有飞跃式的发展。磁盘 IO 始终是系统性能的瓶颈。
SSD 采用 flash memory 技术,内部没有磁盘磁头等机械装置,读写速率大幅度提升。 flash memory 有一些不同于 HDD 的特性。 flash 在写数据之前必须先执行擦除操作;其次,flash 对擦除操作的次数有一定的限制,在技术水平下,对同一个数据单元最多能进行约 10 万次擦除操作,因此,为了延长 flash 的寿命,应该将写操作平均到整个 flash 上。
SSD 在硬件内部的微代码中实现了 wear leveling 等分布写操作的技术,因此系统无须再使用特殊的 MTD 驱动和 FTL 层。虽然 SSD 在硬件层面做了很多努力,但毕竟还是有限。文件系统针对 SSD 的特性做优化不仅能提高 SSD 的使用寿命,而且能提高读写性能。 Btrfs 是少数专门对 SSD 进行优化的文件系统。 btrfs 用户可以使用 mount 参数打开对 SSD 的特殊优化处理。
==Btrfs 的 COW 技术从根本上避免了对同一个物理单元的反复写操作。==如果用户打开了 SSD 优化选项,btrfs 将在底层的块空间分配策略上进行优化:将多次磁盘空间分配请求聚合成一个大小为 2M 的连续的块。大块连续地址的 IO 能够让固化在 SSD 内部的微代码更好的进行读写优化,从而提高 IO 性能。
3. ZFS

ZFS文件系统的英文名称为Zettabyte File System,也叫动态文件系统(Dynamic File System),是第一个128位文件系统。最初是由Sun公司为Solaris 10操作系统开发的文件系统。作为OpenSolaris开源计划的一部分,ZFS于2005年11月发布,被Sun称为是终极文件系统,经历了 10 年的活跃开发。而最新的开发将全面开放,并重新命名为 OpenZFS
3.1 历史

ZFS的设计与开发由Sun公司的Jeff Bonwick所领导的一支团队完成。最早宣布于2004年9月14日,于2005年10月31日并入了Solaris开发的主干源代码。并在2005年11月16日作为OpenSolaris build 27的一部分发布。Sun在OpenSolaris社区开张1年后的2006年六月,将ZFS集成进了Solaris 10 6/06版本更新。
ZFS的命名来源发想于
"ZettabyteFile System"的首字母缩写。
但 ZFS 本身并不具备任何的缩写意涵,只是作者想阐述做为一个具备高扩充容量文件系统且还有支持许多延伸功能的一个产品。
3.2 文件介绍
ZFS是一款128bit文件系统
,总容量是现有64bit文件系统的1.84x1019倍,其支持的单个存储卷容量达到16EiB(264byte,即 16x1024x1024TB);一个zpool存储池可以拥有264个卷,总容量最大256ZiB(278byte);整个系统又可以拥有2^64个存储 池。可以说在相当长的未来时间内,ZFS几乎不太可能出现存储空间不足的问题。另外,它还拥有自优化,自动校验数据完整性,存储池/卷系统易管理等诸多优点。较ext3系统有较大运行速率,提高大约30%-40%。
ZFS是基于存储池的,与典型的映射物理存储设备的传统文件系统不同,ZFS所有在存储池中的文件系统都可以使用存储池的资源。
3.3 什么是ZFS
ZFS 文件系统是一个革命性的全新的文件系统,它从根本上改变了文件系统的管理方式,这个文件系统的特色和其带来的好处至今没有其他文件系统可以与之媲美,ZFS 被设计成强大的、可升级并易于管理的。- ZFS 用“存储池”的概念来管理物理存储空间。过去,文件系统都是构建在物理设备之上的。为了管理这些物理设备,并为数据提供冗余,“卷管理”的概念提供了一个单设备的映像。但是这种设计增加了复杂性,同时根本没法使文件系统向更高层次发展,因为文件系统不能跨越数据的物理位置。
- ZFS 完全抛弃了“
卷管理”,不再创建虚拟的卷,而是把所有设备集中到一个存储池中来进行管理!“存储池”描述了存储的物理特征(设备的布局,数据的冗余等等),并扮演一个能够创建文件系统的专门存储空间。从此,文件系统不再局限于单独的物理设备,而且文件系统还允许物理设备把他们自带的那些文件系统共享到这个“池”中。你也不再需要预先规划好文件系统的大小,因为文件系统可以在“池”的空间内自动的增大。当增加新的存贮介质时,所有“池”中的所有文件系统能立即使用新增的空间,而不需要额外的操作。在很多情况下,存储池扮演了一个虚拟内存。 ZFS使用一种写时拷贝事务模型技术。所有文件系统中的块指针都包括256位的能在读时被重新校验的关于目标块的校验和。含有活动数据的块从来不被覆盖;而是分配一个新块,并把修改过的数据写在新块上。所有与该块相关的元数据块都被重新读、分配和重写。为了减少该过程的开销,多次读写更新被归纳为一个事件组,并且在必要的时候使用日志来同步写操作。利用写时拷贝使ZFS的快照和事物功能的实现变得更简单和自然,快照功能更灵活。缺点是,COW使碎片化问题更加严重,对于顺序写生成的大文件,如果以后随机的对其中的一部分进行了更改,那么这个文件在硬盘上的物理地址就变得不再连续,未来的顺序读会变得性能比较差。
4. 存储池的概念
不同于传统文件系统需要驻留于单独设备或者需要一个卷管理系统去使用一个以上的设备
,ZFS创建在虚拟的,被称为
“zpools”
的存储池之上(存储池最早在AdvFS实现,并且加到后来的Btrfs)。每个存储池由若干虚拟设备(virtual devices,vdevs)组成。这些虚拟设备可以是原始磁盘,也可能是一个RAID1镜像设备,或是非标准RAID等级的多磁盘组。于是zpool上的文件系统可以使用这些虚拟设备的总存储容量。
可以使用磁盘限额以及设置磁盘预留空间来限制存储池中单个文件系统所占用的空间。
如果这份博客对大家有帮助,希望各位给恒川一个免费的点赞👍作为鼓励,并评论收藏一下⭐,谢谢大家!!!
制作不易,如果大家有什么疑问或给恒川的意见,欢迎评论区留言。
版权归原作者 热爱跑步的恒川 所有, 如有侵权,请联系我们删除。